Halo, Habr!
Nama saya Anton Markelov, saya seorang insinyur ops di United Traders. Kami terlibat dalam proyek dengan satu atau lain cara yang terkait dengan investasi, pertukaran dan masalah keuangan lainnya. Kami bukan perusahaan yang sangat besar, sekitar 30 insinyur pengembangan, timbangannya sesuai - sedikit kurang dari seratus server. Selama pertumbuhan kuantitatif dan kualitatif infrastruktur kami, solusi klasik “kami menyimpan aplikasi dan databasenya di server yang sama” tidak lagi sesuai dengan kami dalam hal keandalan dan kecepatan. Pada bagian analis, ada kebutuhan untuk membuat pertanyaan lintas-basis data, departemen operasi sudah bosan bermain-main dengan cadangan dan memantau sejumlah besar server database. Selain itu, menyimpan status pada mesin yang sama dengan aplikasi itu sendiri sangat mengurangi fleksibilitas perencanaan sumber daya dan ketahanan infrastruktur.
Proses transisi ke arsitektur saat ini adalah evolusi, berbagai solusi diuji baik untuk menyediakan antarmuka yang nyaman bagi pengembang dan analis, dan untuk meningkatkan keandalan dan pengelolaan seluruh ekonomi ini. Saya ingin berbicara tentang tahap-tahap utama modernisasi DBMS kami, apa yang telah kami lakukan dan keputusan apa yang kami ambil, sebagai akibatnya, lingkungan independen yang toleran terhadap kesalahan yang menyediakan cara interaksi yang nyaman bagi para insinyur operasi, pengembang dan analis. Saya berharap pengalaman kami akan bermanfaat bagi para insinyur dari perusahaan skala kami.
Artikel ini adalah ringkasan dari
laporan saya di konferensi UPTIMEDAY, mungkin format video akan lebih nyaman bagi seseorang, meskipun penulisnya sedikit lebih baik dengan tangan saya daripada pembicara mulut.
"Manusia Kepingan Salju" dengan KDPV
dipinjam tanpa malu-malu dari Maxim Dorofeev.
Penyakit pertumbuhan
