Algoritma untuk rekomendasi, prediksi peristiwa atau penilaian risiko adalah keputusan tren di bank, perusahaan asuransi dan banyak sektor bisnis lainnya. Sebagai contoh, program-program ini membantu, berdasarkan analisis data, untuk memprediksi kapan klien akan mengembalikan pinjaman bank, apa yang akan menjadi permintaan ritel, apa kemungkinan kejadian yang diasuransikan atau arus keluar pelanggan di telekomunikasi, dll. Untuk bisnis, ini adalah peluang berharga untuk mengoptimalkan pengeluaran mereka, meningkatkan kecepatan kerja, dan umumnya meningkatkan layanan.
Namun, pendekatan tradisional seperti klasifikasi dan regresi tidak cocok untuk membangun program tersebut. Pertimbangkan masalah ini sebagai contoh kasus yang memprediksi episode medis: kami menganalisis nuansa dalam sifat data dan kemungkinan pendekatan untuk pemodelan, membangun model, dan menganalisis kualitasnya.
Tantangan memprediksi episode medis
Prediksi episode didasarkan pada analisis data historis. Dataset dalam hal ini terdiri dari dua bagian. Yang pertama adalah data layanan yang sebelumnya diberikan kepada pasien. Bagian dari dataset ini mencakup data sosio-demografis tentang pasien, seperti usia dan jenis kelamin, serta diagnosis yang dibuat kepadanya pada waktu yang berbeda dalam penyandian ICD10-CM [1] dan prosedur HCPCS yang dilakukan [2]. Data ini membentuk urutan dalam waktu yang memungkinkan Anda untuk mendapatkan gambaran tentang kondisi pasien pada saat menarik. Untuk model pelatihan, serta untuk bekerja dalam produksi, data yang dipersonalisasi sudah cukup.
Bagian kedua dari dataset adalah daftar episode yang terjadi untuk pasien. Untuk setiap episode, kami menunjukkan jenis dan tanggal kemunculannya, serta periode waktunya, termasuk layanan dan informasi lainnya. Dari data ini, variabel target untuk prediksi dihasilkan.
Aspek waktu adalah penting dalam masalah yang sedang dipecahkan: kita hanya tertarik pada episode yang mungkin muncul dalam waktu dekat. Di sisi lain, set data yang kami miliki dikumpulkan untuk periode waktu terbatas, di luar itu tidak ada data. Dengan demikian, kita tidak dapat mengatakan apakah episode terjadi di luar periode pengamatan, episode apa itu, pada saat yang tepat pada saat mereka muncul. Situasi ini disebut sensor benar.
Demikian pula, sensor kiri terjadi: untuk beberapa pasien, suatu episode mungkin mulai berkembang lebih awal daripada yang tersedia untuk pengamatan kami. Bagi kami, itu akan terlihat seperti sebuah episode yang muncul tanpa latar belakang apa pun.
Ada jenis lain dari sensor data - gangguan pengamatan (jika periode pengamatan tidak selesai dan acara belum terjadi). Misalnya, karena pasien bergerak, kegagalan dalam sistem pengumpulan data, dan sebagainya.
Dalam gbr. 1 secara skematis menunjukkan berbagai jenis sensor data. Semuanya mengubah statistik dan membuat pembangunan model menjadi sulit.
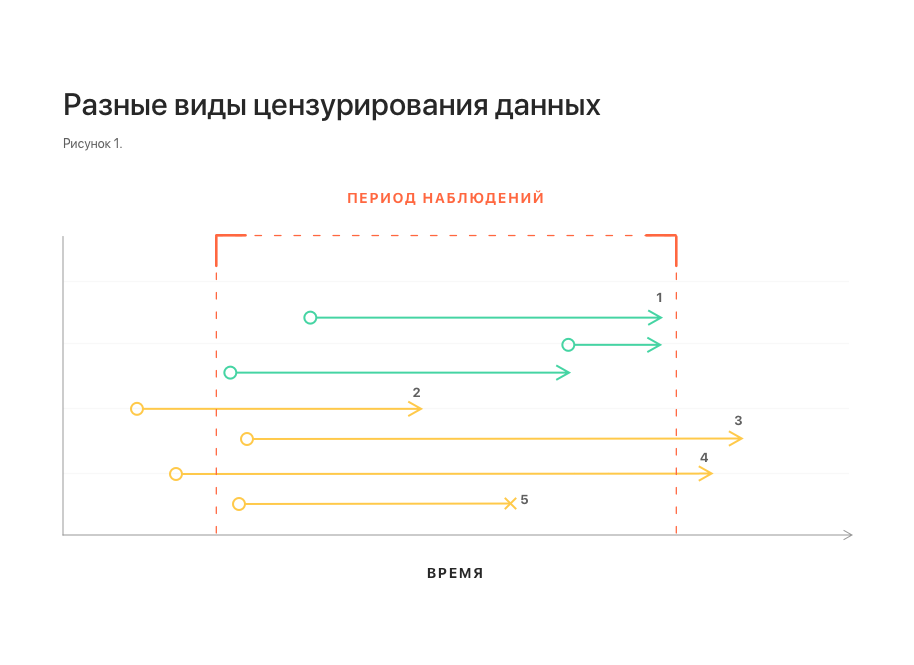 Catatan: 1 - pengamatan tanpa sensor; 2, 3 - sensor kiri dan kanan, masing-masing; 4 - sensor kiri dan kanan pada saat yang sama;
Catatan: 1 - pengamatan tanpa sensor; 2, 3 - sensor kiri dan kanan, masing-masing; 4 - sensor kiri dan kanan pada saat yang sama;
5 - gangguan pengamatan.Fitur penting lainnya dari dataset terkait dengan sifat aliran data dalam kehidupan nyata. Beberapa data mungkin datang terlambat, dalam hal ini mereka tidak tersedia pada saat prediksi. Untuk mempertimbangkan fitur ini, perlu untuk melengkapi dataset dengan melemparkan beberapa elemen dari ekor setiap urutan.
Klasifikasi dan Regresi
Secara alami, pemikiran pertama adalah untuk mengurangi masalah ke klasifikasi dan regresi yang terkenal. Namun, pendekatan ini menghadapi kesulitan yang serius.
Mengapa regresi tidak sesuai dengan kita, jelas dari fenomena yang dipertimbangkan sensor kanan dan kiri: distribusi waktu terjadinya suatu episode dalam dataset dapat digeser. Selain itu, besarnya dan fakta adanya bias ini tidak dapat ditentukan menggunakan dataset itu sendiri. Model yang dibangun dapat menunjukkan hasil yang baik secara sewenang-wenang dengan pendekatan validasi apa pun, tetapi ini, kemungkinan besar, tidak ada hubungannya dengan kesesuaiannya untuk peramalan pada data produksi.
Sekilas, yang lebih menjanjikan, adalah upaya untuk mengurangi masalah menjadi klasifikasi: untuk menetapkan periode waktu tertentu dan menentukan episode yang akan muncul pada periode ini. Kesulitan utama di sini adalah pengikatan interval waktu yang menarik bagi kami. Ini dapat dihubungkan dengan andal hanya pada saat pembaruan terakhir dari riwayat pasien. Pada saat yang sama, permintaan untuk prediksi episode tidak terikat pada waktu sama sekali dan dapat datang kapan saja, baik di dalam periode ini (dan kemudian periode bunga efektif diperpendek), dan sepenuhnya di luar itu - dan kemudian prediksi umumnya kehilangan maknanya (lihat Gambar. 2). Ini secara alami menginduksi peningkatan periode bunga, yang akhirnya mengurangi nilai prediksi.
 Catatan: 1 - memperbarui riwayat pasien; 2 - pembaruan terbaru dan rentang waktu yang terkait dengannya; 3, 4-episode permintaan prediksi diterima selama periode ini. Terlihat bahwa interval prediksi efektif untuk mereka kurang; 5 - permintaan diterima di luar interval. Baginya, prediksi tidak mungkin.
Catatan: 1 - memperbarui riwayat pasien; 2 - pembaruan terbaru dan rentang waktu yang terkait dengannya; 3, 4-episode permintaan prediksi diterima selama periode ini. Terlihat bahwa interval prediksi efektif untuk mereka kurang; 5 - permintaan diterima di luar interval. Baginya, prediksi tidak mungkin.Analisis kelangsungan hidup
Sebagai alternatif, kita dapat mempertimbangkan pendekatan ini, dalam literatur Rusia yang disebut analisis survival (analisis survival, atau analisis waktu-ke-peristiwa) [3]. Ini adalah keluarga model yang dirancang khusus untuk bekerja dengan data yang disensor. Ini didasarkan pada perkiraan fungsi risiko (fungsi bahaya, intensitas kejadian), yang memperkirakan distribusi probabilitas kejadian suatu peristiwa dari waktu ke waktu. Pendekatan ini memungkinkan Anda untuk memperhitungkan dengan tepat keberadaan berbagai jenis sensor.
Untuk masalah yang diselesaikan, pendekatan ini juga memungkinkan menggabungkan kedua aspek masalah dalam satu model: menentukan jenis episode dan memprediksi waktu terjadinya. Untuk melakukan ini, cukup membuat model terpisah untuk setiap jenis episode, mirip dengan pendekatan satu-lawan-semua dalam klasifikasi. Kemudian terjadinya episode non-target dapat diartikan sebagai pengecualian objek dari sampel yang diamati tanpa terjadinya suatu peristiwa, yang merupakan jenis lain dari sensor data dan juga diperhitungkan dengan benar oleh model. Penafsiran ini benar dari sudut pandang logika bisnis: jika seorang pasien menjalani operasi katarak, ini tidak mengecualikan terjadinya episode lain baginya di masa depan.
Di antara keluarga model untuk analisis survival, dua varietas dapat dibedakan: analitik dan regresi. Model analitik adalah murni deskriptif, mereka dibangun untuk seluruh populasi, tidak memperhitungkan fitur anggota individu, dan karena itu hanya dapat memprediksi terjadinya suatu peristiwa untuk beberapa anggota populasi yang khas. Tidak seperti analitis, model regresi dibangun dengan mempertimbangkan karakteristik anggota individu dari populasi dan memungkinkan perkiraan dibuat juga untuk anggota individu dengan mempertimbangkan karakteristik mereka. dalam masalah ini, variasi inilah yang digunakan, atau lebih tepatnya, model Proportional Hazard Cox (selanjutnya - CoxPH).
Regresi kelangsungan hidup dan operasi katarak
Pendekatan paling sederhana akan mirip dengan regresi konvensional: anggap ekspektasi matematis dari waktu dimulainya peristiwa sebagai hasilnya. Karena CoxPH menerima data sebagai vektor numerik pada input, dan dataset kami, pada kenyataannya, adalah urutan kode diagnosis dan prosedur (data kategorikal), diperlukan transformasi data awal:
- Penerjemahan kode menjadi representasi tertanam menggunakan model GloVe yang sebelumnya dilatih [4];
- Penggabungan semua kode yang tersedia dalam periode terakhir dari sejarah pasien menjadi satu vektor;
- Pengodean satu kali panas dari jenis kelamin pasien dan penskalaan usia.
Kami menggunakan vektor fitur yang diperoleh untuk pelatihan model dan validasinya. Model yang dihasilkan menunjukkan nilai indeks kesesuaian (indeks-c atau statistik-c) berikut: [5]:
- 0,71 untuk validasi 5 kali lipat;
- 0,69 pada sampel yang tertunda.
Ini sebanding dengan tingkat 0,6-0,7 biasa untuk model tersebut [6].
Namun, jika Anda melihat kesalahan absolut rata-rata antara perkiraan waktu terjadinya episode dan yang sebenarnya, ternyata kesalahan tersebut adalah 5 hari. Alasan untuk kesalahan besar adalah bahwa optimasi untuk c-index hanya menjamin urutan nilai yang benar: jika satu peristiwa terjadi lebih awal dari yang lain, maka nilai yang diperkirakan dari waktu yang diharapkan untuk acara akan masing-masing kurang dari yang lain. Selain itu, tidak ada pernyataan yang dibuat mengenai nilai yang diprediksi itu sendiri.
Varian lain yang mungkin dari nilai output model adalah tabel nilai fungsi risiko pada titik waktu yang berbeda. Opsi ini memiliki struktur yang lebih kompleks, lebih sulit untuk ditafsirkan daripada yang sebelumnya, tetapi pada saat yang sama memberikan lebih banyak informasi.
Mengubah format output memerlukan cara berbeda untuk menilai kualitas model: kita perlu memastikan bahwa untuk contoh positif (ketika suatu episode terjadi) tingkat risiko lebih tinggi daripada untuk contoh negatif (ketika sebuah episode tidak terjadi). Untuk melakukan ini, untuk setiap distribusi fungsi risiko yang diprediksi dalam sampel yang tertunda, kami akan beralih dari daftar nilai ke satu nilai - maksimum. Setelah menghitung nilai median untuk contoh positif dan negatif, kita akan melihat bahwa mereka berbeda secara andal: masing-masing 0,13 berbanding 0,04.
Selanjutnya, kami menggunakan nilai-nilai ini untuk membangun kurva ROC dan menghitung area di bawahnya - ROC AUC, yaitu 0,92, yang dapat diterima untuk masalah yang sedang dipecahkan.
Kesimpulan
Dengan demikian, kami melihat bahwa analisis survival adalah pendekatan terbaik untuk menyelesaikan masalah prediksi episode medis, dengan mempertimbangkan semua nuansa masalah dan data yang tersedia. Namun, aplikasinya menyiratkan format berbeda dari data keluaran model dan pendekatan yang berbeda untuk menilai kualitasnya.
Menerapkan model CoxPH untuk memprediksi episode operasi katarak memungkinkan kami untuk mencapai indikator kualitas model yang dapat diterima. Pendekatan serupa dapat diterapkan pada jenis episode lainnya, tetapi indikator kualitas spesifik model hanya dapat dievaluasi secara langsung dalam proses pemodelan.
Sastra
[1] Modifikasi Klinis ICD-10
en.wikipedia.org/wiki/ICD-10_Clinical_Modification[2] Sistem Pengodean Prosedur Umum Layanan Kesehatan
en.wikipedia.org/wiki/Healthcare_Common_Procedure_Coding_System[3] Analisis kelangsungan hidup
en.wikipedia.org/wiki/Survival_analysis[4] GloVe: Vektor Global untuk Representasi Kata
nlp.stanford.edu/projects/glove[5] C-Statistik: Definisi, Contoh, Bobot dan Signifikansi
www.statisticshowto.datasciencecentral.com/c-statistic[6] VC Raykar et al. Tentang Peringkat dalam Analisis Kelangsungan Hidup:
Terikat pada indeks Concordance
papers.nips.cc/paper/3375-on-ranking-in-survival-analysis-bounds-on-the-concordance-index.pdf