
Halo semuanya! Nama saya Sergey Kostanbaev, di Bursa saya sedang mengembangkan inti dari sistem perdagangan.
Ketika Bursa Efek New York ditampilkan dalam film-film Hollywood, selalu terlihat seperti ini: kerumunan orang meneriakkan sesuatu, melambaikan kertas, ada kekacauan total. Kami tidak pernah memiliki ini di Bursa Moskow, karena hampir sejak awal, perdagangan dilakukan secara elektronik dan didasarkan pada dua platform utama - Spectra (pasar derivatif) dan ASTS (mata uang, pasar saham dan pasar uang). Dan hari ini saya ingin berbicara tentang evolusi arsitektur perdagangan ASTS dan sistem kliring, tentang berbagai solusi dan temuan. Ceritanya akan panjang, jadi saya harus memecahnya menjadi dua bagian.
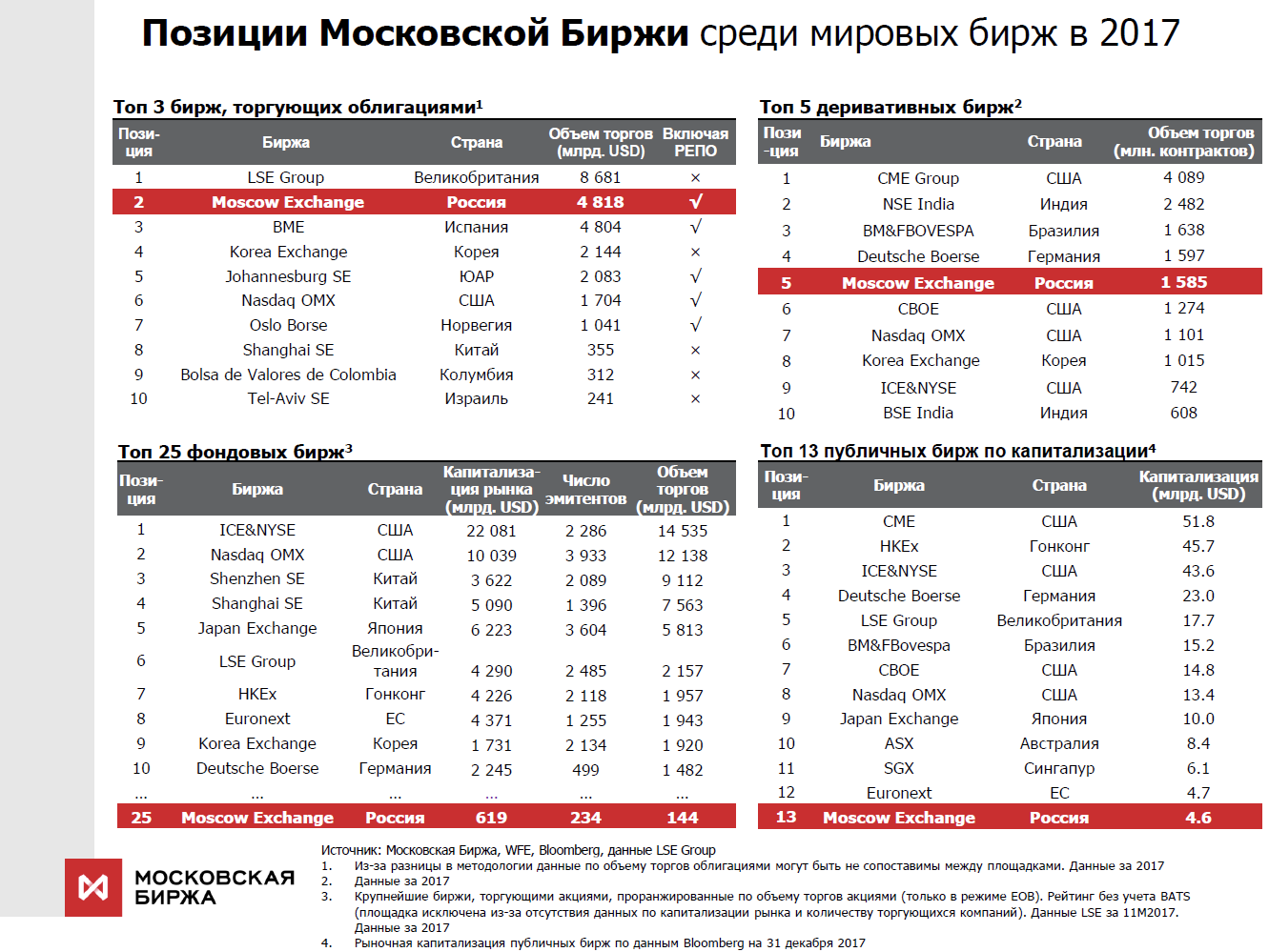
Kami adalah salah satu dari sedikit pertukaran di dunia yang memperdagangkan aset dari semua kelas dan menyediakan berbagai layanan pertukaran. Sebagai contoh, tahun lalu kami berada di peringkat kedua di dunia dalam hal perdagangan obligasi, ke-25 di antara semua bursa saham, ke-13 dengan kapitalisasi di antara bursa-bursa publik.
Untuk penawar profesional, parameter seperti waktu respons, stabilitas distribusi waktu (jitter) dan keandalan seluruh kompleks sangat penting. Saat ini, kami memproses puluhan juta transaksi per hari. Pemrosesan setiap transaksi oleh inti sistem membutuhkan puluhan mikrodetik. Tentu saja, dengan operator seluler di Tahun Baru atau dengan mesin pencari, bebannya sendiri lebih tinggi daripada kita, tetapi dalam hal beban, ditambah dengan karakteristik di atas, hanya sedikit yang bisa dibandingkan dengan kita, seperti yang menurut saya. Pada saat yang sama, penting bagi kami bahwa sistem tidak melambat sesaat, berfungsi sangat stabil, dan semua pengguna memiliki kedudukan yang sama.
Sedikit sejarah
Pada tahun 1994, sistem ASTS Australia diluncurkan di Moscow Interbank Currency Exchange (MICEX), dan mulai saat ini Anda dapat menghitung sejarah perdagangan elektronik Rusia. Pada tahun 1998, arsitektur pertukaran dimodernisasi untuk pengenalan perdagangan Internet. Sejak itu, kecepatan memperkenalkan solusi baru dan perubahan arsitektur di semua sistem dan subsistem hanya mendapatkan momentum.
Pada tahun-tahun itu, sistem pertukaran bekerja pada perangkat keras hi-end - server HP Superdome 9000 yang sangat andal (dibangun di atas
arsitektur PA-RISC ), yang menggandakan semuanya: subsistem I / O, jaringan, RAM (sebenarnya, ada array RAID dari RAM ), prosesor (hot swapping didukung). Dimungkinkan untuk mengubah komponen server apa pun tanpa menghentikan mesin. Kami mengandalkan perangkat ini, menganggapnya hampir bebas masalah. Sistem operasi adalah HP UX seperti Unix.
Tetapi sejak sekitar 2010, sebuah fenomena seperti perdagangan frekuensi tinggi (HFT), atau perdagangan frekuensi tinggi, cukup cantumkan, tukar robot, telah muncul. Hanya dalam 2,5 tahun, beban di server kami telah meningkat 140 kali.
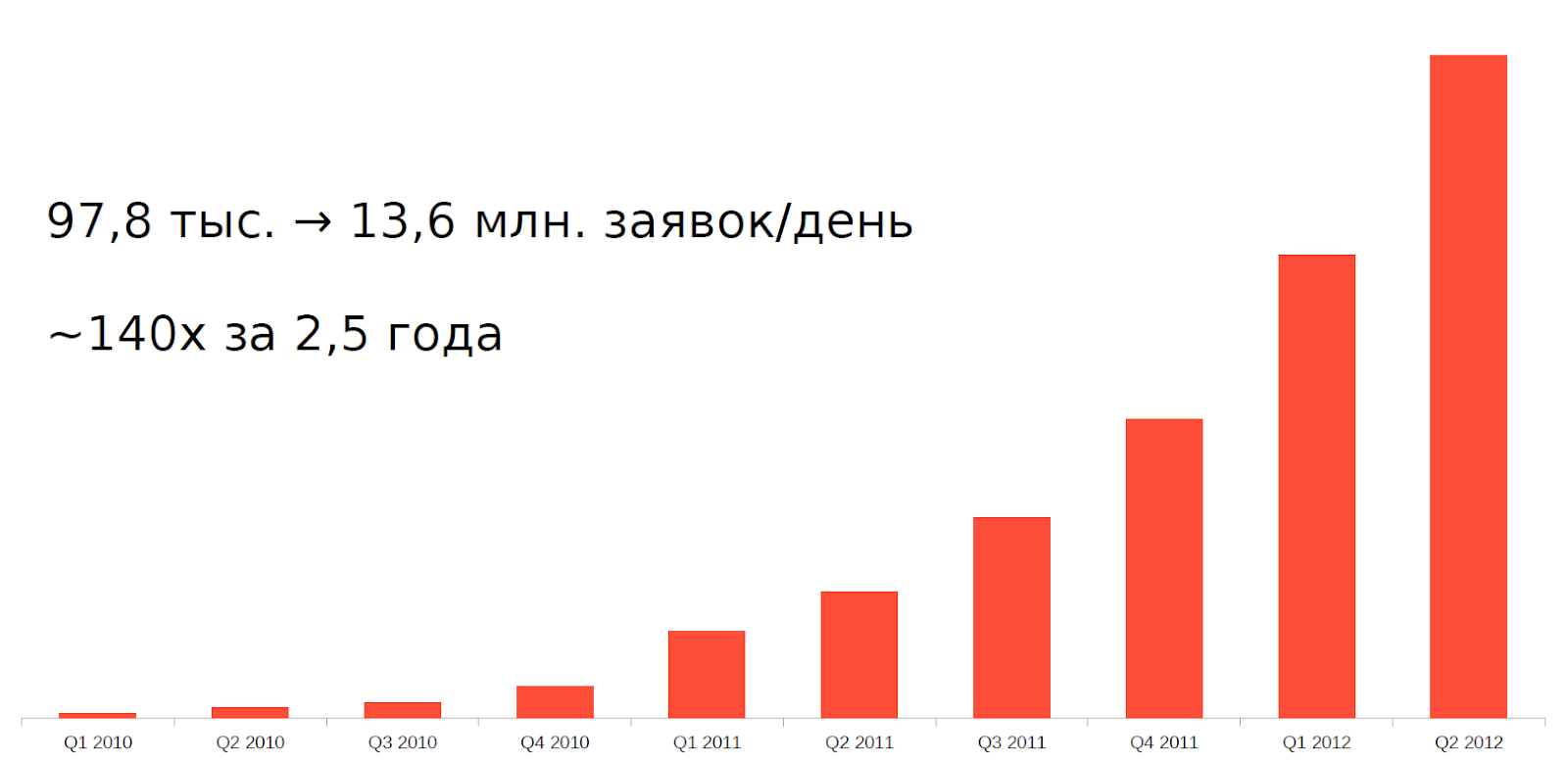
Untuk menahan beban seperti itu dengan arsitektur dan peralatan lama tidak mungkin. Itu perlu untuk beradaptasi entah bagaimana.
Mulai
Permintaan ke sistem pertukaran dapat dibagi menjadi dua jenis:
- Transaksi Jika Anda ingin membeli dolar, saham atau sesuatu yang lain, maka kirim transaksi ke sistem perdagangan dan dapatkan respons tentang keberhasilannya.
- Permintaan informasi. Jika Anda ingin mengetahui harga saat ini, lihat buku pesanan atau indeks, kemudian kirim permintaan informasi.
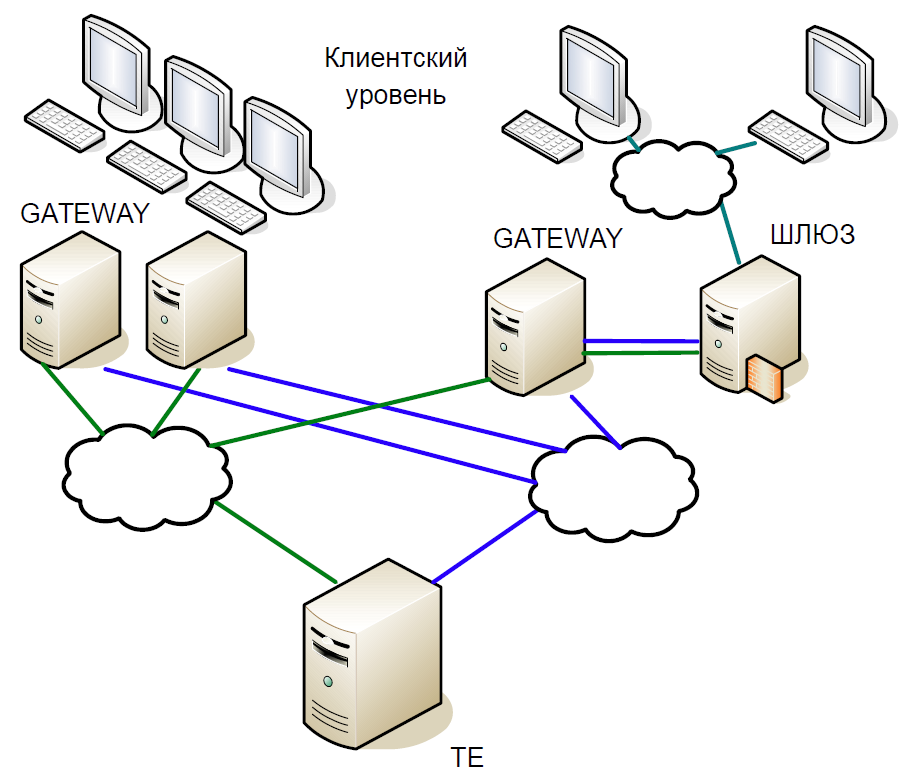
Secara skematis, inti dari sistem dapat dibagi menjadi tiga tingkatan:
- Tingkat klien di mana broker dan klien bekerja. Semuanya berinteraksi dengan server akses.
- Server akses (Gateway) adalah server caching yang secara lokal memproses semua permintaan informasi. Ingin tahu berapa harga saham Sberbank sekarang diperdagangkan? Permintaan masuk ke server akses.
- Tetapi jika Anda ingin membeli saham, maka permintaan sudah ada di server pusat (Trade Engine). Ada satu server seperti itu untuk setiap jenis pasar, mereka memainkan peran penting, dan demi kepentingan itulah kami menciptakan sistem ini.
Inti dari sistem perdagangan adalah database dalam-memori yang rumit di mana semua transaksi merupakan transaksi pertukaran. Basis ditulis dalam C, dari dependensi eksternal hanya ada perpustakaan libc dan sama sekali tidak ada alokasi memori dinamis. Untuk mengurangi waktu pemrosesan, sistem dimulai dengan serangkaian array statis dan dengan relokasi data statis: pertama, semua data untuk hari ini dimuat ke dalam memori, dan kemudian tidak ada disk mengakses, semua pekerjaan hanya dilakukan dalam memori. Ketika sistem dimulai, semua data referensi sudah diurutkan, sehingga pencarian bekerja dengan sangat efisien dan membutuhkan sedikit waktu dalam runtime. Semua tabel dibuat dengan daftar dan pohon intrusif untuk struktur data dinamis sehingga tidak memerlukan alokasi memori saat runtime.
Mari kita secara singkat membahas sejarah pengembangan sistem perdagangan dan kliring kami.
Versi pertama arsitektur sistem perdagangan dan kliring dibangun di atas apa yang disebut interaksi Unix: memori bersama, semafor dan antrian digunakan, dan setiap proses terdiri dari satu utas. Pendekatan ini tersebar luas pada awal 1990-an.
Versi pertama dari sistem berisi dua tingkat Gateway dan server pusat dari sistem perdagangan. Skema kerjanya adalah sebagai berikut:
- Klien mengirim permintaan yang mengenai Gateway. Dia memeriksa validitas format (tetapi bukan data itu sendiri) dan menolak transaksi yang salah.
- Jika permintaan informasi telah dikirim, maka itu dieksekusi secara lokal; jika itu adalah transaksi, maka itu dialihkan ke server pusat.
- Kemudian mesin perdagangan memproses transaksi, mengubah memori lokal dan mengirimkan respons terhadap transaksi, dan itu sendiri - untuk replikasi menggunakan mekanisme replikasi yang terpisah.
- Gateway menerima respons dari simpul pusat dan mengalihkannya ke klien.
- Setelah beberapa saat, Gateway menerima transaksi menggunakan mekanisme replikasi, dan kali ini mengeksekusi secara lokal, mengubah struktur datanya sehingga permintaan informasi berikut menampilkan data aktual.
Bahkan, model replikasi dijelaskan di sini, di mana Gateway sepenuhnya mengulangi tindakan yang dilakukan dalam sistem perdagangan. Saluran replikasi terpisah memberikan urutan eksekusi transaksi yang sama pada beberapa node akses.
Karena kode tersebut adalah single-threaded, skema klasik dengan proses bercabang digunakan untuk melayani banyak klien. Namun, membuat garpu untuk seluruh database sangat mahal, sehingga proses layanan ringan digunakan yang mengumpulkan paket dari sesi TCP dan mentransfernya ke satu antrian (SystemV Message Queue). Gateway dan Trade Engine hanya bekerja dengan antrian ini, mengambil transaksi untuk dieksekusi dari sana. Sudah tidak mungkin mengirim jawaban untuk itu, karena tidak jelas proses layanan mana yang harus membacanya. Jadi kami menggunakan trik: setiap proses bercabang menciptakan antrian respons untuk dirinya sendiri, dan ketika permintaan masuk dalam antrian masuk, tag untuk antrian respons segera ditambahkan ke dalamnya.
Menyalin konstan dari antrian ke antrian sejumlah besar data menciptakan masalah, terutama karakteristik permintaan informasi. Oleh karena itu, kami mengambil keuntungan dari trik lain: selain antrian respons, setiap proses juga membuat memori bersama (SystemV Shared Memory). Paket-paket itu sendiri ditempatkan di dalamnya, dan hanya tag yang disimpan dalam antrian, memungkinkan Anda menemukan paket sumber. Ini membantu menyimpan data dalam cache prosesor.
SystemV IPC mencakup utilitas untuk melihat status antrian, memori, dan objek semafor. Kami secara aktif menggunakan ini untuk memahami apa yang terjadi dalam sistem pada saat tertentu, di mana paket terakumulasi, yang diblokir, dll.
Modernisasi pertama
Pertama-tama, kami menyingkirkan Gateway proses tunggal. Kekurangannya yang signifikan adalah dapat memproses satu transaksi replikasi atau satu permintaan informasi dari klien. Dan dengan meningkatnya beban, Gateway akan memproses permintaan lebih lama dan tidak akan dapat memproses aliran replikasi. Selain itu, jika klien mengirim transaksi, maka Anda hanya perlu memeriksa validitasnya dan meneruskannya lebih lanjut. Oleh karena itu, kami mengganti satu proses Gateway dengan banyak komponen yang dapat bekerja secara paralel: informasi multithreaded dan proses transaksional yang bekerja secara independen satu sama lain dengan area memori umum menggunakan RW-lock. Dan pada saat yang sama kami memperkenalkan proses penjadwalan dan replikasi.
Dampak dari perdagangan frekuensi tinggi
Versi arsitektur di atas berlangsung hingga 2010. Sementara itu, kami tidak lagi puas dengan kinerja server HP Superdome. Selain itu, arsitektur PA-RISC benar-benar mati, vendor tidak menawarkan pembaruan signifikan. Sebagai hasilnya, kami mulai beralih dari HP UX / PA RISC ke Linux / x86. Transisi dimulai dengan adaptasi akses server.
Kenapa kita harus mengubah arsitektur lagi? Faktanya adalah bahwa perdagangan frekuensi tinggi telah secara signifikan mengubah profil beban inti sistem.
Misalkan kita memiliki transaksi kecil yang menyebabkan perubahan harga yang signifikan - seseorang membeli setengah miliar dolar. Setelah beberapa milidetik, semua pelaku pasar memperhatikan hal ini dan mulai memberikan koreksi. Secara alami, permintaan berbaris dalam antrian besar, yang akan dikerjakan sistem untuk waktu yang lama.

Pada interval 50 ms ini, kecepatan rata-rata sekitar 16 ribu transaksi per detik. Jika Anda mengurangi jendela hingga 20 ms, kami mendapatkan kecepatan rata-rata 90 ribu transaksi per detik, dan pada puncaknya akan ada 200 ribu transaksi. Dengan kata lain, bebannya tidak stabil, dengan semburan yang tajam. Dan antrian permintaan harus selalu diproses dengan cepat.
Tapi mengapa ada antrian sama sekali? Jadi, dalam contoh kami, banyak pengguna memperhatikan perubahan harga dan mengirim transaksi yang sesuai. Mereka datang ke Gateway, ia membuat serial mereka, menetapkan urutan tertentu dan mengirimkannya ke jaringan. Router mencampur paket dan meneruskannya. Paket siapa datang lebih awal, transaksi itu "menang". Akibatnya, pelanggan pertukaran mulai memperhatikan bahwa jika transaksi yang sama dikirim dari beberapa Gateways, maka kemungkinan pemrosesan cepatnya meningkat. Segera, robot pertukaran mulai membombardir Gateway dengan permintaan, dan longsoran transaksi muncul.

Babak baru evolusi
Setelah pengujian dan penelitian yang ekstensif, kami beralih ke kernel real-time dari sistem operasi. Untuk melakukan ini, mereka memilih RedHat Enterprise MRG Linux, di mana MRG adalah singkatan dari kotak pesan real-time. Keuntungan dari tambalan waktu nyata adalah tambalan itu mengoptimalkan sistem untuk eksekusi tercepat yang mungkin: semua proses diatur dalam antrian FIFO, Anda dapat mengisolasi kernel, tanpa tetes, semua transaksi diproses dalam urutan yang ketat.
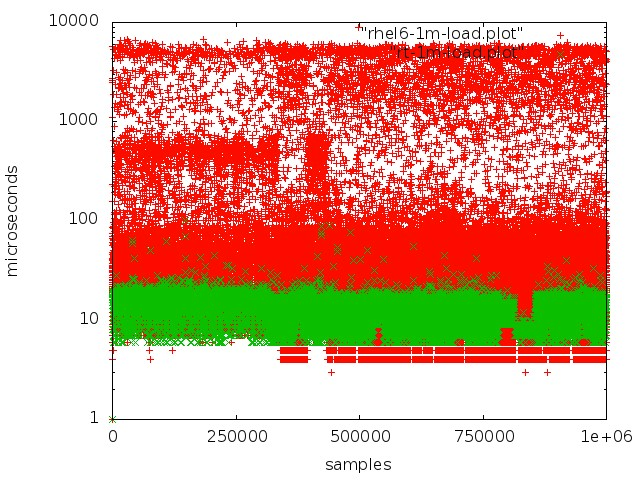 Merah - bekerja dengan antrian di kernel reguler, hijau - bekerja di kernel real-time.
Merah - bekerja dengan antrian di kernel reguler, hijau - bekerja di kernel real-time.Tetapi mencapai latensi rendah di server biasa tidak begitu sederhana:
- Mode SMI, yang dalam arsitektur x86 terletak di jantung bekerja dengan periferal penting, sangat mengganggu. Memproses berbagai peristiwa perangkat keras dan mengelola komponen dan perangkat dilakukan oleh firmware dalam apa yang disebut mode SMI transparan, di mana sistem operasi tidak melihat apa yang dilakukan firmware sama sekali. Sebagai aturan, semua vendor utama menawarkan ekstensi khusus untuk server firmware, yang memungkinkan pengurangan jumlah pemrosesan SMI.
- Seharusnya tidak ada kontrol dinamis dari frekuensi prosesor, ini mengarah ke downtime tambahan.
- Ketika log sistem file diatur ulang, proses-proses tertentu terjadi pada kernel yang menyebabkan penundaan yang tidak terduga.
- Anda perlu memperhatikan hal-hal seperti Affinity CPU, Interrupt afinity, NUMA.
Saya harus mengatakan bahwa topik mengkonfigurasi perangkat keras dan kernel Linux untuk pemrosesan realtime layak mendapat artikel terpisah. Kami menghabiskan banyak waktu untuk eksperimen dan penelitian sebelum kami mencapai hasil yang baik.
Ketika beralih dari server PA-RISC ke x86, kami praktis tidak harus banyak mengubah kode sistem, kami hanya mengadaptasi dan mengkonfigurasi ulang. Pada saat yang sama, beberapa bug diperbaiki. Misalnya, konsekuensi dengan cepat muncul bahwa PA RISC adalah sistem Big endian dan x86 sistem Little endian: misalnya, data tidak dibaca dengan benar. Bug yang lebih rumit adalah bahwa PA RISC menggunakan akses memori
konsisten Sequential , sementara x86 dapat menyusun ulang operasi baca, sehingga kode yang benar-benar valid pada satu platform menjadi tidak beroperasi pada yang lain.
Setelah beralih ke x86, produktivitas meningkat hampir tiga kali lipat, waktu pemrosesan transaksi rata-rata turun menjadi 60 μs.
Sekarang mari kita melihat lebih dekat perubahan kunci apa yang telah dibuat pada arsitektur sistem.
Hot Standby Epic
Beralih ke server komoditas, kami menyadari bahwa mereka kurang dapat diandalkan. Karena itu, ketika membuat arsitektur baru, kami apriori mengasumsikan kemungkinan kegagalan satu atau lebih node. Oleh karena itu, kami membutuhkan sistem siaga panas yang dapat beralih dengan sangat cepat ke mesin cadangan.
Selain itu, ada persyaratan lain:
- Dalam hal apapun Anda tidak boleh kehilangan transaksi yang diproses.
- Sistem harus benar-benar transparan untuk infrastruktur kami.
- Klien seharusnya tidak melihat koneksi terputus.
- Reservasi tidak boleh menyebabkan penundaan yang signifikan, karena ini merupakan faktor penting untuk pertukaran.
Saat membuat sistem siaga panas, kami tidak menganggap skenario seperti itu sebagai kegagalan ganda (misalnya, jaringan pada satu server berhenti bekerja dan server utama macet); tidak mempertimbangkan kemungkinan kesalahan dalam perangkat lunak, karena mereka terdeteksi selama pengujian; dan tidak mempertimbangkan tidak berfungsinya besi.
Akibatnya, kami sampai pada skema berikut:
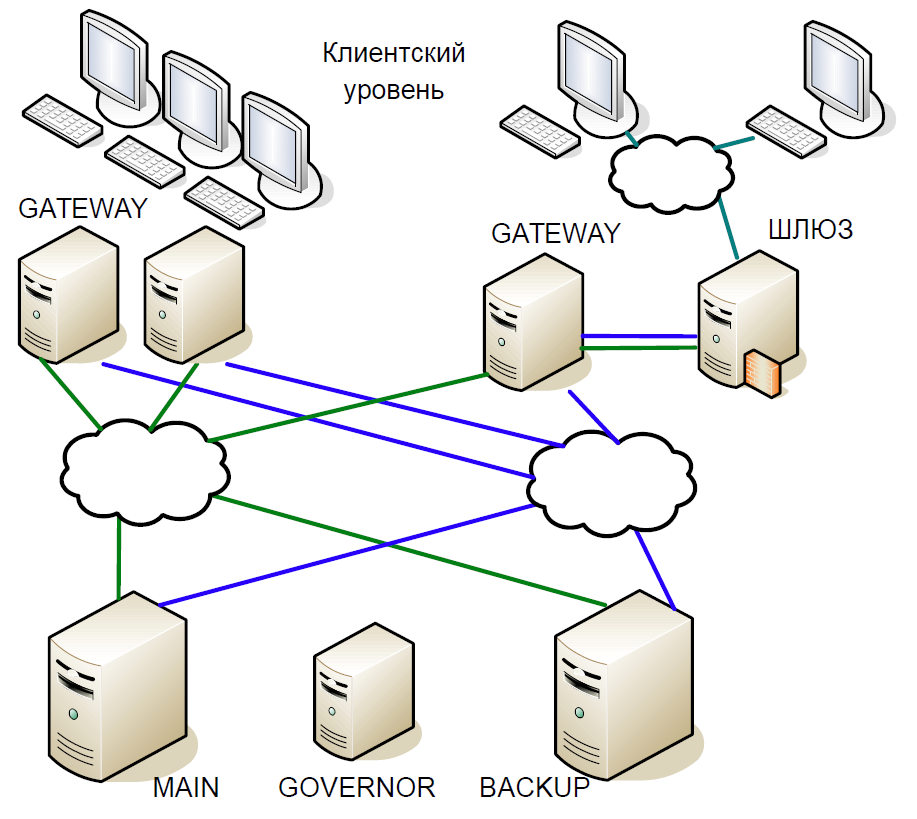
- Server utama berinteraksi langsung dengan server Gateway.
- Semua transaksi yang diterima di server utama langsung direplikasi ke server cadangan melalui saluran terpisah. Wasit (Gubernur) mengoordinasikan sakelar ketika terjadi masalah.
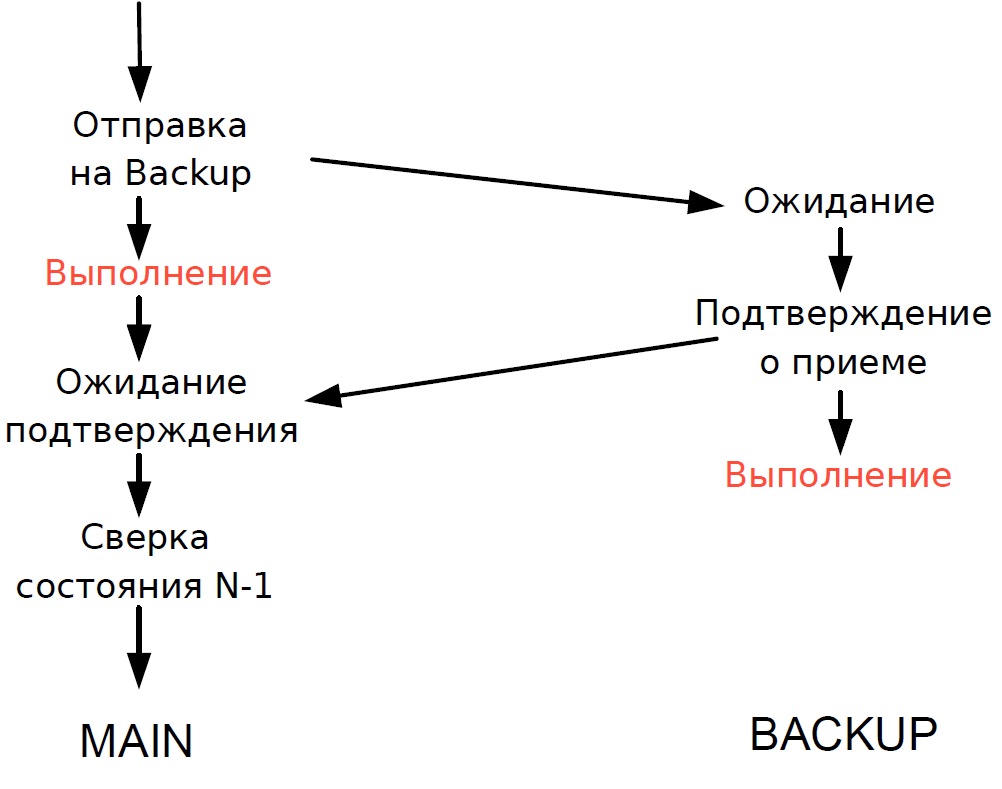
- Server utama memproses setiap transaksi dan menunggu konfirmasi dari server cadangan. Untuk meminimalkan keterlambatan, kami menolak untuk menunggu transaksi diselesaikan di server cadangan. Karena durasi transaksi melalui jaringan sebanding dengan durasi transaksi, tidak ada penundaan tambahan yang ditambahkan.
- Kami dapat memverifikasi status pemrosesan server utama dan cadangan hanya untuk transaksi sebelumnya, dan status pemrosesan transaksi saat ini tidak diketahui. Karena proses single-threaded masih digunakan di sini, menunggu respons dari Cadangan akan memperlambat seluruh aliran pemrosesan, dan karenanya kami membuat kompromi yang masuk akal: kami memeriksa hasil transaksi sebelumnya.

Skema ini bekerja sebagai berikut.
Misalkan server utama berhenti merespons, tetapi Gateway terus berkomunikasi. Di server cadangan, batas waktu dipicu, beralih ke Gubernur, dan yang terakhir menugaskannya peran server utama, dan semua Gateway beralih ke server utama yang baru.
Jika server utama kembali beroperasi, batas waktu internal juga dipicu, karena untuk beberapa waktu tidak ada panggilan ke server dari Gateway. Kemudian dia juga berpaling ke Gubernur, dan dia mengeluarkannya dari skema. Akibatnya, pertukaran bekerja dengan satu server hingga akhir periode perdagangan. Karena kemungkinan server crash agak rendah, skema seperti itu dianggap cukup dapat diterima, itu tidak mengandung logika yang kompleks dan mudah diuji.
Untuk dilanjutkan.