Kami memiliki arsitektur microservice, layanan ditulis terutama di Jawa atau Kotlin menggunakan kerangka Spring. Di samping setiap microservice adalah basis PostgreSQL, semuanya ditutupi oleh nginx di atas untuk menyediakan akses. Layanan microser tipikal adalah aplikasi pada Boot Spring yang menulis datanya ke PostgreSQL (bagian dari aplikasi pada saat yang sama dan untuk ClickHouse), berkomunikasi dengan tetangga melalui Kafka dan memiliki beberapa titik akhir REST atau GraphQL untuk komunikasi dengan dunia luar.
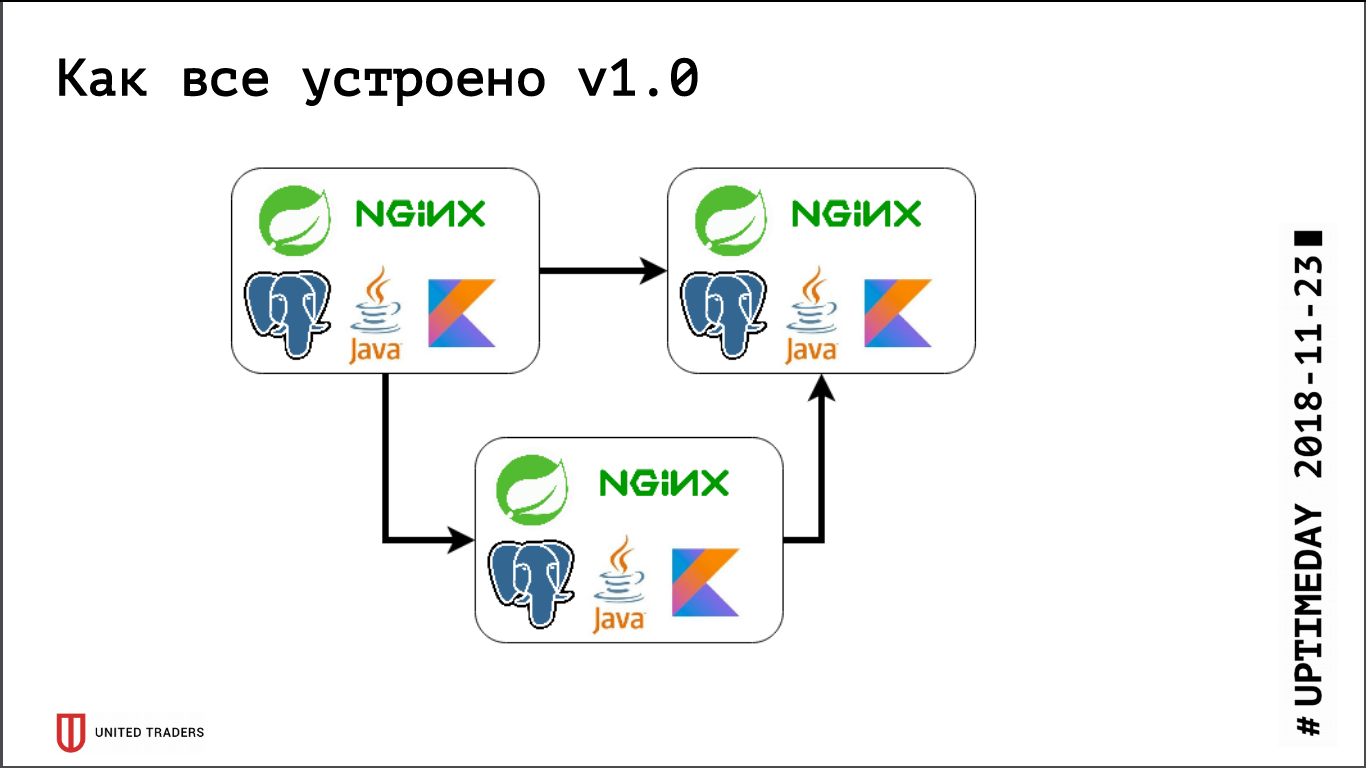
Sebelumnya, ketika kami masih sangat kecil, kami hanya menyimpan beberapa server di DigitalOcean, Kafka belum ada di sana, semua komunikasi dilakukan melalui REST. Artinya, kami mengambil tetesan, menginstal Java, PostgreSQL, nginx di sana, meluncurkan Zabbix di sana sehingga memonitor sumber daya server dan ketersediaan titik akhir layanan. Mereka mengerahkan segala sesuatu dengan bantuan Ansible, kami memiliki buku pedoman standar, empat hingga lima peran diluncurkan seluruh layanan. Selama kami memiliki, secara relatif, 6 server pada produksi dan 3 pada tes - Anda entah bagaimana bisa hidup dengannya.
Kemudian fase pengembangan aktif dimulai, jumlah aplikasi bertambah, sepuluh layanan Microsoft berubah menjadi empat puluh, fungsionalitasnya mulai berubah, ditambah integrasi dengan sistem eksternal seperti CRM, situs klien dan sejenisnya muncul. Kami merasakan sakit pertama. Beberapa aplikasi mulai mengkonsumsi lebih banyak sumber daya, berhenti masuk ke server yang ada, kami mendapat tetesan, menyeret aplikasi bolak-balik, mengambil banyak tangan. Sangat menyakitkan - tidak ada yang suka pekerjaan mekanik bodoh, - Saya ingin memutuskan dengan cepat. Jadi kami langsung saja - kami hanya mengambil 3 server khusus yang besar alih-alih 10 tetesan awan. Ini menutup masalah untuk sementara waktu, tetapi menjadi jelas bahwa sudah waktunya untuk mencari opsi untuk beberapa jenis orkestrasi dan penyeimbangan ulang server. Kami mulai mencermati solusi seperti DC / OS dan Kubernetes, dan secara bertahap meningkatkan keahlian kami di bidang ini.
