Bagi mereka yang terlalu malas untuk membaca semuanya: sanggahan dari tujuh mitos populer disarankan, yang dalam bidang penelitian pembelajaran mesin sering dianggap benar, pada Februari 2019. Artikel ini tersedia di
situs web ArXiv dalam format pdf [dalam bahasa Inggris].
Mitos 1: TensorFlow adalah perpustakaan tensor.
Mitos 2: Database gambar mencerminkan foto asli yang ditemukan di alam.
Mitos 3: Peneliti MO tidak menggunakan alat tes untuk pengujian.
Mitos 4: Pelatihan jaringan saraf menggunakan semua data input.
Mitos 5: Normalisasi batch diperlukan untuk melatih jaringan residual yang sangat dalam.
Mitos 6: Jaringan dengan perhatian lebih baik daripada konvolusi.
Mitos 7: Peta signifikansi adalah cara yang andal untuk menafsirkan jaringan saraf.
Dan sekarang untuk detailnya.
Mitos 1: TensorFlow adalah perpustakaan tensor
Sebenarnya, ini adalah perpustakaan untuk bekerja dengan matriks, dan perbedaan ini sangat signifikan.
Dalam
Menghitung Derivatif Orde Tinggi dari Matriks dan Ekspresi Tensor. Laue et al. Penulis NeurIPS 2018 menunjukkan bahwa perpustakaan mereka diferensiasi otomatis, berdasarkan kalkulus tensor nyata, memiliki pohon ekspresi jauh lebih kompak. Faktanya adalah bahwa kalkulus tensor menggunakan notasi indeks, yang memungkinkan Anda untuk bekerja sama dengan mode langsung dan mundur.
Penomoran matriks menyembunyikan indeks untuk kenyamanan notasi, itulah sebabnya pohon ekspresi diferensiasi otomatis sering menjadi terlalu kompleks.
Pertimbangkan perkalian matriks C = AB. Kita punya
untuk mode langsung dan
untuk kebalikannya. Untuk melakukan perkalian dengan benar, Anda harus benar-benar mengamati urutan dan penggunaan tanda hubung. Dari sudut pandang rekaman, ini terlihat membingungkan bagi orang yang terlibat dalam MO, tetapi dari sudut pandang perhitungan, ini adalah beban tambahan untuk program.
Contoh lain, kurang sepele: c = det (A). Kita punya
untuk mode langsung dan
untuk kebalikannya. Dalam kasus ini, jelas tidak mungkin untuk menggunakan pohon ekspresi untuk kedua mode, mengingat bahwa mereka terdiri dari operator yang berbeda.
Secara umum, cara TensorFlow dan perpustakaan lain (misalnya, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) menerapkan diferensiasi otomatis, yang mengarah pada fakta bahwa untuk mengarahkan dan membalikkan Pohon ekspresi yang berbeda dan tidak efektif dibangun dalam mode. Penomoran tensor menghindari masalah ini karena komutatifitas perkalian karena notasi indeks. Untuk detail tentang cara kerjanya, lihat makalah ilmiah.
Para penulis menguji metode mereka dengan melakukan diferensiasi otomatis dari rezim terbalik, juga dikenal sebagai propagasi balik, dalam tiga tugas yang berbeda, dan mengukur waktu yang diperlukan untuk menghitung para Hessian.

