
Bagian 1/3 di sini .
Bagian 2/3 di sini .
Halo semuanya! Dan di sini adalah bagian ketiga dari Kubernet tentang panduan logam kosong! Saya akan memperhatikan pemantauan cluster dan pengumpulan log, kami juga akan meluncurkan aplikasi uji untuk menggunakan komponen-komponen cluster yang telah dikonfigurasi sebelumnya. Kemudian kita akan melakukan beberapa tes stres dan memeriksa stabilitas skema klaster ini.
Alat paling populer yang ditawarkan oleh komunitas Kubernetes untuk menyediakan antarmuka berbasis web dan mendapatkan statistik kluster adalah Kubernetes Dashboard . Bahkan, ini masih dalam pengembangan, tetapi bahkan sekarang dapat menyediakan beberapa data tambahan untuk pemecahan masalah aplikasi dan mengelola sumber daya cluster.
Topiknya sebagian kontroversial. Benarkah Anda memerlukan semacam antarmuka web untuk mengelola kluster, atau cukup menggunakan alat konsol kubectl ? Nah, terkadang opsi-opsi ini saling melengkapi.
Mari kita memperluas Dashboard Kubernet kita dan melihat. Dengan penerapan standar, dasbor ini hanya akan mulai di alamat host lokal. Dengan demikian, Anda perlu menggunakan perintah proksi kubectl untuk ekspansi , tetapi masih hanya tersedia di perangkat kontrol kubectl lokal Anda. Tidak buruk dari sudut pandang keamanan, tetapi saya ingin memiliki akses di browser, di luar cluster, dan saya siap untuk mengambil beberapa risiko (setelah semua, ssl dengan token yang efektif digunakan).
Untuk menerapkan metode saya, Anda perlu sedikit memodifikasi file penerapan standar di bagian layanan. Untuk membuka dasbor ini pada alamat terbuka, kami menggunakan penyeimbang beban kami.
Kami memasuki sistem mesin dengan utilitas kubectl yang dikonfigurasi dan membuat:
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
Kemudian jalankan:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
Seperti yang Anda lihat, BN kami menambahkan IP 192.168.0.240 untuk layanan ini. Sekarang coba buka https://192.168.0.240 untuk melihat Dasbor Kubernetes.
Ada 2 cara untuk mendapatkan akses: gunakan file admin.conf dari master node kami, yang kami gunakan sebelumnya saat mengatur kubectl, atau buat akun layanan khusus dengan token keamanan.
Mari kita buat pengguna admin:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
Sekarang Anda perlu token untuk masuk ke sistem:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
Salin token dan rekatkan ke bidang token pada layar login.
Setelah memasuki sistem, Anda dapat mempelajari klaster sedikit lebih dalam - Saya suka alat ini.
Langkah selanjutnya menuju pendalaman sistem pemantauan cluster kami adalah menginstal heapster .
Heapster memungkinkan Anda untuk memantau cluster kontainer dan menganalisis kinerja untuk Kubernetes (versi v1.0.6 dan lebih tinggi). Ini menawarkan platform yang tepat.
Alat ini menawarkan statistik tentang penggunaan cluster melalui konsol, dan juga menambahkan lebih banyak informasi tentang sumber daya simpul dan perapian ke Dashboard Kubernetes.
Ada sedikit kesulitan dengan menginstalnya pada bare metal, dan saya perlu melakukan beberapa penyelidikan: mengapa alat ini tidak berfungsi dalam versi aslinya, tetapi saya menemukan solusinya.
Jadi mari kita lanjutkan dan mendukung pengaya ini:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
Ini adalah file penyebaran standar paling umum dari komunitas Heapster, dengan hanya sedikit perbedaan: agar dapat bekerja di cluster kami, baris " source = " di penyebaran heapster diubah sebagai berikut:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
Dalam uraian ini Anda akan menemukan semua opsi ini. Saya mengubah port kubelet ke 10250 dan mematikan verifikasi sertifikat ssl (ada sedikit masalah dengan itu).
Kita juga perlu menambahkan izin untuk mendapatkan statistik simpul dalam peran Heapster RBAC; tambahkan beberapa baris ini di akhir peran:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
Singkatnya, peran RBAC Anda akan terlihat seperti ini:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
Ok, sekarang mari kita jalankan perintah untuk memastikan penyebaran heapster berhasil diluncurkan.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
Nah, jika Anda menerima beberapa data pada output, maka semuanya dilakukan dengan benar. Mari kembali ke halaman dasbor kami dan lihat grafik baru yang sekarang tersedia.
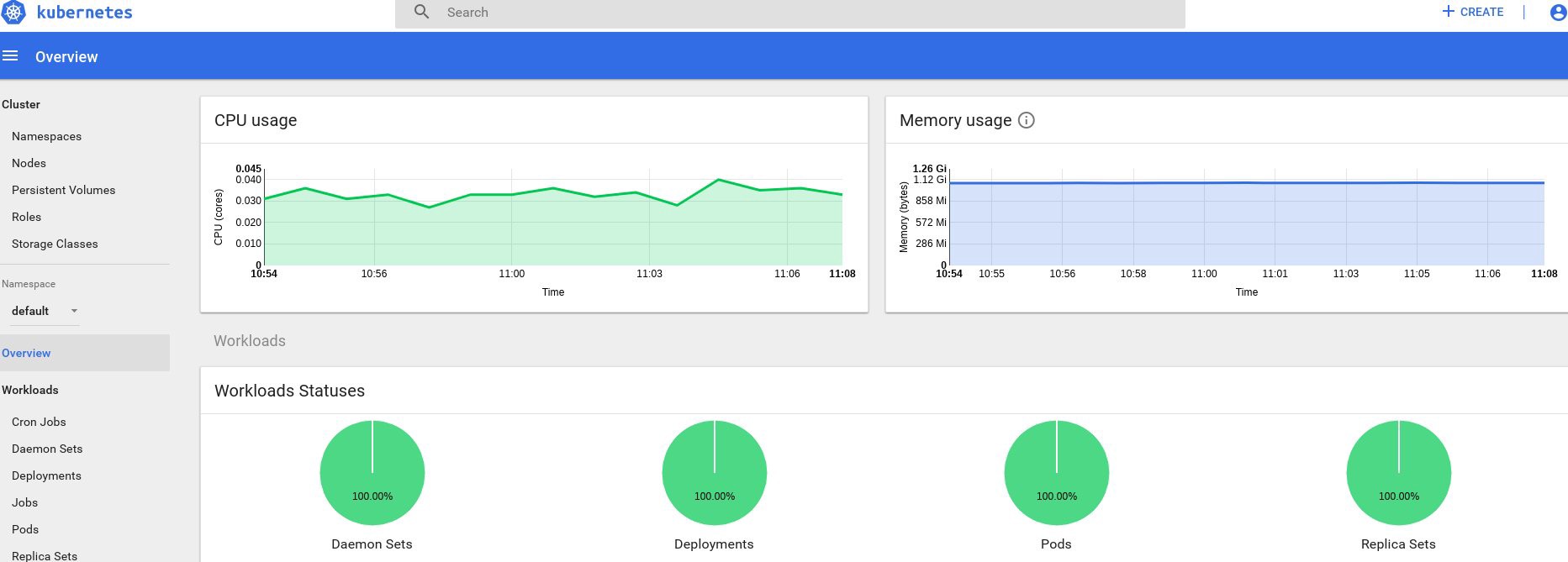

Mulai sekarang, kita juga dapat melacak penggunaan aktual sumber daya untuk node cluster, perapian, dll.
Jika ini tidak cukup, Anda dapat lebih meningkatkan statistik dengan menambahkan InfluxDB + Grafana. Ini akan menambah kemampuan untuk menggambar panel Grafana Anda sendiri.
Kami akan menggunakan versi instalasi InfluxDB + Grafana ini dari halaman Heapster Git, tetapi, seperti biasa, kami akan melakukan koreksi. Karena kami sudah mengonfigurasi penyebaran heapster, kami hanya perlu menambahkan Grafana dan InfluxDB, dan kemudian memodifikasi penyebaran heapster yang ada sehingga juga menempatkan metrik dalam Influx.
Ok, mari kita buat penyebaran InfluxDB dan Grafana:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
Berikutnya adalah Grafana, dan jangan lupa untuk mengubah pengaturan layanan untuk mengaktifkan penyeimbang beban MetaLB dan mendapatkan alamat IP eksternal untuk layanan Grafana.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
Dan buat mereka:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
Saatnya untuk mengubah penyebaran heapster dan menambahkan koneksi InfluxDB ke dalamnya; Anda perlu menambahkan hanya satu baris:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
Edit penyebaran heapster:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Sekarang temukan alamat IP eksternal dari layanan Grafana dan masuk ke sistem di dalamnya:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
Buka http://192.168.0.241 di browser, untuk pertama kalinya gunakan kredensial admin / admin:

Ketika saya masuk, Grafana saya kosong, tetapi, untungnya, kita bisa mendapatkan semua dasbor yang diperlukan dari grafana.com . Anda perlu mengimpor panel No. 3649 dan 3646. Saat mengimpor, pilih sumber data yang benar.