Sekitar waktu yang sama, kami memiliki departemen analitis, yang perlu secara teratur membuat permintaan yang sulit, menyiapkan laporan, memiliki dasbor yang indah, dan ini membuat kami kesakitan kedua. Pertama, analis banyak memuat pangkalan, dan kedua, mereka membutuhkan pertanyaan lintas basis data, karena setiap microservice menyimpan irisan data yang agak sempit. Kami menguji beberapa sistem, pada awalnya kami mencoba menyelesaikannya semua melalui replikasi tingkat-tabel (kembali ke PostgreSQL kesembilan, tidak ada replikasi logis di luar kotak), tetapi kerajinan yang dihasilkan berdasarkan pglogical, Presto, Slony-I dan Bucardo sepenuhnya tidak diatur. Sebagai contoh, pglogical tidak mendukung migrasi - versi baru dari microservice diluncurkan, struktur database berubah, Java sendiri mengubah struktur menggunakan Flyway, dan pada replika di pglogical semuanya perlu diubah secara manual. Kalau tidak, ada sesuatu yang hilang, atau itu terlalu sulit.
Budak super
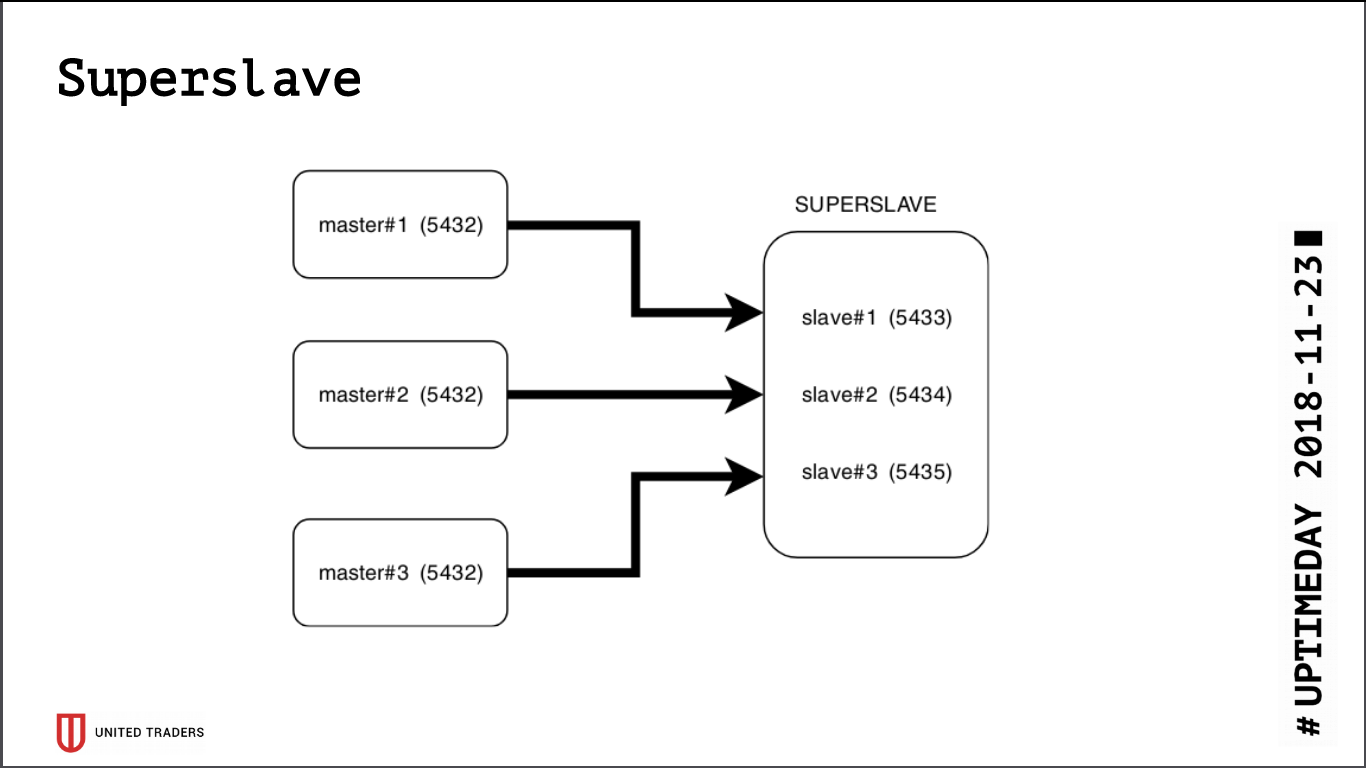
Sebagai hasil dari penelitian, lahirlah solusi sederhana dan brutal yang disebut Superslave: kami mengambil server terpisah, mengkonfigurasinya menjadi budak untuk setiap server produksi pada port yang berbeda, dan menciptakan basis data virtual yang menggabungkan basis data dari para budak melalui postgres_fdw (pembungkus data asing). Yaitu, semua ini dilaksanakan dengan cara standar postgres tanpa memperkenalkan entitas tambahan, secara sederhana dan andal: dengan satu permintaan, dimungkinkan untuk mendapatkan data dari beberapa basis data. Kami memberikan crossbase virtual ini kepada analis. Nilai tambah tambahan adalah bahwa replika hanya-baca, bahkan dengan kesalahan dengan hak akses, tidak dapat menulis apa pun di sana.
Kami mengambil
