
Kode perangkat lunak pembelajaran mesin seringkali rumit dan agak membingungkan. Mendeteksi dan menghilangkan bug di dalamnya adalah tugas intensif sumber daya. Bahkan
jaringan saraf yang terhubung langsung dan paling sederhana memerlukan pendekatan yang serius untuk arsitektur jaringan, inisialisasi bobot, dan optimisasi jaringan. Kesalahan kecil dapat menyebabkan masalah yang tidak menyenangkan.
Artikel ini adalah tentang algoritma debugging dari jaringan saraf Anda.
Skillbox merekomendasikan: Pengembang Python langsung dari awal .
Kami mengingatkan Anda: untuk semua pembaca "Habr" - diskon 10.000 rubel saat mendaftar untuk kursus Skillbox apa pun menggunakan kode promo "Habr".
Algoritma ini terdiri dari lima tahap:
- awal yang sederhana;
- konfirmasi kerugian;
- verifikasi hasil dan senyawa antara;
- diagnostik parameter;
- kontrol kerja.
Jika sesuatu tampak lebih menarik bagi Anda daripada yang lain, Anda dapat langsung menuju ke bagian ini.
Awal yang mudah
Jaringan saraf dengan arsitektur yang kompleks, regularisasi, dan perencana kecepatan belajar lebih sulit untuk debut daripada jaringan biasa. Kami sedikit rumit di sini, karena item itu sendiri memiliki hubungan tidak langsung dengan debugging, tetapi ini masih merupakan rekomendasi penting.
Awal yang sederhana adalah membuat model yang disederhanakan dan melatihnya pada satu set data (titik).
Pertama kita membuat model yang disederhanakanUntuk memulai lebih cepat, buat jaringan kecil dengan satu lapisan tersembunyi dan periksa apakah semuanya berfungsi dengan benar. Kemudian kami secara bertahap menyulitkan model, memeriksa setiap aspek baru dari strukturnya (lapisan tambahan, parameter, dll.), Dan melanjutkan.
Kami melatih model pada satu set data (titik)Sebagai tes cepat kesehatan proyek Anda, Anda dapat menggunakan satu atau dua titik data untuk pelatihan untuk mengonfirmasi apakah sistem bekerja dengan benar. Jaringan saraf harus menunjukkan akurasi pelatihan dan verifikasi 100%. Jika ini bukan masalahnya, maka modelnya terlalu kecil atau Anda sudah memiliki bug.
Bahkan jika semuanya baik-baik saja, persiapkan model untuk perjalanan satu atau lebih era sebelum melanjutkan.
Estimasi kerugian
Estimasi kehilangan adalah cara utama untuk memperbaiki kinerja model. Anda perlu memastikan bahwa kerugian sesuai dengan tugas, dan fungsi kerugian dievaluasi pada skala yang benar. Jika Anda menggunakan lebih dari satu jenis kerugian, maka pastikan semuanya memiliki urutan yang sama dan diskalakan dengan benar.
Penting untuk memperhatikan kerugian awal. Periksa seberapa dekat hasil nyata dengan yang diharapkan jika model dimulai dengan asumsi acak.
Pekerjaan Andrei Karpati menyarankan yang berikut : “Pastikan Anda mendapatkan hasil yang diharapkan ketika Anda mulai bekerja dengan sejumlah kecil parameter. Lebih baik segera memeriksa kehilangan data (dengan tingkat regularisasi diatur ke nol). Misalnya, untuk CIFAR-10 dengan classifier Softmax, kami memperkirakan kerugian awal adalah 2,302, karena probabilitas difus yang diharapkan adalah 0,1 untuk setiap kelas (karena ada 10 kelas), dan hilangnya Softmax adalah probabilitas logaritmik negatif dari kelas yang benar seperti - Dalam (0,1) = 2,302. "
Sebagai contoh biner, perhitungan yang serupa hanya dilakukan untuk masing-masing kelas. Di sini, misalnya, adalah data: 20% 0 dan 80% 1. Kerugian awal yang diharapkan akan sampai -0,2ln (0,5) -0,8ln (0,5) = 0,693147. Jika hasilnya lebih besar dari 1, ini dapat menunjukkan bahwa bobot jaringan saraf tidak seimbang dengan baik atau data tidak dinormalisasi.
Memeriksa hasil dan koneksi antara
Untuk men-debug jaringan saraf, perlu untuk memahami dinamika proses dalam jaringan dan peran masing-masing lapisan menengah, karena mereka terhubung. Berikut adalah beberapa kesalahan umum yang mungkin Anda temui:
- Ekspresi yang salah untuk pembaruan gradien
- pembaruan berat tidak berlaku;
- menghilang atau meledak gradien.
Jika nilai gradien nol, ini berarti bahwa kecepatan latihan dalam pengoptimal terlalu rendah, atau Anda telah menemukan ekspresi yang salah untuk memperbarui gradien.
Selain itu, perlu untuk memantau nilai-nilai fungsi aktivasi, bobot dan pembaruan dari masing-masing lapisan. Misalnya, nilai pembaruan parameter (bobot dan offset)
harus 1-e3 .
Ada fenomena yang disebut "Dying ReLU" atau
"Disappearing Gradient Problem" ketika neuron ReLU akan menghasilkan nol setelah mempelajari nilai bias negatif yang besar untuk bobotnya. Neuron-neuron ini tidak pernah diaktifkan lagi di tempat data apa pun.
Anda dapat menggunakan pengujian gradien untuk mendeteksi kesalahan ini dengan mendekati gradien menggunakan pendekatan numerik. Jika dekat dengan gradien yang dihitung, maka propagasi kembali diimplementasikan dengan benar. Untuk membuat pemeriksaan gradien, lihat sumber daya CS231 yang hebat di
sini dan di
sini , serta tutorial Andrew Nga tentang topik ini.
Fayzan Sheikh menunjukkan tiga metode utama untuk memvisualisasikan jaringan saraf:
- Pendahuluan - metode sederhana yang menunjukkan kepada kita struktur umum model yang dilatih. Mereka termasuk output dari bentuk atau filter lapisan individu dari jaringan saraf dan parameter di setiap lapisan.
- Berdasarkan aktivasi. Di dalamnya, kami menguraikan aktivasi masing-masing neuron atau kelompok neuron untuk memahami fungsinya.
- Berbasis gradien. Metode-metode ini cenderung memanipulasi gradien yang terbentuk dari bolak-balik saat melatih model (termasuk peta signifikansi dan peta aktivasi kelas).
Ada beberapa alat yang berguna untuk memvisualisasikan aktivasi dan koneksi masing-masing lapisan, misalnya,
ConX dan
Tensorboard .
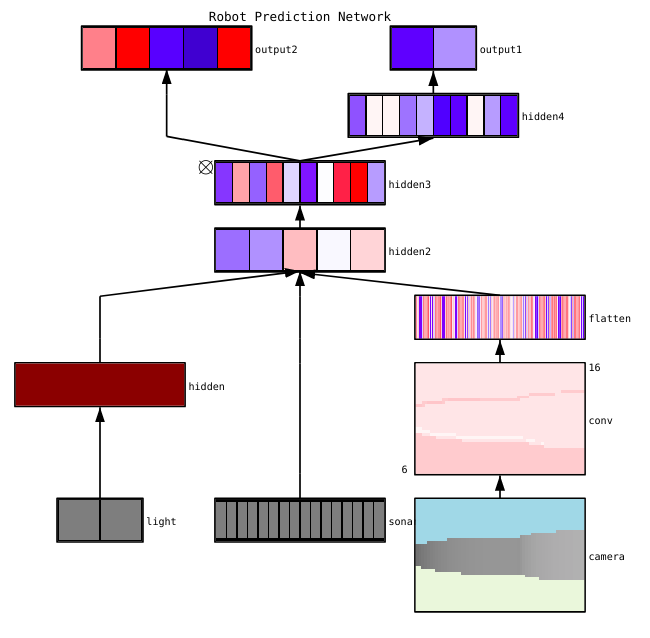
Diagnostik Parameter
Jaringan saraf memiliki banyak parameter yang berinteraksi satu sama lain, yang mempersulit optimasi. Sebenarnya, bagian ini adalah subjek penelitian aktif oleh spesialis, sehingga proposal di bawah ini harus dianggap hanya sebagai saran, titik awal dari mana Anda dapat membangun.