Setelah itu, pantau penggunaan sumber daya node dan perapian dan, tentu saja, buat dashboard unik Anda sendiri.
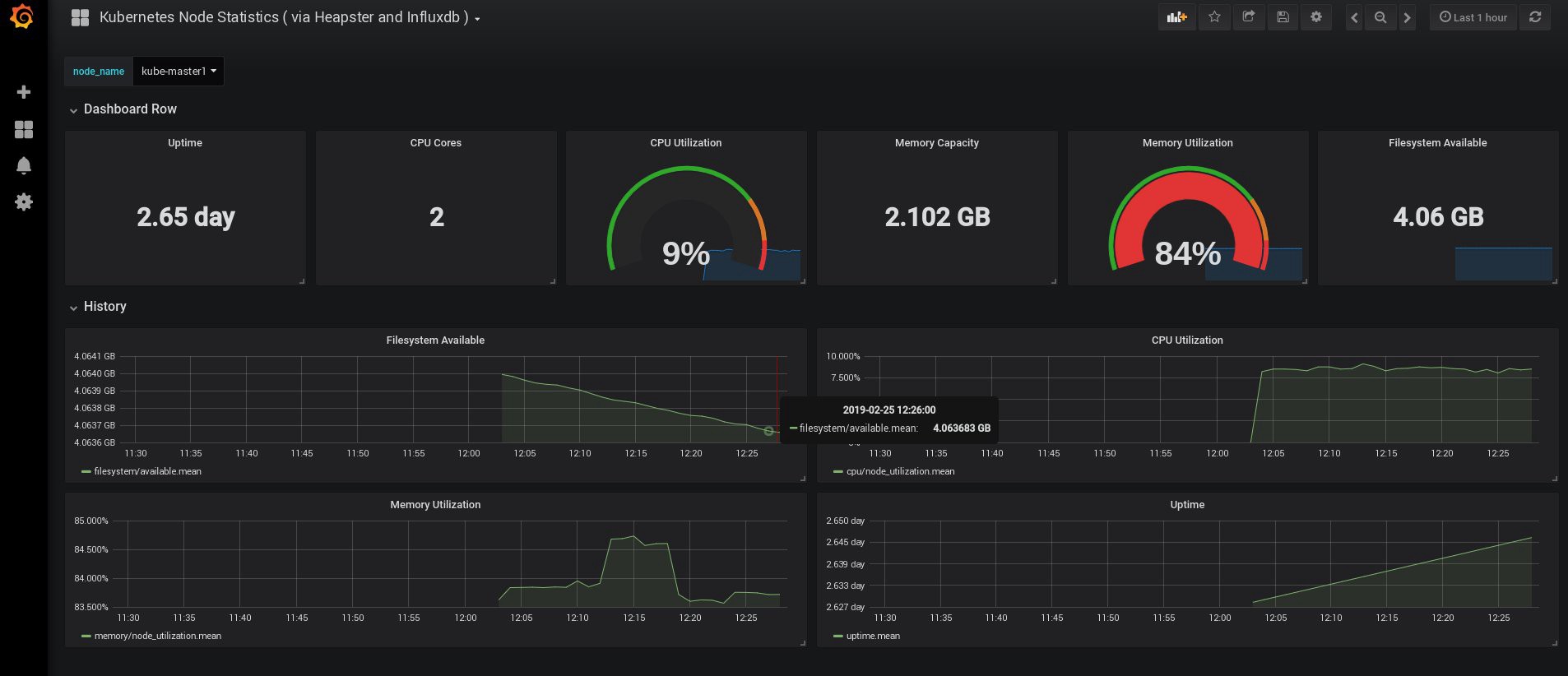
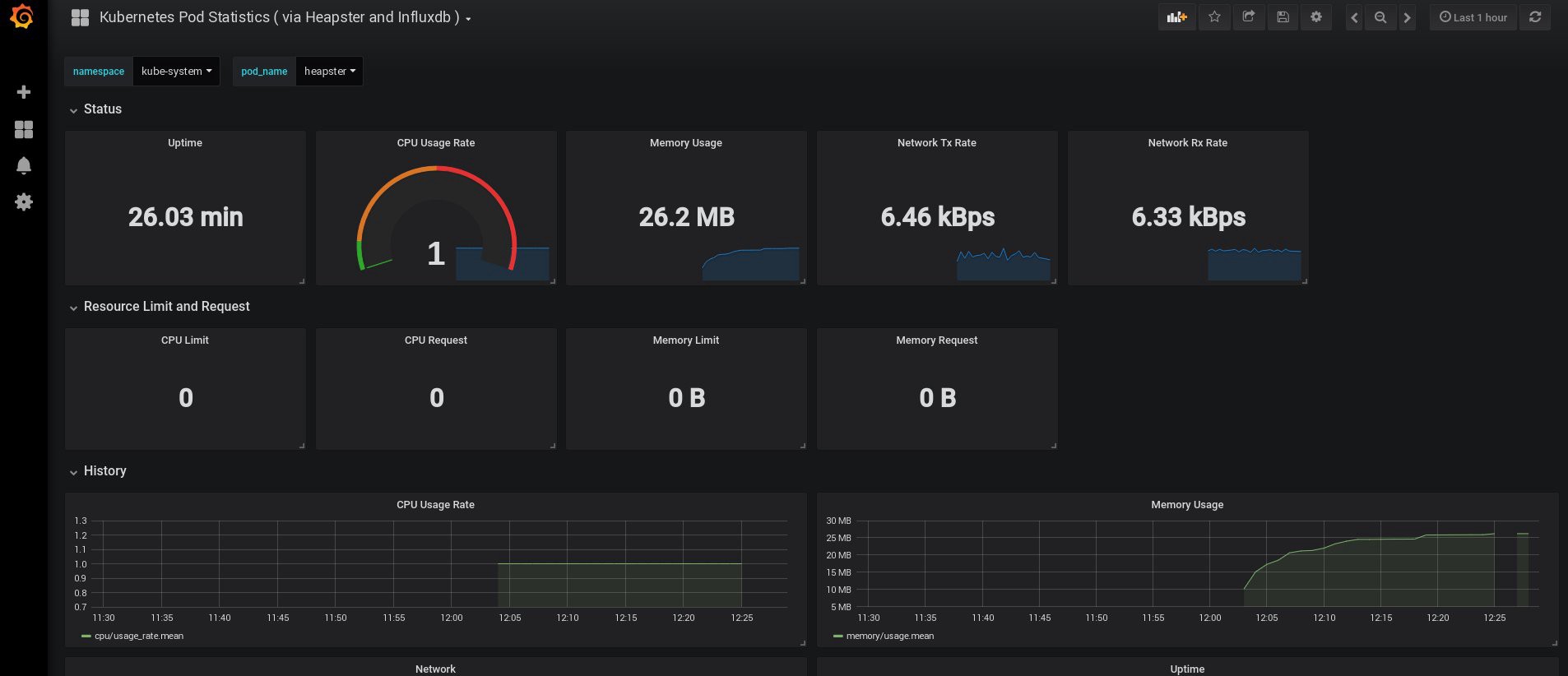
Nah, untuk sekarang, mari kita akhiri dengan pemantauan; Elemen-elemen berikut yang mungkin kita butuhkan adalah log untuk menyimpan aplikasi kita dan cluster. Ada beberapa cara untuk mengimplementasikan ini, dan semuanya dijelaskan dalam dokumentasi Kubernetes. Berdasarkan pengalaman saya sendiri, saya lebih suka menggunakan instalasi eksternal layanan Elasticsearch dan Kibana, serta hanya agen pendaftaran yang berjalan di setiap simpul kerja Kubernetes. Ini akan melindungi cluster dari kelebihan yang terkait dengan sejumlah besar log dan masalah lainnya, dan akan memungkinkan untuk menerima log, bahkan jika cluster menjadi sepenuhnya benar-benar tidak berfungsi.
Stack collection log yang paling populer untuk penggemar Kubernetes adalah Elasticsearch, Fluentd, dan Kibana (EFK stack). Dalam contoh ini, kita akan menjalankan Elasticsearch dan Kibana pada node eksternal (Anda dapat menggunakan stack ELK yang ada), serta Fluentd di dalam cluster kami sebagai daemonset untuk setiap node sebagai agen pengumpul log.
Saya akan melewatkan bagian tentang membuat VM dengan instalasi Elasticsearch dan Kibana; Ini adalah topik yang cukup populer, sehingga Anda dapat menemukan banyak materi tentang cara terbaik untuk melakukannya. Misalnya, di artikel saya. Hapus saja fragmen konfigurasi logstash dari file docker-compose.yml , dan hapus 127.0.0.1 dari bagian port elasticsearch.
Setelah itu, Anda harus memiliki penelitian elastics yang terhubung ke port VM-IP: 9200. Untuk keamanan tambahan, konfigurasikan login: pass atau kunci keamanan antara fluentd dan elasticsearch. Namun, saya sering melindunginya hanya dengan aturan iptables.
Yang masih harus dilakukan adalah membuat daemonset fluentd di Kubernetes dan menentukan node elasticsearch : port alamat eksternal dalam konfigurasi.
Kami menggunakan add-on Kubernetes resmi dengan konfigurasi yaml dari sini , dengan sedikit modifikasi:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
Kemudian kita akan membuat konfigurasi fluentd:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
Konfigurasi ini dasar, tetapi cukup untuk memulai dengan cepat; itu akan mengumpulkan log sistem dan aplikasi. Jika Anda memerlukan sesuatu yang lebih rumit, Anda dapat melihat dokumentasi resmi tentang konfigurasi fluentd dan konfigurasi Kubernetes.
Sekarang mari kita membuat daemonset fluentd di kluster kami:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
Pastikan semua pod fluentd dan sumber daya lainnya berjalan dengan sukses, lalu buka Kibana. Di Kibana, cari dan tambahkan indeks baru dari fluentd. Jika Anda menemukan sesuatu, maka semuanya dilakukan dengan benar, jika tidak, periksa langkah-langkah sebelumnya dan buat ulang daemonset atau edit configmap:

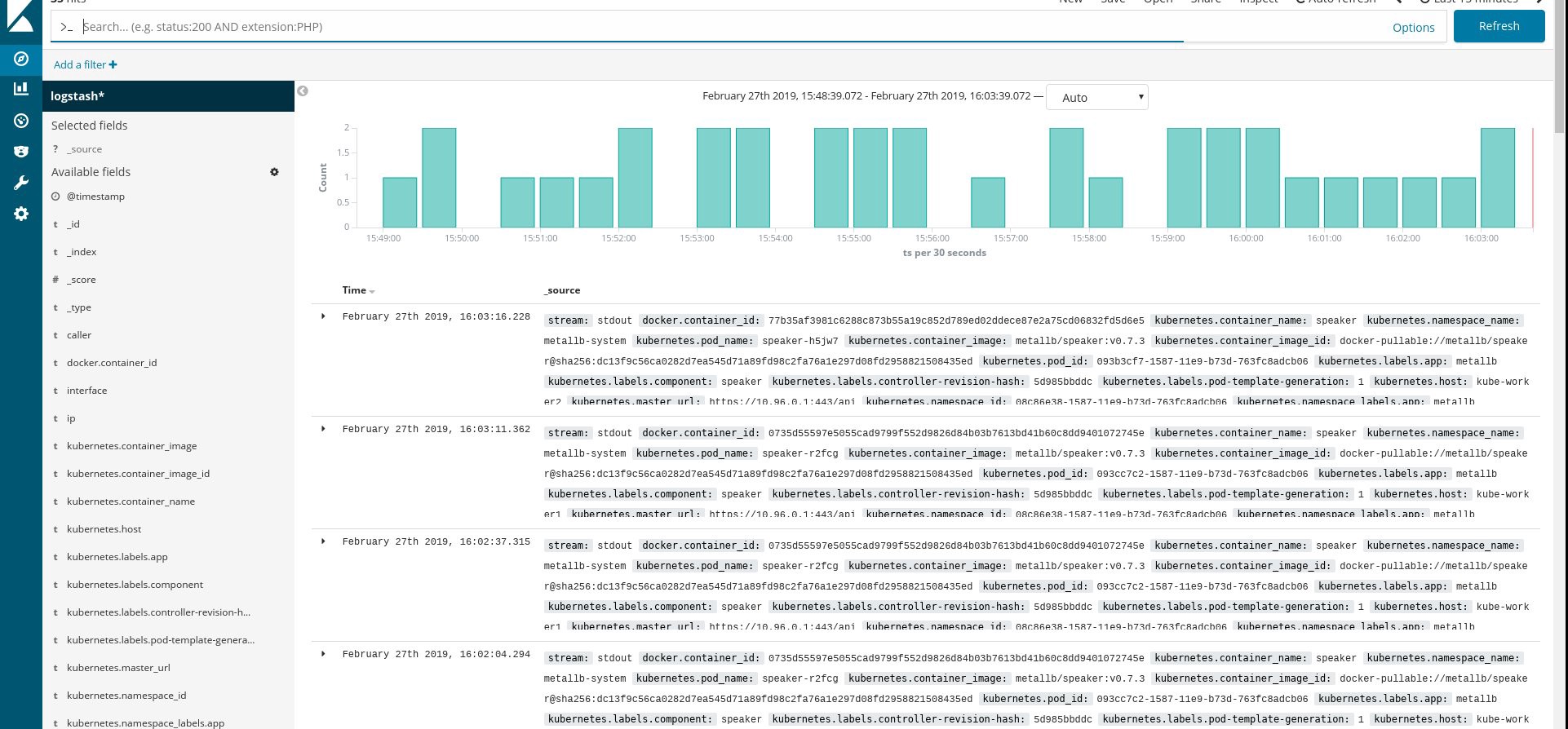
Nah, sekarang kita mendapatkan log dari cluster, Anda dapat membuat dasbor apa pun. Tentu saja, konfigurasi adalah yang paling sederhana, jadi Anda mungkin perlu mengubahnya sendiri. Tujuan utamanya adalah untuk menunjukkan bagaimana hal ini dilakukan.
Setelah menyelesaikan semua langkah sebelumnya, kami mendapatkan cluster Kubernetes yang benar-benar bagus dan siap digunakan. Sudah waktunya untuk memasukkan beberapa aplikasi pengujian ke dalamnya dan lihat apa yang terjadi.
Untuk contoh ini, ambil aplikasi Python / Flask Kubyk kecil saya, yang sudah memiliki wadah Docker, jadi ambil dari pendaftar yang terbuka. Sekarang kita akan menambahkan file database eksternal ke aplikasi ini - untuk ini kita akan menggunakan penyimpanan GlusterFS yang dikonfigurasi.
Pertama, kami membuat volume pvc baru untuk aplikasi ini (permintaan volume permanen), di mana kami akan menyimpan database SQLite dengan kredensial pengguna. Anda dapat menggunakan kelas memori yang sudah dibuat sebelumnya dari bagian 2 panduan ini.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
Setelah membuat PVC baru untuk aplikasi, kami siap untuk ditempatkan.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
Sekarang mari kita buat penyebaran dan layanan:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
Periksa alamat IP baru yang ditetapkan untuk layanan, serta status sub:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
Jadi, sepertinya kami telah berhasil meluncurkan aplikasi baru; jika kita membuka alamat IP http://192.168.0.242 di browser, kita akan melihat halaman login aplikasi ini. Anda dapat menggunakan kredensial admin / admin untuk masuk, tetapi jika kami mencoba masuk pada tahap ini, kami akan mendapatkan kesalahan karena belum ada database yang tersedia.
Berikut ini adalah contoh dari pesan kesalahan log dari perapian di dashboard Kubernetes:
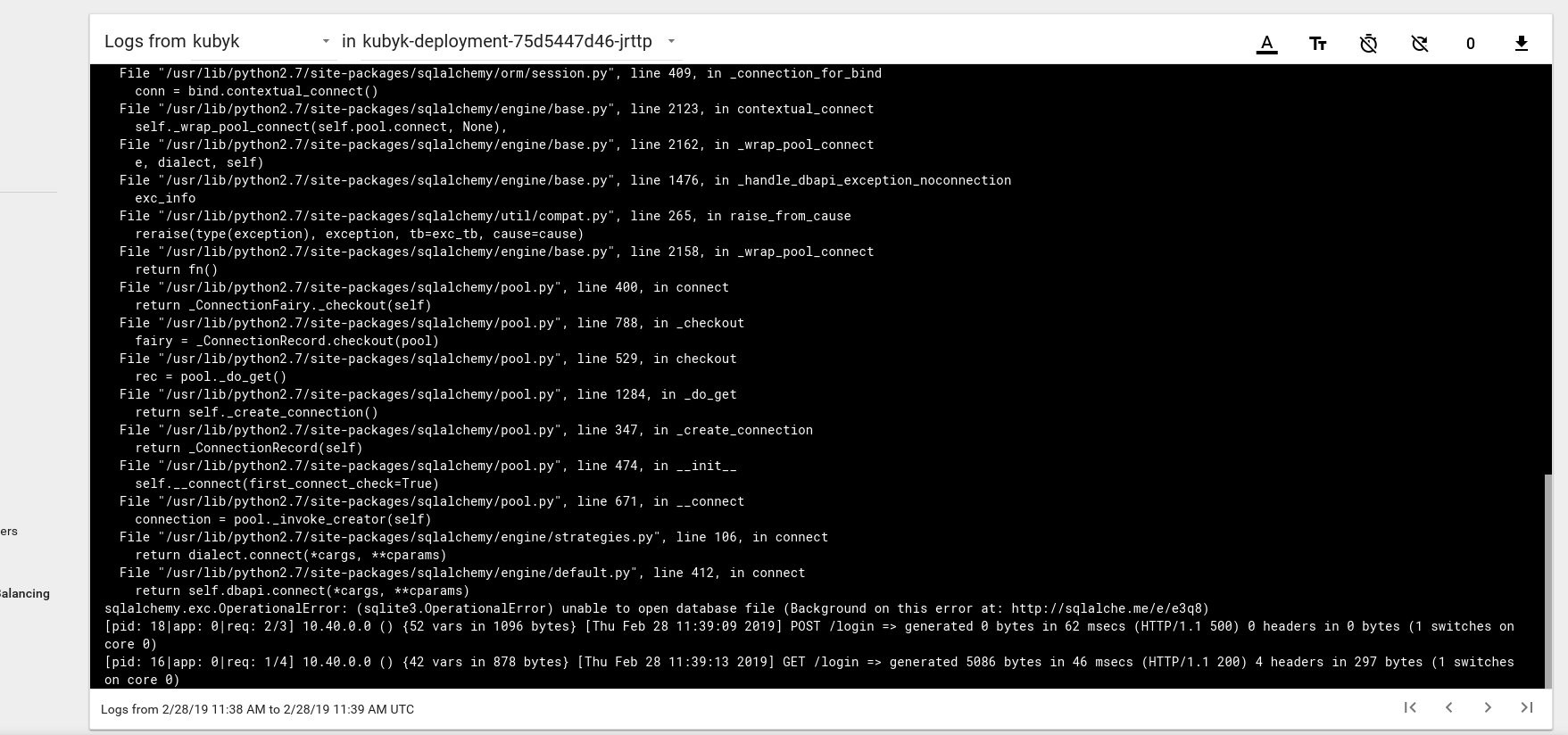
Untuk memperbaikinya, Anda perlu menyalin file SQlite DB dari repositori git saya ke volume pvc yang dibuat sebelumnya. Aplikasi akan mulai menggunakan basis data ini.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
Kami menggunakan bawah dari aplikasi dan perintah kubectl cp untuk menyalin file ini ke volume.
Anda juga harus memberikan akses tulis pengguna nginx ke direktori ini; aplikasi saya diluncurkan melalui pengguna nginx menggunakan supervisord .
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
Mari coba masuk lagi:
Hebat, sekarang aplikasi kita berfungsi dengan benar, dan kita dapat mengatur penyebaran kubyk menjadi 3 replika, misalnya, untuk meletakkan satu salinan aplikasi dalam satu simpul yang berfungsi. Karena kami sebelumnya membuat volume pvc, semua pod kami dengan replika aplikasi akan menggunakan database yang sama, dan layanan akan mendistribusikan lalu lintas di antara replika dengan cara siklik.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
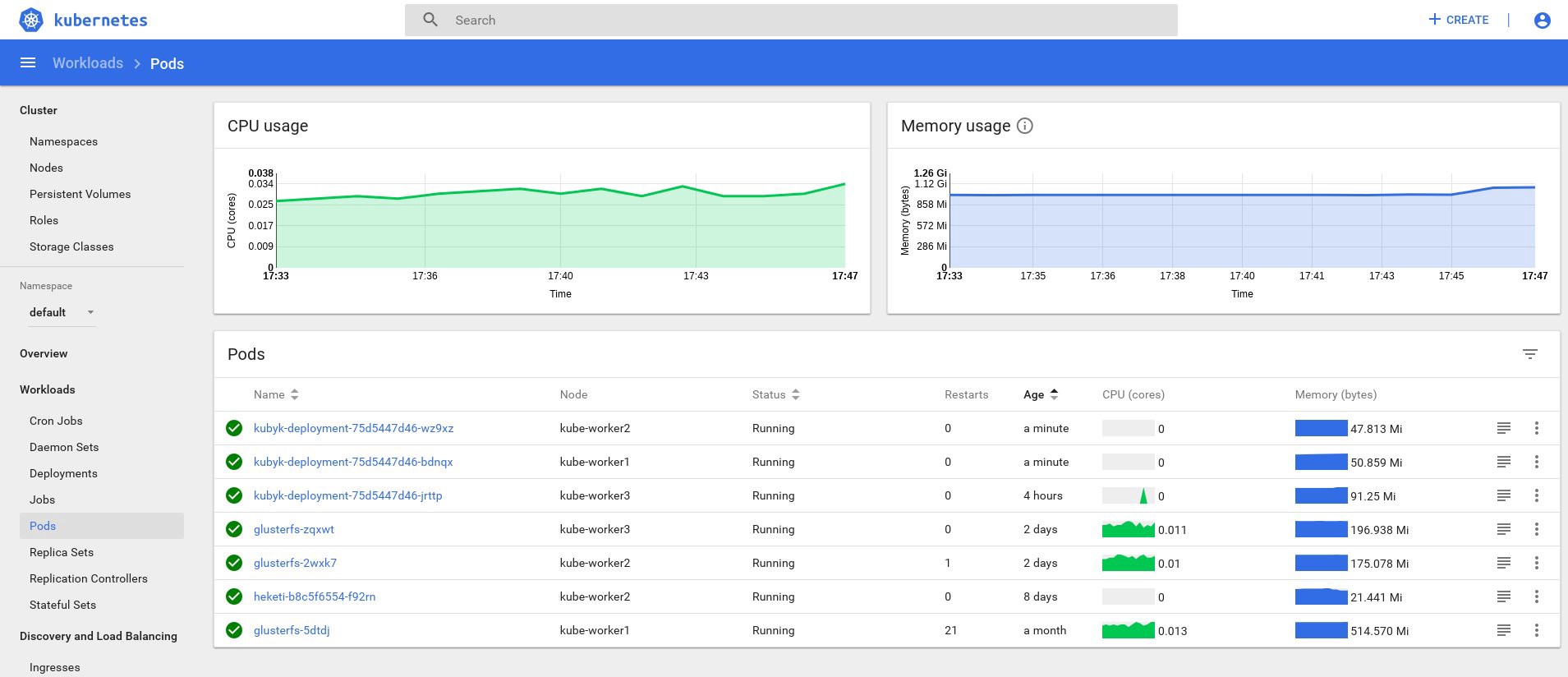
Sekarang kami memiliki replika aplikasi untuk setiap simpul yang berfungsi, sehingga aplikasi tidak akan berhenti bekerja jika kehilangan simpul apa pun. Selain itu, kami mendapatkan cara sederhana untuk menyeimbangkan beban, seperti yang saya katakan sebelumnya. Bukan tempat yang buruk untuk memulai.
Mari buat pengguna baru di aplikasi kita:
Semua permintaan baru akan diproses oleh perapian berikutnya dalam daftar. Ini dapat diperiksa oleh log dari perapian. Misalnya, pengguna baru dibuat oleh aplikasi dalam satu sub, lalu sub berikutnya menjawab permintaan berikutnya, dan seterusnya. Karena aplikasi ini menggunakan volume persisten tunggal untuk menyimpan database, semua data akan aman bahkan jika semua replika hilang.
Dalam aplikasi besar dan kompleks, Anda tidak hanya membutuhkan volume yang ditentukan untuk basis data, tetapi berbagai volume untuk mengakomodasi informasi yang persisten dan banyak elemen lainnya.
Yah, kita hampir selesai. Anda dapat menambahkan lebih banyak aspek, karena Kubernetes adalah topik yang banyak dan dinamis, tetapi kami akan berhenti di situ. Tujuan utama dari rangkaian artikel ini adalah untuk menunjukkan cara membuat cluster Kubernet Anda sendiri, dan saya harap informasi ini bermanfaat bagi Anda.
PS
Pengujian stabilitas dan tes stres, tentu saja.
Diagram klaster dari contoh kami berfungsi tanpa 2 node yang berfungsi, 1 node master, dan 1 node dll. Jika Anda ingin, nonaktifkan mereka dan periksa apakah aplikasi tes akan berfungsi.
Dalam menyusun panduan ini, saya menyiapkan kluster produksi untuk skema yang hampir serupa. Suatu kali, setelah membuat sebuah cluster dan telah menyebarkan aplikasi ke dalamnya, saya mengalami kegagalan daya besar; benar-benar semua server cluster dipotong - mimpi buruk yang hidup dari administrator sistem. Beberapa server dimatikan untuk waktu yang lama, dan kemudian terjadi kesalahan sistem file. Tetapi peluncuran kembali sangat mengejutkan saya: kluster Kubernetes sepenuhnya pulih. Semua volume dan penyebaran GlusterFS diluncurkan. Bagi saya, ini adalah demonstrasi potensi besar dari teknologi ini.
Semua yang terbaik dan, saya harap, sampai jumpa lagi!