Redash untuk visualisasi, ia tahu cara menggambar grafik, menjalankan permintaan sesuai jadwal, misalnya, sekali sehari, dan memiliki sistem hak yang berat, jadi kami membiarkan analis dan pengembang pergi ke sana.

Secara paralel, pertumbuhan terus berlanjut, Kafka muncul di infrastruktur sebagai bus dan ClickHouse untuk penyimpanan analisis. Mereka mudah berkerumun di luar kotak, budak super kami dengan latar belakang mereka tampak seperti fosil canggung. Plus, PostgreSQL, pada kenyataannya, tetap menjadi satu-satunya negara yang perlu diseret setelah aplikasi (jika masih harus ditransfer ke server lain), dan kami benar-benar ingin mendapatkan aplikasi stateless untuk terlibat dalam eksperimen dengan Kubernetes dan dia platform serupa.
Kami mulai mencari solusi yang memenuhi persyaratan berikut:
- toleransi kesalahan: ketika N server jatuh, gugus terus bekerja;
- untuk aplikasi, semuanya harus tetap seperti sebelumnya, tidak ada perubahan dalam kode;
- kemudahan penyebaran dan manajemen;
- lebih sedikit lapisan abstraksi di atas PostgreSQL biasa;
- idealnya, memuat penyeimbangan agar tidak semua permintaan masuk ke satu server;
- Idealnya, ini ditulis dalam bahasa yang akrab.
Tidak banyak kandidat:
- replikasi streaming standar (repmgr, Patroni, Stolon);
- replikasi berbasis pemicu (Londiste, Slony);
- replikasi kueri lapisan tengah (pgpool-II);
- replikasi sinkron dengan beberapa server inti (Bucardo).
Dengan sebagian besar, kami sudah memiliki pengalaman buruk selama pembangunan crossbase, sehingga Patroni dan Stolon tetap. Patroni ditulis dalam Python, Stolon in Go, kami memiliki keahlian yang cukup dalam kedua bahasa. Selain itu, mereka memiliki arsitektur dan fungsionalitas yang serupa, sehingga pilihan dibuat untuk alasan subyektif: Patroni dikembangkan oleh Zalando, dan kami pernah mencoba untuk bekerja dengan proyek Nakadi mereka (API REST untuk Kafka), di mana kami menemukan kurangnya dokumentasi.
Stolon
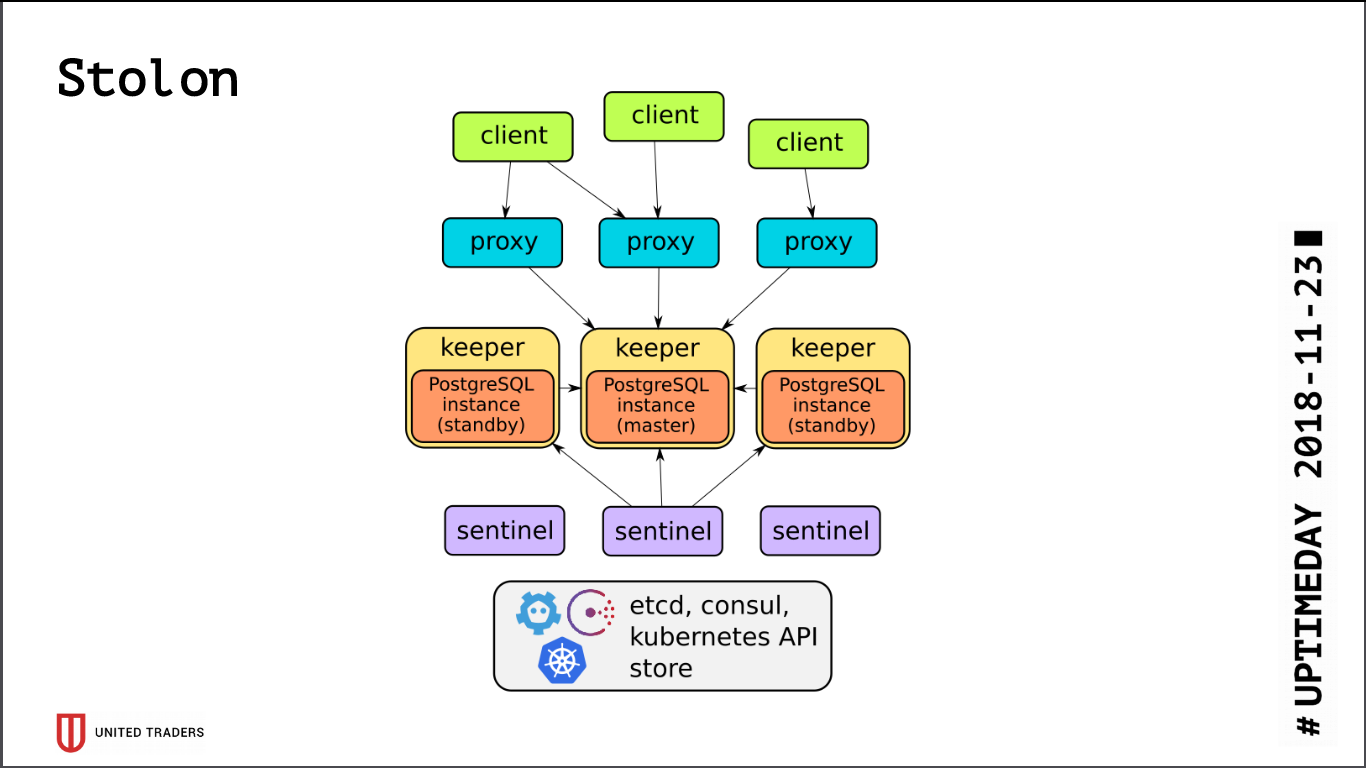
Arsitektur
Stolon cukup sederhana: ada N server, dengan bantuan etcd / consul pemimpin dipilih, PostgreSQL diluncurkan di dalamnya dalam mode wizard dan direplikasi ke server lain. Kemudian proksi stolon pergi ke master PostgreSQL ini, berpura-pura menjadi aplikasi dengan postgres biasa, dan klien pergi ke proksi ini. Dalam hal hilangnya master, pemilihan ulang dilakukan, orang lain menjadi master, sisanya menjadi siaga. Ada beberapa lapisan abstraksi, PostgreSQL diinstal seperti biasa, satu-satunya peringatan adalah bahwa konfigurasi PostgreSQL disimpan di etcd, dan dikonfigurasi agak berbeda.
Saat menguji cluster, kami menemukan beberapa masalah:
- Stolon tidak tahu cara bekerja di atas ZooKeeper, hanya konsul atau etcd;
- etcd sangat sensitif terhadap IO. Jika Anda menyimpan PostgreSQL dan etcd di server yang sama, Anda pasti membutuhkan SSD cepat;
- bahkan pada SSD perlu untuk mengkonfigurasi timeout etcd, jika tidak semuanya akan rusak di bawah beban - cluster akan berpikir bahwa master telah jatuh dan terus-menerus memutuskan koneksi;
- Secara default, max_connections pada PostgreSQL kecil (200), Anda perlu meningkatkannya sesuai kebutuhan Anda;
- sekelompok tiga etcd akan selamat dari kematian hanya satu server, idealnya Anda perlu memiliki konfigurasi, misalnya 5 etcd + 3 Stolon;
- di luar kotak, semua koneksi menuju ke master, budak tidak dapat diakses ke koneksi.
Karena semua koneksi ke PostgreSQL masuk ke wizard, kami kembali mengalami masalah dengan permintaan analitik yang berat. etcd kadang-kadang dengan susah payah bereaksi terhadap beban tinggi pada master dan mengubahnya. Dan beralih wizard selalu memutus koneksi. Permintaan telah dimulai kembali, semuanya dimulai dari awal lagi. Untuk solusinya,
sebuah skrip Python ditulis yang meminta alamat stolonctl dari budak hidup dan menghasilkan konfigurasi untuk HAProxy, mengarahkan permintaan kepada mereka.
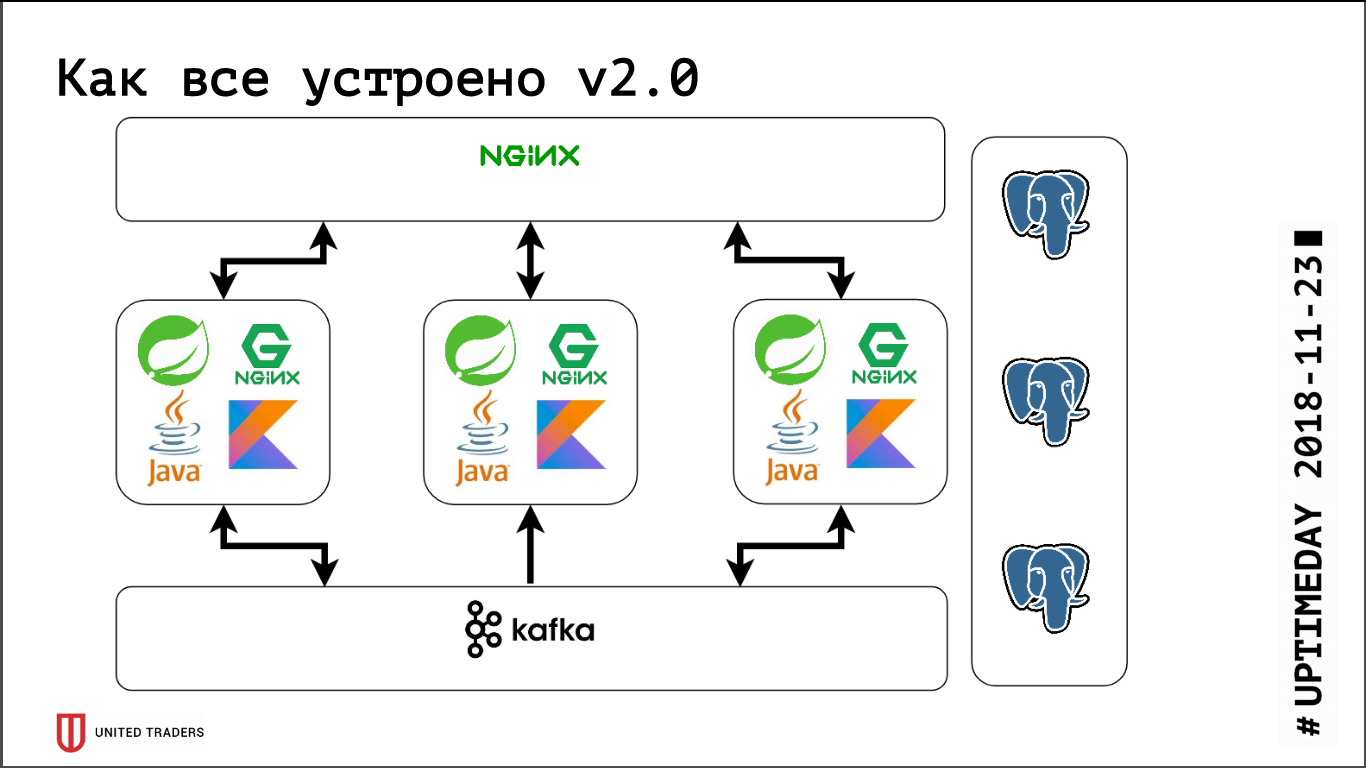
Gambaran berikut ternyata: permintaan dari aplikasi pergi ke porta stolon-proxy, yang mengarahkan mereka ke master, dan permintaan dari analis (mereka selalu hanya-baca) pergi ke port HAProxy, yang melemparkannya ke beberapa budak.
Juga, secara harfiah hari ini, PR diadopsi di Stolon, yang memungkinkan pengiriman informasi tentang contoh Stolon ke penemuan layanan pihak ketiga.
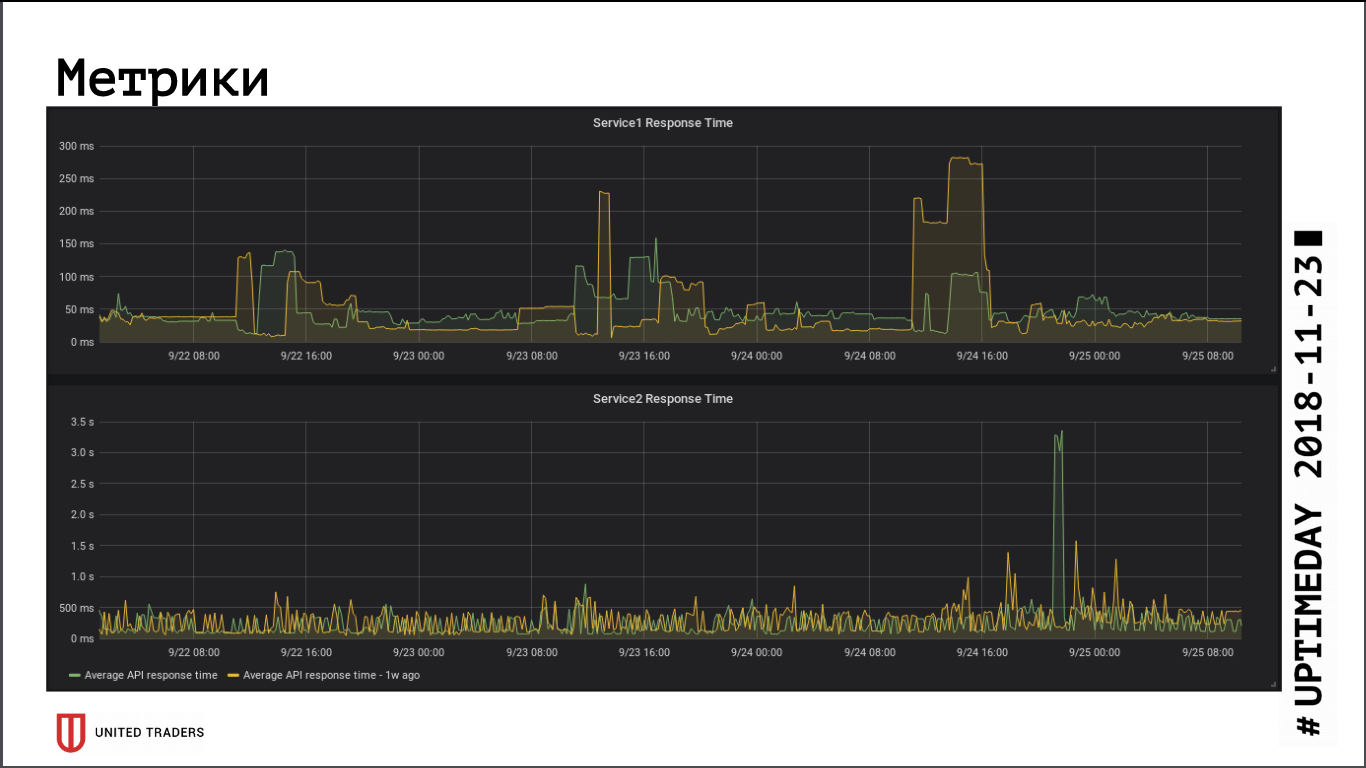
Sejauh dilihat dari metrik kecepatan respons aplikasi, transisi ke cluster jarak jauh tidak memiliki dampak signifikan pada kinerja, waktu respons rata-rata tidak berubah. Latensi jaringan yang dihasilkan, tampaknya, dikompensasi oleh fakta bahwa database sekarang berada di server khusus.
