Paket tidyr adalah bagian dari inti dari salah satu perpustakaan paling populer dalam bahasa R - tidyverse .
Tujuan utama dari paket ini adalah untuk membawa data ke tampilan yang rapi.
Sudah ada publikasi tentang Habré yang didedikasikan untuk paket ini, tetapi sudah ada sejak tahun 2015. Dan saya ingin memberi tahu Anda tentang perubahan yang paling relevan, yang beberapa hari lalu diumumkan oleh penulisnya, Hadley Wickham.
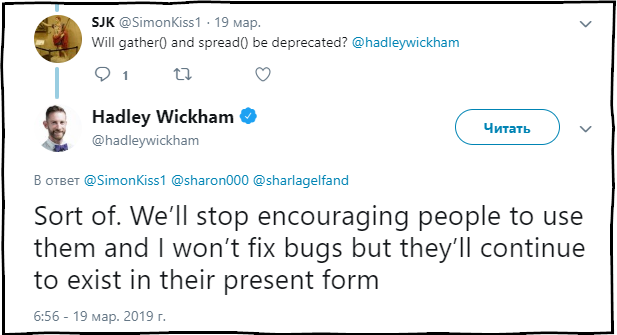
SJK : Apakah fungsi kumpulkan () dan menyebar () ditinggalkan?
Hadley Wickham : Sampai batas tertentu. Kami akan berhenti merekomendasikan penggunaan fungsi-fungsi ini dan memperbaiki kesalahan di dalamnya, tetapi mereka akan terus hadir dalam paket dalam keadaan saat ini.
Isi
Konsep TidyData
Tujuan dari Tidyr adalah untuk membantu Anda membawa data ke tampilan yang disebut rapi. Data akurat adalah data di mana:
- Setiap variabel ada di kolom.
- Setiap pengamatan adalah garis.
- Setiap nilai adalah sel.
Data yang diberikan untuk merapikan data jauh lebih sederhana dan lebih nyaman untuk digunakan selama analisis.
Fungsi utama termasuk dalam paket rapi
tidyr berisi sekumpulan fungsi untuk mengubah tabel:
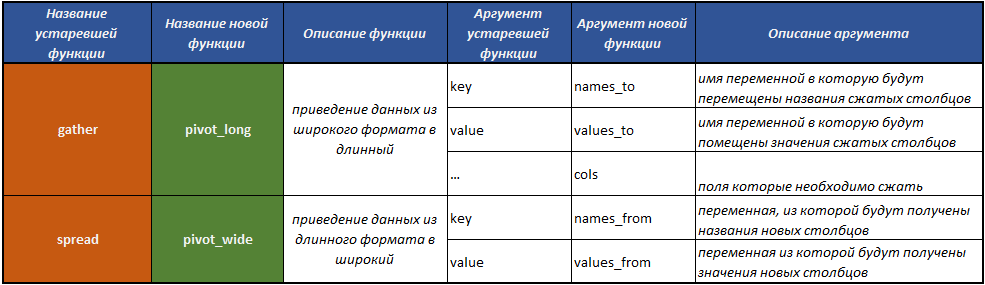
fill() - mengisi nilai yang hilang di kolom dengan nilai sebelumnya;separate() - membagi satu bidang menjadi beberapa melalui pemisah;unite() - melakukan operasi menggabungkan beberapa bidang menjadi satu, kebalikan dari fungsi separate() ;pivot_longer() - fungsi yang mengubah data dari format lebar ke format panjang;pivot_wider() - fungsi yang mengubah data dari format panjang menjadi format lebar. Operasi adalah kebalikan dari yang dilakukan oleh fungsi pivot_longer() .gather() usang - suatu fungsi yang mengubah data dari format lebar ke yang panjang;spread() usang - fungsi yang mengubah data dari format panjang ke format lebar. Operasi terbalik dari fungsi yang gather() lakukan.
Sebelumnya, fungsi gather() dan spread() digunakan untuk transformasi semacam ini. Selama bertahun-tahun keberadaan fungsi-fungsi ini, menjadi jelas bahwa bagi sebagian besar pengguna, termasuk penulis paket, nama-nama fungsi ini dan argumen mereka tidak begitu jelas, dan menyebabkan kesulitan dalam menemukan mereka dan memahami fungsi mana yang membawa kerangka tanggal dari lebar ke panjang format dan sebaliknya.
Dalam hubungan ini, dua fungsi penting baru ditambahkan ke tidyr , yang dirancang untuk mengubah kerangka tanggal.
Fungsi baru pivot_longer() dan pivot_wider() terinspirasi oleh beberapa fungsi dalam paket cdata yang dibuat oleh John Mount dan Nina Zumel.
Menginstal versi terbaru dari tidyr 0.8.3.9000
Untuk menginstal paket Tidyr 0.8.3.9000 versi terbaru dan terbaru, di mana fungsi-fungsi baru tersedia, gunakan kode berikut.
devtools::install_github("tidyverse/tidyr")
Pada saat penulisan, fungsi-fungsi ini hanya tersedia dalam versi dev dari paket di GitHub.
Beralih ke fitur baru
Sebenarnya, tidak sulit untuk mentransfer skrip lama untuk bekerja dengan fungsi-fungsi baru, untuk pemahaman yang lebih baik, saya akan mengambil contoh dari dokumentasi fungsi-fungsi lama dan menunjukkan bagaimana operasi yang sama dilakukan menggunakan fungsi pivot_*() .
Konversi lebar ke format panjang.
Kode sampel dari dokumentasi fungsi kumpulkan # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
Mengubah format panjang menjadi lebar.
Kode sampel dari dokumentasi fungsi penyebaran # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
Karena dalam contoh di atas bekerja dengan pivot_longer() dan pivot_wider() , dalam tabel sumber saham tidak ada kolom yang tercantum dalam argumen names_to dan values_to, nama mereka harus ditunjukkan dalam tanda kutip.
Tabel dengan bantuan yang paling mudah Anda pikirkan bagaimana beralih ke bekerja dengan konsep tidyr baru.
Catatan dari penulis
Semua teks di bawah ini adaptif, saya bahkan akan mengatakan terjemahan sketsa gratis dari situs resmi perpustakaan yang rapi.
pivot_longer () - membuat set data lebih lama dengan mengurangi jumlah kolom dan meningkatkan jumlah baris.

Untuk menjalankan contoh yang disajikan dalam artikel, Anda harus terlebih dahulu menghubungkan paket yang diperlukan:
library(tidyr) library(dplyr) library(readr)
Misalkan kita memiliki tabel dengan hasil survei di mana (antara lain) orang ditanya tentang agama dan pendapatan tahunan mereka:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
Tabel ini berisi data agama responden dalam baris, dan tingkat pendapatan tersebar di seluruh nama kolom. Jumlah responden dari masing-masing kategori disimpan dalam nilai-nilai sel di persimpangan tingkat agama dan pendapatan. Untuk membawa tabel ke format yang rapi dan benar, cukup gunakan pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
Argumen untuk pivot_longer()
- Argumen pertama, cols , menjelaskan kolom mana yang akan digabung. Dalam hal ini, semua kolom kecuali waktu .
- Argumen names_to memberikan nama variabel yang akan dibuat dari nama kolom yang kita gabungkan.
- values_to memberikan nama variabel yang akan dibuat dari data yang disimpan dalam nilai sel kolom yang digabungkan.
Spesifikasi
Ini adalah fungsionalitas baru dari paket tidyr , yang sebelumnya tidak tersedia ketika bekerja dengan fungsi-fungsi usang.
Spesifikasi adalah bingkai data, setiap baris yang sesuai dengan satu kolom dalam bingkai tanggal keluaran baru, dan dua kolom khusus yang dimulai dengan:
- .name berisi nama asli kolom.
- .value berisi nama kolom tempat nilai sel akan pergi.
Kolom yang tersisa dari spesifikasi mencerminkan bagaimana nama kolom yang dapat dikompresi dari .name akan ditampilkan di kolom baru.
Spesifikasi menjelaskan metadata yang disimpan dalam nama kolom, dengan satu baris untuk setiap kolom dan satu kolom untuk setiap variabel dikombinasikan dengan nama kolom, mungkin definisi ini tampak membingungkan sekarang, tetapi setelah mempertimbangkan beberapa contoh semuanya akan menjadi lebih jelas.
Arti spesifikasinya adalah Anda dapat mengambil, memodifikasi, dan mengatur metadata baru untuk kerangka data yang dikonversi.
Fungsi pivot_longer_spec() untuk bekerja dengan spesifikasi saat mengonversi tabel dari format lebar ke format panjang.
Cara kerja fungsi ini, dibutuhkan kerangka tanggal apa pun, dan menghasilkan metadata-nya seperti dijelaskan di atas.
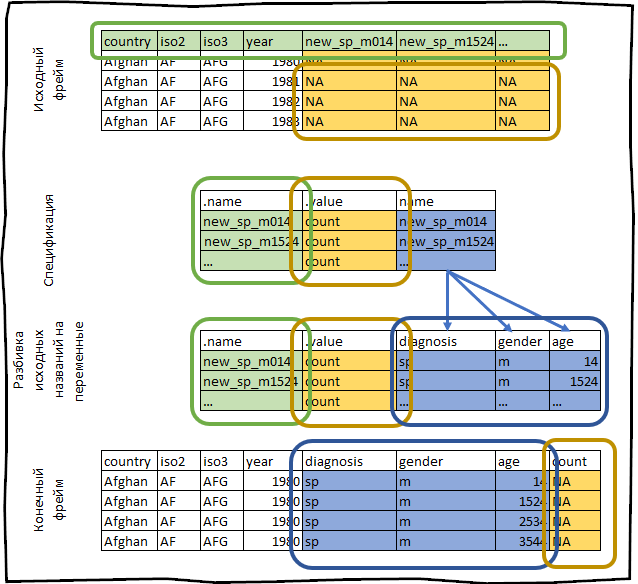
Sebagai contoh, mari kita ambil dataset siapa yang datang dengan paket tidyr . Dataset ini berisi informasi yang disediakan oleh organisasi kesehatan internasional tentang kejadian TBC.
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
Kami membangun spesifikasinya.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
Negara isian, iso2 , iso3 sudah menjadi variabel. Tugas kami adalah membalik kolom dari new_sp_m014 ke newrel_f65 .
Nama-nama kolom ini menyimpan informasi berikut:
- Awalan
new_ menunjukkan bahwa kolom berisi data tentang kasus baru tuberkulosis, kerangka tanggal saat ini hanya berisi informasi tentang penyakit baru, oleh karena itu awalan ini dalam konteks saat ini tidak membawa makna apa pun. sp / rel / sp / ep menjelaskan suatu metode untuk mendiagnosis suatu penyakit.m / f jenis kelamin pasien.014 rentang usia pasien.
Kita dapat memisahkan kolom-kolom ini menggunakan fungsi extract() menggunakan ekspresi reguler.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
Perhatikan bahwa kolom .name harus tetap tidak berubah, karena ini adalah indeks kami dalam nama kolom dari dataset sumber.
Jenis kelamin dan usia ( jenis kelamin dan usia ) memiliki nilai-nilai tetap dan diketahui, oleh karena itu disarankan untuk mengubah kolom ini menjadi faktor:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
Akhirnya, untuk menerapkan spesifikasi yang kami buat ke tanggal asli bingkai siapa , kita perlu menggunakan argumen spesifikasi dalam fungsi pivot_longer() .
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
Segala sesuatu yang baru saja kita lakukan dapat digambarkan secara skematis sebagai berikut:
Spesifikasi menggunakan beberapa nilai (.value)
Dalam contoh di atas, kolom spesifikasi .value hanya berisi satu nilai, dalam banyak kasus hal ini terjadi.
Tetapi kadang-kadang situasi mungkin muncul ketika Anda perlu mengumpulkan data dari kolom dengan tipe data yang berbeda dalam nilai. Menggunakan fungsi spread() digunakan lagi, ini akan cukup sulit.
Contoh berikut dipinjam dari sketsa untuk paket data.table .
Mari kita buat kerangka data pelatihan.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
Kerangka tanggal yang dibuat di setiap baris berisi data tentang anak-anak dari satu keluarga. Keluarga dapat memiliki satu atau dua anak. Untuk setiap anak, data tentang tanggal lahir dan jenis kelamin disediakan, dan data untuk setiap anak dalam kolom terpisah, tugas kami adalah membawa data ini ke format yang benar untuk dianalisis.
Harap dicatat bahwa kami memiliki dua variabel dengan informasi tentang setiap anak: jenis kelamin dan tanggal lahirnya (kolom dengan awalan dop berisi tanggal lahir, kolom dengan awalan gender berisi jenis kelamin anak). Dalam hasil yang diharapkan, mereka harus masuk dalam kolom terpisah. Kita dapat melakukan ini dengan membuat spesifikasi di mana kolom .value akan memiliki dua nilai yang berbeda.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
Jadi, mari kita melangkah melalui langkah-langkah yang dilakukan oleh kode di atas.
pivot_longer_spec(-family) - buat spesifikasi yang memampatkan semua kolom yang tersedia kecuali kolom keluarga.separate(col = name, into = c(".value", "child")) - pisahkan kolom .name , yang berisi nama-nama bidang sumber, garis bawah dan masukkan nilainya ke dalam kolom .value dan child .mutate(child = parse_number(child)) - mengonversi nilai-nilai bidang anak dari teks ke tipe data numerik.
Sekarang kita bisa menerapkan spesifikasi yang diterima ke bingkai data awal, dan membawa tabel ke formulir yang diinginkan.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
Kami menggunakan argumen na.rm = TRUE , karena formulir data saat ini memaksa kami untuk membuat baris tambahan untuk pengamatan yang tidak ada. Karena keluarga 2 hanya memiliki satu anak, na.rm = TRUE memastikan bahwa keluarga 2 akan memiliki satu baris dalam output.
pivot_wider() - adalah transformasi terbalik, dan sebaliknya meningkatkan jumlah kolom dalam tanggal bingkai dengan mengurangi jumlah baris.
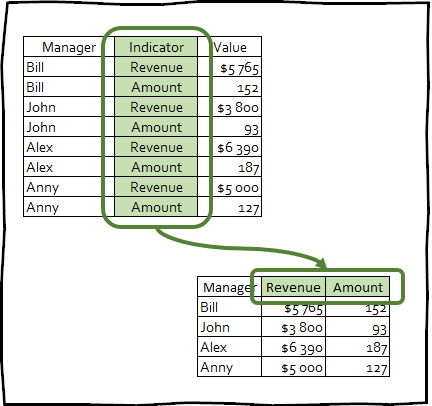
Transformasi semacam ini jarang digunakan untuk membawa data ke tampilan yang rapi, namun teknik ini dapat berguna untuk membuat tabel pivot yang digunakan dalam presentasi, atau untuk integrasi dengan alat lain.
Bahkan, fungsi pivot_longer() dan pivot_wider() simetris, dan mereka melakukan tindakan yang berlawanan, yaitu: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) dan df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) akan mengembalikan df asli.
Untuk mendemonstrasikan operasi fungsi pivot_wider() , kami akan menggunakan dataset fish_encounters , yang menyimpan informasi tentang bagaimana berbagai stasiun merekam pergerakan ikan di sepanjang sungai.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
Dalam kebanyakan kasus, tabel ini akan lebih informatif dan nyaman digunakan jika Anda memberikan informasi untuk setiap stasiun dalam kolom terpisah.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
Kumpulan data ini mencatat informasi hanya ketika ikan terdeteksi oleh stasiun, mis. jika ada ikan yang tidak diperbaiki oleh beberapa stasiun, maka data ini tidak akan ada dalam tabel. Ini berarti bahwa output akan diisi oleh NA.
Namun, dalam kasus ini, kita tahu bahwa tidak adanya catatan berarti bahwa ikan tidak diperhatikan, sehingga kita dapat menggunakan argumen values_fill dalam fungsi pivot_wider() dan mengisi nilai-nilai yang hilang ini dengan nol:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
Menghasilkan nama kolom dari beberapa variabel sumber
Bayangkan kita memiliki tabel yang berisi kombinasi produk, negara, dan tahun. Untuk menghasilkan tanggal bingkai uji, Anda dapat menjalankan kode berikut:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
Tugas kami adalah memperluas kerangka tanggal sehingga satu kolom berisi data untuk setiap kombinasi produk dan negara. Untuk melakukan ini, cukup lewati vektor yang berisi nama-nama bidang yang akan digabungkan ke argumen names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
Anda juga dapat menerapkan spesifikasi ke fungsi pivot_wider() . Tetapi ketika dipasok ke pivot_wider() spesifikasi melakukan kebalikan dari pivot_longer() : kolom yang ditentukan dalam .name dibuat menggunakan nilai dari .value dan kolom lainnya.
Untuk rangkaian data ini, Anda dapat membuat spesifikasi pengguna jika Anda ingin setiap kombinasi negara dan produk yang mungkin memiliki kolom sendiri, dan bukan hanya yang ada dalam data:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
Beberapa contoh canggih bekerja dengan konsep tidyr baru
Membawa data ke tampilan yang rapi menggunakan dataset sensus pendapatan dan sewa AS sebagai contoh
Dataset us_rent_income berisi informasi tentang pendapatan rata-rata dan sewa untuk setiap negara bagian di Amerika Serikat untuk 2017 (dataset tersedia dalam paket tidycensus ).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
Sangat tidak nyaman untuk bekerja dengan mereka dalam bentuk penyimpanan data di us_rent_income, jadi kami ingin membuat kumpulan data dengan kolom: rent , rent_moe , come , income_moe . Ada banyak cara untuk membuat spesifikasi ini, tetapi yang utama adalah kita perlu menghasilkan setiap kombinasi dari nilai variabel dan estimasi / moe , dan kemudian menghasilkan nama kolom.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
Memberikan spesifikasi ini ke pivot_wider() memberi kami hasil yang kami cari:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
Bank Dunia
Terkadang membawa set data ke formulir yang tepat membutuhkan beberapa langkah.
Dataset world_bank_pop berisi data dari Bank Dunia tentang populasi setiap negara dari 2000 hingga 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
Tujuan kami adalah untuk membuat dataset yang rapi di mana setiap variabel berada di kolom terpisah. Belum jelas langkah mana yang diperlukan, tetapi kami akan mulai dengan masalah yang paling jelas: tahun didistribusikan di beberapa kolom.
Untuk memperbaikinya, Anda harus menggunakan fungsi pivot_longer() .
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
Kesimpulan
, tidyr , spread() gather() . pivot_longer() pivot_wider() .