Di Amerika Serikat saja, ada 3 juta orang cacat yang tidak bisa meninggalkan rumah mereka. Robot penolong yang dapat menavigasi jarak jauh secara otomatis dapat membuat orang-orang ini lebih mandiri dengan membawa makanan, obat-obatan, dan paket. Studi menunjukkan bahwa pembelajaran mendalam dengan penguatan (OP) sangat cocok untuk membandingkan input data mentah dan tindakan, misalnya, untuk belajar
menangkap objek atau
memindahkan robot , tetapi biasanya
agen OP kurang memahami ruang fisik besar yang diperlukan untuk orientasi yang aman ke jarak jauh jarak tanpa bantuan manusia dan adaptasi ke lingkungan baru.
Dalam tiga karya terbaru, “
Pelatihan Orienteering dari awal dengan AOP ,” “
PRM-RL: Menerapkan orientasi robot dari jarak jauh menggunakan kombinasi pembelajaran penguatan dan perencanaan berbasis pola ” dan “
Orientasi jarak jauh dengan PRM-RL, ” kami Kami mempelajari robot otonom yang mudah beradaptasi dengan lingkungan baru, menggabungkan OP dalam dengan perencanaan jangka panjang. Kami mengajarkan agen perencana lokal bagaimana melakukan tindakan dasar yang diperlukan untuk orientasi dan cara bergerak jarak pendek tanpa tabrakan dengan benda bergerak. Perencana lokal melakukan pengamatan lingkungan yang bising menggunakan sensor seperti lidar satu dimensi yang menyediakan jarak ke hambatan dan memberikan kecepatan linier dan sudut untuk mengendalikan robot. Kami melatih perencana lokal dalam simulasi menggunakan pembelajaran penguatan otomatis (AOP), sebuah metode yang mengotomatiskan pencarian hadiah untuk OP dan arsitektur jaringan saraf. Meskipun jangkauan terbatas antara 10-15 m, perencana lokal beradaptasi dengan baik untuk digunakan pada robot asli dan untuk lingkungan baru yang sebelumnya tidak dikenal. Ini memungkinkan Anda untuk menggunakannya sebagai blok bangunan untuk orientasi pada ruang besar. Kemudian kita membangun peta jalan, grafik di mana simpul-simpul itu merupakan bagian yang terpisah, dan ujung-ujungnya menghubungkan simpul hanya jika perencana lokal, yang dengan baik meniru robot asli menggunakan sensor dan kontrol yang bising, dapat bergerak di antara mereka.
Pembelajaran penguatan otomatis (AOP)
Dalam
pekerjaan pertama kami, kami melatih perencana lokal di lingkungan statis kecil. Namun, ketika belajar dengan algoritma OP dalam standar, misalnya, gradien deterministik mendalam (
DDPG ), ada beberapa kendala. Sebagai contoh, tujuan nyata perencana lokal adalah untuk mencapai tujuan yang diberikan, sebagai akibatnya mereka menerima hadiah langka. Dalam praktiknya, ini menuntut para peneliti untuk menghabiskan banyak waktu pada implementasi algoritma dan penyesuaian penghargaan secara bertahap. Para peneliti juga harus membuat keputusan tentang arsitektur jaringan saraf tanpa memiliki resep yang jelas dan sukses. Akhirnya, algoritma seperti DDPG belajar dengan tidak stabil dan sering menunjukkan
pelupa bencana .
Untuk mengatasi kendala ini, kami mengotomatisasi pembelajaran mendalam dengan penguatan. AOP adalah pembungkus otomatis evolusioner di sekitar OP yang dalam, mencari imbalan dan arsitektur jaringan saraf melalui
optimisasi hyperparameter skala besar . Ia bekerja dalam dua tahap, pencarian penghargaan dan pencarian arsitektur. Selama pencarian hadiah, AOP telah secara bersamaan melatih populasi agen DDPG selama beberapa generasi, masing-masing memiliki fungsi hadiah yang sedikit berubah, dioptimalkan untuk tugas sebenarnya dari perencana lokal: mencapai titik akhir jalan. Di akhir fase pencarian hadiah, kami memilih satu yang paling sering mengarahkan agen ke tujuan. Dalam fase pencarian arsitektur jaringan saraf, kami mengulangi proses ini, untuk balapan ini menggunakan penghargaan yang dipilih dan menyesuaikan lapisan jaringan, mengoptimalkan penghargaan kumulatif.
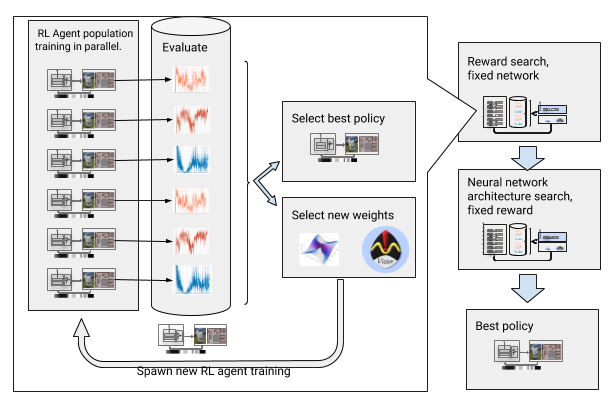 AOP dengan pencarian penghargaan dan arsitektur jaringan saraf
AOP dengan pencarian penghargaan dan arsitektur jaringan sarafNamun, proses ini selangkah demi selangkah membuat AOP tidak efektif dalam hal jumlah sampel. Pelatihan AOP dengan 10 generasi 100 agen membutuhkan 5 miliar sampel, setara dengan 32 tahun studi! Keuntungannya adalah bahwa setelah AOP, proses pembelajaran manual terotomatisasi, dan DDPG tidak memiliki bencana lupa. Yang paling penting, kualitas kebijakan akhir lebih tinggi - mereka tahan terhadap kebisingan dari sensor, drive, dan pelokalan, dan digeneralisasikan dengan baik ke lingkungan baru. Kebijakan terbaik kami adalah 26% lebih berhasil daripada metode orientasi lainnya di lokasi pengujian kami.
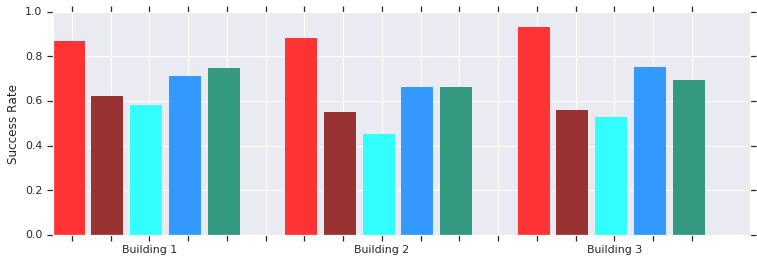 Merah - AOP berhasil pada jarak pendek (hingga 10 m) di beberapa bangunan yang sebelumnya tidak dikenal. Perbandingan dengan DDPG yang dilatih secara manual (merah tua), bidang potensial buatan (biru), jendela dinamis (biru) dan kloning perilaku (hijau).Kebijakan penjadwal AOP lokal berfungsi baik dengan robot di lingkungan nyata yang tidak terstruktur
Merah - AOP berhasil pada jarak pendek (hingga 10 m) di beberapa bangunan yang sebelumnya tidak dikenal. Perbandingan dengan DDPG yang dilatih secara manual (merah tua), bidang potensial buatan (biru), jendela dinamis (biru) dan kloning perilaku (hijau).Kebijakan penjadwal AOP lokal berfungsi baik dengan robot di lingkungan nyata yang tidak terstrukturDan meskipun politisi ini hanya mampu orientasi lokal, mereka tahan terhadap rintangan yang bergerak dan ditoleransi dengan baik oleh robot nyata di lingkungan yang tidak terstruktur. Dan meskipun mereka dilatih dalam simulasi dengan objek statis, mereka secara efektif mengatasi yang bergerak. Langkah selanjutnya adalah menggabungkan kebijakan AOP dengan perencanaan berbasis sampel untuk memperluas area kerja mereka dan mengajari mereka cara menavigasi jarak jauh.
Orientasi jarak jauh dengan PRM-RL
Perencana berbasis pola bekerja dengan orientasi jarak jauh, mendekati gerakan robot. Sebagai contoh, robot membangun
roadmap probabilistic (PRMs) dengan menggambar jalur transisi antar bagian. Dalam
karya kedua kami, yang memenangkan penghargaan pada konferensi
ICRA 2018 , kami menggabungkan PRM dengan penjadwal OP lokal yang disetel secara manual (tanpa AOP) untuk melatih robot secara lokal dan kemudian menyesuaikannya dengan lingkungan lain.
Pertama, untuk setiap robot, kami melatih kebijakan penjadwal lokal dalam simulasi umum. Kemudian kami membuat PRM dengan mempertimbangkan kebijakan ini, yang disebut PRM-RL, berdasarkan peta lingkungan di mana ia akan digunakan. Kartu yang sama dapat digunakan untuk robot apa pun yang ingin kita gunakan di gedung.
Untuk membuat PRM-RL, kami menggabungkan node dari sampel hanya jika OP-scheduler lokal dapat dipercaya dan berulang kali berpindah di antara mereka. Ini dilakukan dalam simulasi Monte Carlo. Peta yang dihasilkan menyesuaikan dengan kemampuan dan geometri robot tertentu. Kartu untuk robot dengan geometri yang sama, tetapi dengan sensor dan drive yang berbeda, akan memiliki konektivitas yang berbeda. Karena agen dapat berputar di sudut, node yang tidak berhadapan langsung juga dapat dihidupkan. Namun, simpul-simpul yang berdekatan dengan dinding dan rintangan akan lebih kecil kemungkinannya untuk dimasukkan dalam peta karena kebisingan sensor. Pada waktu berjalan, agen OP bergerak melintasi peta dari satu bagian ke bagian lain.
 Peta dibuat dengan tiga simulasi Monte Carlo untuk setiap pasangan node yang dipilih secara acak
Peta dibuat dengan tiga simulasi Monte Carlo untuk setiap pasangan node yang dipilih secara acak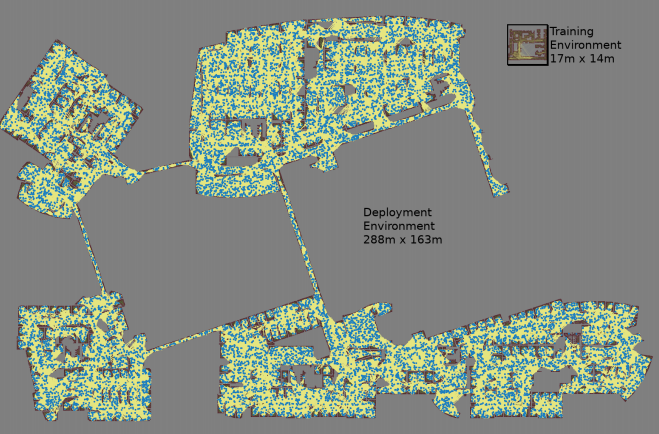 Peta terbesar berukuran 288x163 m dan berisi hampir 700.000 tepi. 300 pekerja mengumpulkannya selama 4 hari, setelah melakukan 1,1 miliar cek tabrakan.Karya ketiga
Peta terbesar berukuran 288x163 m dan berisi hampir 700.000 tepi. 300 pekerja mengumpulkannya selama 4 hari, setelah melakukan 1,1 miliar cek tabrakan.Karya ketiga menyediakan beberapa perbaikan pada PRM-RL asli. Pertama, kami mengganti DDPG yang disetel secara manual dengan penjadwal AOP lokal, yang memberikan peningkatan orientasi jarak jauh. Kedua,
peta lokalisasi dan penandaan simultan (
SLAM ) ditambahkan, yang digunakan robot saat runtime sebagai sumber untuk membangun peta jalan. Kartu SLAM tunduk pada kebisingan, dan ini menutup "celah antara simulator dan kenyataan", masalah yang terkenal dalam robotika, karena agen yang dilatih dalam simulasi berperilaku jauh lebih buruk di dunia nyata. Tingkat kesuksesan kami dalam simulasi bertepatan dengan tingkat keberhasilan robot nyata. Dan akhirnya, kami menambahkan peta bangunan terdistribusi, sehingga kami dapat membuat peta sangat besar yang berisi hingga 700.000 node.
Kami mengevaluasi metode ini dengan bantuan agen AOP kami, yang membuat peta berdasarkan gambar bangunan yang melebihi lingkungan pelatihan sebanyak 200 kali di daerah tersebut, termasuk hanya tulang rusuk, yang berhasil diselesaikan dalam 90% kasus dalam 20 upaya. Kami membandingkan PRM-RL dengan berbagai metode pada jarak hingga 100 m, yang secara signifikan melebihi kisaran perencana lokal. PRM-RL mencapai keberhasilan 2-3 kali lebih sering daripada metode konvensional karena koneksi node yang benar, cocok untuk kemampuan robot.
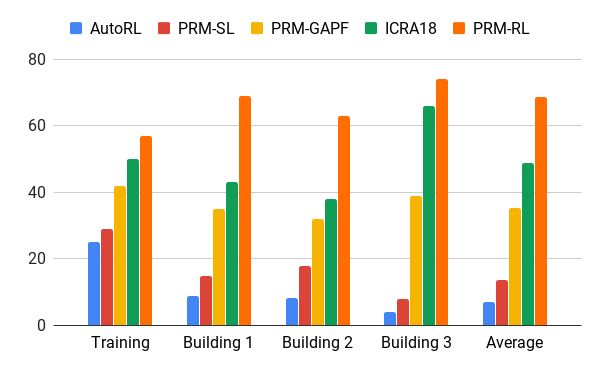 Tingkat keberhasilan dalam memindahkan 100 m di berbagai bangunan. Biru - penjadwal AOP lokal, pekerjaan pertama; PRM merah asli; kuning - bidang potensial buatan; hijau adalah pekerjaan kedua; merah - pekerjaan ketiga, PRM dengan AOP.
Tingkat keberhasilan dalam memindahkan 100 m di berbagai bangunan. Biru - penjadwal AOP lokal, pekerjaan pertama; PRM merah asli; kuning - bidang potensial buatan; hijau adalah pekerjaan kedua; merah - pekerjaan ketiga, PRM dengan AOP.Kami menguji PRM-RL pada banyak robot nyata di banyak bangunan. Di bawah ini adalah salah satu suite tes; robot andal bergerak hampir ke mana-mana, kecuali untuk tempat dan area paling berantakan yang melampaui kartu SLAM.

Kesimpulan
Orientasi alat berat dapat secara serius meningkatkan kemandirian orang dengan gangguan mobilitas. Ini dapat dicapai dengan mengembangkan robot otonom yang dapat dengan mudah beradaptasi dengan lingkungan, dan metode yang tersedia untuk implementasi di lingkungan baru berdasarkan informasi yang ada. Ini dapat dilakukan dengan mengotomatisasi pelatihan orientasi dasar untuk jarak pendek dengan AOP, dan kemudian menggunakan keterampilan yang diperoleh bersama dengan kartu SLAM untuk membuat peta jalan. Peta jalan terdiri dari simpul-simpul yang dihubungkan oleh tulang rusuk, tempat robot dapat bergerak dengan andal. Akibatnya, kebijakan perilaku robot dikembangkan yang, setelah satu pelatihan, dapat digunakan di lingkungan yang berbeda dan mengeluarkan peta jalan yang secara khusus disesuaikan untuk robot tertentu.