Ukuran paket (
ukuran batch) - jika Anda ingin ukuran paket cukup besar untuk mendapatkan perkiraan gradien kesalahan yang akurat, tetapi cukup kecil sehingga stochastic gradient descent (SGD) dapat merampingkan jaringan Anda. Ukuran kecil dari paket akan mengarah pada konvergensi yang cepat karena kebisingan dalam proses pembelajaran dan di masa depan kesulitan optimasi. Ini dijelaskan lebih rinci di
sini .
Kecepatan Belajar - Terlalu lambat akan menghasilkan konvergensi yang lambat atau risiko terjebak dalam posisi terendah lokal. Pada saat yang sama, kecepatan belajar yang tinggi akan menyebabkan perbedaan dalam optimasi, karena Anda berisiko "melompat" melalui kedalaman, tetapi pada saat yang sama mempersempit bagian dari fungsi kerugian. Coba gunakan perencanaan kecepatan untuk menguranginya selama pelatihan jaringan saraf. CS231n
memiliki bagian besar tentang masalah ini .
Gradient clipping - memangkas gradien parameter selama propagasi balik pada nilai maksimum atau norma batas. Berguna untuk memecahkan masalah dengan gradien meledak yang mungkin Anda temui di paragraf ketiga.
Batch normalisasi - digunakan untuk menormalkan data input dari setiap lapisan, yang memungkinkan untuk menyelesaikan masalah pergeseran kovarian internal. Jika Anda menggunakan Dropout dan Batch Norma bersama-sama,
lihat artikel ini .
Stochastic Gradient Descent (SGD) - Ada beberapa jenis SGD yang menggunakan momentum, kecepatan belajar adaptif, dan metode Nesterov. Pada saat yang sama, tidak satu pun dari mereka memiliki keunggulan yang jelas baik dalam hal efisiensi pelatihan dan generalisasi (
detail di sini ).
Regularisasi - sangat penting untuk membangun model umum, karena menambah penalti untuk kompleksitas model atau nilai parameter ekstrim. Ini adalah cara untuk mengurangi varians model tanpa secara signifikan meningkatkan perpindahannya. Informasi lebih
lanjut di sini .
Untuk mengevaluasi semuanya sendiri, Anda harus menonaktifkan regularisasi dan memeriksa sendiri gradien kehilangan data.
Dropout adalah cara lain untuk merampingkan jaringan Anda untuk mencegah kemacetan. Selama pelatihan, kehilangan hanya terjadi dengan mempertahankan aktivitas neuron dengan probabilitas p tertentu (hiperparameter) atau menetapkannya ke nol pada kasus yang berlawanan. Akibatnya, jaringan harus menggunakan subset parameter yang berbeda untuk setiap pihak pelatihan, yang mengurangi perubahan pada parameter tertentu yang menjadi dominan.
Penting: jika Anda menggunakan normalisasi dropout dan batch, berhati-hatilah dengan urutan operasi ini atau bahkan dengan penggunaan bersama mereka. Semua ini masih dibahas dan ditambah secara aktif. Berikut adalah dua diskusi penting tentang topik ini
tentang Stackoverflow dan
Arxiv .
Kontrol kerja
Ini tentang mendokumentasikan alur kerja dan eksperimen. Jika Anda tidak mendokumentasikan apa pun, Anda bisa lupa, misalnya, kecepatan latihan atau bobot kelas seperti apa yang digunakan. Berkat kontrolnya, Anda dapat dengan mudah melihat dan mereproduksi eksperimen sebelumnya. Ini mengurangi jumlah percobaan duplikat.
Benar, dokumentasi manual bisa jadi menantang jika ada banyak pekerjaan. Di sini alat-alat seperti Comet.ml membantu Anda untuk secara otomatis mencatat kumpulan data, perubahan kode, riwayat percobaan, dan model produksi, termasuk informasi kunci tentang model Anda (hyperparameters, indikator kinerja model, dan informasi lingkungan).
Jaringan saraf bisa sangat sensitif terhadap perubahan kecil, dan ini akan menyebabkan penurunan kinerja model. Melacak dan mendokumentasikan pekerjaan adalah langkah pertama yang harus diambil untuk membakukan lingkungan dan pemodelan Anda.
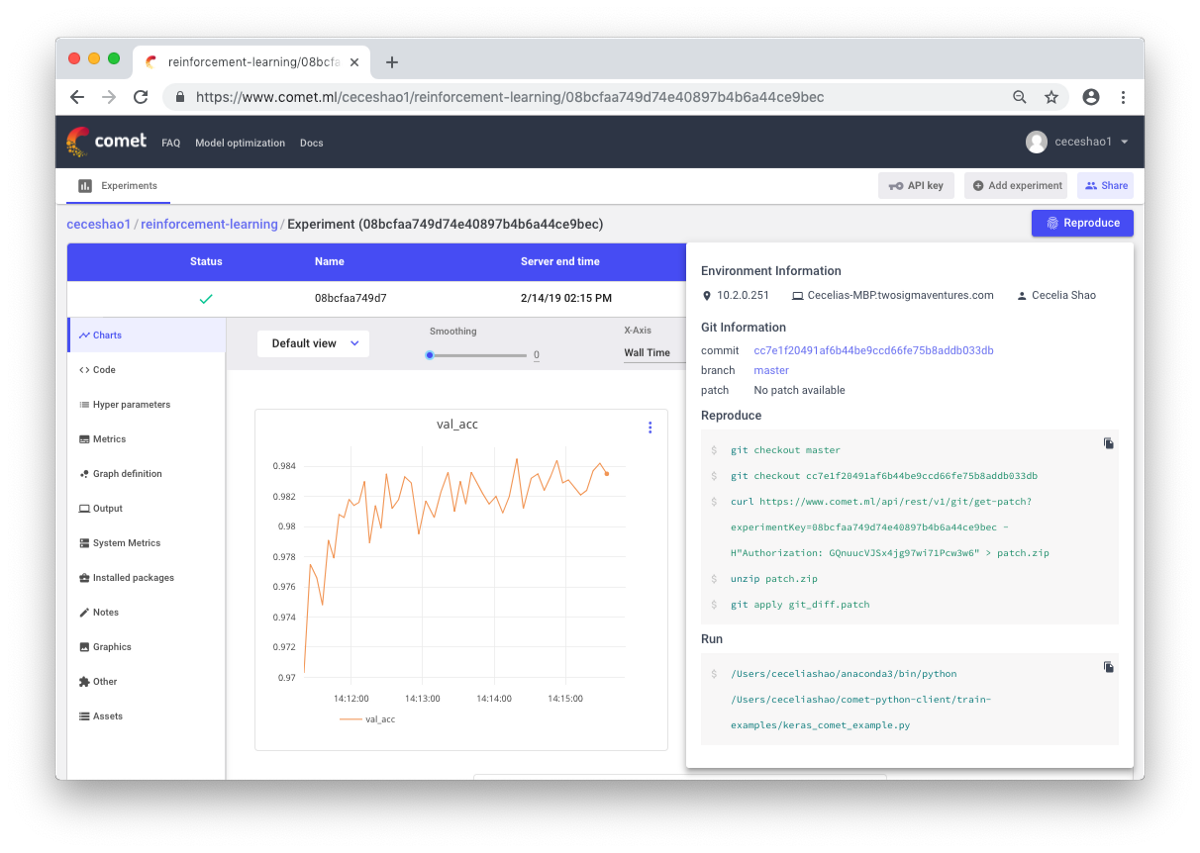
Saya harap posting ini dapat menjadi titik awal dari mana Anda akan mulai men-debug jaringan saraf Anda.
Skillbox merekomendasikan: