Hal terpenting untuk layanan Yandex.Zen adalah mengembangkan dan memelihara platform yang menghubungkan audiens dengan penulis. Untuk menjadi platform yang menarik bagi penulis yang baik, Zen harus dapat menemukan pemirsa yang relevan untuk saluran yang menulis tentang topik apa pun, termasuk yang tersempit. Kepala kelompok kebahagiaan penulis Boris Sharchilev berbicara tentang peringkat autosentris, yang memilih pengguna yang paling relevan untuk penulis. Dari laporan Anda dapat mengetahui bagaimana pendekatan ini berbeda dari pemilihan item yang relevan - lebih populer di sistem rekomendasi.
Dengan menyeimbangkan peringkat sentris-pengguna dan sentris-otomatis, kita dapat mencapai keseimbangan yang tepat antara kebahagiaan pengguna dan kebahagiaan penulis.
- Kolega, halo semuanya. Nama saya Borya. Saya berurusan dengan kualitas peringkat di Zen. Saya yakin bahwa ini adalah salah satu layanan Yandex yang paling menarik, kami memiliki pembelajaran mesin yang sangat keren, dan dalam 17 menit ke depan saya akan mencoba meyakinkan Anda tentang ini.
Apa itu Zen? Jika cukup sederhana, Zen adalah layanan rekomendasi pribadi. Kami mencoba merekomendasikan pengguna konten yang relevan berdasarkan apa yang kami ketahui tentang minat pengguna ini. Sasaran tingkat tinggi kami adalah agar pengguna menghabiskan waktu di Zen. Dan yang sangat penting adalah mereka tidak menyesal kali ini.
Bentuk dasar konsumsi konten kami terlihat seperti ini. Ini adalah aliran rekomendasi yang tak ada habisnya. Dan di sini jelas bahwa kita, pada prinsipnya, mencoba untuk merekomendasikan materi yang sangat tentang topik yang sangat berbeda. Ada berbagai topik: sesuatu tentang bisnis, sesuatu tentang humor, bahkan sesuatu tentang fantasi. Artinya, dalam rekaman itu Anda dapat menemukan artikel pendidikan dan pendidikan, serta yang lebih menghibur. Dan, tentu saja, personalisasi. Umpan Zen untuk semua orang terlihat berbeda - tergantung pada minat pengguna. Plus, tentu saja, sedikit iklan.

Poin yang sangat penting. Pada awalnya, ketika kami pertama kali muncul, kami sebenarnya adalah agregator konten dari Internet. Artinya, kami berkeliling situs yang ada, mengambil konten dari mereka, dan menunjukkannya kepada pengguna tergantung minat. Sekarang situasinya berbeda. Sekarang Zen adalah seluruh platform blogging di mana setiap orang dapat membuat saluran mereka sendiri, apakah itu beberapa blogger terkenal atau penulis pemula yang memiliki sesuatu untuk diceritakan. Penulis baru melihat layar sambutan yang begitu bagus di mana kami berbicara tentang layanan - bahwa Zen sendiri akan memilih audiens, dan dia hanya perlu menulis materi yang bagus.
Sekarang platform menyumbang lebih dari setengah dari total lalu lintas di Zen. Dan angka ini hanya akan tumbuh. Kami memahami bahwa setiap orang dapat memberi peringkat konten yang ada. Tentu saja, kami akan melakukan yang terbaik dari semuanya. Tetapi tidak semua orang memiliki konten yang unik, dan kami percaya ini akan menjadi keunggulan kompetitif kami.

Penting untuk dipahami bahwa Zen sudah sangat besar. Menurut Yandex.Radar, pada akhir tahun lalu kami memiliki sekitar 10-12 juta pembaca harian per hari, sekitar 35 juta pembaca harian, dan bahkan menurut beberapa data dari Yandex.Radar, kami tahun lalu Untuk pertama kalinya mereka berkeliling di audiensi Yandex.News. Ini berarti bahwa kami membuat Internet dengan sangat serius, kami memiliki tugas yang sangat serius, ada banyak dari mereka, dan kami sangat menantikan bantuan Anda.
Mari kita bicara tentang detail cara kerjanya, dan diskusikan apa yang bisa kita lakukan dengan pekerja magang, bagaimana kita dapat membantu layanan kita.
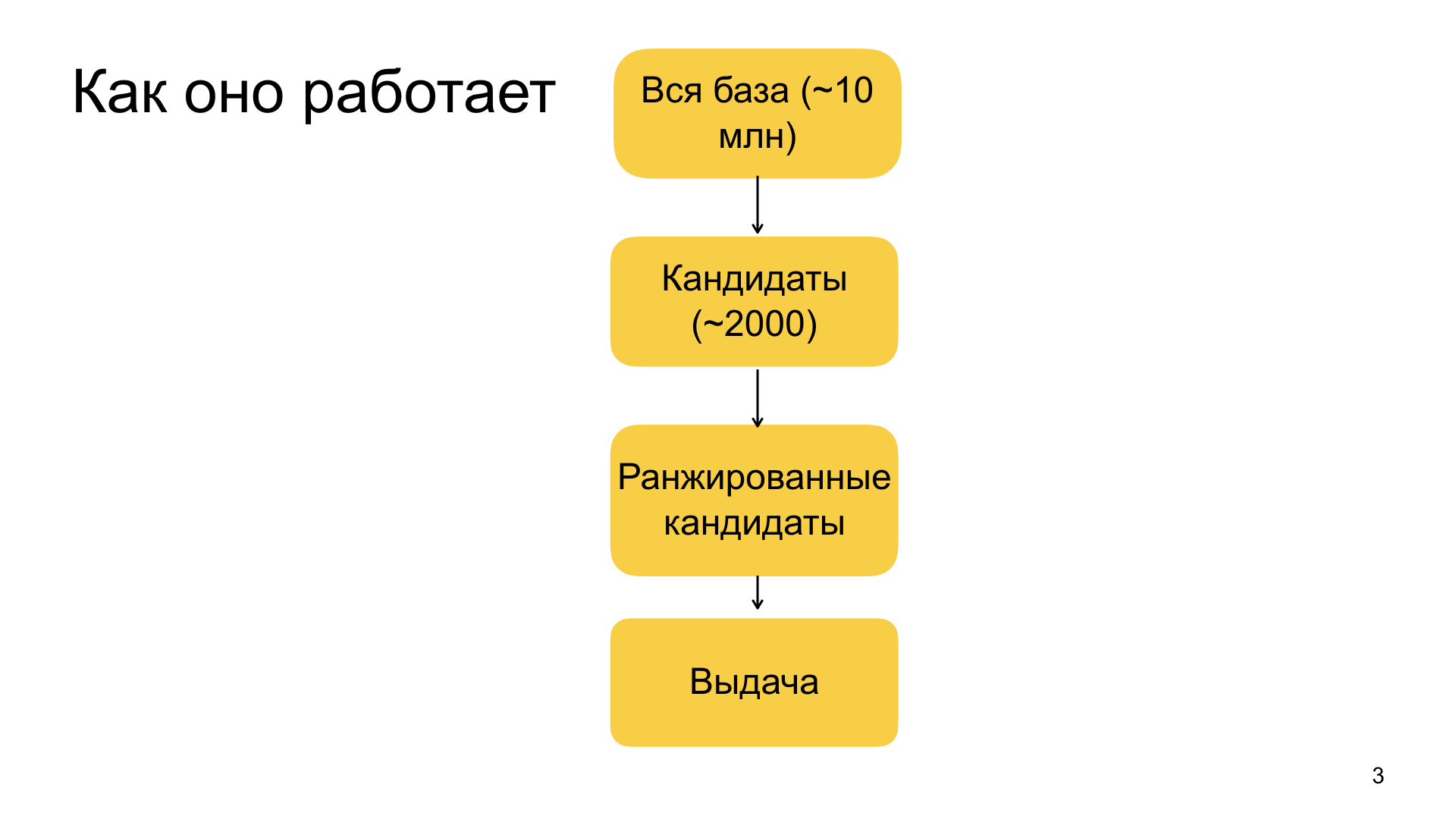
Garis besar rekomendasi yang kami miliki disusun seperti ini. Semuanya dimulai dengan basis data dokumen kami yang besar dari mana kami memilih bahan untuk rekomendasi. Ini terdiri dari puluhan juta dokumen. Selain itu, database ini terus diisi ulang - sekitar satu juta dokumen baru tiba setiap hari di dalamnya. Idealnya, kami ingin menerapkan seluruh mesin pembelajaran mesin kami ke semua puluhan juta dokumen ini secara pribadi untuk setiap pengguna, dan memilih yang paling relevan untuknya. Tapi, sayangnya, ini tidak berhasil dalam prakteknya, karena Zen adalah layanan yang bekerja secara real time. Kami memiliki jaminan yang sangat ketat tentang seberapa cepat kami siap untuk menanggapi, oleh karena itu, untuk alasan praktis, kami terpaksa mempersempit basis puluhan juta dokumen ke ribuan rekomendasi potensial pada tahap pertama, yang kami sudah dapat peringkat sepenuhnya dengan model kami dan memilih yang paling relevan. Tahap mempersempit basis dari puluhan juta menjadi sekitar ribuan disebut seleksi kandidat atau peringkat mudah.
Ketika kami memiliki kit ini, kami menerapkannya pada model pembelajaran mesin besar kami yang kompleks, yang pada tingkat atas adalah peningkatan gradien. Ini semua tanpa kejutan, tetapi kami memiliki faktor yang sangat beragam - dari beberapa faktor sederhana yang mencirikan, misalnya, seberapa relevan domain dengan pengguna, sumbernya, seberapa sering ia mengunjungi, mengklik, meninggalkan umpan balik, suka, dan tidak suka. Jadi, ada faktor yang lebih kompleks yang didasarkan, misalnya, pada fitur jaringan saraf. Kami memproses teks artikel, kami memproses gambar, sumber data lainnya, dan kami juga menggunakan fitur komposit tersebut. Semua skema ini cukup rumit, saya tidak akan punya waktu untuk memberi tahu Anda secara rinci.
Setelah kami memberi peringkat 2 ribu kandidat, kami memilih yang teratas dari mereka. Ukuran bagian atas tergantung pada seberapa banyak kita perlu merekomendasikan bahan. Itu selalu didefinisikan secara berbeda. Dan dengan demikian kami membentuk masalah terakhir.
Beginilah tampilan sirkuit pada level tinggi. Sekarang mari kita bicara tentang komponen mana dari keseluruhan proses yang ingin kita perbaiki.

Ternyata kami tertarik untuk melakukan apa saja. Ada banyak tugas. Kami ingin meningkatkan kecepatan pengiriman data untuk pemeringkatan: semakin baru kami memiliki data, semakin relevan rekomendasi yang kami buat. Saya ingin mempercepat layanan: semakin cepat kami bekerja, semakin baik pengalaman pengguna. Kami ingin meningkatkan keandalan layanan.
Penting bagi kita untuk meningkatkan peringkat. Artinya, kita perlu menerapkan model baru pembelajaran mesin dan meningkatkan model kita saat ini di negara lain. Kami direkomendasikan tidak hanya di Rusia, tetapi juga di banyak negara lain di dunia.
Kami juga ingin mempertimbangkan regionalitas akun dan merekomendasikan orang-orang konten yang berhubungan dengan wilayah mereka.
Dan ini sangat penting - kita perlu mengembangkan platform penulisan kita. Ini adalah masa depan kita, kita perlu berinvestasi di dalamnya. Ada juga banyak tugas. Secara khusus, kita harus dapat menemukan dan meluncurkan konten yang berkualitas. Penting bagi kami untuk menunjukkan materi yang bagus, bukan sampah. Kita harus dapat membuat peringkat format konten baru. Kami tidak hanya memiliki artikel, tetapi juga video pendek, dan pos yang ditonton pengguna langsung di umpan. Semua format ini harus dapat diurutkan.
Dan poin yang sangat penting, yang ingin saya bicarakan sedikit lebih detail dalam detail yang lebih teknis - penting bagi kita untuk dapat setiap penulis untuk menemukan audiens yang relevan dengannya, bahkan jika itu datang ke penulis dan topik niche yang cukup. Mari kita bicara lebih detail apa masalahnya di sini dan bagaimana kita menyelesaikannya.
Mari kita lihat sebuah contoh.
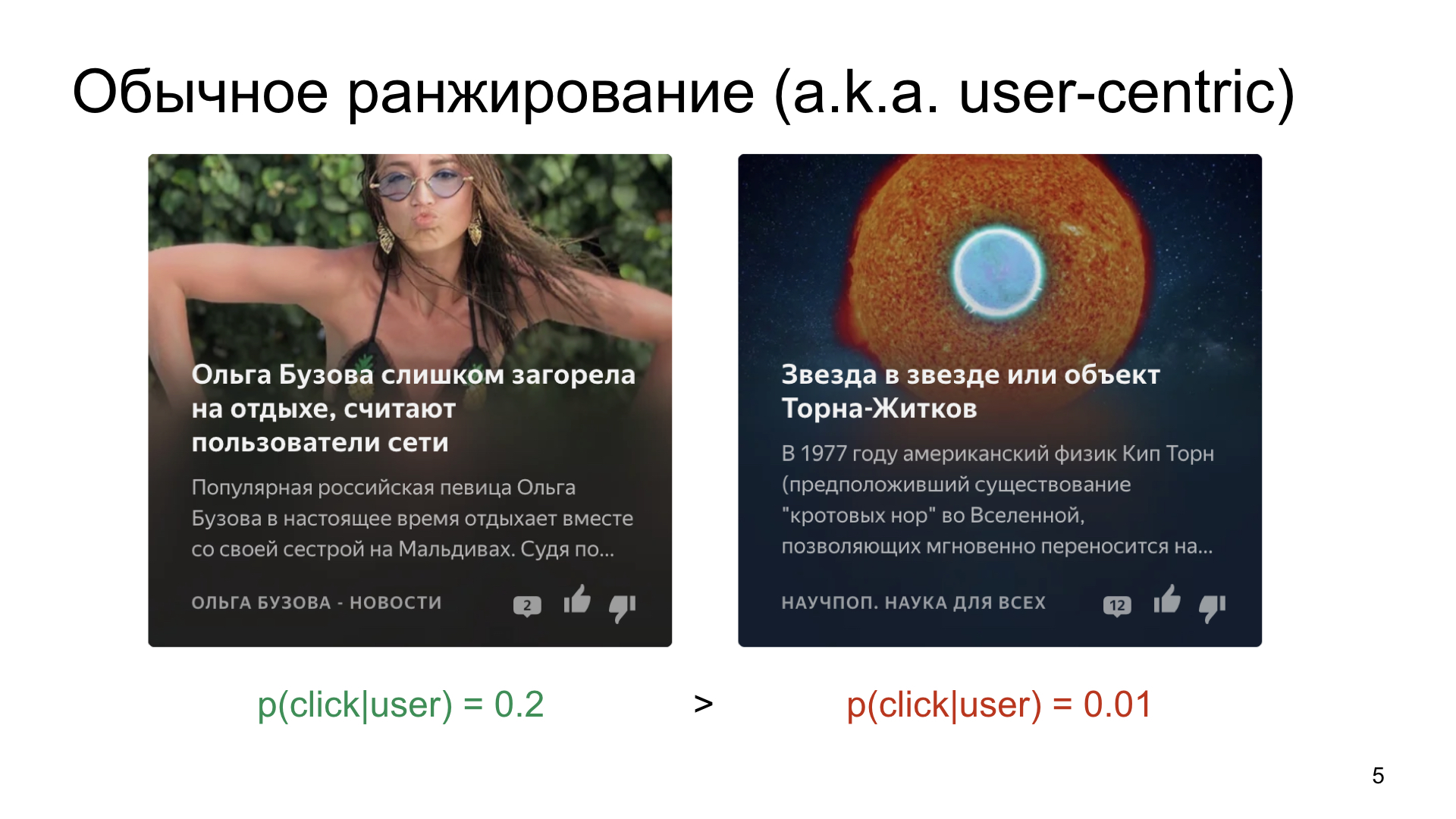
Kami memilih, misalkan, dari dua kartu yang ingin kami perlihatkan kepada pengguna.
Beginilah dunia bekerja dan cara orang bekerja, bahwa ada sesuatu yang lebih rata-rata, di mana probabilitas klik rata-rata 20 persen, dan ada sesuatu yang lebih niche, misalnya, artikel tentang sains atau tentang ruang.
Jika kita hanya memberi peringkat kartu berdasarkan probabilitas klik, maka, tentu saja, konten yang lebih dapat diklik dan lebih sederhana akan mengumpulkan jumlah tayangan yang sangat besar, dan bahkan artikel yang sangat bagus tentang sains tidak akan melakukannya. Tentu saja, kami tidak menginginkan ini. Kami ingin menemukan pemirsa yang tertarik bahkan untuk saluran khusus.

Mengapa Anda ingin melakukan ini? Padahal, ada dua alasan. Yang pertama adalah grosir. Artinya, kami ingin Zen menjadi semacam jaringan Internet. Sehingga segala sesuatu yang dapat ditemukan pengguna dan apa yang ia minati di Internet besar disajikan dalam Zen. Dan agar dia menerima apa yang menarik baginya.
Saluran ilmiah memiliki pemirsa mereka sendiri. Tapi ada nuansa seperti itu. Jika pecinta sains menunjukkan sains dan konten populer, mereka lebih cenderung mengkliknya daripada sains. Tetapi jika Anda hanya menunjukkan kepada mereka sains, mereka akan mengklik sains juga, dan mereka bahkan tidak akan menyesalinya. Pertanyaannya adalah bagaimana menemukan orang-orang seperti itu dan bagaimana menampilkan konten, dengan fokus bukan pada pengguna, tetapi pada penulis.

Bagaimana cara melakukannya? Formula peringkat yang biasa, yang memprediksi kemungkinan klik, tidak akan membantu kami di sini, karena rata-rata lebih banyak artikel niche akan kehilangan. Tapi Anda bisa sebaliknya - untuk mengalokasikan kuota tertentu, dan di dalamnya kurang lebih memberikan kesan kepada penulis, memberi mereka semacam jaminan minimal. Ini bisa dilakukan, dan ini akan membuat penulis sedikit lebih bahagia, tetapi, sayangnya, ini akan membuat pengguna kami kurang bahagia. Pengguna akan mengklik lebih sedikit, lebih marah dan pergi. Tentu saja, kami tidak menginginkan ini.
Bagaimana caranya berada di sini?
Kami berpikir lama dan menghasilkan konsep baru. Kami menyebutnya peringkat atau kesan autosentris untuk penulis.
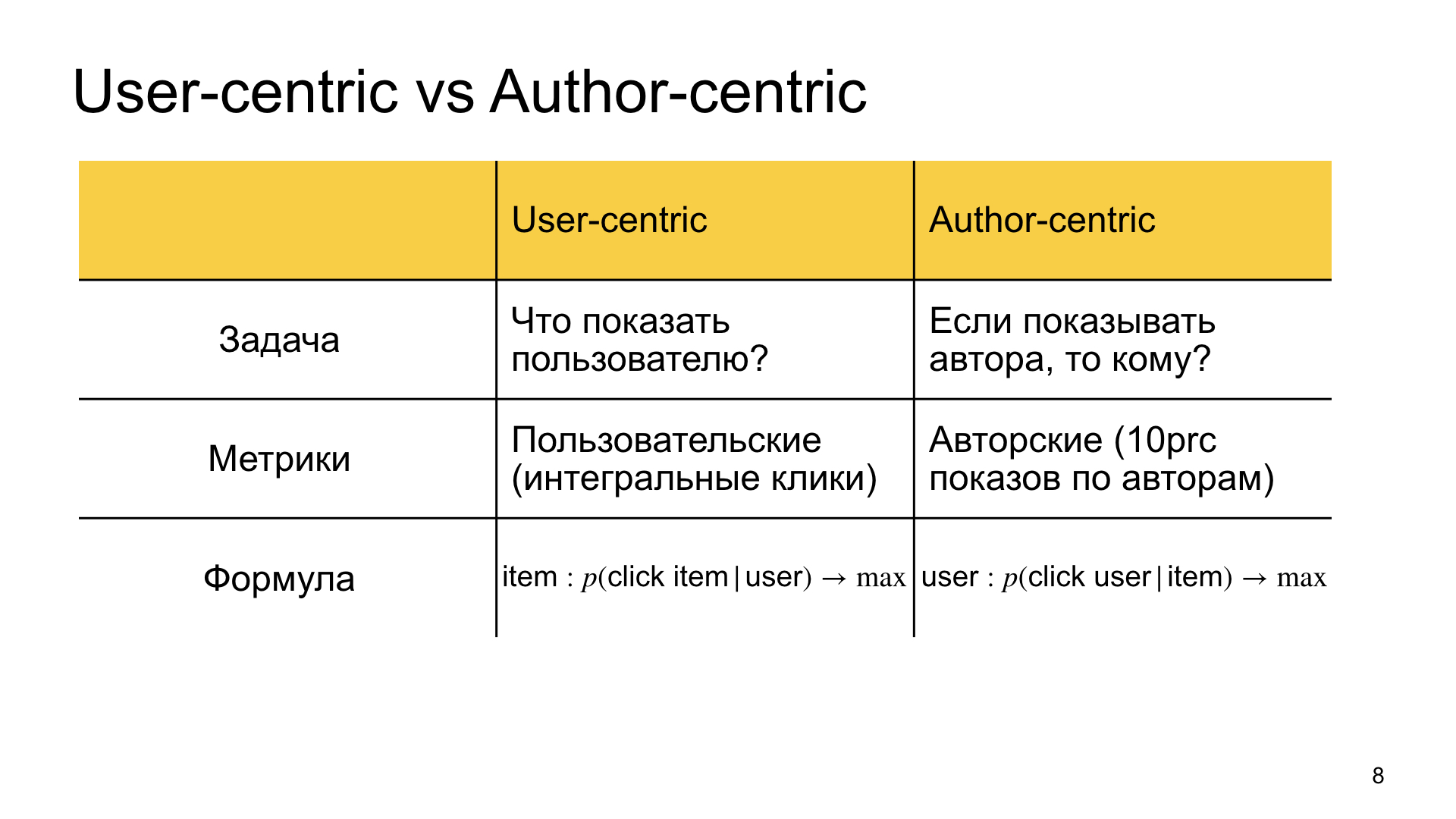
Apa tujuan kami dalam peringkat reguler, yang kami sebut usercentric? Temukan materi yang paling relevan bagi pengguna. Kami menjawab pertanyaan tentang apa yang harus ditampilkan kepada pengguna.
Dalam peringkat autosentris, kami semacam membalikkan pernyataan masalah dan mengatakan bahwa kami ingin menunjukkan kepada penulis ini, dan pertanyaannya adalah siapa yang harus ditunjukkan kepadanya, kepada siapa ia paling relevan. Karenanya perbedaan dalam metrik. Dalam kasus pertama, kami lebih tertarik pada metrik khusus, yaitu, klik integral, waktu integral di Zen, dan sebagainya. Dalam kasus kedua, kami tertarik pada apa yang disebut metrik penulis. Misalnya, kami mengukur seberapa baik Zen hidup, misalnya, terbawah 10% dari penulis. Jika mereka hidup cukup baik, maka semua orang juga senang.

Bagaimana kita melakukan ini? Misalkan kita memiliki formula peringkat yang biasa. Untuk kesederhanaan, anggap itu memprediksi kemungkinan pengguna mengklik item yang diberikan, pada kartu yang diberikan. Apa yang akan kita lakukan Mari sekarang perbaiki untuk setiap artikel dan terapkan model kami untuk artikel ini, idealnya - untuk semua pengguna, dalam praktiknya - untuk beberapa jenis sampel pengguna. Dan kami akan membangun distribusi skor kami, yaitu, perkiraan probabilitas mengklik suatu artikel, untuk setiap artikel oleh pengguna. Sekarang untuk setiap artikel kami memiliki distribusi seperti pada grafik (slide di atas - kira-kira. Ed). Setelah itu, kami akan memberi peringkat artikel untuk pengguna dan memilih bagian atas tidak hanya oleh kemungkinan klik, tetapi oleh persentil yang termasuk dalam pengguna ini untuk artikel ini. Artinya, kami memperkirakan probabilitas klik, melihat di mana pengguna berada dalam distribusi ini, dan mengatur berdasarkan nilai ini.

Di sini kita memiliki dua kartu yang sama, salah satunya lebih dapat diklik, 20%, yang lain - kurang dari 1%. Sekarang, jika Anda mengambil pengguna tertentu, situasi seperti itu mungkin terjadi sehingga ia memiliki peluang untuk mengklik kartu yang lebih populer daripada yang kurang populer, katakanlah, 10% berbanding 3%. Tetapi karena probabilitas rata-rata klik pada kartu populer adalah 20%, dan pengguna memiliki 10%, ia rata-rata kurang relevan dengan publikasi ini daripada rata-rata pengguna Zen. Dan dalam situasi lain, kebalikannya: ia memiliki peluang 3% klik, tetapi artikel rata-rata memiliki 1%. Oleh karena itu, ini adalah rata-rata audiens yang lebih relevan dengan artikel daripada pengguna Zen lainnya. Oleh karena itu, wawasan utama di sini adalah bahwa bahkan jika kemungkinan klik pada suatu artikel kurang, dengan bantuan kerangka kerja seperti itu, kami memiliki kesempatan untuk menampilkan artikel yang kurang populer jika pengguna berada dalam inti yang paling tepercaya untuk publikasi ini.

Jika pengguna mendatangi kami lebih atau kurang secara merata, maka skor yang diberikan dengan mana kami memberi peringkat, yaitu persentil tempat setiap pengguna masuk, akan didistribusikan secara merata di antara pengguna. Ini berarti bahwa jika semua artikel diberi peringkat dengan cara ini, maka mereka semua akan mengumpulkan kurang lebih jumlah tayangan yang sama. Tidak akan ada emisi puluhan juta tayangan dibandingkan dengan 10 tayangan beberapa kartu yang kurang relevan. Dengan demikian, dengan menyeimbangkan peringkat sentris-pengguna dan sentris-otomatis, kita dapat mencapai rasio kebahagiaan pengguna dan kebahagiaan penulis yang menurut kami benar.
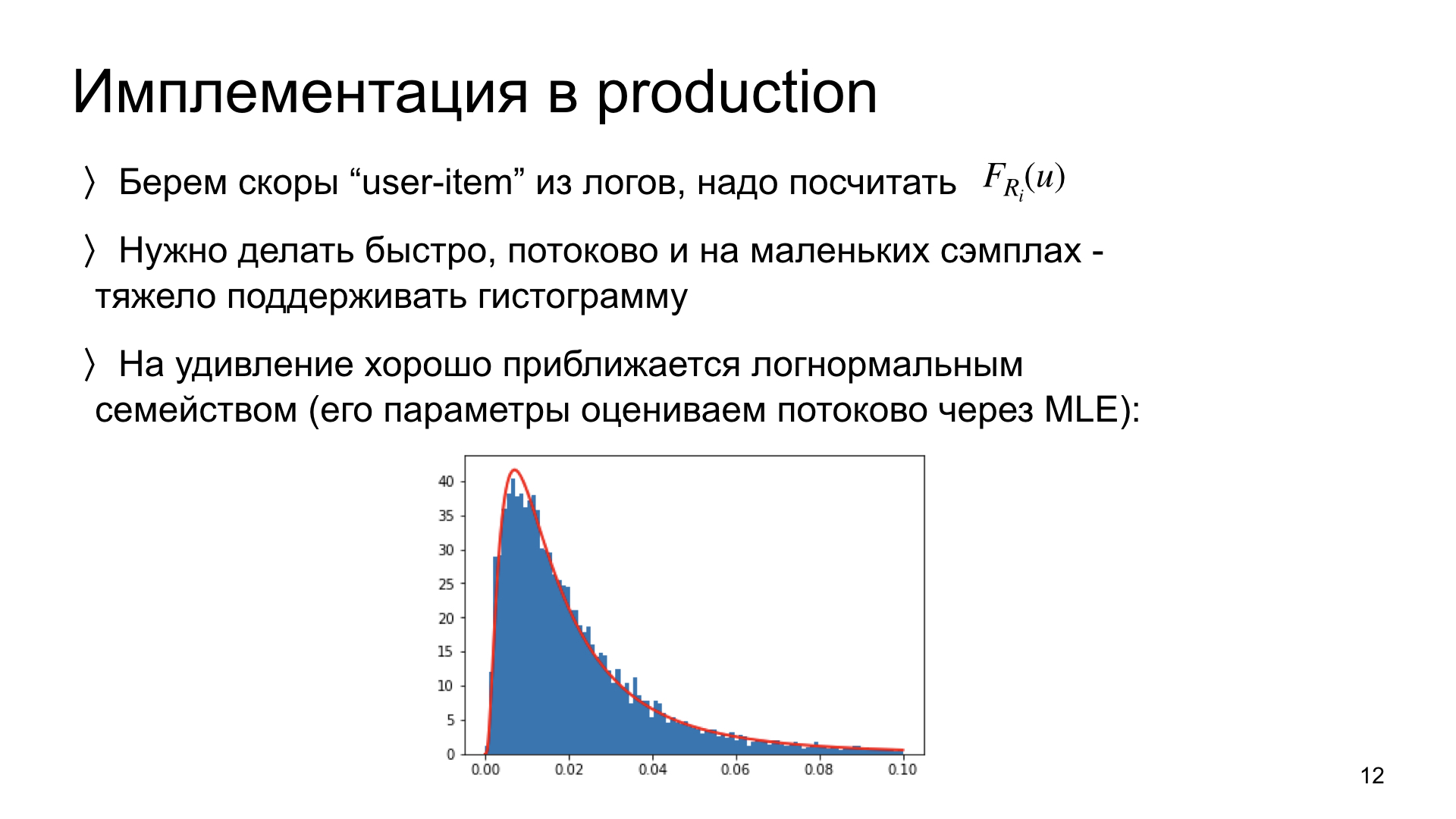
Beberapa kata tentang bagaimana kami menerapkan ini dalam produksi. Kita perlu melihat log kita dan menghitung distribusi untuk setiap artikel dari mereka. Keterbatasan penting: kita harus bisa melakukan ini, pertama, cepat, dan kedua, dalam mode streaming. Artinya, idealnya, untuk memperbarui estimasi distribusi untuk data baru, kita harus memiliki dalam memori tidak semua data sebelumnya, tetapi hanya perkiraan saat ini. Sistem seperti itu dapat diskalakan, skema semacam itu berfungsi. Idealnya, kita harus dapat melakukan ini pada data kecil. Jika ada artikel yang hanya memiliki 300 tayangan, maka kami harus dapat memperkirakan distribusi untuk jumlah pengamatan yang memadai.
Kami melakukan eksperimen dan menemukan bahwa distribusi skor tersebut secara mengejutkan mendekati distribusi normal log. Artinya, ini adalah pengamatan empiris. Dan jika demikian, maka alih-alih memperkirakan seluruh histogram distribusi secara non-parametrik, kita hanya dapat mengevaluasi dua parameter dari distribusi ini. Dan kita bisa melakukan ini di stream, hanya menggunakan estimasi parameter saat ini dan pengamatan baru. Skema seperti itu sangat cepat dan bekerja dengan sangat baik. Sekarang dia berproduksi bersama kami.
Hasilnya juga bagus. Kami sangat meningkatkan kebahagiaan penulis yang diabaikan di Zen dan tidak menyia-nyiakan metrik pengguna umum. Artinya, tugas bisnis sepenuhnya tercapai.
Saya sekarang telah menunjukkan salah satu contoh tugas yang dapat kita tangani. Tentu saja, ada banyak dari tugas-tugas ini, dan dengan masing-masing dari mereka kami membutuhkan bantuan Anda. Kami sangat berharap Anda ingin
bekerja bersama kami . Pada akhirnya, saya akan mengatakan beberapa kata tentang apa yang kami harapkan dari pekerja magang dan apa yang tidak kami harapkan dari mereka. Dari peserta pelatihan, kami mengharapkan hal yang paling penting - kemampuan untuk menulis kode. Kami tidak memiliki ilmuwan murni dalam layanan ini. Kita semua adalah insinyur ML, mereka harus dapat melakukan siklus penuh tugas. Mereka harus mampu dan menerapkan solusi mereka dalam produksi, dan menerapkan ML. Artinya, kami berharap Anda dapat menulis kode pada tingkat dasar, memahami pendekatan, mengetahui algoritma, struktur data, dasar-dasar pembelajaran mesin.
Apa yang tidak kita harapkan dari pekerja magang? Pertama-tama, kami tidak mengharapkan pengetahuan yang mendalam tentang bahasa atau kerangka kerja apa pun. Yaitu, jika Anda tidak tahu bagaimana coroutine bekerja dengan Python - tidak apa-apa, kami akan mengajarkan Anda segalanya. Dan kami tidak berharap banyak pengalaman dari Anda. Kami mengharapkan pengetahuan dari Anda, keinginan untuk bekerja. Jika tidak ada pengalaman, tidak apa-apa. Kami akan mengajarkan segalanya, dan semuanya akan baik-baik saja. Terima kasih