Ini adalah bagian kedua dari serangkaian artikel tentang sistem analitik (
tautan ke bagian 1 ).

Saat ini tidak ada keraguan bahwa pemrosesan data dan interpretasi hasil yang akurat dapat membantu hampir semua jenis bisnis. Dalam hal ini, sistem analitis menjadi semakin sarat dengan parameter, jumlah pemicu dan peristiwa pengguna dalam aplikasi meningkat.
Karena itu, perusahaan memberikan analis mereka lebih banyak dan lebih banyak informasi "mentah" untuk dianalisis dan mengubahnya menjadi keputusan yang tepat. Pentingnya sistem analitik bagi perusahaan tidak boleh diremehkan, dan sistem itu sendiri harus dapat diandalkan dan berkelanjutan.
Analisis pelanggan
Analisis klien adalah layanan yang disambungkan oleh perusahaan ke situs web atau aplikasinya melalui SDK resmi, diintegrasikan ke dalam basis kode sendiri dan memilih pemicu acara. Pendekatan ini memiliki kelemahan yang jelas: semua data yang dikumpulkan tidak dapat diproses sepenuhnya seperti yang Anda inginkan, karena keterbatasan layanan yang dipilih. Misalnya, dalam satu sistem tidak akan mudah untuk menjalankan tugas-tugas MapReduce, di lain sistem Anda tidak akan dapat menjalankan model Anda. Kelemahan lain akan menjadi tagihan reguler (mengesankan) untuk layanan.
Ada banyak solusi analitik klien di pasar, tetapi cepat atau lambat, para analis dihadapkan pada kenyataan bahwa tidak ada satu layanan universal yang cocok untuk tugas apa pun (sementara harga untuk semua layanan ini terus tumbuh). Dalam situasi ini, perusahaan sering memutuskan untuk membuat sistem analitik mereka sendiri dengan semua pengaturan dan kemampuan khusus yang diperlukan.
Analisis server
Server analytics adalah layanan yang dapat digunakan secara internal di perusahaan di server sendiri dan (biasanya) dengan usahanya sendiri. Dalam model ini, semua peristiwa pengguna disimpan di server internal, yang memungkinkan pengembang untuk mencoba berbagai database penyimpanan dan memilih arsitektur yang paling nyaman. Dan bahkan jika Anda masih ingin menggunakan analitik klien pihak ketiga untuk beberapa tugas, itu masih mungkin.
Analisis server dapat digunakan dalam dua cara. Pertama: pilih beberapa utilitas open source, gunakan pada mesin Anda dan kembangkan logika bisnis.
| Pro | Cons |
| Anda dapat menyesuaikan apa pun | Seringkali sangat sulit dan pengembang individu diperlukan. |
Kedua: ambil layanan SaaS (Amazon, Google, Azure) alih-alih menggunakan sendiri. Tentang SaaS secara lebih rinci akan kami sampaikan di bagian ketiga.
| Pro | Cons |
| Mungkin lebih murah pada volume menengah, tetapi dengan pertumbuhan besar itu masih akan menjadi terlalu mahal | Tidak dapat mengontrol semua parameter |
| Administrasi sepenuhnya ditransfer ke bahu penyedia layanan | Tidak selalu diketahui apa yang ada di dalam layanan (mungkin tidak diperlukan) |
Cara mengumpulkan analitik server
Jika kita ingin melepaskan diri dari menggunakan analisis klien dan menyusun analisis kita sendiri, pertama-tama kita perlu memikirkan arsitektur sistem baru. Di bawah ini saya akan langkah demi langkah memberi tahu Anda apa yang harus dipertimbangkan, mengapa setiap langkah diperlukan dan alat apa yang dapat Anda gunakan.
1. Akuisisi data
Sama seperti dalam kasus analitik klien, pertama-tama, analis perusahaan memilih jenis peristiwa yang ingin mereka pelajari di masa depan dan mengumpulkannya ke dalam daftar. Biasanya, peristiwa ini berlangsung dalam urutan tertentu, yang disebut "pola acara".
Selanjutnya, bayangkan aplikasi seluler (situs web) memiliki pengguna reguler (perangkat) dan banyak server. Untuk mentransfer acara dari perangkat ke server dengan aman, lapisan perantara diperlukan. Bergantung pada arsitektur, beberapa antrian acara yang berbeda dapat terjadi.
Apache Kafka adalah
pub / sub antrian yang digunakan sebagai antrian untuk mengumpulkan acara.
Menurut sebuah posting di Kvor pada tahun 2014, pencipta Apache Kafka memutuskan untuk memberi nama perangkat lunak tersebut setelah Franz Kafka karena "ini adalah sistem yang dioptimalkan untuk perekaman" dan karena ia menyukai karya-karya Kafka. - Wikipedia
Dalam contoh kami, ada banyak produsen data dan konsumen mereka (perangkat dan server), dan Kafka membantu menghubungkan mereka satu sama lain. Konsumen akan dijelaskan secara lebih rinci dalam langkah-langkah selanjutnya, di mana mereka akan menjadi aktor utama. Sekarang kami hanya akan mempertimbangkan produsen data (acara).
Kafka merangkum konsep antrian dan partisi, lebih khusus, lebih baik untuk membacanya di tempat lain (misalnya, dalam
dokumentasi ). Tanpa merinci, bayangkan sebuah aplikasi seluler diluncurkan untuk dua OS yang berbeda. Kemudian setiap versi membuat aliran acara yang terpisah. Produsen mengirim acara ke Kafka, mereka direkam dalam antrian yang sesuai.
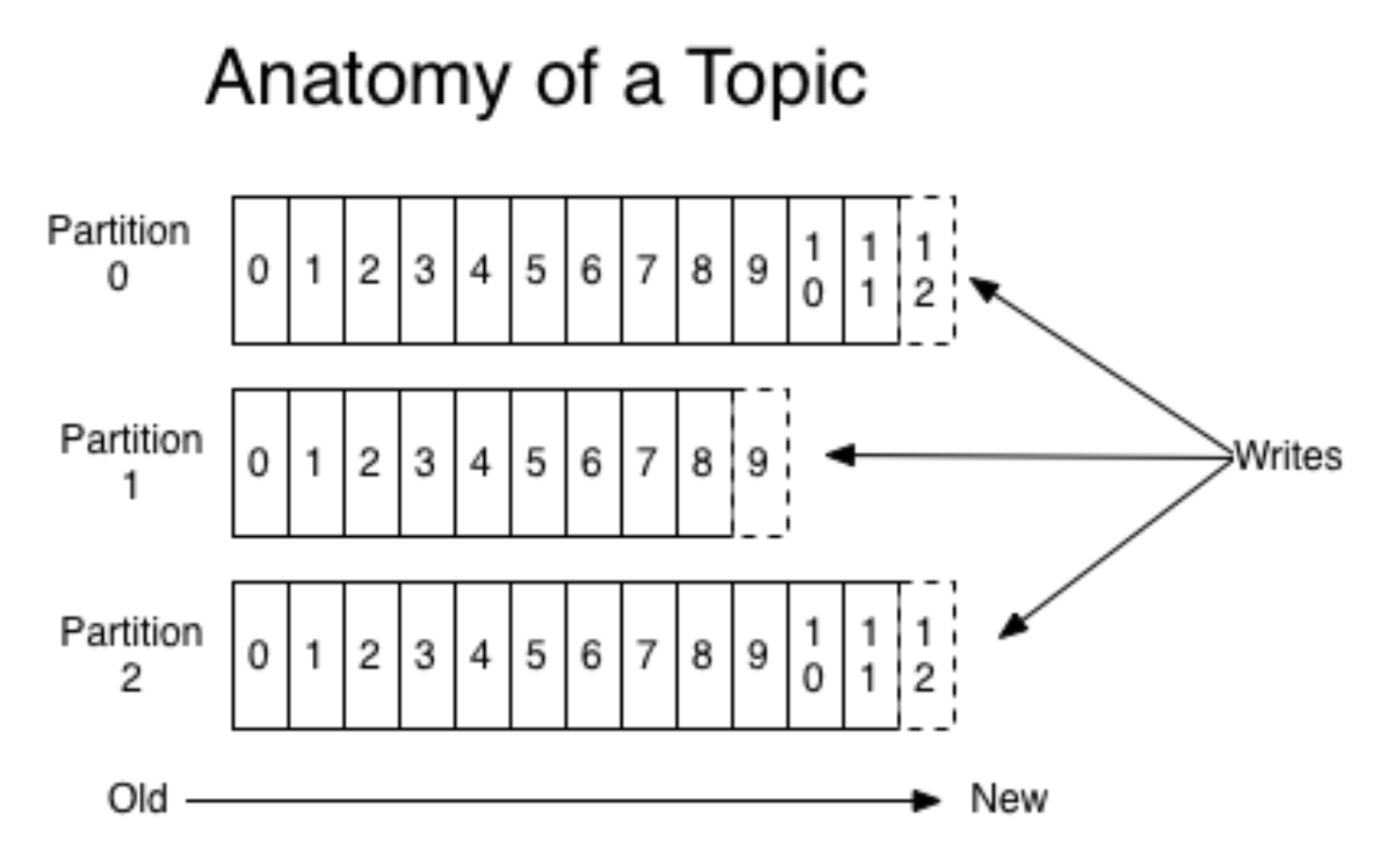
(gambar
dari sini )
Pada saat yang sama, Kafka memungkinkan Anda untuk membaca dalam keping-keping dan memproses aliran acara dengan kelelawar mini. Kafka adalah alat yang sangat nyaman yang berskala baik dengan meningkatnya kebutuhan (misalnya, dengan geolokasi acara).
Biasanya satu beling sudah cukup, tetapi hal-hal menjadi lebih sulit karena penskalaan (seperti biasa). Mungkin tidak ada yang mau menggunakan hanya satu pecahan fisik dalam produksi, karena arsitekturnya harus toleran terhadap kesalahan. Selain Kafka, ada solusi terkenal lainnya - RabbitMQ. Kami tidak menggunakannya dalam produksi sebagai antrian untuk analitik acara (jika Anda memiliki pengalaman seperti itu, beri tahu kami tentang hal itu di komentar!). Namun, mereka menggunakan AWS Kinesis.
Sebelum melanjutkan ke langkah berikutnya, kita perlu menyebutkan satu lagi lapisan tambahan sistem - penyimpanan log mentah. Ini bukan lapisan yang diperlukan, tetapi akan bermanfaat jika terjadi kesalahan dan antrian acara di Kafka diatur ulang. Penyimpanan log mentah tidak memerlukan solusi yang rumit dan mahal, Anda dapat merekamnya di suatu tempat dalam urutan yang benar (bahkan pada hard drive).

2. Event stream stream memproses
Setelah kami menyiapkan semua acara dan menempatkannya dalam antrian yang sesuai, kami melanjutkan ke langkah pemrosesan. Di sini saya akan berbicara tentang dua opsi pemrosesan yang paling umum.
Opsi pertama adalah mengaktifkan Spark Streaming pada sistem Apache. Semua produk Apache hidup dalam HDFS, sistem file replika file yang aman. Spark Streaming adalah alat yang mudah digunakan yang memproses data streaming dan skala dengan baik. Namun, ini bisa sedikit sulit untuk dipertahankan.
Pilihan lain adalah membuat event handler Anda sendiri. Untuk melakukan ini, misalnya, Anda perlu menulis aplikasi Python, membangunnya di buruh pelabuhan dan berlangganan antrian Kafka. Ketika pemicu tiba pada penangan di buruh pelabuhan, pemrosesan akan dimulai. Dengan metode ini, Anda harus terus menjalankan aplikasi.
Misalkan kita telah memilih salah satu opsi yang dijelaskan di atas dan melanjutkan ke pemrosesan itu sendiri. Prosesor harus mulai dengan memeriksa validitas data, memfilter sampah dan acara "rusak". Untuk validasi, kami biasanya menggunakan
Cerberus . Setelah itu, Anda dapat membuat pemetaan data: data dari berbagai sumber dinormalisasi dan distandarisasi untuk ditambahkan ke label umum.
3. Basis Data
Langkah ketiga adalah mempertahankan acara yang dinormalisasi. Ketika bekerja dengan sistem analitik yang siap pakai, kita sering harus menghubungi mereka, jadi penting untuk memilih basis data yang nyaman.
Jika data cocok dengan skema tetap, Anda dapat memilih
Clickhouse atau database kolom lainnya. Jadi agregasi akan bekerja dengan sangat cepat. Yang minus adalah bahwa skema tersebut diperbaiki dengan kaku dan karenanya melipat objek sewenang-wenang tanpa penyempurnaan akan gagal (misalnya, ketika peristiwa non-standar terjadi). Tetapi Anda dapat menghitung dengan sangat cepat.
Untuk data yang tidak terstruktur, Anda dapat mengambil NoSQL, misalnya,
Apache Cassandra . Ini bekerja pada HDFS, direplikasi dengan baik, Anda dapat meningkatkan banyak instance, toleran terhadap kesalahan.
Anda dapat mengambil sesuatu yang lebih sederhana, misalnya,
MongoDB . Cukup lambat dan untuk volume kecil. Namun plus adalah sangat sederhana dan karenanya cocok untuk memulai.
4. Agregasi
Setelah dengan hati-hati menyimpan semua acara, kami ingin mengumpulkan semua informasi penting dari kumpulan yang datang dan memperbarui database. Secara global, kami ingin mendapatkan dasbor dan metrik yang relevan. Misalnya, dari acara untuk mengumpulkan profil pengguna dan entah bagaimana mengukur perilaku. Acara dikumpulkan, dikumpulkan, dan disimpan lagi (sudah ada di tabel pengguna). Pada saat yang sama, Anda dapat membangun sistem sehingga Anda juga menghubungkan filter ke agregator-koordinator: kumpulkan pengguna hanya dari jenis peristiwa tertentu.
Setelah itu, jika seseorang dalam tim hanya membutuhkan analitik tingkat tinggi, Anda dapat menghubungkan sistem analitik eksternal. Anda bisa minum Mixpanel lagi. tetapi karena itu cukup mahal, mengirimkan tidak semua peristiwa pengguna di sana, tetapi hanya apa yang dibutuhkan. Untuk melakukan ini, Anda perlu membuat koordinator yang akan mengirimkan beberapa peristiwa mentah atau sesuatu yang kami kumpulkan sebelumnya ke sistem eksternal, API, atau platform iklan.
5. Frontend
Anda harus menghubungkan antarmuka ke sistem yang dibuat. Contoh yang baik adalah layanan
redash , GUI untuk database yang membantu membangun panel. Bagaimana interaksi itu bekerja:
- Pengguna membuat kueri SQL.
- Sebagai tanggapan, terima tablet.
- Baginya, dia menciptakan 'visualisasi baru' dan mendapatkan jadwal yang indah yang sudah bisa diselamatkan untuk dirinya sendiri.
Visualisasi dalam layanan diperbarui secara otomatis, Anda dapat mengonfigurasi dan melacak pemantauan Anda. Redash gratis, dalam hal di-host-sendiri, dan bagaimana SaaS akan dikenakan biaya $ 50 per bulan.

Kesimpulan
Setelah menyelesaikan semua langkah di atas, Anda akan membuat analitik server Anda. Harap perhatikan bahwa ini bukan cara yang mudah dengan hanya menghubungkan analitik klien, karena semuanya perlu dikonfigurasi secara independen. Karena itu, sebelum membuat sistem Anda sendiri, ada baiknya membandingkan kebutuhan akan sistem analisis serius dengan sumber daya yang siap Anda curahkan untuk itu.
Jika Anda menghitung semuanya dan mendapatkan bahwa biayanya terlalu tinggi, pada bagian selanjutnya saya akan berbicara tentang cara membuat versi analitik server yang lebih murah.
Terima kasih sudah membaca! Saya akan senang pertanyaan di komentar.