
Ini adalah kelanjutan dari cerita panjang tentang jalan berduri kami untuk menciptakan sistem yang kuat dan penuh muatan yang menjamin operasi Bursa.
Bagian pertama ada di sini .
Kesalahan misterius
Setelah banyak pengujian, sistem perdagangan dan kliring yang diperbarui dioperasikan, dan kami bertemu dengan bug tentang apa yang tepat untuk menulis cerita detektif mistis.
Segera setelah memulai pada server utama, salah satu transaksi diproses dengan kesalahan. Pada saat yang sama, semuanya beres di server cadangan. Ternyata operasi matematika sederhana untuk menghitung eksponen pada server utama memberikan hasil negatif dari argumen yang valid! Survei berlanjut, dan dalam register SSE2 mereka menemukan perbedaan dalam satu bit, yang bertanggung jawab untuk pembulatan ketika bekerja dengan angka floating point.
Mereka menulis sebuah utilitas tes sederhana untuk menghitung eksponen dengan set bit pembulatan. Ternyata dalam versi RedHat Linux yang kami gunakan, ada bug dalam bekerja dengan fungsi matematika ketika bit naas dimasukkan. Kami melaporkan ini ke RedHat, setelah beberapa saat kami menerima patch dari mereka dan menggulungnya. Kesalahan tidak lagi terjadi, tetapi tidak jelas dari mana datangnya bit ini? Fungsi
fesetround dari C bertanggung jawab untuk itu. Kami dengan hati-hati menganalisis kode kami untuk mencari dugaan kesalahan: memeriksa semua situasi yang mungkin; mempertimbangkan semua fungsi yang menggunakan pembulatan; mencoba memainkan sesi yang gagal; menggunakan kompiler berbeda dengan opsi berbeda; menggunakan analisis statis dan dinamis.
Penyebab kesalahan tidak dapat ditemukan.
Kemudian mereka mulai memeriksa perangkat keras: mereka melakukan uji beban prosesor; memeriksa RAM; bahkan menjalankan tes untuk skenario yang sangat tidak mungkin dari kesalahan multi-bit dalam satu sel. Tidak berhasil.
Pada akhirnya, mereka menetapkan teori-teori dari dunia fisika berenergi tinggi: beberapa partikel berenergi tinggi terbang ke pusat data kami, menerobos dinding kasing, menabrak prosesor dan menyebabkan kait pelatuk menempel di bagian yang sama. Teori absurd ini disebut "neutrino." Jika Anda jauh dari fisika partikel elementer: neutrino jarang berinteraksi dengan dunia luar, dan tentu saja mereka tidak dapat memengaruhi prosesor.
Karena tidak mungkin untuk menemukan penyebab kegagalan, kalau-kalau mereka mengecualikan server "nakal" dari operasi.
Setelah beberapa waktu, kami mulai meningkatkan sistem siaga panas: kami memperkenalkan apa yang disebut "cadangan panas" (replika asinkron). Mereka menerima aliran transaksi yang mungkin ada di pusat data yang berbeda, tetapi hangat tidak mendukung interaksi aktif dengan server lain.
Mengapa ini dilakukan? Jika server cadangan gagal, maka koneksi hangat ke server utama menjadi cadangan baru. Artinya, setelah kegagalan, sistem tidak tetap sampai akhir sesi perdagangan dengan satu server utama.
Dan ketika versi baru dari sistem diuji dan dioperasikan, kesalahan dengan pembulatan kembali terjadi. Selain itu, dengan meningkatnya jumlah server yang hangat, kesalahan mulai muncul lebih sering. Dalam hal ini, vendor tidak memiliki apa pun untuk disajikan, karena tidak ada bukti nyata.
Selama analisis situasi selanjutnya, muncul teori bahwa masalahnya bisa terkait dengan OS. Kami menulis sebuah program sederhana yang memanggil fungsi
fesetround dalam loop tanpa akhir, mengingat keadaan saat ini dan memeriksanya melalui sleep, dan ini dilakukan di banyak utas yang bersaing. Setelah memilih parameter tidur dan jumlah utas, kami mulai mereproduksi kegagalan bit secara stabil setelah sekitar 5 menit utilitas. Namun, dukungan Red Hat tidak dapat mereproduksi itu. Pengujian server kami yang lain menunjukkan bahwa hanya mereka yang memasang prosesor tertentu yang terpengaruh oleh kesalahan tersebut. Pada saat yang sama, transisi ke inti baru menyelesaikan masalah. Pada akhirnya, kami baru saja mengganti OS, dan penyebab sebenarnya dari bug itu masih belum jelas.
Dan tiba-tiba tahun lalu sebuah artikel muncul di Habré "
Bagaimana saya menemukan bug dalam prosesor Intel Skylake ". Situasi yang digambarkan di dalamnya sangat mirip dengan situasi kita, tetapi penulis maju lebih jauh dalam penyelidikan dan mengajukan teori bahwa kesalahan ada dalam mikrokode. Dan ketika memperbarui kernel Linux, pabrikan juga memperbarui mikrokode.
Pengembangan sistem lebih lanjut
Meskipun kami menyingkirkan kesalahan, cerita ini membuat kami mempertimbangkan kembali arsitektur sistem lagi. Bagaimanapun, kami tidak terlindungi dari pengulangan bug semacam itu.
Prinsip-prinsip berikut membentuk dasar untuk perbaikan lebih lanjut pada sistem cadangan:
- Anda tidak bisa mempercayai siapa pun. Server mungkin tidak berfungsi dengan baik.
- Redundansi mayoritas.
- Pembangunan konsensus. Sebagai pelengkap logis untuk redundansi mayoritas.
- Kegagalan ganda dimungkinkan.
- Vitalitas. Skema cadangan panas baru seharusnya tidak lebih buruk dari yang sebelumnya. Perdagangan harus berjalan lancar sampai server terakhir.
- Sedikit peningkatan keterlambatan. Setiap downtime menyebabkan kerugian finansial yang sangat besar.
- Interaksi jaringan minimum sehingga keterlambatan serendah mungkin.
- Pilih server master baru dalam hitungan detik.
Tidak ada solusi yang tersedia di pasaran yang cocok untuk kami, dan protokol Raft baru dalam masa pertumbuhan, jadi kami menciptakan solusi kami sendiri.

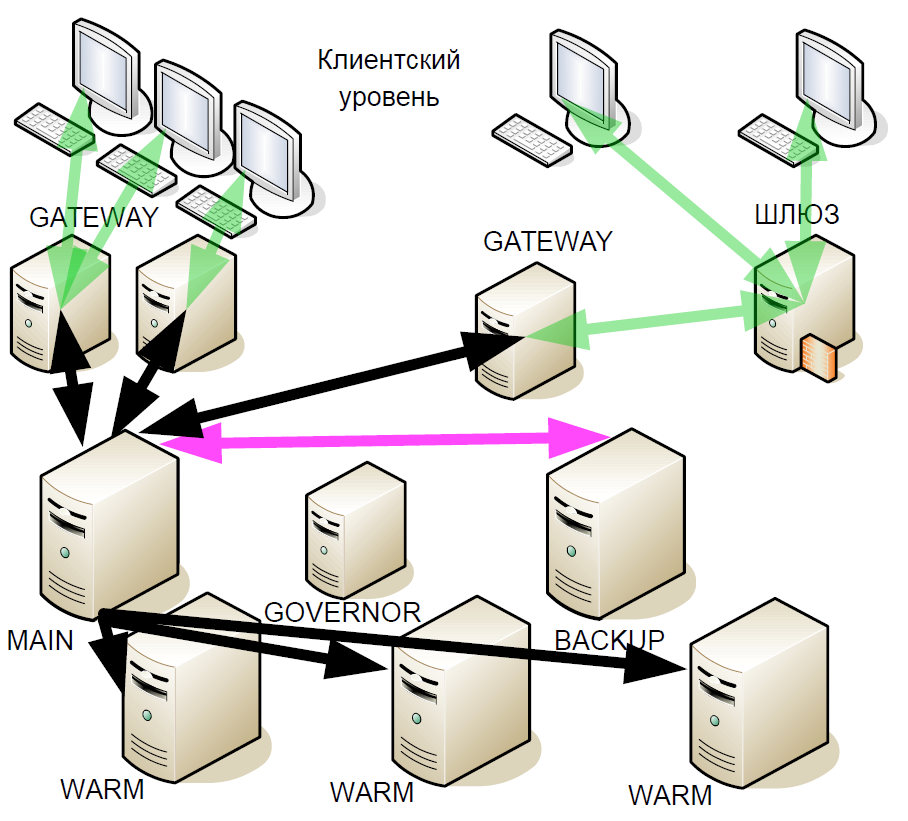
Konektivitas jaringan
Selain sistem cadangan, kami mulai memodernkan konektivitas jaringan. Subsistem I / O adalah banyak proses, yang dalam cara terburuk mempengaruhi jitter dan delay. Memiliki ratusan proses yang memproses koneksi TCP, kami dipaksa untuk terus-menerus beralih di antara mereka, dan dalam skala mikrodetik, ini adalah operasi yang agak panjang. Tetapi bagian terburuknya adalah ketika suatu proses menerima paket untuk diproses, ia mengirimnya ke satu antrian SystemV, dan kemudian menunggu kejadian dari antrian SystemV lain. Namun, dengan sejumlah besar node, kedatangan paket TCP baru dalam satu proses dan penerimaan data dalam antrian di lain merupakan dua peristiwa yang bersaing untuk OS. Dalam hal ini, jika tidak ada prosesor fisik yang tersedia untuk kedua tugas, satu akan diproses, dan yang kedua akan berdiri dalam antrian menunggu. Tidak mungkin untuk memprediksi konsekuensinya.
Dalam situasi seperti itu, Anda dapat menerapkan kontrol prioritas proses dinamis, tetapi ini akan membutuhkan penggunaan panggilan sistem intensif sumber daya. Akibatnya, kami beralih ke satu utas menggunakan epoll klasik, ini sangat meningkatkan kecepatan dan mengurangi waktu pemrosesan transaksi. Kami juga menyingkirkan proses tertentu dari interaksi dan interaksi jaringan melalui SystemV, secara signifikan mengurangi jumlah panggilan sistem dan mulai mengendalikan prioritas operasi. Dengan hanya menggunakan satu subsistem I / O, dimungkinkan untuk menyimpan sekitar 8-17 mikrodetik, tergantung pada skenario. Skema single-threaded ini sejak itu diterapkan tidak berubah, satu aliran epoll dengan margin cukup untuk melayani semua koneksi.
Pemrosesan transaksi
Tumbuhnya beban pada sistem kami membutuhkan modernisasi hampir semua komponennya. Tapi, sayangnya, stagnasi dalam peningkatan kecepatan clock prosesor dalam beberapa tahun terakhir tidak lagi memungkinkan kita untuk skala proses "langsung". Oleh karena itu, kami memutuskan untuk membagi proses Engine menjadi tiga tingkatan, yang paling banyak memuatnya adalah sistem verifikasi risiko, yang menilai ketersediaan dana di akun dan membuat transaksi sendiri. Tetapi uang bisa dalam mata uang yang berbeda, dan perlu untuk mencari tahu apa prinsip untuk membagi pemrosesan permintaan.
Solusi logis adalah dengan membagi berdasarkan mata uang: satu server berdagang dalam dolar, yang lain dalam pound, dan euro ketiga. Tetapi jika, dengan skema seperti itu, dua transaksi dikirim untuk membeli mata uang yang berbeda, maka akan ada masalah dompet tidak sinkron. Dan sinkronisasi itu sulit dan mahal. Oleh karena itu, akan benar untuk shard secara terpisah di dompet dan secara terpisah pada alat. Ngomong-ngomong, di sebagian besar bursa barat tugas memeriksa risiko tidak seakurat risiko kita, jadi paling sering ini dilakukan secara offline. Kami perlu menerapkan pemeriksaan online.
Mari kita ilustrasikan dengan sebuah contoh. Pedagang ingin membeli $ 30, dan permintaannya untuk memvalidasi transaksi: kami memeriksa apakah pedagang ini diizinkan untuk mode perdagangan ini, apakah ia memiliki hak yang diperlukan. Jika semuanya beres, permintaan masuk ke sistem verifikasi risiko, mis. untuk memverifikasi kecukupan dana untuk menyelesaikan transaksi. Ada catatan bahwa jumlah yang diperlukan saat ini diblokir. Selanjutnya, permintaan tersebut dialihkan ke sistem perdagangan, yang menyetujui atau tidak menyetujui transaksi ini. Katakanlah transaksi disetujui - maka sistem verifikasi risiko mencatat bahwa uang tidak terkunci dan rubel dikonversi menjadi dolar.
Secara umum, sistem verifikasi risiko mengandung algoritme yang rumit dan melakukan perhitungan sangat intensif sumber daya dalam jumlah besar, dan tidak hanya memeriksa "saldo akun", seperti yang terlihat pada pandangan pertama.
Ketika kami mulai membagi proses Engine menjadi level, kami mengalami masalah: kode yang tersedia pada saat itu pada tahap validasi dan verifikasi secara aktif menggunakan array data yang sama, yang mengharuskan penulisan ulang seluruh basis kode. Sebagai hasilnya, kami meminjam metodologi untuk memproses instruksi dari prosesor modern: masing-masing dibagi menjadi beberapa tahap kecil dan beberapa tindakan dilakukan secara paralel dalam satu siklus.
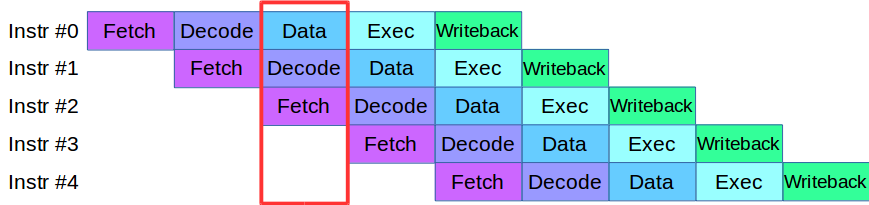
Setelah sedikit adaptasi kode, kami membuat pipa untuk pemrosesan transaksi paralel, di mana transaksi dibagi menjadi 4 tahap pipa: interaksi jaringan, validasi, eksekusi, dan publikasi hasil

Pertimbangkan sebuah contoh. Kami memiliki dua sistem pemrosesan, serial dan paralel. Transaksi pertama tiba, dan dalam kedua sistem itu berlaku untuk validasi. Kemudian transaksi kedua tiba: dalam sistem paralel, ia segera dibawa untuk bekerja, dan dalam sistem berurutan ia antri menunggu transaksi pertama melewati tahap pemrosesan saat ini. Artinya, keuntungan utama pipelining adalah kami memproses antrian transaksi lebih cepat.
Jadi kami mendapat sistem ASTS +.
Benar, dengan konveyor juga, tidak semuanya lancar. Misalkan kita memiliki transaksi yang mempengaruhi array data dalam transaksi tetangga, ini adalah situasi khas untuk pertukaran. Transaksi semacam itu tidak dapat dieksekusi dalam pipa, karena dapat mempengaruhi orang lain. Situasi ini disebut bahaya data, dan transaksi semacam itu hanya diproses secara terpisah: ketika transaksi "cepat" di ujung antrian, pipa berhenti, sistem memproses transaksi "lambat" dan kemudian memulai pipa lagi. Untungnya, bagian dari transaksi tersebut dalam aliran total sangat kecil, sehingga pipa berhenti sangat jarang sehingga tidak mempengaruhi kinerja keseluruhan.

Kemudian kami mulai memecahkan masalah sinkronisasi tiga utas eksekusi. Akibatnya, sebuah sistem yang didasarkan pada buffer melingkar dengan sel ukuran tetap lahir. Dalam sistem ini, semuanya tergantung pada kecepatan pemrosesan, data tidak disalin.
- Semua paket jaringan masuk ke dalam tahap alokasi.
- Kami menempatkan mereka dalam array dan menandai bahwa mereka tersedia untuk tahap No. 1.
- Transaksi kedua datang, sekali lagi tersedia untuk tahap No. 1.
- Aliran pemrosesan pertama melihat transaksi yang tersedia, memprosesnya, dan mentransfernya ke tahap berikutnya dari aliran pemrosesan kedua.
- Kemudian memproses transaksi pertama dan menandai sel yang sesuai dengan bendera yang
deleted - sekarang tersedia untuk penggunaan baru.
Dengan demikian, seluruh antrian diproses.
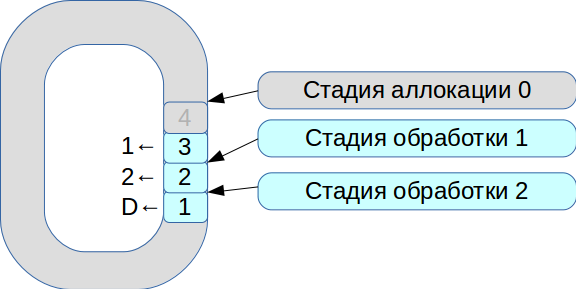
Pemrosesan setiap tahap membutuhkan satuan atau puluhan mikrodetik. Dan jika Anda menggunakan skema sinkronisasi OS standar, maka kita akan kehilangan lebih banyak waktu pada sinkronisasi itu sendiri. Karena itu, kami mulai menggunakan spinlock. Namun, ini adalah nada yang sangat buruk dalam sistem waktu nyata, dan RedHat sangat menyarankan untuk tidak melakukan ini, jadi kami menggunakan spinlock selama 100 ms, dan kemudian masuk ke mode semaphore untuk mengecualikan kemungkinan kebuntuan.
Sebagai hasilnya, kami mencapai kinerja sekitar 8 juta transaksi per detik. Dan hanya dua bulan kemudian, dalam sebuah
artikel tentang LMAX Disruptor, mereka melihat deskripsi sirkuit dengan fungsi yang sama.
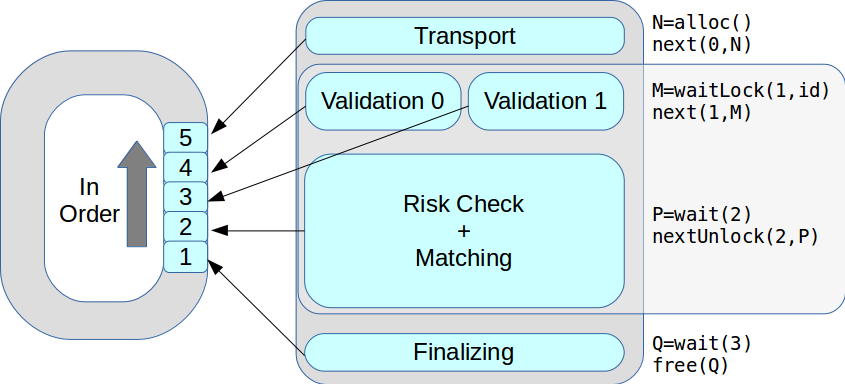
Sekarang pada satu tahap mungkin ada beberapa utas eksekusi. Semua transaksi diproses secara bergiliran, sesuai urutan yang diterima. Akibatnya, kinerja puncak meningkat dari 18 ribu menjadi 50 ribu transaksi per detik.
Sistem Manajemen Risiko Pertukaran
Tidak ada batasan untuk kesempurnaan, dan segera kami mulai memodernisasi lagi: sebagai bagian dari ASTS +, kami mulai mentransfer sistem manajemen risiko dan operasi penyelesaian ke dalam komponen otonom. Kami mengembangkan arsitektur modern yang fleksibel dan model risiko hierarkis baru, mencoba sedapat mungkin untuk menggunakan kelas
fixed_point alih-alih
double .
Tetapi segera muncul masalah: bagaimana cara menyinkronkan semua logika bisnis yang telah bekerja selama bertahun-tahun dan mentransfernya ke sistem baru? Akibatnya, versi pertama dari prototipe sistem baru harus ditinggalkan. Versi kedua, yang saat ini bekerja di produksi, didasarkan pada kode yang sama yang berfungsi baik di bagian perdagangan maupun di bagian risiko. Selama pengembangan, hal yang paling sulit adalah membuat git menggabungkan antara kedua versi. Rekan kami Evgeny Mazurenok melakukan operasi ini setiap minggu dan memaki untuk waktu yang sangat lama setiap kali.
Ketika memilih sistem baru, kami segera harus menyelesaikan masalah interaksi. Ketika memilih bus data, itu perlu untuk memastikan jitter stabil dan penundaan minimal. Untuk ini, jaringan InfiniBand RDMA paling cocok: waktu pemrosesan rata-rata adalah 4 kali lebih sedikit dari pada jaringan 10G Ethernet. Tetapi perbedaan sebenarnya ada di persentil - 99 dan 99,9.
Tentu saja, InfiniBand memiliki kesulitannya sendiri. Pertama, API lain adalah ibverb, bukan soket. Kedua, hampir tidak ada solusi perpesanan sumber terbuka yang tersedia secara luas. Kami mencoba membuat prototipe kami, tetapi ternyata sangat sulit, jadi kami memilih solusi komersial - Perpesanan Latensi Rendah (sebelumnya IBM MQ LLM).
Kemudian timbul masalah pemisahan yang benar dari sistem risiko. Jika Anda hanya mengambil Mesin Risiko dan tidak membuat simpul perantara, maka transaksi dari dua sumber dapat digabungkan.
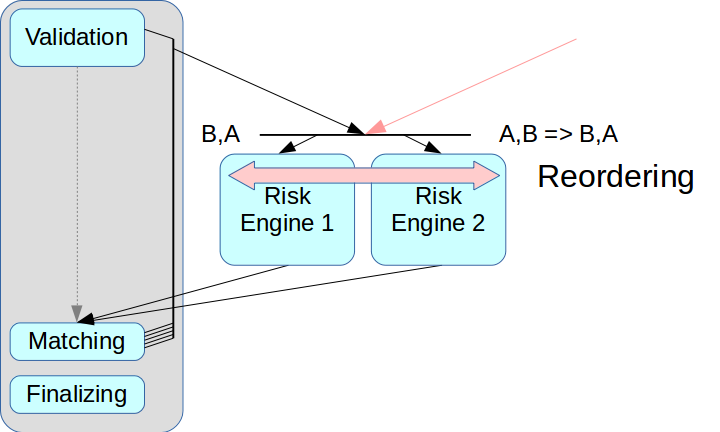
Solusi Ultra Low Latency disebut memiliki mode penataan ulang: transaksi dari dua sumber dapat diatur dalam urutan yang benar setelah diterima, ini diwujudkan dengan menggunakan saluran terpisah untuk bertukar informasi tentang urutan. Tetapi kami belum menerapkan mode ini: ini mempersulit seluruh proses, dan dalam beberapa solusi tidak didukung sama sekali. Selain itu, setiap transaksi harus diberi cap waktu yang sesuai, dan dalam skema kami mekanisme ini sangat sulit untuk diterapkan dengan benar. Oleh karena itu, kami menggunakan skema klasik dengan broker pesan, yaitu, dengan operator yang mendistribusikan pesan antara Risk Engine.
Masalah kedua terkait dengan akses klien: jika ada beberapa Gateways Risiko, klien harus terhubung ke masing-masing, dan untuk ini Anda harus membuat perubahan ke lapisan klien. Kami ingin keluar dari ini pada tahap ini, jadi dalam skema Risk Gateway saat ini mereka memproses seluruh aliran data. Ini sangat membatasi throughput maksimum, tetapi sangat menyederhanakan integrasi sistem.
Duplikasi
Sistem kami seharusnya tidak memiliki satu titik kegagalan, yaitu, semua komponen harus digandakan, termasuk pialang pesan. Kami memecahkan masalah ini menggunakan sistem CLLM: ini berisi gugus RCMS di mana dua dispatcher dapat bekerja dalam mode master-slave, dan ketika satu gagal, sistem otomatis beralih ke yang lain.
Bekerja dengan pusat data cadangan
InfiniBand dioptimalkan untuk berfungsi sebagai jaringan lokal, yaitu, untuk menghubungkan peralatan rack-mount, dan tidak ada cara untuk meletakkan jaringan InfiniBand antara dua pusat data yang didistribusikan secara geografis. Oleh karena itu, kami menerapkan penghubung / pengirim yang terhubung ke penyimpanan pesan melalui jaringan Ethernet biasa dan menyampaikan semua transaksi ke jaringan IB kedua. Saat Anda membutuhkan migrasi dari pusat data, kami dapat memilih pusat data mana yang akan bekerja sekarang.
Ringkasan
Semua hal di atas tidak dilakukan sekaligus, butuh beberapa iterasi pengembangan arsitektur baru. Kami membuat prototipe dalam sebulan, tetapi butuh lebih dari dua tahun untuk menyelesaikan kondisi kerja. Kami mencoba untuk mencapai kompromi terbaik antara meningkatkan durasi pemrosesan transaksi dan meningkatkan keandalan sistem.
Karena sistem ini sangat diperbarui, kami menerapkan pemulihan data dari dua sumber independen. Jika karena alasan tertentu penyimpanan pesan tidak berfungsi dengan benar, Anda dapat mengambil log transaksi dari sumber kedua - dari Risk Engine. Prinsip ini dihormati di seluruh sistem.
Di antara hal-hal lain, kami berhasil mempertahankan API klien sehingga broker maupun orang lain tidak memerlukan perubahan signifikan untuk arsitektur baru. Saya harus mengubah beberapa antarmuka, tetapi saya tidak perlu melakukan perubahan signifikan pada model pekerjaan.
Kami menyebut versi terbaru dari platform kami, Rebus - sebagai singkatan dari dua inovasi paling terkenal dalam arsitektur, Risk Engine, dan BUS.
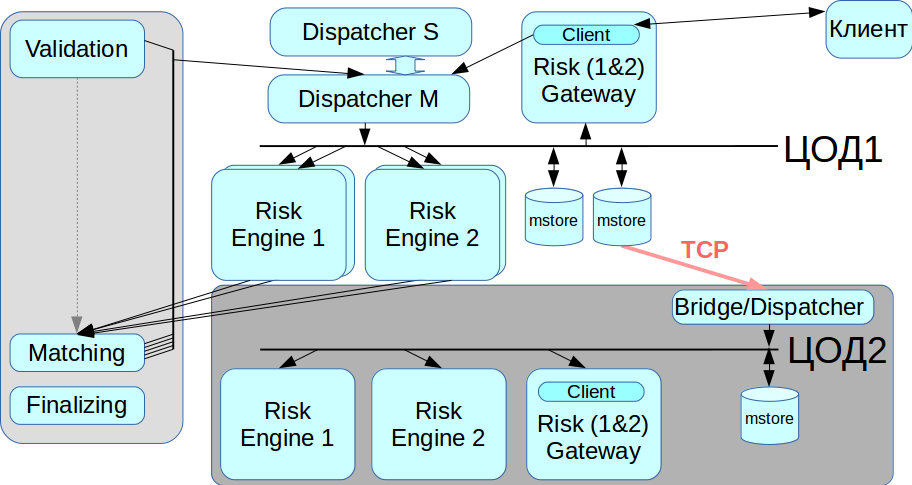
Awalnya, kami hanya ingin menyoroti bagian kliring, tetapi hasilnya adalah sistem terdistribusi besar. Sekarang pelanggan dapat berinteraksi dengan Trading Gateway, atau dengan kliring, atau keduanya sekaligus.
Apa yang akhirnya kami capai:

Mengurangi tingkat keterlambatan. Dengan volume transaksi yang kecil, sistem bekerja sama dengan versi sebelumnya, tetapi pada saat yang sama dapat menahan beban yang jauh lebih tinggi.
Produktivitas puncak meningkat dari 50 ribu menjadi 180 ribu transaksi per detik. Aliran informasi lebih lanjut menghambat pertumbuhan lebih lanjut.
: matching Gateway. Gateway , .
, -: