Jaringan saraf convolutional melakukan pekerjaan yang sangat baik untuk mengklasifikasikan gambar yang terdistorsi, tidak seperti manusia.

Dalam artikel ini saya akan menunjukkan mengapa jaringan neural dalam yang canggih dapat dengan sempurna mengenali gambar yang terdistorsi dan bagaimana ini membantu mengungkapkan strategi yang sangat sederhana yang digunakan oleh jaringan saraf untuk mengklasifikasikan foto-foto alami. Penemuan ini, yang
diterbitkan dalam ICLR 2019, memiliki banyak konsekuensi: pertama, mereka menunjukkan bahwa jauh lebih mudah untuk menemukan solusi "
ImageNet " daripada yang diperkirakan. Kedua, mereka membantu kami menciptakan sistem klasifikasi gambar yang lebih mudah dipahami dan dimengerti. Ketiga, mereka menjelaskan beberapa fenomena yang diamati dalam jaringan saraf convolutional modern (SNA), misalnya, kecenderungan mereka untuk mencari tekstur (lihat
karya kami yang lain di ICLR 2019 dan
entri blog yang sesuai), dan mengabaikan penataan ruang bagian-bagian dari objek.
Model lama yang bagus "kantong kata-kata"
Di masa lalu yang indah, sebelum munculnya pembelajaran yang mendalam, pengenalan gambar alami cukup sederhana: kami mendefinisikan serangkaian fitur visual utama ("kata-kata"), menentukan seberapa sering setiap fitur visual muncul dalam gambar ("tas"), dan mengklasifikasikan gambar berdasarkan ini angka. Oleh karena itu, model seperti itu dalam visi komputer disebut "bag of words" (bag-of-words atau BoW). Sebagai contoh, misalkan kita memiliki dua fitur visual, mata manusia dan pena, dan kami ingin mengklasifikasikan gambar menjadi dua kelas, "orang" dan "burung". Model BoW yang paling sederhana adalah sebagai berikut: untuk setiap mata yang ditemukan dalam gambar, kami meningkatkan kesaksian yang mendukung "orang" dengan 1. Dan sebaliknya, untuk setiap pena kami menambah kesaksian yang mendukung "burung" dengan 1. Kelas mana yang mendapatkan lebih banyak bukti, ini dia.
Sifat yang mudah digunakan dari model BoW yang sederhana adalah interpretabilitas dan kejelasan proses pengambilan keputusan: kita dapat dengan tepat memeriksa fitur tertentu dari gambar yang mendukung kelas tertentu, integrasi spasial fitur sangat sederhana (dibandingkan dengan integrasi fitur non-linear dalam jaringan saraf yang dalam), oleh karena itu cukup pahami bagaimana model membuat keputusannya.
Model BoW tradisional sangat populer dan bekerja sangat baik sebelum invasi pembelajaran yang mendalam, tetapi dengan cepat keluar dari mode karena efisiensi yang relatif rendah. Tetapi apakah kita yakin bahwa jaringan saraf menggunakan strategi keputusan yang berbeda secara fundamental dari BoW?
Kedalaman Menafsirkan Jaringan dengan Fitur-fitur Tas (BagNet)
Untuk menguji asumsi ini, kami menggabungkan interpretabilitas dan kejelasan model BoW dengan efisiensi jaringan saraf. Strateginya terlihat seperti ini:
- Bagilah gambar menjadi potongan-potongan kecil qx q.
- Kami melewati potongan melalui jaringan saraf untuk mendapatkan bukti keanggotaan kelas (log) untuk masing-masing bagian.
- Ringkaslah bukti di semua bagian untuk mendapatkan solusi di tingkat keseluruhan gambar.
