Terakhir kali kami berbicara tentang konsistensi data, melihat perbedaan antara tingkat isolasi transaksi yang berbeda melalui mata pengguna, dan mencari tahu mengapa itu penting untuk diketahui. Sekarang kita mulai belajar bagaimana PostgreSQL mengimplementasikan isolasi berbasis gambar dan mekanisme multi-versi.
Pada artikel ini, kita akan melihat bagaimana data secara fisik terletak di file dan halaman. Ini menjauhkan kita dari topik isolasi, tetapi penyimpangan semacam itu diperlukan untuk memahami materi lebih lanjut. Kita perlu memahami cara kerja penyimpanan data tingkat rendah.
Hubungan
Jika Anda melihat di dalam tabel dan indeks, ternyata mereka disusun dengan cara yang sama. Baik itu, dan lain - objek dasar yang berisi beberapa data yang terdiri dari garis.
Fakta bahwa tabel terdiri dari baris tidak diragukan; untuk indeks, ini kurang jelas. Namun, bayangkan B-tree: terdiri dari node yang berisi nilai yang diindeks dan tautan ke node lain atau ke baris tabel. Node-node ini dapat dianggap sebagai garis indeks - pada kenyataannya, sebagaimana adanya.
Bahkan, masih ada sejumlah objek yang disusun dengan cara yang serupa: urutan (pada dasarnya tabel baris tunggal), tampilan terwujud (pada dasarnya tabel yang mengingat kueri). Dan kemudian ada pandangan biasa, yang dengan sendirinya tidak menyimpan data, tetapi dalam semua hal lain mirip dengan tabel.
Semua objek ini di PostgreSQL disebut
hubungan kata umum. Kata ini sangat disayangkan karena merupakan istilah dari teori relasional. Anda bisa menggambar paralel antara relasi dan tabel (tampilan), tetapi tentu saja tidak antara relasi dan indeks. Tetapi itu terjadi: akar akademik PostgreSQL membuat mereka merasa. Saya pikir pada awalnya disebut tabel dan pandangan, dan sisanya tumbuh seiring waktu.
Lebih lanjut, untuk kesederhanaan, kita hanya akan berbicara tentang tabel dan indeks, tetapi
hubungan lainnya terstruktur persis sama.
Layers (fork) dan file
Biasanya, setiap relasi memiliki beberapa
lapisan (garpu). Lapisan terdiri dari beberapa jenis dan masing-masingnya berisi jenis data tertentu.
Jika ada layer, maka pada awalnya itu diwakili oleh satu
file . Nama file terdiri dari pengidentifikasi numerik dimana akhir yang sesuai dengan nama layer dapat ditambahkan.
File secara bertahap tumbuh dan ketika ukurannya mencapai 1 GB, file berikutnya dari lapisan yang sama dibuat (file tersebut kadang-kadang disebut
segmen ). Nomor segmen ditambahkan ke akhir nama file.
Batasan ukuran file 1 GB telah muncul secara historis untuk mendukung berbagai sistem file, beberapa di antaranya tidak dapat bekerja dengan file besar. Pembatasan dapat diubah ketika membangun PostgreSQL (
./configure --with-segsize ).
Dengan demikian, beberapa file dapat berhubungan dengan satu relasi pada disk. Misalnya, untuk meja kecil akan ada 3 dari mereka.
Semua file objek milik satu ruang tabel dan satu basis data akan ditempatkan dalam satu direktori. Ini harus diperhitungkan karena sistem file biasanya tidak berfungsi dengan baik dengan sejumlah besar file dalam direktori.
Perhatikan saja bahwa file-file tersebut, pada gilirannya, dibagi menjadi beberapa
halaman (atau
blok ), biasanya 8 KB. Kami akan berbicara tentang struktur internal laman di bawah.
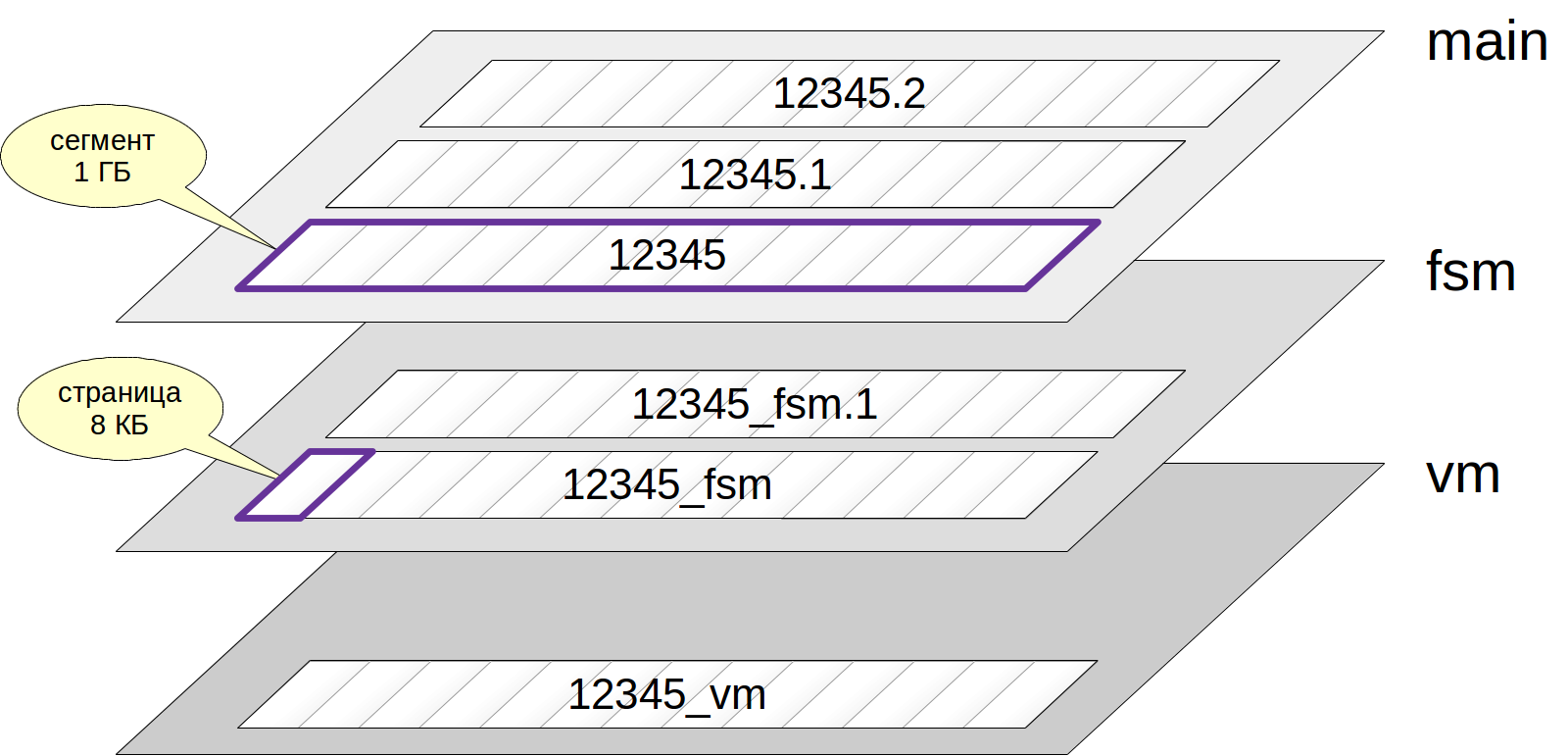
Sekarang mari kita lihat jenis-jenis lapisan.
Lapisan utama adalah data itu sendiri: tabel atau baris indeks yang sama. Lapisan utama ada untuk setiap hubungan (kecuali untuk representasi yang tidak mengandung data).
Nama-nama file di lapisan utama hanya terdiri dari pengidentifikasi numerik. Berikut ini contoh jalur ke file tabel yang kami buat terakhir kali:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
Dari mana pengidentifikasi ini berasal? Direktori dasar sesuai dengan tablespace pg_default, subdirektori berikutnya sesuai dengan database, dan file yang kami minati sudah ada di dalamnya:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
Path relatif, dihitung dari direktori data (PGDATA). Selain itu, hampir semua jalur di PostgreSQL dihitung dari PGDATA. Berkat ini, Anda dapat dengan aman mentransfer PGDATA ke tempat lain - itu tidak menampung apa pun (kecuali Anda mungkin perlu mengkonfigurasi jalur ke perpustakaan di LD_LIBRARY_PATH).
Kami melihat lebih jauh dalam sistem file:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Lapisan inisialisasi hanya ada untuk tabel non-jurnal (dibuat dengan UNLOGGED) dan indeksnya. Objek seperti itu tidak berbeda dari yang biasa, kecuali bahwa tindakan dengan mereka tidak direkam dalam log prarekam. Karena ini, bekerja dengan mereka lebih cepat, tetapi jika terjadi kegagalan, tidak mungkin untuk mengembalikan data dalam keadaan konsisten. Oleh karena itu, ketika memulihkan, PostgreSQL hanya menghapus semua lapisan objek tersebut dan menulis lapisan inisialisasi ke tempat lapisan utama. Hasilnya adalah "boneka". Kita akan berbicara tentang penjurnalan secara terperinci, tetapi dalam siklus yang berbeda.
Tabel akun dijurnal, sehingga tidak ada lapisan inisialisasi untuknya. Tetapi untuk percobaan, Anda dapat menonaktifkan pencatatan:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
Kemampuan untuk mengaktifkan dan menonaktifkan journaling on the fly, seperti dapat dilihat dari contoh, melibatkan menimpa data ke file dengan nama yang berbeda.
Lapisan inisialisasi memiliki nama yang sama dengan lapisan utama, tetapi dengan akhiran "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Peta ruang bebas (peta ruang bebas) - lapisan di mana ada ruang kosong di dalam halaman. Tempat ini terus berubah: ketika versi baru dari string ditambahkan, ia berkurang, sementara pembersihan - itu meningkat. Peta ruang bebas digunakan ketika memasukkan versi baris baru untuk dengan cepat menemukan halaman yang cocok di mana data yang akan ditambahkan akan cocok.
Peta ruang bebas memiliki akhiran "_fsm". Tetapi file tidak segera muncul, tetapi hanya jika perlu. Cara termudah untuk mencapai ini adalah dengan membersihkan meja (mengapa - mari kita bicara tepat waktu):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Peta visibilitas adalah lapisan di mana halaman yang hanya berisi versi string saat ini ditandai dengan satu bit. Secara kasar, ini berarti bahwa ketika suatu transaksi mencoba membaca suatu baris dari halaman seperti itu, garis tersebut dapat ditampilkan tanpa memeriksa visibilitasnya. Kami akan memeriksa secara rinci bagaimana ini terjadi dalam artikel berikut.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Halaman
Seperti yang telah kami katakan, file secara logis dibagi menjadi beberapa halaman.
Biasanya, sebuah halaman berukuran 8 KB. Anda dapat mengubah ukuran dalam batas-batas tertentu (16 KB atau 32 KB), tetapi hanya selama perakitan (
./configure --with-blocksize ). Contoh assembled and running dapat bekerja dengan halaman hanya satu ukuran.
Terlepas dari lapisan mana file milik, mereka digunakan oleh server dengan cara yang kira-kira sama. Halaman pertama kali dibaca ke dalam cache buffer, tempat proses dapat membaca dan memodifikasinya; kemudian, jika perlu, halaman didorong kembali ke disk.
Setiap halaman memiliki markup internal dan umumnya berisi bagian-bagian berikut:
0 + ----------------------------------- +
| menuju |
24 + ----------------------------------- +
| array pointer ke string versi |
lebih rendah + ----------------------------------- +
| ruang kosong |
atas + ----------------------------------- +
| versi baris |
spesial + ----------------------------------- +
| area khusus |
pagesize + ----------------------------------- +
Ukuran bagian-bagian ini mudah diketahui dengan ekstensi halaman "penelitian":
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Di sini kita melihat
judul halaman pertama (nol) dari tabel. Selain ukuran area yang tersisa, tajuk berisi informasi lain tentang halaman, tetapi belum menarik bagi kami.
Di bagian bawah halaman adalah
area khusus , dalam kasus kami, kosong. Ini digunakan hanya untuk indeks, dan kemudian tidak untuk semua orang. "Bawah" di sini sesuai dengan gambar; mungkin akan lebih tepat untuk mengatakan "di alamat tinggi".
Mengikuti area khusus adalah
versi baris - data yang kami simpan di tabel, ditambah beberapa informasi overhead.
Di bagian atas halaman, segera setelah tajuk, adalah daftar isi:
array pointer ke versi garis yang tersedia di halaman.
Antara versi garis dan pointer mungkin ada
ruang kosong (yang ditandai di peta ruang kosong). Perhatikan bahwa tidak ada fragmentasi di dalam halaman, semua ruang kosong selalu diwakili oleh satu fragmen.
Pointer
Mengapa pointer ke versi string diperlukan? Faktanya adalah bahwa baris indeks entah bagaimana harus merujuk ke versi baris dalam tabel. Jelas bahwa tautan tersebut harus berisi nomor file, nomor halaman dalam file dan beberapa indikasi versi baris. Offset dari awal halaman dapat digunakan sebagai indikasi seperti itu, tetapi ini tidak nyaman. Kami tidak akan dapat memindahkan versi baris di dalam halaman karena akan merusak tautan yang ada. Dan ini akan menyebabkan fragmentasi ruang di dalam halaman dan konsekuensi tidak menyenangkan lainnya. Oleh karena itu, indeks mengacu pada nomor indeks, dan penunjuk mengacu pada posisi saat ini dari versi baris di halaman. Ternyata pengalamatan tidak langsung.
Setiap pointer menempati tepat 4 byte dan berisi:
- tautan ke versi string;
- panjang versi string ini;
- beberapa bit yang menentukan status versi string.
Format data
Format data pada disk sepenuhnya bertepatan dengan representasi data dalam RAM. Halaman dibaca ke dalam cache buffer "apa adanya", tanpa transformasi apa pun. Oleh karena itu, file data dari satu platform tidak kompatibel dengan platform lain.
Misalnya, dalam arsitektur x86, urutan byte diadopsi dari yang paling signifikan ke yang tertinggi (little-endian), z / Arsitektur menggunakan urutan terbalik (big-endian), dan dalam ARM urutan sakelar.
Banyak arsitektur menyediakan penyelarasan data melintasi batas-batas kata mesin. Misalnya, pada sistem 32-bit x86, bilangan bulat (tipe bilangan bulat, menempati 4 byte) akan disejajarkan di perbatasan kata 4-byte, serta angka floating-point presisi ganda (tipe presisi ganda, 8 byte). Dan pada sistem 64-bit, nilai ganda akan disejajarkan di perbatasan kata 8-byte. Ini adalah alasan lain ketidakcocokan.
Karena perataan, ukuran baris tabel tergantung pada urutan bidang. Biasanya efek ini tidak terlalu terlihat, tetapi dalam beberapa kasus dapat menyebabkan peningkatan ukuran yang signifikan. Misalnya, jika Anda menempatkan char (1) dan bidang integer bercampur, 3 byte biasanya akan terbuang di antara mereka. Anda dapat melihat lebih banyak tentang ini di presentasi Nikolai Shaplov "
What's Inside It ".
Versi String dan TOAST
Tentang bagaimana versi string disusun dari dalam, kami akan berbicara secara rinci lain kali. Sejauh ini, satu-satunya hal penting bagi kami adalah bahwa setiap versi harus sesuai sepenuhnya pada satu halaman: PostgreSQL tidak menyediakan cara untuk "melanjutkan" baris pada halaman berikutnya. Alih-alih, sebuah teknologi yang disebut TOAST (Teknik Penyimpanan Atribut Besar) digunakan. Nama itu sendiri menunjukkan bahwa tali dapat dipotong menjadi roti panggang.
Serius berbicara, TOAST melibatkan beberapa strategi. Nilai atribut "Panjang" dapat dikirim ke tabel layanan terpisah, yang sebelumnya dipotong kecil-kecil. Pilihan lain adalah untuk mengompres nilai sehingga versi baris masih cocok di halaman tabel reguler. Dan mungkin baik itu, dan yang lain: pada awalnya untuk kompres, dan hanya kemudian memotong dan mengirim.
Untuk setiap tabel utama, jika perlu, yang terpisah, tetapi satu untuk semua atribut, tabel TOAST (dan indeks khusus untuk itu) dibuat. Kebutuhan ditentukan oleh keberadaan atribut yang berpotensi panjang dalam tabel. Misalnya, jika tabel memiliki kolom tipe numerik atau teks, tabel TOAST akan segera dibuat, bahkan jika nilai yang panjang tidak digunakan.
Karena tabel TOAST pada dasarnya adalah tabel biasa, ia masih memiliki seperangkat lapisan yang sama. Dan ini menggandakan jumlah file yang "melayani" tabel.
Awalnya, strategi ditentukan oleh tipe data kolom. Anda dapat melihatnya dengan perintah
\d+ dalam psql, tetapi karena ia juga menampilkan banyak informasi lain, kami akan menggunakan permintaan ke direktori sistem:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Nama-nama strategi memiliki arti sebagai berikut:
- plain - TOAST tidak digunakan (digunakan untuk tipe data yang jelas "pendek", seperti integer);
- extended - baik kompresi dan penyimpanan dalam tabel TOAST terpisah diizinkan;
- nilai eksternal - panjang disimpan dalam tabel TOAST tanpa kompresi;
- nilai utama - panjang dikompresi terlebih dahulu dan hanya di tabel TOAST jika kompresi tidak membantu.
Secara umum, algoritma adalah sebagai berikut. PostgreSQL ingin setidaknya 4 baris agar sesuai pada satu halaman. Oleh karena itu, jika ukuran garis melebihi bagian keempat halaman, dengan mempertimbangkan tajuk (dengan halaman 8K normal, ini adalah 2040 byte), TOAST harus diterapkan ke bagian nilai. Kami bertindak sesuai urutan yang dijelaskan di bawah ini dan berhenti segera setelah garis berhenti melebihi ambang batas:
- Pertama, kami memilah-milah atribut dengan strategi eksternal dan diperpanjang, bergerak dari yang terpanjang ke yang lebih pendek. Atribut yang diperluas dikompresi (jika ini memiliki efek) dan, jika nilainya sendiri melebihi seperempat halaman, ia segera dikirim ke tabel TOAST. Atribut eksternal ditangani dengan cara yang sama, tetapi tidak dikompresi.
- Jika setelah lulus pertama versi baris masih tidak cocok, kami mengirim atribut yang tersisa dengan strategi eksternal dan diperluas ke tabel TOAST.
- Jika ini juga tidak membantu, coba kompres atribut dengan strategi utama, sambil meninggalkannya di halaman tabel.
- Dan hanya jika setelah itu barisnya masih belum cukup pendek, atribut utama dikirim ke tabel TOAST.
Terkadang mungkin berguna untuk mengubah strategi untuk beberapa kolom. Misalnya, jika diketahui sebelumnya bahwa data dalam kolom tidak dikompresi, Anda dapat mengatur strategi eksternal untuk itu - ini akan menghemat upaya kompresi yang tidak berguna. Ini dilakukan sebagai berikut:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Mengulangi permintaan, kami mendapatkan:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
Tabel dan indeks TOAST terletak di skema pg_toast terpisah dan karenanya biasanya tidak terlihat. Untuk tabel sementara, skema pg_toast_temp_
N digunakan, mirip dengan pg_temp_
N. biasa
Tentu saja, jika diinginkan, tidak ada yang mau mengintip mekanisme internal proses. Katakanlah ada tiga atribut yang berpotensi panjang di tabel akun, jadi tabel TOAST harus. Ini dia:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
Adalah logis bahwa untuk "bersulang" ke mana garis diiris, strategi polos diterapkan: TOAST tingkat kedua tidak ada.
Indeks PostgreSQL bersembunyi lebih hati-hati, tetapi juga mudah ditemukan:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
Kolom klien menggunakan strategi yang diperluas: nilai-nilai di dalamnya akan dikompresi. Periksa:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
Tidak ada dalam tabel TOAST: karakter berulang dikompresi dengan sempurna dan setelah itu nilainya cocok dengan halaman tabel biasa.
Sekarang biarkan nama klien terdiri dari karakter acak:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Urutan ini tidak dapat dikompresi, dan jatuh ke dalam tabel TOAST:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Seperti yang Anda lihat, data dipotong menjadi fragmen 2000 byte.
Ketika mengakses nilai "panjang", PostgreSQL secara otomatis, transparan ke aplikasi, mengembalikan nilai asli dan mengembalikannya ke klien.
Tentu saja, cukup banyak sumber daya dihabiskan untuk mengiris kompresi dan pemulihan selanjutnya. Oleh karena itu, menyimpan data dalam PostgreSQL bukan ide yang baik, terutama jika itu digunakan secara aktif dan logika transaksional tidak diperlukan untuk mereka (sebagai contoh: dokumen asli yang dipindai dari dokumen akuntansi). Alternatif yang lebih menguntungkan mungkin menyimpan data tersebut pada sistem file, dan dalam DBMS, nama-nama file yang sesuai.
Tabel TOAST hanya digunakan saat mengacu pada nilai "panjang". Selain itu, tabel roti panggang memiliki versi sendiri: jika pembaruan data tidak memengaruhi nilai "panjang", versi baris baru akan merujuk ke nilai yang sama di tabel TOAST - ini menghemat ruang.
Perhatikan bahwa TOAST hanya berfungsi untuk tabel, tetapi tidak untuk indeks. Ini memberlakukan batasan pada ukuran kunci yang diindeks.
Anda dapat membaca lebih lanjut tentang organisasi data internal dalam dokumentasi .
Untuk dilanjutkan .