Dalam masalah pertama, fungsi kuadrat x
T Ax dioptimalkan. Yang kedua, regresi logistik dihitung, dalam faktorisasi matriks ketiga.
Pada CPU, metode mereka ternyata dua urutan besarnya lebih cepat daripada perpustakaan populer seperti TensorFlow, Theano, PyTorch, dan HIPS autograd.
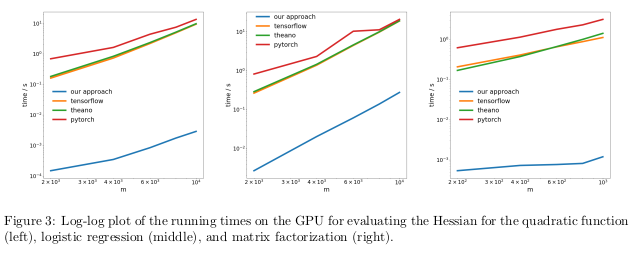
Pada GPU, mereka mengamati akselerasi yang lebih besar, sebanyak tiga kali lipat.
Konsekuensinya:Komputasi derivatif untuk fungsi orde kedua atau lebih tinggi menggunakan perpustakaan pembelajaran mendalam saat ini terlalu mahal dari sudut pandang komputasi. Ini termasuk perhitungan tensor orde keempat umum seperti Goni (misalnya, dalam MAML dan optimisasi orde dua Newton). Untungnya, rumus kuadrat jarang ditemukan dalam pembelajaran mendalam. Namun, mereka sering ditemukan dalam pembelajaran mesin "klasik" -
SVM , metode kuadrat terkecil, LASSO, proses Gaussian, dll.
Mitos 2: Database gambar mencerminkan foto dunia nyata
Banyak orang suka berpikir bahwa jaringan saraf telah belajar mengenali objek lebih baik daripada orang. Ini tidak benar. Mereka dapat berada di depan orang-orang di pangkalan gambar yang dipilih, misalnya, ImageNet, tetapi dalam hal pengenalan objek dari foto nyata dari kehidupan biasa, mereka pasti tidak akan dapat menyalip orang dewasa biasa. Ini karena pemilihan gambar dalam set data saat ini tidak bertepatan dengan pemilihan semua gambar yang mungkin ditemui secara alami dalam kenyataan.
Dalam sebuah karya yang agak lama,
Lihat Tidak Sesuai dengan
Dataset Bias. Torralba dan Efros. CVPR 2011. , Penulis mengusulkan untuk mempelajari distorsi yang terkait dengan satu set gambar di dua belas database populer, mencari tahu apakah mungkin untuk melatih classifier untuk menentukan set data dari mana gambar ini diambil.

Peluang untuk secara tidak sengaja menebak set data yang benar adalah 1/12 ≈ 8%, sementara para ilmuwan sendiri menghadapi tugas dengan tingkat keberhasilan> 75%.
Mereka melatih SVM pada directogram
gradient histogram (HOG) dan menemukan bahwa classifier menyelesaikan tugas dalam 39% kasus, yang secara signifikan melebihi hit acak. Jika kita mengulangi percobaan ini hari ini, dengan jaringan saraf paling maju, kita pasti akan melihat peningkatan akurasi pengklasifikasi.
Jika database gambar dengan benar menampilkan gambar sebenarnya dari dunia nyata, kita tidak harus dapat menentukan dari mana dataset berasal gambar tertentu.

Namun, ada sifat dalam data yang membuat setiap set gambar berbeda dari yang lain. ImageNet memiliki banyak mobil balap yang tidak mungkin menggambarkan mobil rata-rata "teoritis" secara keseluruhan.

Para penulis juga menentukan nilai setiap set data dengan mengukur seberapa baik seorang classifier melatih pada satu set bekerja dengan gambar dari set lain. Menurut metrik ini, database LabelMe dan ImageNet ternyata menjadi yang paling tidak bias, setelah menerima peringkat 0,58 menggunakan metode "keranjang mata uang". Semua nilai ternyata kurang dari satu, yang berarti bahwa pelatihan tentang kumpulan data yang berbeda selalu mengarah pada kinerja yang buruk. Dalam dunia ideal tanpa set bias, beberapa angka seharusnya melebihi satu.
Para penulis dengan pesimis menyimpulkan:
Jadi apa nilai dataset yang ada untuk algoritma pelatihan yang dirancang untuk dunia nyata? Jawaban yang dihasilkan dapat digambarkan sebagai "lebih baik daripada tidak sama sekali tetapi tidak banyak."
Mitos 3: Peneliti MO tidak menggunakan alat tes untuk pengujian
Dalam buku teks tentang pembelajaran mesin, kami diajarkan untuk membagi set data ke dalam pelatihan, evaluasi dan verifikasi. Efektivitas model, dilatih pada set pelatihan, dan dievaluasi pada evaluasi membantu orang yang terlibat dalam MO untuk menyempurnakan model untuk memaksimalkan efisiensi dalam penggunaannya yang sebenarnya. Set tes tidak perlu disentuh sampai orang tersebut selesai menyesuaikan diri untuk memberikan penilaian yang tidak bias tentang efektivitas nyata model di dunia nyata. Jika seseorang berselingkuh menggunakan set tes pada tahap pelatihan atau penilaian, model berisiko menjadi terlalu beradaptasi untuk set data tertentu.
Dalam dunia yang sangat kompetitif dalam penelitian MO, algoritma dan model baru sering dinilai dari keefektifan pekerjaan mereka dengan data verifikasi. Oleh karena itu, tidak masuk akal bagi peneliti untuk menulis atau menerbitkan makalah yang menjelaskan metode yang bekerja buruk dengan set data uji. Dan ini, pada dasarnya, berarti bahwa komunitas Wilayah Moskow secara keseluruhan menggunakan set tes untuk evaluasi.
Apa konsekuensi dari penipuan ini?

Penulis
Do CIFAR-10 Classifiers Generalised to CIFAR-10? Recht et al. ArXiv 2018 menyelidiki masalah ini dengan membuat test suite baru untuk CIFAR-10. Untuk melakukan ini, mereka membuat pilihan gambar dari Tiny Images.
Mereka memilih CIFAR-10 karena itu adalah salah satu set data yang paling umum digunakan di MO, set kedua paling populer di NeurIPS 2017 (setelah MNIST). Proses pembuatan dataset untuk CIFAR-10 juga dijelaskan dengan baik dan transparan, dalam basis data Tiny Images yang besar terdapat banyak label terperinci, sehingga Anda dapat mereproduksi set uji baru, meminimalkan pergeseran distribusi.

Mereka menemukan bahwa sejumlah besar model yang berbeda dari jaringan saraf pada set tes baru menunjukkan penurunan akurasi yang signifikan (4% - 15%). Namun, peringkat kinerja relatif masing-masing model tetap cukup stabil.
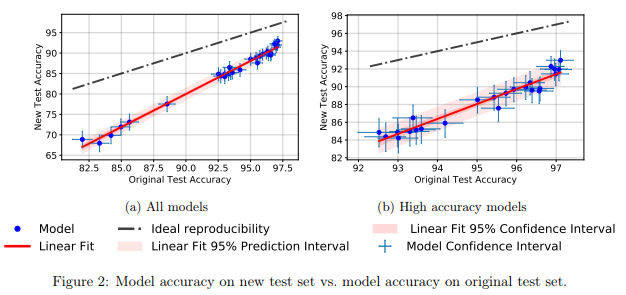
Secara umum, model yang berkinerja lebih baik menunjukkan penurunan akurasi yang lebih rendah dibandingkan dengan yang lebih buruk. Ini bagus karena ini berarti bahwa hilangnya generalisasi model akibat kecurangan, setidaknya dalam kasus CIFAR-10, berkurang ketika masyarakat menemukan metode dan model MO yang ditingkatkan.
Mitos 4: Pelatihan jaringan saraf menggunakan semua input
Secara umum diterima bahwa
data adalah minyak baru , dan bahwa semakin banyak data yang kita miliki, semakin baik kita dapat melatih model pembelajaran mendalam yang sekarang tidak efisien dan terlalu banyak sampel.
Dalam
Sebuah Studi Empiris Contoh Lupa Selama Belajar Jaringan Neural Dalam. Toneva et al. ICLR 2019 penulis menunjukkan redundansi yang signifikan dalam beberapa set gambar kecil yang umum. Anehnya, 30% data dari CIFAR-10 dapat dengan mudah dihapus tanpa mengubah keakuratan cek dengan jumlah yang signifikan.
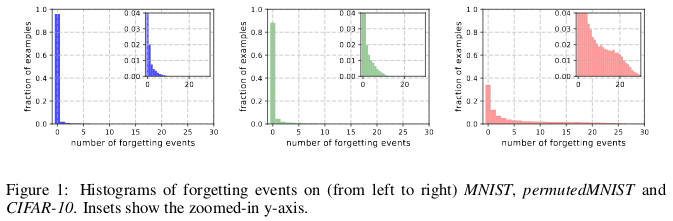 Sejarah dilupakan dari (kiri ke kanan) MNIST, permutasiMNIST dan CIFAR-10.
Sejarah dilupakan dari (kiri ke kanan) MNIST, permutasiMNIST dan CIFAR-10.Lupa terjadi ketika jaringan saraf secara salah mengklasifikasikan suatu gambar pada waktu t + 1, sementara pada waktu itu mampu mengklasifikasikan dengan benar suatu gambar. Aliran waktu diukur dengan pembaruan SGD. Untuk melacak lupa, penulis meluncurkan jaringan saraf mereka pada set data kecil setelah setiap pembaruan SGD, dan tidak pada semua contoh yang tersedia dalam database. Contoh yang tidak bisa dilupakan disebut contoh yang tak terlupakan.
Mereka menemukan bahwa 91,7% MNIST, 75,3% diijinkanMNIST, 31,3% CIFAR-10, dan 7,62% CIFAR-100 adalah contoh yang tak terlupakan. Ini dapat dimengerti secara intuitif, karena meningkatkan keragaman dan kompleksitas dari kumpulan data harus membuat jaringan saraf melupakan lebih banyak contoh.

Contoh-contoh yang terlupakan sepertinya memperlihatkan fitur yang lebih langka dan aneh dibandingkan dengan yang tak terlupakan. Para penulis membandingkannya dengan vektor dukungan dalam SVM, karena mereka tampaknya menggambarkan garis besar batas keputusan.
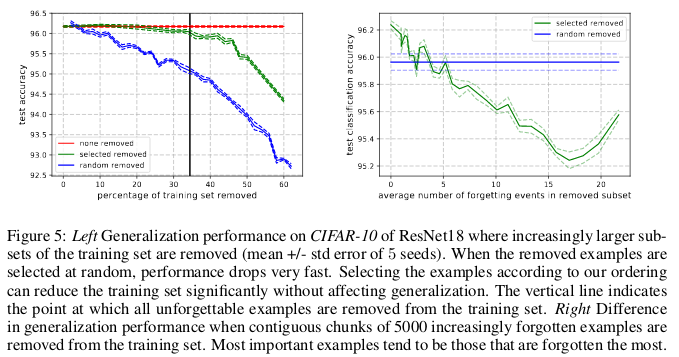
Contoh-contoh yang tak terlupakan, pada gilirannya, mengkodekan sebagian besar informasi yang berlebihan. Jika kita mengurutkan contoh berdasarkan tingkat tidak termaafkan, kita dapat mengompres kumpulan data dengan menghapus yang paling tak terlupakan.
30% dari data CIFAR-10 dapat dihapus tanpa memengaruhi keakuratan pemeriksaan, dan penghapusan 35% data menyebabkan sedikit penurunan keakuratan pemeriksaan sebesar 0,2%. Jika Anda memilih 30% dari data secara acak, maka menghapusnya akan menyebabkan hilangnya signifikan dalam keakuratan verifikasi 1%.
Demikian pula, 8% data dapat dihapus dari CIFAR-100 tanpa penurunan akurasi validasi.
Hasil ini menunjukkan bahwa ada redundansi yang signifikan dalam data untuk pelatihan jaringan saraf, mirip dengan pelatihan SVM, di mana vektor yang tidak mendukung dapat dihilangkan tanpa mempengaruhi keputusan model.
Konsekuensinya:Jika kita dapat menentukan data mana yang tidak terlupakan sebelum memulai pelatihan, maka kita dapat menghemat ruang dengan menghapusnya dan waktu tanpa menggunakannya saat melatih jaringan saraf.
Mitos 5: Normalisasi batch diperlukan untuk melatih jaringan residual yang sangat dalam.
Untuk waktu yang lama diyakini bahwa "pelatihan jaringan saraf yang dalam untuk optimasi langsung hanya untuk tujuan yang terkontrol (misalnya, probabilitas logaritmik dari klasifikasi yang benar) menggunakan gradient descent, dimulai dengan parameter acak, tidak bekerja dengan baik."
Tumpukan metode cerdik inisialisasi acak, fungsi aktivasi, teknik optimasi, dan inovasi lainnya, seperti koneksi residual, yang telah muncul sejak itu memfasilitasi pelatihan jaringan saraf yang mendalam menggunakan metode gradient descent.
Tapi terobosan nyata terjadi setelah pengenalan normalisasi batch (dan teknik normalisasi sekuensial lainnya), membatasi ukuran aktivasi untuk setiap lapisan jaringan untuk menghilangkan masalah gradien menghilang dan meledak.
Dalam karya terbarunya,
Inisialisasi Fixup: Sisa Pembelajaran Tanpa Normalisasi. Zhang et al. ICLR 2019 telah menunjukkan bahwa mungkin untuk melatih jaringan dengan 10.000 lapisan menggunakan SGD murni tanpa menerapkan normalisasi apa pun.

Para penulis membandingkan pelatihan jaringan saraf residual untuk kedalaman berbeda pada CIFAR-10 dan menemukan bahwa sementara metode inisialisasi standar tidak bekerja untuk 100 lapisan, metode fixup dan normalisasi batch berhasil dengan 10.000 lapisan.

Mereka melakukan analisis teoritis dan menunjukkan bahwa "normalisasi gradien dari lapisan tertentu dibatasi oleh jumlah yang jauh meningkat dari jaringan yang dalam", yang merupakan masalah gradien eksplosif. Untuk mencegah hal ini, Foxup digunakan, ide utamanya adalah untuk menskalakan bobot dalam lapisan m untuk masing-masing cabang residu L dengan jumlah kali tergantung pada m dan L.

Fixup membantu melatih jaringan residu yang dalam dengan 110 lapisan pada CIFAR-10 dengan kecepatan belajar tinggi yang sebanding dengan perilaku jaringan arsitektur serupa yang dilatih menggunakan normalisasi batch.
Para penulis selanjutnya menunjukkan hasil tes yang sama menggunakan Fixup di jaringan tanpa normalisasi apa pun, bekerja dengan database ImageNet dan dengan terjemahan dari Bahasa Inggris ke Bahasa Jerman.
Mitos 6: Jaringan dengan perhatian lebih baik daripada yang konvolusional.
Gagasan bahwa mekanisme "perhatian" lebih unggul daripada jaringan saraf convolutional adalah mendapatkan popularitas di komunitas peneliti MO. Dalam karya
Vaswani dan rekannya , tercatat bahwa "biaya komputasi konvolusi yang dapat dilepas sama dengan kombinasi dari lapisan perhatian-diri dan lapisan umpan-maju yang bijak."
Bahkan jaringan kompetitif-generatif canggih menunjukkan keuntungan perhatian-diri atas konvolusi standar ketika memodelkan ketergantungan jangka panjang.
Kontributor
Kurang Perhatian dengan Konvolusi Ringan dan Dinamis. Wu et al. ICLR 2019 meragukan efisiensi parametrik dan efektivitas perhatian-diri ketika memodelkan ketergantungan jangka panjang, dan menawarkan opsi baru untuk konvolusi, sebagian diinspirasi oleh perhatian-diri, lebih efektif dalam hal parameter.
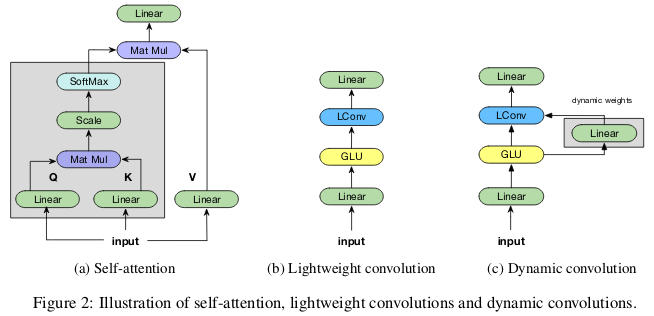
Konvolusi "ringan" dapat dipisahkan secara dalam, dimensi softmax dinormalisasi dalam waktu, dipisahkan oleh bobot dalam dimensi saluran, dan menggunakan kembali bobot yang sama pada setiap langkah waktu (sebagai jaringan saraf berulang). Konvolusi dinamis adalah konvolusi ringan yang menggunakan bobot berbeda pada setiap langkah waktu.
Trik semacam itu membuat konvolusi yang ringan dan dinamis beberapa urutan besarnya lebih efektif daripada konvolusi tak terpisahkan standar.

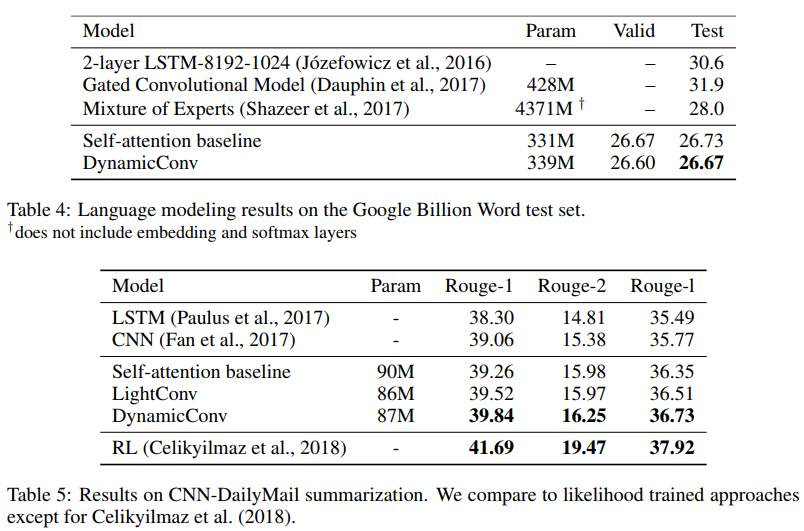
Para penulis menunjukkan bahwa konvolusi baru ini sesuai atau melebihi jaringan yang mementingkan diri sendiri dalam terjemahan mesin, pemodelan bahasa, masalah penjumlahan abstrak, menggunakan parameter yang sama atau kurang.
Mitos 7: Kartu Signifikansi - Cara yang Andal untuk Menafsirkan Jaringan Saraf
Meskipun ada pendapat bahwa jaringan saraf adalah kotak hitam, ada banyak upaya untuk menafsirkannya. Yang paling populer di antaranya adalah peta signifikansi, atau metode serupa lainnya yang menetapkan penilaian penting untuk fitur atau contoh pelatihan.
Sangat menggoda untuk dapat menyimpulkan bahwa gambar yang diberikan telah diklasifikasikan dengan cara tertentu karena bagian-bagian tertentu dari gambar yang signifikan untuk jaringan saraf. Untuk menghitung peta signifikansi, ada beberapa metode yang sering menggunakan aktivasi jaringan saraf pada gambar yang diberikan dan gradien yang melewati jaringan.
Dalam
Interpretasi Neural Networks adalah Rapuh. Ghorbani et al. Penulis
AAAI 2019 menunjukkan bahwa mereka dapat memperkenalkan perubahan yang sulit dipahami dalam gambar, yang, bagaimanapun, akan mengubah peta signifikansinya.

Jaringan saraf menentukan kupu-kupu raja bukan dengan pola pada sayapnya, tetapi karena kehadiran daun hijau yang tidak penting terhadap latar belakang foto.

Gambar multidimensi seringkali lebih dekat dengan batas keputusan yang dibuat oleh jaringan saraf yang dalam, karenanya sensitivitasnya terhadap serangan permusuhan. Dan jika serangan kompetitif memindahkan gambar di luar batas solusi, serangan interpretatif kompetitif menggeser mereka di sepanjang batas solusi tanpa meninggalkan wilayah solusi yang sama.
Metode dasar yang dikembangkan oleh penulis adalah modifikasi dari metode Goodfello untuk penandaan gradien cepat, yang merupakan salah satu metode serangan kompetitif pertama yang berhasil. Dapat diasumsikan bahwa serangan lain, yang lebih baru dan lebih kompleks juga dapat digunakan untuk serangan pada interpretasi jaringan saraf.
Konsekuensinya:Karena semakin berkembangnya pembelajaran mendalam di bidang aplikasi kritis seperti pencitraan medis, penting untuk secara cermat mendekati interpretasi keputusan yang dibuat oleh jaringan saraf. Sebagai contoh, meskipun akan lebih bagus jika jaringan saraf convolutional dapat mengenali tempat pada gambar MRI sebagai tumor ganas, hasil ini tidak boleh dipercaya jika mereka didasarkan pada metode interpretasi yang tidak dapat diandalkan.