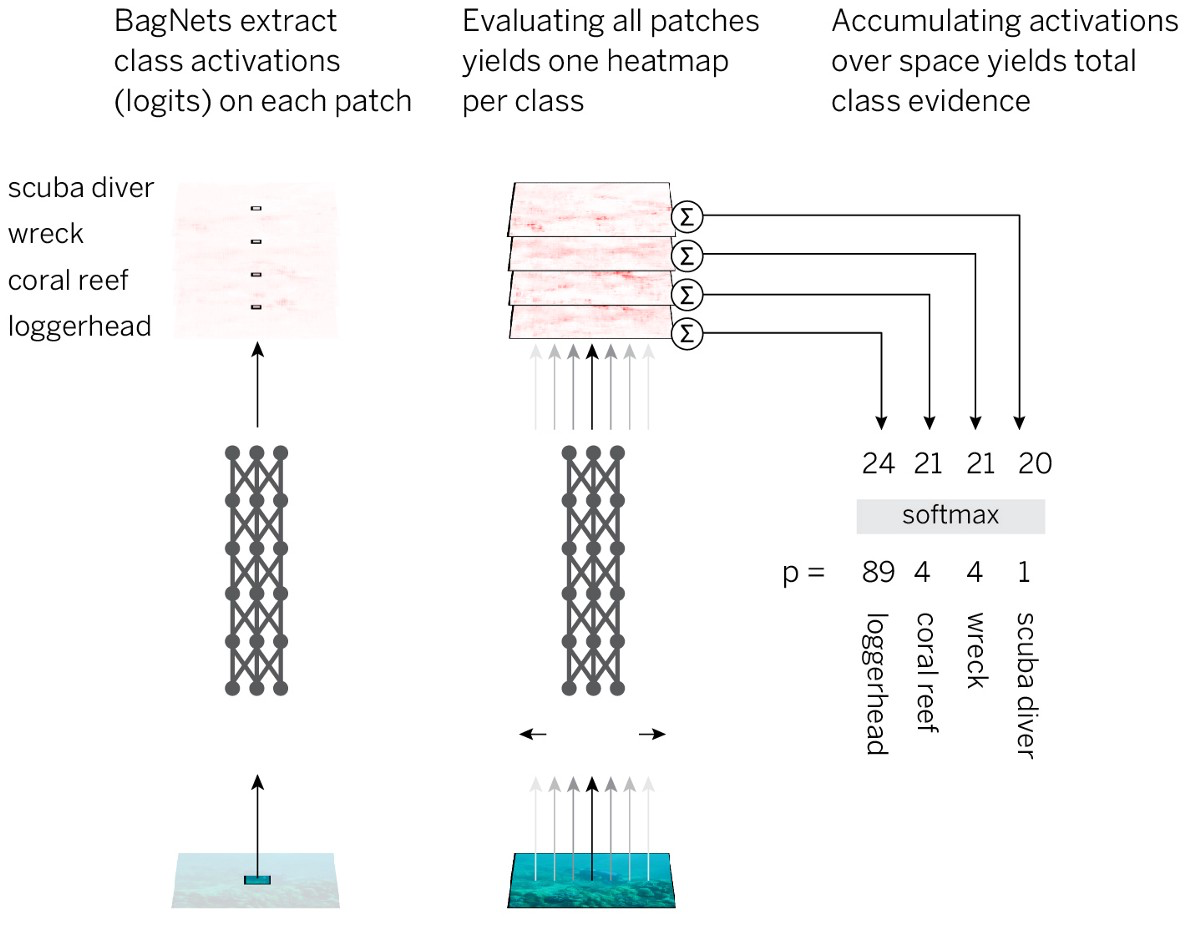
Untuk menerapkan strategi ini, dengan cara paling sederhana, kami menggunakan arsitektur standar ResNet-50 dan mengganti hampir semua konvolusi 3x3 dengan konvolusi 1x1. Akibatnya, setiap elemen tersembunyi di lapisan convolutional terakhir "melihat" hanya sebagian kecil dari gambar (yaitu, bidang persepsi mereka jauh lebih kecil dari ukuran gambar). Jadi kami menghindari markup yang dikenakan gambar dan sedekat mungkin dengan SNA standar, sambil menerapkan strategi yang telah direncanakan. Kami menyebut arsitektur yang dihasilkan BagNet-q, di mana q menunjukkan ukuran bidang persepsi lapisan paling atas (kami menguji model dengan q = 9, 17, dan 33). BagNet-q beroperasi sekitar 2,5 lebih lama dari ResNet-50.
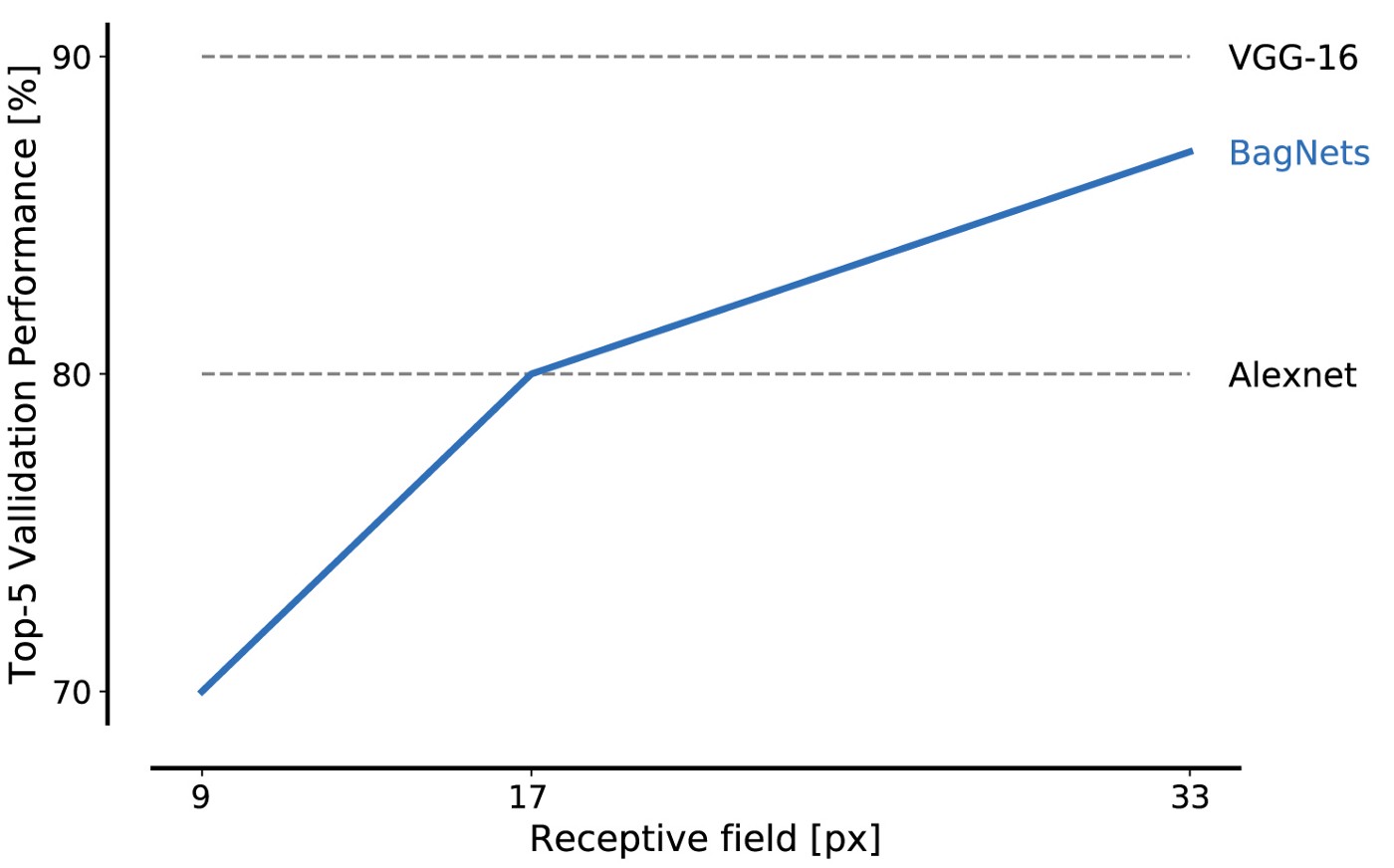
Kinerja BagNet pada data dari basis data ImageNet sangat mengesankan bahkan ketika menggunakan potongan-potongan kecil: fragmen 17x17 piksel sudah cukup untuk mencapai efisiensi tingkat AlexNet, dan fragmen 33x33 piksel cukup untuk mencapai akurasi 87%, memasuki posisi ke-5. Anda dapat meningkatkan efisiensi dengan menempatkan paket 3x3 lebih hati-hati dan menyesuaikan hyperparameter.
Ini adalah hasil utama pertama kami: ImageNet dapat diselesaikan hanya dengan menggunakan serangkaian fitur gambar kecil. Hubungan spasial yang jauh dari bagian-bagian komposisi, seperti bentuk benda atau interaksi antara bagian-bagian objek, dapat sepenuhnya diabaikan; mereka sama sekali tidak diperlukan untuk menyelesaikan masalah.
Fitur luar biasa dari BagNet'ov adalah transparansi sistem pengambilan keputusan mereka. Misalnya, Anda dapat mengetahui fitur gambar apa yang paling khas untuk kelas tertentu. Misalnya, tench, ikan besar, biasanya dikenali oleh gambar jari-jari pada latar belakang hijau. Mengapa Karena pada sebagian besar foto dalam kategori ini ada seorang nelayan memegang piala sebagai trofi. Dan ketika BagNet salah mengenali gambar sebagai garis, ini biasanya terjadi karena di suatu tempat di foto ada jari pada latar belakang hijau.
 Bagian paling khas dari gambar. Baris atas di setiap sel sesuai dengan pengenalan yang benar, dan bagian bawah dengan fragmen yang mengganggu yang menyebabkan pengakuan yang salah
Bagian paling khas dari gambar. Baris atas di setiap sel sesuai dengan pengenalan yang benar, dan bagian bawah dengan fragmen yang mengganggu yang menyebabkan pengakuan yang salahKami juga mendapatkan "peta panas" yang tepat, yang menunjukkan bagian gambar mana yang berkontribusi pada keputusan.
 Heatmaps bukan perkiraan, mereka secara akurat menunjukkan kontribusi setiap bagian dari gambar.
Heatmaps bukan perkiraan, mereka secara akurat menunjukkan kontribusi setiap bagian dari gambar.BagNet menunjukkan bahwa Anda bisa mendapatkan akurasi tinggi dengan ImageNet hanya atas dasar korelasi statistik yang lemah antara fitur gambar lokal dan kategori objek. Jika ini cukup, lalu mengapa jaringan saraf standar ResNet-50 mempelajari sesuatu yang secara fundamental berbeda? Mengapa ResNet-50 harus mempelajari hubungan skala besar yang kompleks seperti bentuk objek, jika kelimpahan fitur lokal gambar cukup untuk menyelesaikan masalah?
Untuk menguji hipotesis bahwa SNA modern mematuhi strategi yang mirip dengan operasi jaringan BoW yang paling sederhana, kami menguji berbagai jaringan - ResNet, DenseNet, dan VGG pada "tanda" BagNet berikut:
- Solusi tidak tergantung pada pengocokan spasial dari fitur gambar (ini hanya dapat diperiksa pada model VGG).
- Modifikasi bagian gambar yang berbeda tidak boleh saling bergantung (dalam arti pengaruhnya terhadap keanggotaan kelas).
- Kesalahan yang dibuat oleh SNA standar dan BagNet'ami harus serupa.
- SNS dan BagNet standar harus peka terhadap fitur serupa.
Dalam keempat percobaan, kami menemukan perilaku yang mirip dari SNS dan BagNet. Misalnya, dalam percobaan terakhir, kami menunjukkan bahwa BagNet paling sensitif (jika, misalnya, mereka tumpang tindih) ke tempat yang sama dalam gambar seperti SNA. Bahkan, peta panas BagNet (peta sensitivitas spasial) lebih baik memprediksi sensitivitas DenseNet-169 daripada peta panas yang diperoleh dengan metode atribusi seperti DeepLift (penghitungan langsung peta panas untuk DenseNet-169). Tentu saja, SNA tidak persis mengulangi perilaku BagNet, tetapi beberapa penyimpangan menunjukkan. Secara khusus, semakin dalam jaringan, semakin besar ukuran fitur menjadi dan semakin jauh ketergantungan. Oleh karena itu, jaringan syaraf yang dalam memang merupakan peningkatan dari model-model BagNet, tetapi saya tidak berpikir bahwa dasar klasifikasi mereka entah bagaimana berubah.
Melampaui klasifikasi BoW
Mengamati pengambilan keputusan SNA dalam gaya strategi BoW dapat menjelaskan beberapa fitur aneh SNA. Pertama, ini menjelaskan mengapa SNA sangat
terikat dengan tekstur . Kedua, mengapa SNA tidak sensitif untuk
mencampur bagian-bagian gambar. Ini bahkan dapat menjelaskan keberadaan stiker permusuhan dan gangguan permusuhan: sinyal yang membingungkan dapat ditempatkan di mana saja pada gambar, dan SNS pasti akan menangkap sinyal ini, terlepas dari apakah itu sesuai dengan sisa gambar.
Bahkan, pekerjaan kami menunjukkan bahwa SNA, ketika mengenali gambar, menggunakan banyak undang-undang statistik yang lemah dan tidak melanjutkan untuk mengintegrasikan bagian-bagian gambar di tingkat objek, seperti yang dilakukan orang. Hal yang sama kemungkinan besar benar untuk tugas-tugas lain dan modalitas sensorik.
Kita perlu merencanakan arsitektur, tugas, dan metode pelatihan kita dengan hati-hati untuk mengatasi kecenderungan menggunakan korelasi statistik yang lemah. Salah satu pendekatan adalah menerjemahkan distorsi pelatihan SNA dari fitur lokal kecil ke fitur yang lebih global. Yang lain adalah untuk menghapus atau mengganti fitur-fitur yang seharusnya tidak mengandalkan jaringan saraf, yang kami lakukan dalam
publikasi lain untuk ICLR 2019, menggunakan preprocessing transfer gaya untuk menghilangkan tekstur objek alami.
Namun, salah satu masalah terbesar tetap klasifikasi gambar: jika fitur lokal cukup, tidak ada insentif untuk mempelajari "fisika" nyata dari dunia alami. Kita perlu merestrukturisasi tugas sedemikian rupa untuk menggerakkan model untuk mempelajari sifat fisik benda. Untuk melakukan ini, kemungkinan besar, Anda harus melampaui pengajaran pengamatan murni untuk korelasi data input dan output sehingga model dapat mengekstraksi hubungan sebab akibat.
Bersama-sama, hasil kami menunjukkan bahwa SNA dapat mengikuti strategi klasifikasi yang sangat sederhana. Fakta bahwa penemuan semacam itu dapat dilakukan pada tahun 2019 menekankan betapa sedikitnya kita masih memahami fitur internal dari kerja jaringan saraf yang dalam. Kurangnya pemahaman tidak memungkinkan kita untuk mengembangkan model dan arsitektur yang ditingkatkan secara fundamental yang menjembatani kesenjangan antara persepsi manusia dan mesin. Memperdalam pemahaman kita akan memungkinkan kita menemukan cara untuk mempersempit kesenjangan ini. Ini bisa sangat berguna: mencoba menggeser SNA ke arah sifat fisik benda, kami tiba-tiba mencapai
resistensi terhadap kebisingan di tingkat manusia. Saya mengharapkan munculnya sejumlah besar hasil menarik lainnya di jalur kami menuju pengembangan SNA, yang benar-benar memahami sifat fisik dan kausal dari dunia kita.