Menanggapi peningkatan jumlah aplikasi yang berjalan dan jumlah perangkat jaringan, peningkatan bandwidth jaringan dan persyaratan pengiriman paket diperketat. Pada skala pusat data cloud-critical yang penting untuk bisnis, pendekatan tradisional untuk pemeliharaan infrastruktur tidak lagi memungkinkan penyelesaian tugas-tugas khusus. Karena itu, lahirlah konsep AIOps (Operasi TI Algoritmik).
Menurut Gartner, sekitar 50% perusahaan akan menggunakan AIOps pada tahun depan. Kita dapat berbicara tentang apa yang dapat dilakukan alat serupa hari ini, menggunakan contoh Huawei FabricInsight, penganalisa jaringan yang merupakan bagian dari solusi komprehensif untuk pusat data Huawei CloudFabric.
Transformasi digital dari perusahaan memberikan peluang baru - pengenalan analisis Big Data, pengembangan algoritma pembelajaran mesin - bukan lagi sekadar iseng, tetapi merupakan kebutuhan sadar, penutupan yang membawa keuntungan nyata. Namun, implementasi baru memerlukan beberapa peningkatan kompleksitas infrastruktur, yang pada saat yang sama menimbulkan tantangan baru dalam hal pemeliharaannya.
Masalah utama pemeliharaan infrastruktur besar saat ini adalah jumlah data yang harus dikumpulkan dan diproses untuk mendapatkan informasi tentang status pusat data, serta kecepatan yang diperlukan untuk memberikan jawaban yang relevan dengan penyebab kegagalan. Di satu sisi, jumlah parameter yang dipantau terus meningkat, di sisi lain, waktu bermain melawan organisasi, karena tujuan dari perusahaan mana pun adalah untuk memulihkan ketersediaan layanannya sesegera mungkin jika terjadi kesalahan (terutama mengingat persyaratan SLA yang ketat). Kecepatan "kebangkitan" layanan setelah keruntuhan sebagian besar ditentukan oleh kecepatan penyelidikan insiden. Dan itu, pada gilirannya, tergantung pada kelengkapan informasi tentang apa yang terjadi. Tetapi jika setidaknya 50 - 100 rak server dipasang di pusat data, mekanisme pemantauan standar tidak dapat mengatasi persyaratan tinggi untuk bandwidth dan pengiriman paket yang tepat waktu.
Mengapa SNMP gagal?
Mekanisme standar - SNMP dan xFlow - mengumpulkan data hanya setiap 5-15 menit, pengambilan sampel informasi. Mereka awalnya dikembangkan dengan memperhatikan keterbatasan post-processing data yang terakumulasi tanpa tugas mengidentifikasi masalah secara real time. Dan bahkan pengumpulan data terbatas seperti itu mempengaruhi pengoperasian perangkat jaringan.
Mengingat lalu lintas yang bermasalah hanya 3,65%, pendekatan tradisional, berdasarkan hasil analisis, hanya mengungkapkan 30% masalah jaringan, 70% tidak terlihat oleh sistem pemantauan.
Diperlukan administrator berpengalaman yang tahu apa dan ke mana mencarinya untuk mengidentifikasi akar masalah dari data yang dikumpulkan oleh SNMP dan xFlow. Masalah harus diidentifikasi dengan menganalisis log besar dan beberapa pesan kesalahan, dan kemudian secara manual membuat perubahan konfigurasi. Tetapi dengan pengembangan SDN, dengan virtualisasi sumber daya fisik, konfigurasi manual adalah sesuatu dari masa lalu. Saat ini, bahkan seluruh staf administrator sistem tidak dapat lagi memastikan kepatuhan yang berkelanjutan terhadap parameter infrastruktur dengan persyaratan bisnis.
FabricInsight bekerja secara berbeda
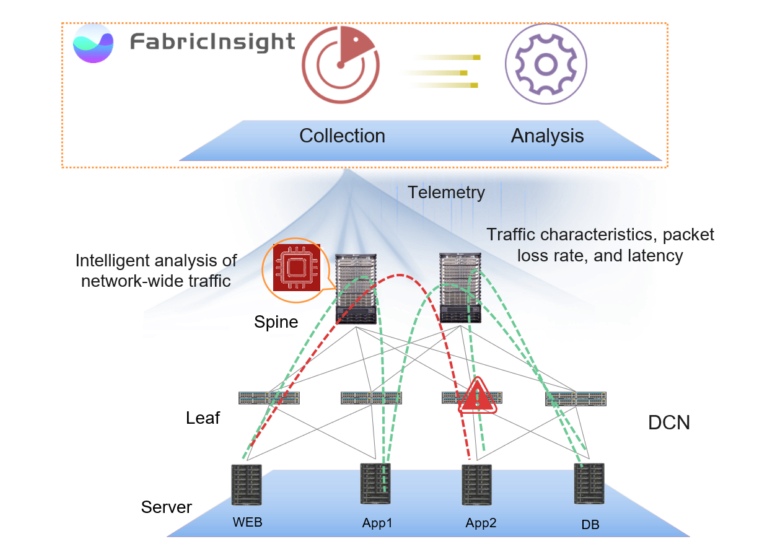
Platform Analisis Jaringan FabricInsight menawarkan pendekatan yang berbeda, mengotomatiskan pemeliharaan jaringan dan deteksi titik kegagalan. FabricInsight menganalisis perilaku aplikasi, mengidentifikasi jalur jaringan yang mereka gunakan dan melacak status perangkat di dalamnya.

Pendekatan ini didasarkan pada dua komponen utama - pengumpulan semua data yang tersedia dan analisis otomatisnya. Dilengkapi dengan visualisasi fungsional dan kebijakan keterbukaan data, pendekatan ini memungkinkan kami untuk menyelesaikan banyak masalah yang sebelumnya buntu.
Kumpulkan semua data yang tersedia.
Kunci untuk respons cepat terhadap situasi adalah gambaran lengkap tentang apa yang terjadi di dalam pusat data di tingkat jaringan. FabricInsight menggunakan mekanisme berlangganan push telemetri untuk mengumpulkan semua data layanan tingkat kedua secara tepat waktu tanpa sampel. Untuk mendapatkan gambaran lengkap dari jaringan, data dikumpulkan pada pengoperasian perangkat, aplikasi, dan lalu lintas jaringan (paket TCP SYN, FIN, dan RST) - ERSPAN didukung untuk paket mirroring tanpa menggunakan CPU perangkat dan GRPC Google untuk melaporkan kinerja perangkat itu sendiri.
Data yang dikumpulkan melalui FabricInsight LEAF ditransmisikan ke FabricInsight Collector, yang memantau parameter temporal dari paket yang melewati jaringan. Kolektor memberikan data lalu lintas jaringan dengan cap waktu, menyandikan dan mengirim melalui HTTP ke FabricInsight Analyzer. Pendekatan ini memungkinkan Anda untuk mengumpulkan informasi maksimum tentang jaringan, menangkap bahkan lalu lintas jangka pendek yang tidak dapat dideteksi oleh solusi "klasik".
Pada saat yang sama, FabricInsight tidak melihat ke dalam paket IP (tidak menangkap isinya), hanya menggunakan header dalam pekerjaannya. Dengan demikian, dapat digunakan di area-area penting untuk bisnis, misalnya, di mana ada pekerjaan dengan data pribadi.
Analisis waktu nyata
Elemen integral kedua dari sistem adalah FabricInsight Analyzer. Menerima data yang dikumpulkan, itu mengidentifikasi jalur lalu lintas dan menjalankan algoritma yang menganalisis situasi dalam waktu yang hampir nyata. Secara umum, FabricInsight Analyzer menghubungkan lalu lintas jaringan dengan aplikasi, memungkinkan Anda untuk dengan cepat mengidentifikasi dan memperbaiki masalah. Karena pembelajaran mesin, algoritma ini “dilatih” untuk mengidentifikasi perilaku normal dan abnormal infrastruktur.
NetworkInsight mencerminkan hasil analisis jaringan dalam antarmuka dalam bentuk peta status jaringan, interaksi aplikasi, analisis untuk aplikasi individual, dll., Diperbarui secara real time. Antarmuka diimplementasikan sedemikian rupa untuk secara visual menghubungkan tingkat aplikasi dan perangkat fisik tertentu yang bertanggung jawab atas operabilitas jaringan, yang mempercepat pemecahan masalah dan metode untuk menyelesaikannya.
Jika ada anomali terdeteksi, informasi awal disimpan secara otomatis, sesuai dengan masalah yang telah diidentifikasi (durasi penyimpanan disesuaikan), jika perlu, FabricInsight memperingatkan pengguna. Selain itu, prosedur untuk memperbaiki situasi "dalam satu klik dengan mouse" melalui antarmuka grafis diinisialisasi. Pada saat yang sama, berbagai pola koreksi kesalahan dianalisis untuk menemukan pendekatan yang paling relevan.
Kasing
Untuk mengidentifikasi anomali pusat data, analisis korelasi operasi aplikasi, perangkat, dan jalur lalu lintas digunakan, sehingga berbagai jenis anomali dicatat - baik sementara dan jangka panjang.

Omong-omong, sebagian besar anomali sementara yang disebutkan di atas tidak dapat diperbaiki dengan menggunakan pendekatan klasik. Ini juga berlaku untuk beberapa anomali jangka panjang. Contoh yang cukup umum adalah pembaruan perangkat lunak "bengkok". Misalkan aplikasi tertentu beroperasi di pusat data yang menghasilkan lalu lintas tertentu. Setelah memperbaruinya, volume lalu lintas ini telah berubah secara dramatis, misalnya, throughput aplikasi telah menurun, penundaan telah meningkat. Anomali ini akan diperbaiki oleh FabricInsight.
Contoh lain adalah degradasi bertahap dari modul komunikasi optik (kehilangan kinerja), sebelum kegagalan. Degradasi menentukan ketidakstabilan transmisi, yang dalam jangka waktu lama dapat mengindikasikan perlunya penggantian awal peralatan. Tetapi untuk mengidentifikasi ini dengan pendekatan standar sangat sulit.

Sebagai jawaban untuk masalah ini, antarmuka FabricInsight menampilkan status semua modul optik dalam sistem bersama dengan perkiraan probabilitas kegagalannya.

Integrasi
Meskipun FabricInsight muncul di pasar Rusia pada bulan Januari tahun ini, itu telah digunakan di ICBC, China UnionPay, China Merchants Bank, PICC dan pusat data besar lainnya berdasarkan infrastruktur Huawei.
Sejauh ini, solusinya hanya mendukung sakelar kami (pada chipset Broadcom), tetapi di masa depan ia direncanakan untuk melampaui ekosistem satu pabrikan. Juga, ketika mengerjakan FabricInsight, kami awalnya berfokus pada standar terbuka sehingga kami bisa berteman dengan alat pihak ketiga secara normal. Misalnya, Druid dapat digunakan untuk mengekspor data dari FabricInsight, di mana Anda dapat mengirim informasi ke visualisator pihak ketiga. FabricInsight juga sudah terintegrasi dengan alat rendering terbuka Grafana.
Secara umum, alat AIOps seperti FabricInsight kami adalah cara logis untuk mengembangkan alat pemantauan dan pemeliharaan infrastruktur. Tampaknya bagi kami bahwa ini adalah satu-satunya cara untuk terus mematuhi SLA untuk layanan.