Stolon tanpa masalah selamat dari penyihir crash (kehilangan server, kehilangan jaringan, kehilangan disk), ketika server menjadi hidup - secara otomatis me-reset replika. Titik terlemah di Stolon adalah etcd, kegagalan di dalamnya menempatkan cluster. Kami mengalami kecelakaan yang khas: sekelompok tiga node dll, dua ditebang. Semuanya, kuorumnya rusak, dll berubah menjadi tidak sehat, gugus Stolon tidak menerima koneksi apa pun, termasuk permintaan dari stolonctl. Skema pemulihan: ubah etcd di server yang masih hidup menjadi satu simpul tunggal, kemudian tambahkan anggota kembali. Kesimpulan: untuk bertahan dari kematian dua server, Anda harus memiliki setidaknya 5 instance etcd.
Memantau dan menangkap kesalahan
Dengan pertumbuhan infrastruktur dan kompleksitas layanan-layanan mikro, saya ingin mengumpulkan lebih banyak informasi tentang apa yang terjadi di dalam aplikasi dan mesin Java. Kami tidak dapat mengadaptasi Zabbix dengan lingkungan baru: sangat tidak nyaman dalam kondisi infrastruktur yang berubah. Saya harus menggiling kruk melalui API-nya, atau naik ke dalam dengan tangan saya, yang bahkan lebih buruk. Basis datanya kurang beradaptasi dengan beban berat, dan secara umum sangat tidak nyaman untuk memasukkan semua ini ke dalam basis data relasional.
Akibatnya, kami memilih Prometheus untuk pemantauan. Dia memiliki aktuator di luar kotak untuk aplikasi Spring untuk menyediakan metrik, untuk Kafka mereka mengacaukan JMX Eksportir, yang juga menyediakan metrik dengan cara yang nyaman. Para eksportir yang tidak ditemukan "di dalam kotak", kami menulis sendiri dengan Python, ada sekitar sepuluh dari mereka. Kami memvisualisasikan Grafana, mengumpulkan log dengan Graylog (karena dia sekarang mendukung Beats).
Kami menggunakan
Sentry untuk mengumpulkan kesalahan. Dia menulis semuanya dalam bentuk terstruktur, menggambar grafik, menunjukkan apa yang terjadi lebih sering, lebih jarang. Biasanya, pengembang segera pergi ke Sentry segera setelah penyebaran, melihat apakah ada puncak, atau sangat perlu digulung kembali. Ternyata dengan cepat menangkap kesalahan tanpa mengambil log.
Itu saja untuk saat ini, jika format artikel sesuai dengan pembaca, kami akan terus berbicara tentang infrastruktur kami lebih lanjut, masih ada banyak kesenangan: Kafka dan solusi analitik untuk peristiwa yang melewatinya, saluran CI / CD untuk aplikasi Windows dan petualangan dengan Openshift.