Saya penggemar berat semua yang dilakukan
Fabien Sanglard , saya suka blognya, dan saya membaca
kedua bukunya sampul depan (dijelaskan dalam
podcast Hansleminutes baru-baru ini).
Fabien baru-baru ini menulis posting yang bagus di mana dia
mendekripsi pelacak sinar
kecil , menghilangkan kode dan menjelaskan matematika dengan sangat indah. Saya sangat merekomendasikan meluangkan waktu untuk membaca ini!
Tapi itu membuat saya bertanya-tanya
apakah mungkin untuk mem-porting kode C ++ ini ke C # ? Karena saya harus menulis banyak C ++ di
pekerjaan utama saya belakangan ini, saya pikir saya bisa mencobanya.
Tetapi yang lebih penting, saya ingin mendapatkan ide yang lebih baik tentang
apakah C # adalah bahasa tingkat rendah ?
Pertanyaan yang sedikit berbeda, tetapi terkait: berapa banyak C # cocok untuk "pemrograman sistem"? Mengenai hal ini, saya sangat merekomendasikan
postingan bagus Joe Duffy mulai 2013 .
Port jalur
Saya mulai dengan hanya porting
kode C ++ deobfuscated baris demi baris ke C #. Itu cukup sederhana: tampaknya kebenaran masih dikatakan bahwa C # adalah C ++++ !!!
Contoh menunjukkan struktur data utama - 'vektor', di sini adalah perbandingan, C ++ di sebelah kiri, C # di kanan:

Jadi, ada beberapa perbedaan sintaksis, tetapi karena .NET memungkinkan Anda untuk menentukan
jenis nilai Anda sendiri , saya bisa mendapatkan fungsionalitas yang sama. Ini penting karena memperlakukan 'vektor' sebagai struktur berarti kita bisa mendapatkan "lokalitas data" yang lebih baik dan kita tidak perlu melibatkan pengumpul sampah .NET, karena data akan didorong ke tumpukan (ya, saya tahu ini adalah detail implementasi).
Untuk informasi lebih lanjut tentang
structs atau "tipe nilai" di .NET, lihat di sini:
Secara khusus, dalam posting terakhir Eric Lippert, kami menemukan kutipan yang sangat berguna yang memperjelas “tipe nilai” sebenarnya:
Tentu saja, fakta yang paling penting tentang jenis-jenis nilai bukanlah rincian implementasi, bagaimana mereka dialokasikan , melainkan makna semantik asli dari “tipe nilai”, yaitu, bahwa ia selalu disalin “berdasarkan nilai” . Jika informasi alokasi penting, kami akan menyebutnya "tipe tumpukan" dan "tipe tumpukan". Tetapi dalam kebanyakan kasus itu tidak masalah. Sebagian besar waktu, semantik penyalinan dan identifikasi relevan.
Sekarang mari kita lihat seperti apa beberapa metode lain dalam perbandingan (lagi C ++ di sebelah kiri, C # di kanan),
RayTracing(..) pertama
RayTracing(..) :
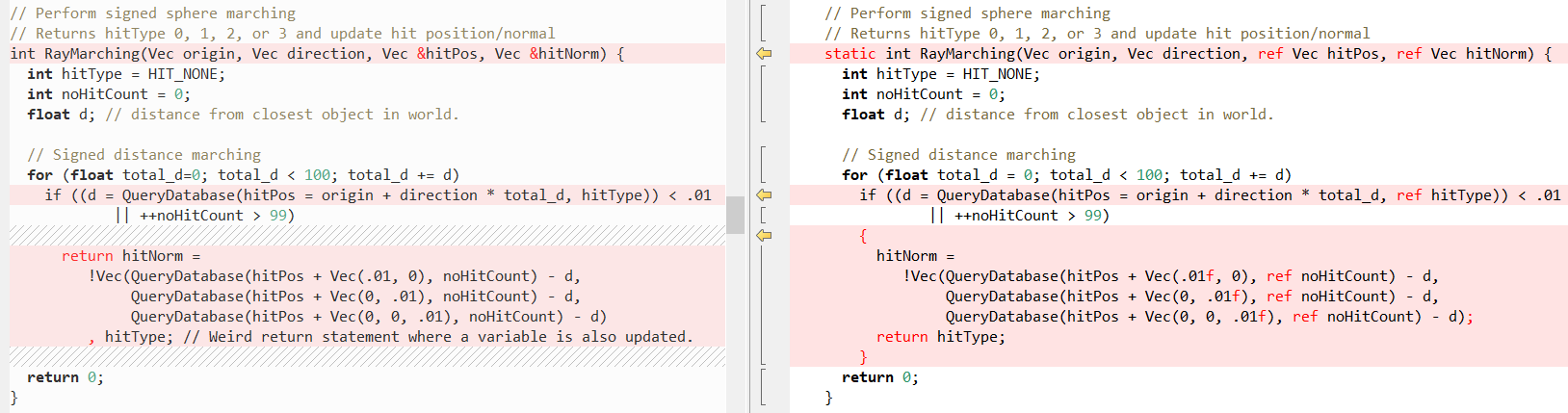
Kemudian
QueryDatabase (..) :
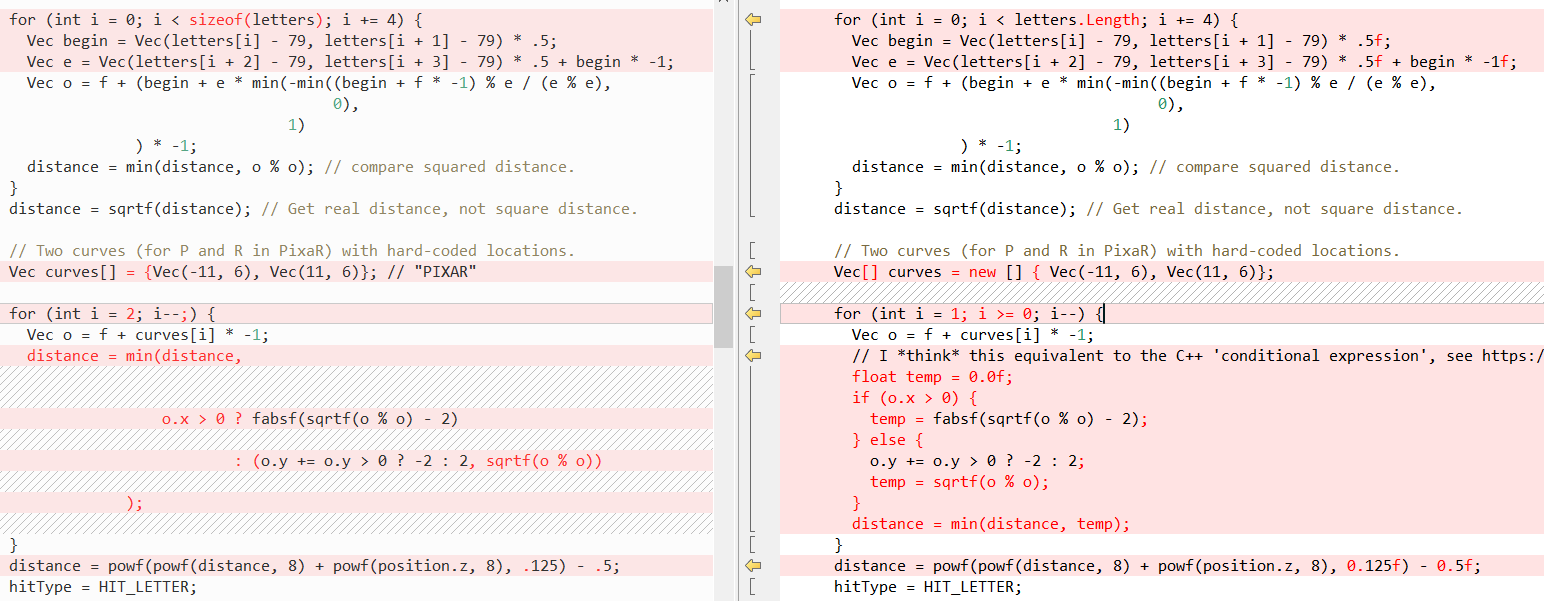
(lihat
posting Fabian untuk penjelasan tentang apa yang dilakukan kedua fungsi ini)
Tetapi sekali lagi, kenyataannya adalah bahwa C # membuatnya sangat mudah untuk menulis kode C ++! Dalam hal ini, kata kunci
ref paling membantu kami, yang memungkinkan kami memberikan
nilai dengan referensi . Kami telah menggunakan
ref dalam panggilan metode untuk beberapa waktu, tetapi baru-baru ini, upaya telah dilakukan untuk menyelesaikan
ref tempat lain:
Sekarang
kadang -
kadang menggunakan
ref akan meningkatkan kinerja, karena dengan demikian struktur tidak perlu disalin, lihat tolok ukur dalam
posting oleh Adam Stinix dan
“Perangkap kinerja ref lokal dan pengembalian ref dalam C #” untuk informasi lebih lanjut.
Tetapi yang paling penting adalah bahwa skrip semacam itu memberikan C # port kita dengan perilaku yang sama dengan kode sumber C ++. Meskipun saya ingin mencatat bahwa apa yang disebut "tautan terkelola" tidak persis sama dengan "petunjuk", khususnya, Anda tidak dapat melakukan aritmatika pada mereka, lihat lebih lanjut tentang ini di sini:
Performa
Dengan demikian, kode porting baik, tetapi kinerja juga penting. Terutama pada ray tracer, yang dapat menghitung frame selama beberapa menit. Kode C ++ berisi
sampleCount variabel, yang mengontrol kualitas gambar akhir, dengan
sampleCount = 2 sebagai berikut:

Jelas tidak terlalu realistis!
Tetapi ketika Anda mendapatkan
sampleCount = 2048 , semuanya terlihat
jauh lebih baik:

Tetapi memulai dengan
sampleCount = 2048 sangat memakan waktu, jadi semua proses lainnya dilakukan dengan nilai
2 untuk memenuhi setidaknya satu menit. Mengubah
sampleCount hanya memengaruhi jumlah iterasi dari loop kode terluar, lihat
intisari ini untuk penjelasan.
Hasil setelah port baris “naif”
Untuk membandingkan secara substansial C ++ dan C #, saya menggunakan alat
time-windows , ini adalah port dari perintah unix
time . Hasil awal terlihat seperti ini:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| Waktu (detik) | 47.40 | 80.14 | 78.02 |
| Dalam inti (dtk) | 0,14 (0,3%) | 0,72 (0,9%) | 0,63 (0,8%) |
| Di ruang pengguna (detik) | 43,86 (92,5%) | 73,06 (91,2%) | 70.66 (90.6%) |
| Jumlah kesalahan halaman kesalahan | 1143 | 4818 | 5945 |
| Perangkat Kerja (KB) | 4232 | 13 624 | 17 052 |
| Memori yang Diekstrusi (KB) | 95 | 172 | 154 |
| Memori non-preemptive | 7 | 14 | 16 |
| Swap File (KB) | 1460 | 10 936 | 11 024 |
Awalnya, kita melihat bahwa kode C # sedikit lebih lambat dari versi C ++, tetapi semakin baik (lihat di bawah).
Tapi pertama-tama mari kita lihat apa yang dilakukan oleh .NET JIT kepada kita bahkan dengan port baris demi baris yang “naif” ini. Pertama, ini melakukan pekerjaan yang baik dengan menanamkan metode pembantu yang lebih kecil. Ini dapat dilihat pada output alat
Inlining Analyzer yang sangat baik (hijau =
bawaan ):
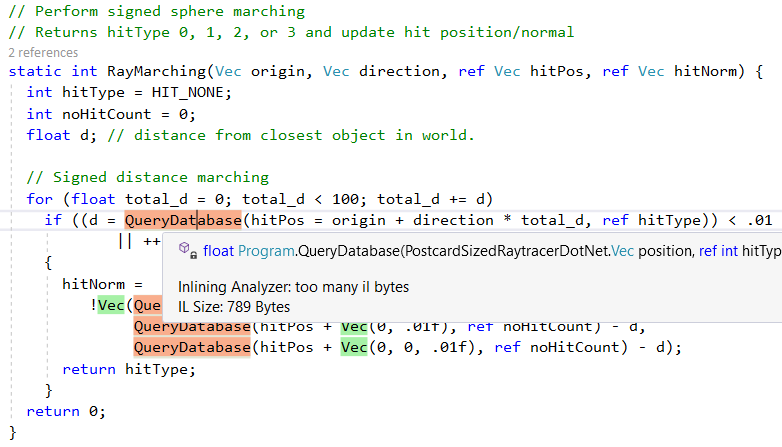
Namun, itu tidak menanamkan semua metode, misalnya, karena kompleksitas,
QueryDatabase(..) dilewati:
Fitur kompiler .NET Just-In-Time (JIT) lainnya adalah konversi panggilan metode khusus ke instruksi CPU yang sesuai. Kita dapat melihat ini beraksi dengan fungsi shell
sqrt , di sini adalah kode sumber C # (perhatikan panggilan ke
Math.Sqrt ):
Dan di sini adalah kode assembler yang dihasilkan oleh .NET JIT: tidak ada panggilan ke
Math.Sqrt dan instruksi prosesor
vsqrtsd digunakan :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(untuk mendapatkan masalah ini, ikuti
instruksi ini , gunakan
add-on "Disasmo" VS2019 atau lihat
SharpLab.io )
Penggantian ini juga dikenal sebagai
intrinsik , dan dalam kode di bawah ini kita dapat melihat bagaimana JIT menghasilkannya. Cuplikan ini hanya menunjukkan pemetaan untuk
AMD64 , tetapi JIT juga menargetkan
X86 ,
ARM dan
ARM64 , metode lengkap di
sini .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
Seperti yang Anda lihat, beberapa metode diimplementasikan seperti
Sqrt dan
Abs , sementara yang lain menggunakan fungsi runtime C ++, misalnya,
powf .
Seluruh proses ini dijelaskan dengan sangat baik dalam artikel
"Bagaimana Math.Pow () diimplementasikan dalam .NET Framework?" , itu juga dapat dilihat pada sumber CoreCLR:
Hasil setelah peningkatan kinerja sederhana
Saya ingin tahu apakah Anda dapat segera meningkatkan port line-by-port yang naif. Setelah membuat profil, saya membuat dua perubahan besar:
- Menghapus Inisialisasi Array Inline
- Mengganti fungsi
Math.XXX(..) dengan analog dari MathF.()
Perubahan ini dijelaskan secara lebih rinci di bawah ini.
Menghapus Inisialisasi Array Inline
Untuk informasi lebih lanjut tentang mengapa ini perlu, lihat
jawaban Stack Overflow yang luar biasa dari
Andrei Akinshin ini , bersama dengan kode benchmark dan assembler. Dia sampai pada kesimpulan berikut:
Kesimpulan
- Apakah .NET cache array lokal kode-keras? Seperti yang meletakkan kompiler Roslyn di metadata.
- Dalam hal ini, akan ada overhead? Sayangnya, ya: untuk setiap panggilan, JIT akan menyalin isi array dari metadata, yang membutuhkan waktu lebih lama dibandingkan dengan array statis. Runtime juga memilih objek dan menciptakan lalu lintas di memori.
- Apakah ada yang perlu dikhawatirkan tentang hal ini? Mungkin Jika ini adalah metode panas dan Anda ingin mencapai tingkat kinerja yang baik, Anda perlu menggunakan array statis. Jika ini adalah metode dingin yang tidak mempengaruhi kinerja aplikasi, Anda mungkin perlu menulis kode sumber "baik" dan menempatkan array di area metode.
Anda dapat melihat perubahan yang dibuat di
diff ini .
Menggunakan Fungsi MathF Daripada Matematika
Kedua, dan yang paling penting, saya meningkatkan kinerja secara signifikan dengan melakukan perubahan berikut:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
Dimulai dengan .NET Standard 2.1, implementasi konkret dari fungsi matematika umum
float ada. Mereka berada di kelas
System.MathF . Untuk selengkapnya tentang API ini dan implementasinya, lihat di sini:
Setelah perubahan ini, perbedaan dalam kinerja kode C # dan C ++ dikurangi menjadi sekitar 10%:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| Waktu (detik) | 41.38 | 58.89 | 46.04 | 44.33 |
| Dalam inti (dtk) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0,13 (0,3%) |
| Di ruang pengguna (detik) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44,03 (99,3%) |
| Jumlah kesalahan halaman kesalahan | 1119 | 4749 | 5776 | 5661 |
| Perangkat Kerja (KB) | 4136 | 13,440 | 16.788 | 16.652 |
| Memori yang Diekstrusi (KB) | 89 | 172 | 150 | 150 |
| Memori non-preemptive | 7 | 13 | 16 | 16 |
| Swap File (KB) | 1428 | 10 904 | 10 960 | 11 044 |
TC - kompilasi bertingkat,
Kompilasi Berjenjang (
saya kira ini akan diaktifkan secara default di .NET Core 3.0)
Untuk kelengkapan, berikut adalah hasil dari beberapa proses:
| Lari | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| TestRun-01 | 41.38 | 58.89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57.65 | 46.23 | 45,96 |
| TestRun-03 | 42.17 | 62.64 | 46.22 | 48.73 |
Catatan : perbedaan antara .NET Core dan .NET Framework adalah karena tidak adanya API MathF di .NET Framework 4.7.2, untuk informasi lebih lanjut, lihat
tiket dukungan .Net Framework (4.8?) Untuk netstandard 2.1 .
Lebih lanjut meningkatkan produktivitas
Saya yakin kode itu masih bisa diperbaiki!
Jika Anda tertarik untuk menyelesaikan perbedaan kinerja,
ini adalah kode C # . Sebagai perbandingan, Anda dapat menonton kode assembler C ++ dari layanan
Compiler Explorer yang sangat baik.
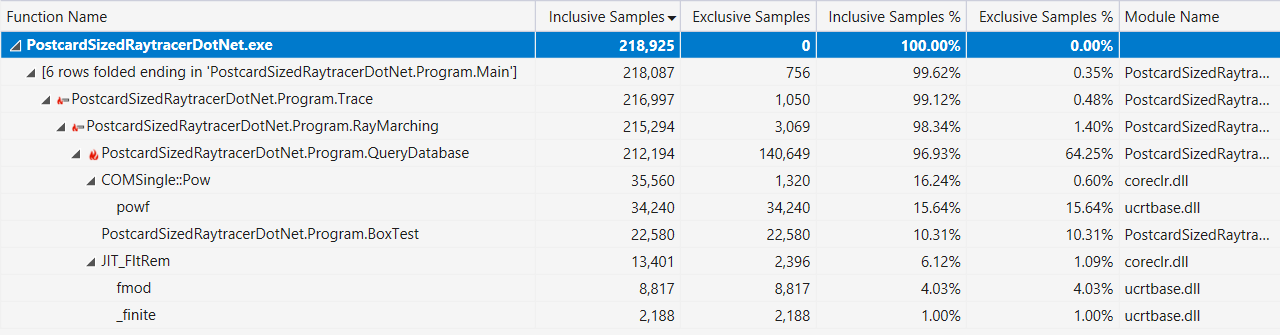
Akhirnya, jika itu membantu, berikut ini adalah output profiler Visual Studio dengan tampilan "jalur panas" (setelah peningkatan kinerja yang dijelaskan di atas):
Apakah C # bahasa tingkat rendah?
Atau lebih khusus:
Apa fitur bahasa dari fungsi C # / F # / VB.NET atau BCL / Runtime yang berarti "level rendah" *?
* Ya, saya mengerti bahwa "level rendah" adalah istilah subyektif.
Catatan: setiap pengembang C # memiliki ide sendiri tentang apa "level rendah" itu, fungsi-fungsi ini akan diterima begitu saja oleh programmer C ++ atau Rust.
Ini daftar yang saya buat:
- ref pengembalian dan ref penduduk setempat
- “Melewati dan kembali dengan referensi untuk menghindari menyalin struktur besar. Jenis dan memori yang aman bisa lebih cepat daripada tidak aman! "
- Kode tidak aman di .NET
- “Bahasa inti C #, sebagaimana didefinisikan dalam bab-bab sebelumnya, sangat berbeda dari C dan C ++ karena tidak memiliki pointer sebagai tipe data. Sebaliknya, C # memberikan tautan dan kemampuan untuk membuat objek yang diatur oleh pengumpul sampah. Desain ini, dikombinasikan dengan fitur-fitur lain, menjadikan C # bahasa yang jauh lebih aman daripada C atau C ++. ”
- Pointer yang Dikelola di .NET
- “Ada jenis pointer lain di CLR - pointer terkelola. Ini dapat didefinisikan sebagai jenis tautan yang lebih umum yang dapat menunjuk ke lokasi lain, dan tidak hanya ke awal objek. "
- Seri C # 7, Bagian 10: Rentang <T> dan Manajemen Memori Universal
- "System.Span <T> hanyalah tipe tumpukan (
ref struct ) yang membungkus semua pola akses memori, ini adalah tipe untuk akses memori kontinu universal. Kita dapat membayangkan implementasi Span dengan referensi dummy dan panjang yang menerima ketiga jenis akses memori. "
- Kompatibilitas ("Panduan Pemrograman C #")
- ".NET Framework menyediakan interoperabilitas dengan kode yang tidak dikelola melalui layanan permintaan platform,
System.Runtime.InteropServices , kompatibilitas C ++, dan kompatibilitas COM (interoperabilitas COM)."
Saya juga melemparkan teriakan di Twitter dan mendapat lebih banyak opsi untuk dimasukkan dalam daftar:
- Ben Adams : "Alat Bawaan untuk Platform (Instruksi CPU)"
- Mark Gravell : “SIMD via Vector (yang cocok dengan Span) * cukup * rendah; .NET Core harus (segera?) Menawarkan alat embedded CPU langsung untuk penggunaan instruksi CPU spesifik yang lebih eksplisit ”
- Mark Gravell : “JIT Powerfull: hal-hal seperti rentang elision pada array / interval, serta menggunakan aturan per-struct-T untuk menghapus potongan besar kode yang JIT tahu pasti bahwa mereka tidak tersedia untuk T atau spesifik Anda CPU (BitConverter.IsLittleEndian, Vector.IsHardwareDipercepat, dll.) "
- Kevin Jones : "Saya akan secara khusus menyebutkan kelas
MemoryMarshal dan Unsafe , dan mungkin beberapa hal lain di dalam System.Runtime.CompilerServices "
- Theodoros Chatsigiannakis : "Anda juga bisa memasukkan
__makeref dan yang lainnya"
- damageboy : "Kemampuan untuk secara dinamis menghasilkan kode yang sama persis dengan input yang diharapkan, mengingat bahwa yang terakhir hanya akan diketahui pada saat run time dan dapat berubah secara berkala?"
- Robert Hacken : "Emisi dinamis IL"
- Victor Baybekov : “Stackalloc tidak disebutkan. Dimungkinkan juga untuk menulis IL murni (bukan dinamis, oleh karena itu disimpan pada panggilan fungsi), misalnya, gunakan
ldftn cache dan panggil mereka melalui calli . Ada template proj di VS2017 yang membuat ini sepele dengan menulis ulang metode extern + MethodImplOptions.ForwardRef + ilasm.ex »
- Victor Baybekov : "MethodImplOptions.AggressiveInlining juga" mengaktifkan pemrograman tingkat rendah "dalam arti memungkinkan Anda untuk menulis kode tingkat tinggi dengan banyak metode kecil dan masih mengontrol perilaku JIT untuk mendapatkan hasil yang optimal. Kalau tidak, salin dan tempel ratusan metode LOC ... "
- Ben Adams : "Menggunakan konvensi pemanggilan yang sama (ABI) seperti pada platform dasar, dan p / memanggil untuk interaksi?"
- Victor Baibekov : “Juga, karena Anda menyebutkan #fsharp -
inline yang berfungsi di tingkat IL hingga JIT, oleh karena itu dianggap penting di tingkat bahasa. C # ini tidak cukup (sejauh ini) untuk lambdas, yang selalu merupakan panggilan virtual, dan solusi sering aneh (obat generik terbatas) "
- Alexandre Mutel : “SIMD tertanam baru, pasca pemrosesan kelas Utilitas Tidak Aman / IL (misalnya, kustom, Fody, dll.). Untuk C # 8.0, pointer fungsi mendatang ... "
- Alexandre Mutel : “Mengenai IL, F # secara langsung mendukung IL dalam bahasa, misalnya”
- OmariO : " BinaryPrimitive . Tingkat rendah, tapi aman "
- Koji Matsui : “Bagaimana dengan assembler bawaanmu sendiri? Sulit untuk toolkit dan runtime, tetapi dapat mengganti solusi p / invoke saat ini dan mengimplementasikan kode yang disematkan, jika ada ”
- Frank A. Kruger : "Ldobj, stobj, initobj, initblk, cpyblk"
- Conrad Coconut : “Mungkin streaming penyimpanan lokal? Memperbaiki ukuran buffer? Anda mungkin harus menyebutkan batasan yang tidak dikelola dan tipe yang bisa ditembus :) ”
- Sebastiano Mandala : "Hanya tambahan kecil untuk semua yang dikatakan: bagaimana dengan sesuatu yang sederhana, seperti mengatur struktur dan bagaimana mengisi dan menyelaraskan memori dan bidang pemesanan dapat mempengaruhi kinerja cache? Ini adalah sesuatu yang saya sendiri harus jelajahi. ”
- Nino Floris : "Konstanta yang disematkan melalui readonlyspan, stackalloc, finalizers, WeakReference, delegasi terbuka, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, dapat mengatur jenis struktur sesuai dengan tata letak (digunakan untuk TaskAwaiter dan versinya)"
Jadi pada akhirnya, saya akan mengatakan bahwa C # tentu memungkinkan Anda untuk menulis kode yang terlihat seperti C ++, dan dalam kombinasi dengan pustaka runtime dan kelas dasar menyediakan banyak fungsi tingkat rendah.Bacaan lebih lanjut
Unity Burst Compiler: