Pada artikel sebelumnya, kami membahas
mesin pengindeksan PostgreSQL,
antarmuka metode akses , dan dua metode akses:
indeks hash dan
B-tree . Pada artikel ini, kami akan menjelaskan indeks GiST.
Intisari
GiST adalah singkatan dari "pohon pencarian umum". Ini adalah pohon pencarian seimbang, seperti "b-tree" yang dibahas sebelumnya.
Apa bedanya? "Btree" indeks secara ketat terhubung ke semantik perbandingan: dukungan dari operator "lebih besar", "kurang", dan "sama" adalah semua yang mampu (tetapi sangat mampu!) Namun, database modern menyimpan tipe data yang digunakan operator ini tidak masuk akal: geodata, dokumen teks, gambar, ...
Metode indeks GiST membantu kami untuk tipe data ini. Ini memungkinkan mendefinisikan aturan untuk mendistribusikan data dari tipe arbitrer di pohon seimbang dan metode untuk menggunakan representasi ini untuk akses oleh beberapa operator. Misalnya, indeks GiST dapat "mengakomodasi" R-tree untuk data spasial dengan dukungan operator posisi relatif (terletak di sebelah kiri, di sebelah kanan, berisi, dll.) Atau RD-tree untuk set dengan dukungan operator persimpangan atau inklusi.
Berkat ekstensibilitas, metode yang sama sekali baru dapat dibuat dari awal di PostgreSQL: untuk tujuan ini, antarmuka dengan mesin pengindeksan harus diimplementasikan. Tetapi ini membutuhkan perencanaan awal tidak hanya logika pengindeksan, tetapi juga memetakan struktur data ke halaman, implementasi kunci yang efisien, dan dukungan log menulis-depan. Semua ini mengasumsikan keterampilan pengembang yang tinggi dan upaya manusia yang besar. GiST menyederhanakan tugas dengan mengambil alih masalah tingkat rendah dan menawarkan antarmuka sendiri: beberapa fungsi yang tidak berkaitan dengan teknik, tetapi untuk domain aplikasi. Dalam hal ini, kita dapat menganggap GiST sebagai kerangka kerja untuk membangun metode akses baru.
Struktur
GiST adalah pohon seimbang tinggi yang terdiri dari halaman simpul. Node terdiri dari baris indeks.
Setiap baris simpul daun (baris daun), secara umum, berisi beberapa
predikat (ekspresi boolean) dan referensi ke baris tabel (TID). Data yang diindeks (kunci) harus memenuhi predikat ini.
Setiap baris dari simpul internal (baris internal) juga berisi
predikat dan referensi ke simpul anak, dan semua data yang diindeks dari subtree anak harus memenuhi predikat ini. Dengan kata lain, predikat baris internal
mencakup predikat semua baris anak. Sifat penting dari indeks GiST ini menggantikan pemesanan sederhana B-tree.
Pencarian di pohon GiST menggunakan
fungsi konsistensi khusus ("konsisten") - salah satu fungsi yang ditentukan oleh antarmuka dan diimplementasikan dengan caranya sendiri untuk setiap keluarga operator yang didukung.
Fungsi konsistensi dipanggil untuk baris indeks dan menentukan apakah predikat baris ini konsisten dengan predikat pencarian (ditentukan sebagai "
ekspresi operator bidang-bidang yang diindeks "). Untuk baris internal, fungsi ini benar-benar menentukan apakah diperlukan untuk turun ke subtree yang sesuai, dan untuk baris daun, fungsi menentukan apakah data yang diindeks memenuhi predikat.
Pencarian dimulai dengan simpul akar, sebagai pencarian pohon normal. Fungsi konsistensi memungkinkan untuk mengetahui node anak mana yang masuk akal (mungkin ada beberapa) dan yang tidak. Algoritma ini kemudian diulang untuk setiap simpul anak yang ditemukan. Dan jika simpul adalah daun, baris yang dipilih oleh fungsi konsistensi dikembalikan sebagai salah satu hasilnya.
Pencariannya adalah kedalaman-pertama: algoritma pertama-tama mencoba mencapai simpul daun. Ini memungkinkan untuk mengembalikan hasil pertama segera bila memungkinkan (yang mungkin penting jika pengguna hanya tertarik pada beberapa hasil daripada semuanya).
Sekali lagi mari kita perhatikan bahwa fungsi konsistensi tidak perlu ada hubungannya dengan operator "lebih besar", "kurang", atau "sama". Semantik fungsi konsistensi mungkin sangat berbeda dan oleh karena itu, indeks tidak dianggap menghasilkan nilai dalam urutan tertentu.
Kami tidak akan membahas algoritma penyisipan dan penghapusan nilai dalam GiST: beberapa
fungsi antarmuka melakukan operasi ini. Namun ada satu poin penting. Ketika nilai baru dimasukkan ke dalam indeks, posisi untuk nilai ini di pohon dipilih sehingga predikat baris induknya diperluas sesedikit mungkin (idealnya, tidak diperpanjang sama sekali). Tetapi ketika nilai dihapus, predikat baris induk tidak berkurang lagi. Ini hanya terjadi dalam kasus-kasus seperti ini: halaman dipecah menjadi dua (ketika halaman tidak memiliki cukup ruang untuk memasukkan baris indeks baru) atau indeks dibuat kembali dari awal (dengan perintah REINDEX atau VACUUM FULL). Oleh karena itu, efisiensi indeks GiST untuk data yang sering berubah dapat menurun seiring waktu.
Lebih lanjut kami akan mempertimbangkan beberapa contoh indeks untuk berbagai tipe data dan properti berguna GiST:
- Poin (dan entitas geometris lainnya) dan pencarian tetangga terdekat.
- Interval dan batasan pengecualian.
- Pencarian teks lengkap.
R-tree untuk poin
Kami akan mengilustrasikan contoh di atas dengan contoh indeks untuk titik-titik dalam bidang (kami juga dapat membuat indeks serupa untuk entitas geometris lainnya). B-tree reguler tidak cocok dengan tipe data data ini karena tidak ada operator pembanding yang ditentukan untuk poin.
Gagasan R-tree adalah untuk membagi pesawat menjadi empat persegi panjang yang secara total mencakup semua poin yang diindeks. Baris indeks menyimpan persegi panjang, dan predikat dapat didefinisikan seperti ini: "titik yang dicari terletak di dalam persegi panjang yang diberikan".
Akar R-tree akan berisi beberapa persegi panjang terbesar (mungkin berpotongan). Node anak akan berisi persegi panjang ukuran lebih kecil yang tertanam di induknya dan secara total mencakup semua titik yang mendasarinya.
Secara teori, node daun harus mengandung titik yang diindeks, tetapi tipe data harus sama di semua baris indeks dan oleh karena itu, lagi persegi panjang disimpan, tetapi "diciutkan" menjadi poin.
Untuk memvisualisasikan struktur seperti itu, kami menyediakan gambar untuk tiga tingkat R-tree. Poin adalah koordinat bandara (mirip dengan yang ada di tabel "bandara" dari
database demo , tetapi lebih banyak data dari
openflights.org disediakan).
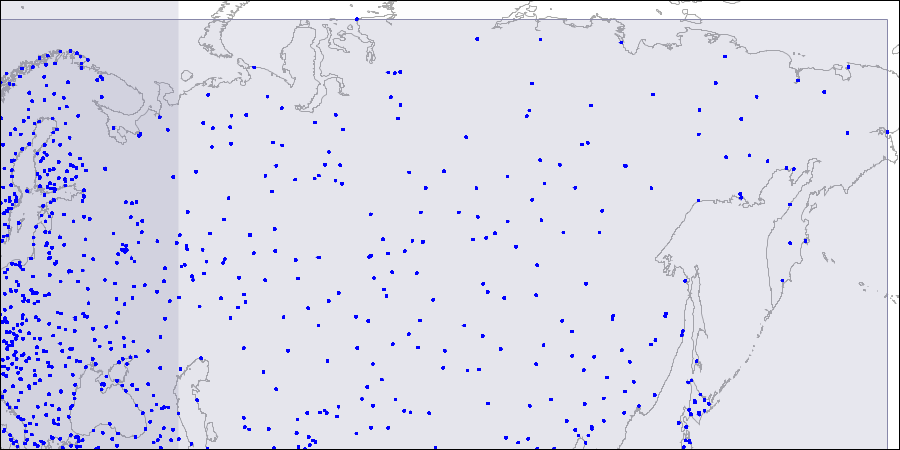 Tingkat satu: dua persegi panjang berpotongan besar terlihat.
Tingkat satu: dua persegi panjang berpotongan besar terlihat. Level dua: persegi panjang besar dibagi menjadi area yang lebih kecil.
Level dua: persegi panjang besar dibagi menjadi area yang lebih kecil.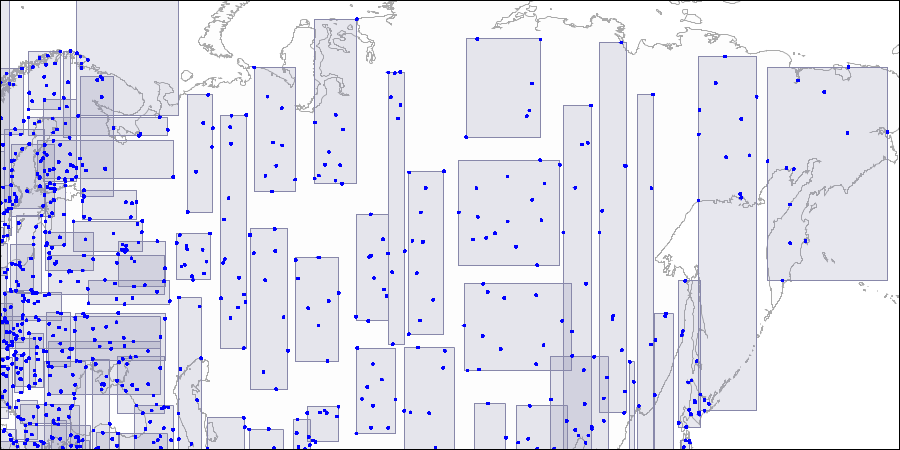 Level tiga: setiap kotak berisi poin sebanyak yang sesuai dengan satu halaman indeks.
Level tiga: setiap kotak berisi poin sebanyak yang sesuai dengan satu halaman indeks.Sekarang mari kita perhatikan contoh "satu tingkat" yang sangat sederhana:
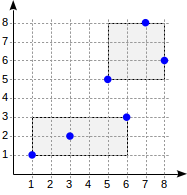
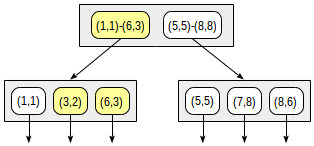
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index on points using gist(p);
Dengan pemisahan ini, struktur indeks akan terlihat sebagai berikut:
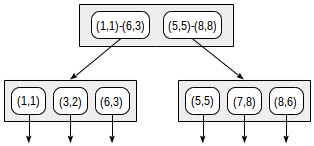
Indeks yang dibuat dapat digunakan untuk mempercepat kueri berikut, misalnya: "temukan semua titik yang terkandung dalam kotak yang diberikan". Kondisi ini dapat diformalkan sebagai berikut:
p <@ box '(2,1),(6,3)' (operator
<@ dari "points_ops" keluarga berarti "terkandung dalam"):
postgres=# set enable_seqscan = off; postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN ---------------------------------------------- Index Only Scan using points_p_idx on points Index Cond: (p <@ '(7,4),(2,1)'::box) (2 rows)
Fungsi konsistensi operator ("
bidang terindeks <@
ekspresi ", di mana
bidang berindeks adalah titik dan
ekspresi adalah persegi panjang) didefinisikan sebagai berikut. Untuk baris internal, ia mengembalikan "ya" jika persegi panjangnya bersinggungan dengan persegi panjang yang ditentukan oleh
ekspresi . Untuk baris daun, fungsi mengembalikan "ya" jika titiknya ("runtuh" persegi panjang) terkandung dalam persegi panjang yang ditentukan oleh ekspresi.
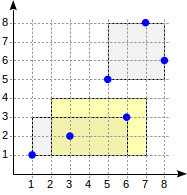
Pencarian dimulai dengan root node. Persegi panjang (2,1) - (7,4) berpotongan dengan (1,1) - (6,3), tetapi tidak berpotongan dengan (5,5) - (8,8), oleh karena itu, tidak perlu untuk turun ke subtree kedua.
Setelah mencapai simpul daun, kita pergi melalui tiga poin yang terkandung di sana dan mengembalikan dua di antaranya sebagai hasilnya: (3.2) dan (6.3).
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p ------- (3,2) (6,3) (2 rows)
Internal
Sayangnya, "pageinspect" biasa tidak memungkinkan melihat indeks GiST. Tetapi cara lain tersedia: ekstensi "gevel". Itu tidak termasuk dalam pengiriman standar, jadi lihat
instruksi instalasi .
Jika semuanya dilakukan dengan benar, tiga fungsi akan tersedia untuk Anda. Pertama, kita bisa mendapatkan beberapa statistik:
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat ------------------------------------------ Number of levels: 4 + Number of pages: 690 + Number of leaf pages: 625 + Number of tuples: 7873 + Number of invalid tuples: 0 + Number of leaf tuples: 7184 + Total size of tuples: 354692 bytes + Total size of leaf tuples: 323596 bytes + Total size of index: 5652480 bytes+ (1 row)
Jelas bahwa ukuran indeks pada koordinat bandara adalah 690 halaman dan indeks terdiri dari empat tingkat: root dan dua tingkat internal ditunjukkan pada gambar di atas, dan tingkat keempat adalah daun.
Sebenarnya, indeks untuk delapan ribu poin akan secara signifikan lebih kecil: di sini dibuat dengan fillfactor 10% untuk kejelasan.
Kedua, kita dapat menampilkan pohon indeks:
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree ----------------------------------------------------------------------------------------- 0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) + 1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) + 1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) + 1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) + 2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) + 3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) + 4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) + ...
Dan ketiga, kita bisa menampilkan data yang disimpan dalam baris indeks. Perhatikan nuansa berikut: hasil fungsi harus dilemparkan ke tipe data yang dibutuhkan. Dalam situasi kami, tipe ini adalah "kotak" (persegi panjang pembatas). Misalnya, perhatikan lima baris di tingkat atas:
postgres=# select level, a from gist_print('airports_coordinates_idx') as t(level int, valid bool, a box) where level = 1;
level | a -------+----------------------------------------------------------------------- 1 | (47.663586,80.803207),(-39.2938003540039,-90) 1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336) 1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047) 1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291) 1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088) (5 rows)
Sebenarnya, angka-angka yang diberikan di atas dibuat hanya dari data ini.
Operator untuk pencarian dan pemesanan
Operator yang dibahas sejauh ini (seperti
<@ dalam predikat
p <@ box '(2,1),(7,4)' ) dapat disebut operator pencarian karena mereka menentukan kondisi pencarian dalam suatu query.
Ada juga tipe operator lain: operator pemesanan. Mereka digunakan untuk spesifikasi urutan sortir dalam klausa ORDER BY alih-alih spesifikasi konvensional nama kolom. Berikut ini adalah contoh dari permintaan seperti itu:
postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p ------- (5,5) (7,8) (2 rows)
p <-> point '(4,7)' sini adalah ekspresi yang menggunakan operator pemesanan
<-> , yang menunjukkan jarak dari satu argumen ke argumen lainnya. Arti dari kueri adalah mengembalikan dua titik terdekat ke titik (4.7). Pencarian seperti ini dikenal sebagai k-NN - k-tetangga terdekat pencarian.
Untuk mendukung pertanyaan semacam ini, metode akses harus menentukan
fungsi jarak tambahan, dan operator pemesanan harus dimasukkan dalam kelas operator yang sesuai (misalnya, kelas "points_ops" untuk poin). Kueri di bawah ini menunjukkan operator, beserta tipenya ("s" - pencarian dan "o" - pemesanan):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------+-------------+-------------- <<(point,point) | s | 1 strictly left >>(point,point) | s | 5 strictly right ~=(point,point) | s | 6 coincides <^(point,point) | s | 10 strictly below >^(point,point) | s | 11 strictly above <->(point,point) | o | 15 distance <@(point,box) | s | 28 contained in rectangle <@(point,polygon) | s | 48 contained in polygon <@(point,circle) | s | 68 contained in circle (9 rows)
Jumlah strategi juga ditampilkan, dengan artinya dijelaskan. Jelas bahwa ada lebih banyak strategi daripada "btree", hanya beberapa dari mereka yang didukung untuk poin. Strategi yang berbeda dapat didefinisikan untuk tipe data lainnya.
Fungsi jarak dipanggil untuk elemen indeks, dan itu harus menghitung jarak (dengan mempertimbangkan semantik operator) dari nilai yang ditentukan oleh ekspresi ("ekspresi
bidang-operator pemesanan-ekspresi ") ke elemen yang diberikan. Untuk elemen daun, ini hanya jarak ke nilai yang diindeks. Untuk elemen internal, fungsi harus mengembalikan jarak minimum ke elemen daun anak. Karena melalui semua baris anak akan sangat mahal, fungsi ini diizinkan untuk meremehkan jarak secara optimis, tetapi dengan mengorbankan mengurangi efisiensi pencarian. Namun, fungsi ini tidak pernah diizinkan untuk melebih-lebihkan jarak karena ini akan mengganggu pekerjaan indeks.
Fungsi jarak dapat mengembalikan nilai jenis apa pun yang dapat diurutkan (untuk memesan nilai, PostgreSQL akan menggunakan semantik perbandingan dari keluarga operator yang sesuai dari metode akses "btree", seperti yang
dijelaskan sebelumnya ).
Untuk titik-titik dalam sebuah pesawat, jarak ditafsirkan dalam arti yang sangat biasa: nilai
(x1,y1) <-> (x2,y2) sama dengan akar kuadrat dari jumlah kuadrat perbedaan abscissas dan ordinat. Jarak dari suatu titik ke persegi panjang terikat diambil sebagai jarak minimal dari titik ke persegi panjang ini atau nol jika titik tersebut terletak di dalam persegi panjang. Mudah untuk menghitung nilai ini tanpa berjalan melalui titik anak, dan nilainya pasti tidak lebih besar dari jarak ke titik anak mana pun.
Mari pertimbangkan algoritma pencarian untuk kueri di atas.
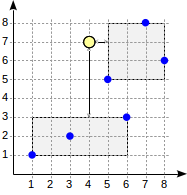
Pencarian dimulai dengan root node. Node berisi dua persegi panjang yang saling terikat. Jarak ke (1,1) - (6,3) adalah 4,0 dan ke (5,5) - (8,8) adalah 1,0.
Simpul anak dilalui dengan urutan yang meningkatkan jarak. Dengan cara ini, pertama-tama kita turun ke simpul anak terdekat dan menghitung jarak ke titik (kami akan menunjukkan angka dalam gambar untuk visibilitas):

Informasi ini cukup untuk mengembalikan dua poin pertama, (5,5) dan (7,8). Karena kita sadar bahwa jarak ke titik-titik yang terletak di dalam persegi panjang (1,1) - (6,3) adalah 4,0 atau lebih besar, kita tidak perlu turun ke simpul anak pertama.
Tetapi bagaimana jika kita perlu menemukan
tiga poin pertama?
postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
Meskipun simpul anak kedua berisi semua titik ini, kami tidak dapat kembali (8,6) tanpa melihat ke simpul anak pertama karena simpul ini dapat mengandung titik yang lebih dekat (sejak 4,0 <4,1).

Untuk baris internal, contoh ini menjelaskan persyaratan untuk fungsi jarak. Dengan memilih jarak yang lebih kecil (4,0 bukannya 4,5 sebenarnya) untuk baris kedua, kami mengurangi efisiensi (algoritma perlu mulai memeriksa node tambahan), tetapi tidak merusak kebenaran algoritma.
Sampai saat ini, GiST adalah satu-satunya metode akses yang mampu menangani operator pemesanan. Tetapi situasinya telah berubah: metode akses RUM (akan dibahas lebih lanjut) telah bergabung dengan kelompok metode ini, dan bukan tidak mungkin pohon B-tua yang baik akan bergabung dengan mereka: patch yang dikembangkan oleh Nikita Glukhov, kolega kami, sedang dibahas oleh masyarakat.
Pada Maret 2019, dukungan k-NN ditambahkan untuk SP-GiST di PostgreSQL 12 mendatang (juga ditulis oleh Nikita). Patch untuk B-tree masih dalam proses.
R-tree untuk interval
Contoh lain menggunakan metode akses GiST adalah pengindeksan interval, misalnya, interval waktu (tipe "tsrange"). Semua perbedaannya adalah bahwa node internal akan berisi interval pembatas bukannya persegi panjang pembatas.
Mari kita perhatikan contoh sederhana. Kami akan menyewakan pondok dan menyimpan interval pemesanan dalam sebuah tabel:
postgres=# create table reservations(during tsrange); postgres=# insert into reservations(during) values ('[2016-12-30, 2017-01-09)'), ('[2017-02-23, 2017-02-27)'), ('[2017-04-29, 2017-05-02)'); postgres=# create index on reservations using gist(during);
Indeks dapat digunakan untuk mempercepat kueri berikut, misalnya:
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during ----------------------------------------------- ["2016-12-30 00:00:00","2017-01-08 00:00:00") ["2017-02-23 00:00:00","2017-02-26 00:00:00") (2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN ------------------------------------------------------------------------------------ Index Only Scan using reservations_during_idx on reservations Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange) (2 rows)
&& operator untuk interval menunjukkan persimpangan; Oleh karena itu, kueri harus mengembalikan semua interval yang bersinggungan dengan yang diberikan. Untuk operator seperti itu, fungsi konsistensi menentukan apakah interval yang diberikan berpotongan dengan nilai dalam baris internal atau daun.
Perhatikan bahwa ini bukan tentang mendapatkan interval dalam urutan tertentu, meskipun operator perbandingan ditentukan untuk interval. Kita dapat menggunakan indeks "btree" untuk interval, tetapi dalam kasus ini, kita harus melakukannya tanpa dukungan operasi seperti ini:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'range_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------------+-------------+-------------- @>(anyrange,anyelement) | s | 16 contains element <<(anyrange,anyrange) | s | 1 strictly left &<(anyrange,anyrange) | s | 2 not beyond right boundary &&(anyrange,anyrange) | s | 3 intersects &>(anyrange,anyrange) | s | 4 not beyond left boundary >>(anyrange,anyrange) | s | 5 strictly right -|-(anyrange,anyrange) | s | 6 adjacent @>(anyrange,anyrange) | s | 7 contains interval <@(anyrange,anyrange) | s | 8 contained in interval =(anyrange,anyrange) | s | 18 equals (10 rows)
(Kecuali kesetaraan, yang terkandung dalam kelas operator untuk metode akses "btree".)
Internal
Kita bisa melihat ke dalam menggunakan ekstensi "gevel" yang sama. Kita hanya perlu ingat untuk mengubah tipe data dalam panggilan ke gist_print:
postgres=# select level, a from gist_print('reservations_during_idx') as t(level int, valid bool, a tsrange);
level | a -------+----------------------------------------------- 1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00") 1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00") 1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00") (3 rows)
Batasan pengecualian
Indeks GiST dapat digunakan untuk mendukung batasan eksklusi (TERKECUALI).
Batasan pengecualian memastikan bidang yang diberikan dari setiap dua baris tabel untuk tidak "berkorespondensi" satu sama lain dalam hal beberapa operator. Jika operator "equals" dipilih, kami mendapatkan batasan unik: bidang yang diberikan dari dua baris tidak sama satu sama lain.
Batasan pengecualian didukung oleh indeks, serta kendala unik. Kami dapat memilih operator mana saja sehingga:
- Ini didukung oleh metode indeks - properti "can_exclude" (misalnya, "btree", GiST, atau SP-GiST, tetapi tidak GIN).
- Itu komutatif, yaitu, kondisi terpenuhi: operator b = b operator a.
Ini adalah daftar strategi dan contoh operator yang sesuai (operator, seperti yang kita ingat, dapat memiliki nama yang berbeda dan tersedia tidak untuk semua tipe data):
- Untuk "btree":
- Untuk GiST dan SP-GiST:
- "Persimpangan"
&& - "Kebetulan"
~= - Adjacency
-|-
Perhatikan bahwa kita dapat menggunakan operator kesetaraan dalam batasan pengecualian, tetapi tidak praktis: kendala unik akan lebih efisien. Itulah mengapa kami tidak menyentuh batasan eksklusi ketika kami membahas B-tree.
Mari kita berikan contoh menggunakan batasan pengecualian. Adalah masuk akal untuk tidak mengizinkan reservasi untuk interval yang berpotongan.
postgres=# alter table reservations add exclude using gist(during with &&);
Setelah kami membuat batasan pengecualian, kami dapat menambahkan baris:
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
Tetapi upaya untuk memasukkan interval berpotongan ke dalam tabel akan menghasilkan kesalahan:
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl" DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
Ekstensi "Btree_gist"
Mari kita memperumit masalah. Kami mengembangkan bisnis kami yang sederhana, dan kami akan menyewakan beberapa pondok:
postgres=# alter table reservations add house_no integer default 1;
Kita perlu mengubah batasan pengecualian sehingga nomor rumah diperhitungkan. GiST, bagaimanapun, tidak mendukung operasi kesetaraan untuk bilangan bulat:
postgres=# alter table reservations drop constraint reservations_during_excl; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Dalam hal ini, ekstensi "
btree_gist " akan membantu, yang menambahkan dukungan GiST terhadap operasi yang melekat pada B-tree. GiST, pada akhirnya, dapat mendukung operator mana pun, jadi mengapa kita tidak mengajarkannya untuk mendukung operator "lebih besar", "kurang", dan "setara"?
postgres=# create extension btree_gist; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
Sekarang kami masih belum dapat memesan pondok pertama untuk tanggal yang sama:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
Namun, kami dapat memesan yang kedua:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
Namun ketahuilah bahwa meskipun GiST dapat mendukung operator "lebih besar", "kurang", dan "setara", B-tree masih melakukan ini dengan lebih baik. Jadi layak menggunakan teknik ini hanya jika indeks GiST pada dasarnya diperlukan, seperti dalam contoh kita.
RD-tree untuk pencarian teks lengkap
Tentang pencarian teks lengkap
Mari kita mulai dengan pengantar minimalis untuk pencarian teks lengkap PostgreSQL (jika Anda tahu, Anda dapat melewati bagian ini).
Tugas pencarian teks lengkap adalah memilih dari kumpulan dokumen dokumen yang
sesuai dengan permintaan pencarian. (Jika ada banyak dokumen yang cocok, penting untuk menemukan
yang cocok , tetapi kami tidak akan mengatakan apa-apa tentang hal ini pada saat ini.)
Untuk keperluan pencarian, dokumen dikonversi ke tipe khusus "tsvector", yang berisi
leksem dan posisinya dalam dokumen. Lexeme adalah kata-kata yang dikonversi ke bentuk yang cocok untuk pencarian. Misalnya, kata-kata biasanya dikonversi menjadi huruf kecil, dan ujung variabel terpotong:
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile');
to_tsvector ----------------------------------------- 'crook':4,10 'man':5 'mile':11 'walk':8 (1 row)
Kita juga dapat melihat bahwa beberapa kata (disebut
kata berhenti ) benar-benar dijatuhkan ("di sana", "adalah", "a", "dan", "dia") karena kata-kata itu agaknya sering terjadi sehingga pencarian kata-kata itu tidak masuk akal. Semua konversi ini tentu saja dapat dikonfigurasi, tapi itu cerita lain.
Permintaan pencarian diwakili dengan tipe lain: "tsquery". Secara kasar, kueri terdiri dari satu atau beberapa leksem yang dihubungkan oleh penghubung: "dan" &, "atau" |, "tidak"! .. Kita juga dapat menggunakan tanda kurung untuk memperjelas prioritas operasi.
postgres=# select to_tsquery('man & (walking | running)');
to_tsquery ---------------------------- 'man' & ( 'walk' | 'run' ) (1 row)
Hanya satu operator
@@ cocok digunakan untuk pencarian teks lengkap.
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (walking | running)');
?column? ---------- t (1 row)
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (going | running)');
?column? ---------- f (1 row)
Informasi ini cukup untuk saat ini. Kami akan terjun sedikit lebih dalam ke pencarian teks lengkap di artikel berikutnya yang menampilkan indeks GIN.
RD-pohon
Untuk pencarian teks lengkap cepat, pertama, tabel perlu menyimpan kolom tipe "tsvector" (untuk menghindari melakukan konversi yang mahal setiap kali mencari) dan kedua, indeks harus dibangun pada kolom ini. Salah satu metode akses yang mungkin untuk ini adalah GiST.
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# create index on ts using gist(doc_tsv); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc);
Tentu saja nyaman untuk mempercayakan pemicu dengan langkah terakhir (konversi dokumen ke "tsvector").
postgres=# select * from ts;
-[ RECORD 1 ]---------------------------------------------------- doc | Can a sheet slitter slit sheets? doc_tsv | 'sheet':3,6 'slit':5 'slitter':4 -[ RECORD 2 ]---------------------------------------------------- doc | How many sheets could a sheet slitter slit? doc_tsv | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 -[ RECORD 3 ]---------------------------------------------------- doc | I slit a sheet, a sheet I slit. doc_tsv | 'sheet':4,6 'slit':2,8 -[ RECORD 4 ]---------------------------------------------------- doc | Upon a slitted sheet I sit. doc_tsv | 'sheet':4 'sit':6 'slit':3 'upon':1 -[ RECORD 5 ]---------------------------------------------------- doc | Whoever slit the sheets is a good sheet slitter. doc_tsv | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 -[ RECORD 6 ]---------------------------------------------------- doc | I am a sheet slitter. doc_tsv | 'sheet':4 'slitter':5 -[ RECORD 7 ]---------------------------------------------------- doc | I slit sheets. doc_tsv | 'sheet':3 'slit':2 -[ RECORD 8 ]---------------------------------------------------- doc | I am the sleekest sheet slitter that ever slit sheets. doc_tsv | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 -[ RECORD 9 ]---------------------------------------------------- doc | She slits the sheet she sits on. doc_tsv | 'sheet':4 'sit':6 'slit':2
Bagaimana seharusnya indeks disusun? Penggunaan R-tree secara langsung bukan merupakan pilihan karena tidak jelas cara mendefinisikan "recting rectangle" untuk dokumen. Tapi kita bisa menerapkan beberapa modifikasi dari pendekatan ini untuk set, yang disebut RD-tree (RD singkatan dari "Russian Doll"). Suatu himpunan dipahami sebagai himpunan leksem dalam kasus ini, tetapi secara umum, himpunan dapat berupa apa saja.
Gagasan RD-tree adalah untuk mengganti persegi panjang pembatas dengan set pembatas, yaitu, set yang berisi semua elemen set anak.
Sebuah pertanyaan penting muncul bagaimana merepresentasikan set dalam baris indeks. Cara yang paling mudah adalah menghitung semua elemen himpunan. Ini mungkin terlihat sebagai berikut:

Kemudian misalnya, untuk akses dengan syarat
doc_tsv @@ to_tsquery('sit') kita hanya bisa turun ke simpul-simpul yang mengandung lexeme "duduk":
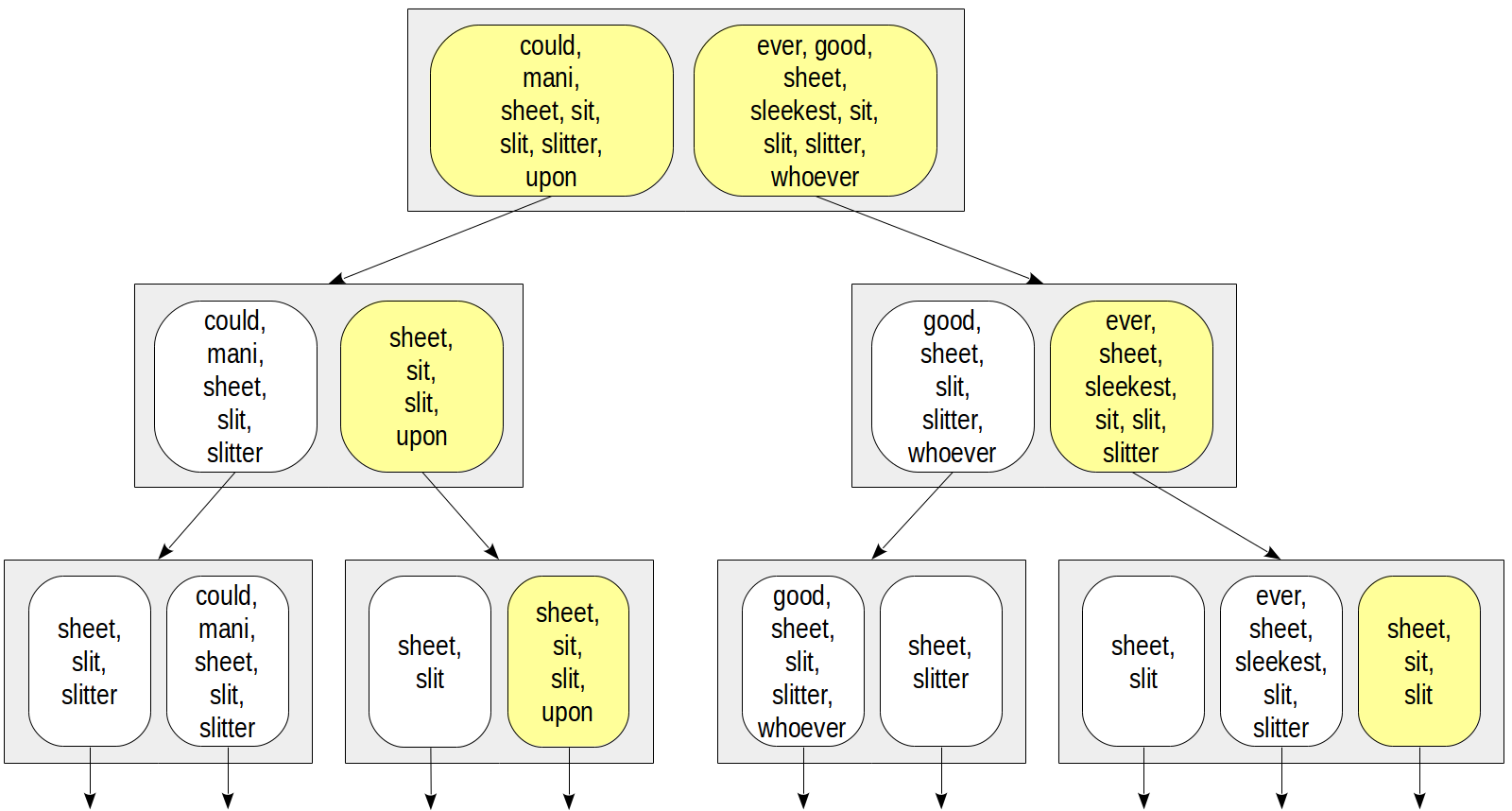
Representasi ini memiliki masalah yang jelas. Jumlah leksem dalam sebuah dokumen bisa sangat besar, sehingga baris indeks akan memiliki ukuran besar dan masuk ke TOAST, membuat indeks jauh lebih efisien. Bahkan jika setiap dokumen memiliki beberapa leksem unik, gabungan set mungkin masih sangat besar: semakin tinggi ke root baris indeks yang lebih besar.
Representasi seperti ini kadang-kadang digunakan, tetapi untuk tipe data lainnya. Dan pencarian teks lengkap menggunakan solusi lain yang lebih ringkas - yang disebut
pohon tanda tangan . Idenya cukup akrab bagi semua yang berurusan dengan filter Bloom.
Setiap leksem dapat diwakili dengan
tanda tangannya : string bit dengan panjang tertentu di mana semua bit kecuali satu adalah nol. Posisi bit ini ditentukan oleh nilai fungsi hash dari lexeme (kami membahas internal fungsi hash
sebelumnya ).
Tanda tangan dokumen adalah bitwise ATAU dari tanda tangan semua leksem dokumen.
Mari kita asumsikan tanda tangan leksem berikut:
bisa 1.000.000
pernah 0001000
bagus 0000010
mani 0000100
sheet 0000100
sleekest 0100000
duduk 0010000
celah 0001000
slitter 0000001
pada 0000010
siapapun 0010000
Maka tanda tangan dokumen adalah seperti ini:
Bisakah lembaran slitter slit sheet? 0001101
Berapa banyak lembaran yang bisa memotong lembaran slitter? 1001101
Saya memotong lembaran, lembaran saya memotong. 0001100
Di atas selembar slitted saya duduk. 0011110
Siapa pun yang menggorok lembaran itu adalah pemotong lembaran yang bagus. 0011111
Saya seorang slitter sheet. 0000101
Saya memotong lembaran. 0001100
Saya slitter sheet paling licin yang pernah memotong lembaran. 0101101
Dia memotong lembaran yang dia duduki. 0011100
Pohon indeks dapat direpresentasikan sebagai berikut:
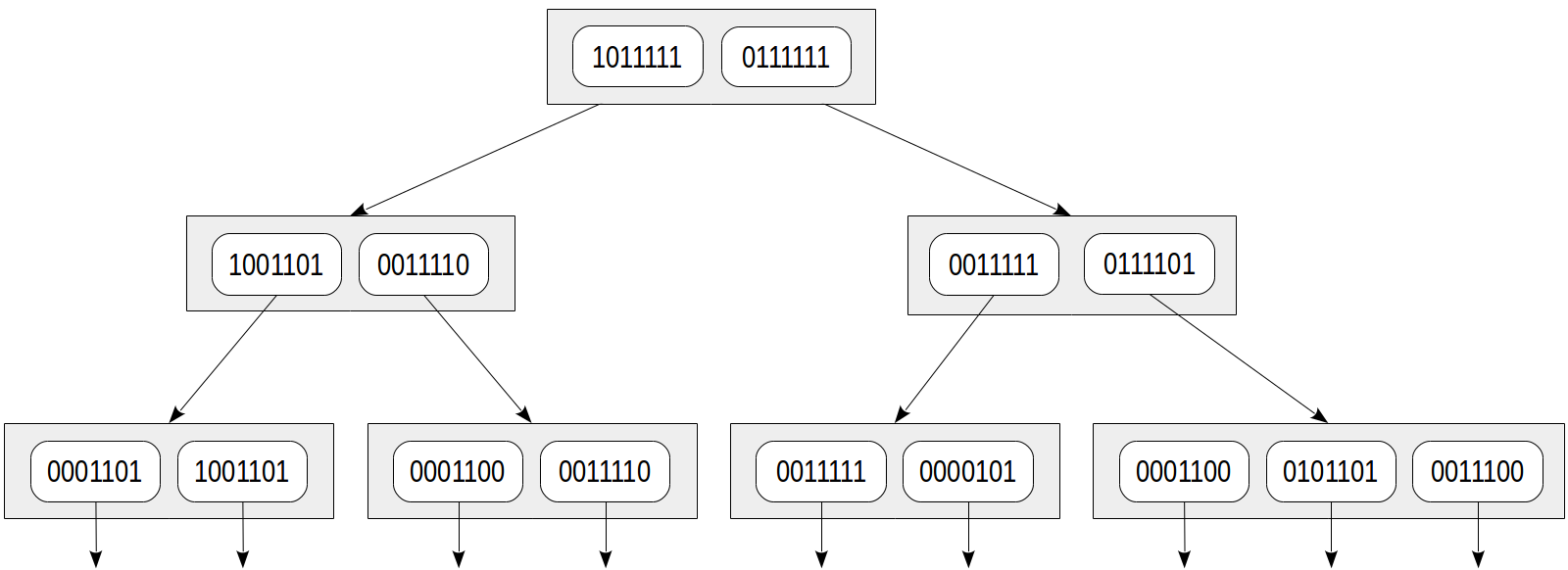
Keuntungan dari pendekatan ini jelas: baris indeks memiliki ukuran kecil yang sama, dan indeks tersebut kompak. Namun kelemahannya juga jelas: akurasi dikorbankan untuk kekompakan.
Mari pertimbangkan kondisi yang sama
doc_tsv @@ to_tsquery('sit') . Dan mari kita menghitung tanda tangan dari permintaan pencarian dengan cara yang sama seperti untuk dokumen: 0010000 dalam hal ini. Fungsi konsistensi harus mengembalikan semua simpul turunan yang tanda tangannya mengandung setidaknya satu bit dari tanda tangan kueri:

Bandingkan dengan gambar di atas: kita dapat melihat bahwa pohon menjadi kuning, yang berarti bahwa false positive terjadi dan node berlebihan dilalui selama pencarian. Di sini kami mengambil leksem "siapa pun", yang tanda tangannya sayangnya sama dengan tanda tangan leksem "duduk". Sangat penting bahwa tidak ada negatif palsu dapat terjadi dalam pola, yaitu, kami yakin tidak akan melewatkan nilai yang dibutuhkan.
Selain itu, bisa jadi terjadi bahwa dokumen yang berbeda juga akan mendapatkan tanda tangan yang sama: dalam contoh kita, dokumen yang tidak beruntung adalah "Saya memotong lembaran, lembaran saya memotong" dan "Saya memotong lembaran" (keduanya memiliki tanda tangan 0001100). Dan jika baris indeks daun tidak menyimpan nilai "tsvector", indeks itu sendiri akan memberikan false positive. Tentu saja, dalam hal ini, metode akan meminta mesin pengindeksan untuk memeriksa kembali hasil dengan tabel, sehingga pengguna tidak akan melihat positif palsu ini. Tetapi efisiensi pencarian dapat terganggu.
Sebenarnya, tanda tangan berukuran 124 byte dalam implementasi saat ini, bukan 7-bit dalam gambar, sehingga masalah di atas jauh lebih kecil kemungkinannya terjadi daripada dalam contoh. Namun dalam kenyataannya, lebih banyak dokumen yang diindeks juga. Untuk mengurangi jumlah kesalahan positif dari metode indeks, penerapannya menjadi sedikit rumit: "tsvector" yang diindeks disimpan dalam baris indeks daun, tetapi hanya jika ukurannya tidak besar (sedikit kurang dari 1/16 dari halaman, yaitu sekitar setengah kilobyte untuk halaman 8-KB).
Contoh
Untuk melihat bagaimana pengindeksan bekerja pada data aktual, mari kita ambil arsip email "pgsql-hacker".
Versi yang digunakan dalam contoh berisi 356125 pesan dengan tanggal kirim, subjek, penulis, dan teks:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------ id | 1572389 parent_id | 1562808 sent | 1997-06-24 11:31:09 subject | Re: [HACKERS] Array bug is still there.... author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov> body_plain | Andrew Martin wrote: + | > Just run the regression tests on 6.1 and as I suspected the array bug + | > is still there. The regression test passes because the expected output+ | > has been fixed to the *wrong* output. + | + | OK, I think I understand the current array behavior, which is apparently+ | different than the behavior for v1.0x. + ...
Menambahkan dan mengisi kolom tipe "tsvector" dan membangun indeks. Di sini kita akan menggabungkan tiga nilai dalam satu vektor (subjek, penulis, dan teks pesan) untuk menunjukkan bahwa dokumen tidak perlu menjadi satu bidang, tetapi dapat terdiri dari bagian-bagian acak yang sama sekali berbeda.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
Seperti yang bisa kita lihat, sejumlah kata dijatuhkan karena ukurannya yang terlalu besar. Tetapi indeks akhirnya dibuat dan dapat mendukung permintaan pencarian:
fts=# explain (analyze, costs off) select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN ---------------------------------------------------------- Index Scan using mail_messages_tsv_idx on mail_messages (actual time=0.998..416.335 rows=898 loops=1) Index Cond: (tsv @@ to_tsquery('magic & value'::text)) Rows Removed by Index Recheck: 7859 Planning time: 0.203 ms Execution time: 416.492 ms (5 rows)
Kita dapat melihat bahwa bersama dengan 898 baris yang cocok dengan kondisi tersebut, metode akses mengembalikan 7859 lebih banyak baris yang difilter dengan mengecek ulang dengan tabel. Ini menunjukkan dampak negatif dari hilangnya akurasi pada efisiensi.
Internal
Untuk menganalisis konten indeks, kami akan kembali menggunakan ekstensi "gevel":
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a -------+------------------------------- 1 | 992 true bits, 0 false bits 2 | 988 true bits, 4 false bits 3 | 573 true bits, 419 false bits 4 | 65 unique words 4 | 107 unique words 4 | 64 unique words 4 | 42 unique words ...
Nilai dari tipe khusus "gtsvector" yang disimpan dalam baris indeks sebenarnya adalah tanda tangan plus, mungkin, sumber "tsvector". Jika vektor tersedia, output berisi jumlah leksem (kata-kata unik), jika tidak, jumlah bit benar dan salah dalam tanda tangan.
Jelas bahwa dalam simpul akar, tanda tangan berubah menjadi "semua yang", yaitu, satu tingkat indeks menjadi sama sekali tidak berguna (dan satu lagi menjadi hampir tidak berguna, dengan hanya empat bit salah).
Properti
Mari kita lihat sifat-sifat metode akses GiST (pertanyaan
disediakan sebelumnya ):
amname | name | pg_indexam_has_property --------+---------------+------------------------- gist | can_order | f gist | can_unique | f gist | can_multi_col | t gist | can_exclude | t
Penyortiran nilai dan batasan unik tidak didukung. Seperti yang telah kita lihat, indeks dapat dibangun di beberapa kolom dan digunakan dalam batasan pengecualian.
Properti lapisan indeks berikut tersedia:
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | f
Dan sifat yang paling menarik adalah dari lapisan kolom. Beberapa properti tidak tergantung pada kelas operator:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f search_array | f search_nulls | t
(Penyortiran tidak didukung; indeks tidak dapat digunakan untuk mencari array; NULL didukung.)
Tetapi dua properti yang tersisa, "distance_orderable" dan "returnable", akan tergantung pada kelas operator yang digunakan. Misalnya, untuk poin kita akan mendapatkan:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | t returnable | t
Properti pertama memberi tahu bahwa operator jarak tersedia untuk mencari tetangga terdekat. Dan yang kedua memberi tahu bahwa indeks dapat digunakan untuk memindai hanya indeks. Meskipun baris indeks daun menyimpan persegi panjang daripada titik, metode akses dapat mengembalikan apa yang dibutuhkan.
Berikut ini adalah properti untuk interval:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | t
Untuk interval, fungsi jarak tidak ditentukan dan oleh karena itu, pencarian tetangga terdekat tidak dimungkinkan.
Dan untuk pencarian teks lengkap, kami mendapatkan:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | f
Dukungan pemindaian hanya indeks telah hilang sejak baris daun hanya dapat berisi tanda tangan tanpa data itu sendiri. Namun, ini adalah kerugian kecil karena tidak ada yang tertarik pada nilai tipe "tsvector": nilai ini digunakan untuk memilih baris, sementara itu adalah teks sumber yang perlu ditampilkan, tetapi tetap tidak ada dalam indeks.
Tipe data lainnya
Terakhir, kami akan menyebutkan beberapa jenis lagi yang saat ini didukung oleh metode akses GiST selain jenis geometris yang telah dibahas (dengan contoh poin), interval, dan jenis pencarian teks lengkap.
Dari tipe standar, ini adalah tipe "
inet " untuk alamat IP. Semua ditambahkan melalui ekstensi:
- kubus menyediakan tipe data "kubus" untuk kubus multi-dimensi. Untuk tipe ini, seperti halnya tipe geometris dalam pesawat, kelas operator GiST didefinisikan: R-tree, mendukung pencarian tetangga terdekat.
- seg menyediakan tipe data "seg" untuk interval dengan batas yang ditentukan untuk akurasi tertentu dan menambahkan dukungan indeks GiST untuk tipe data ini (R-tree).
- intarray memperluas fungsi array integer dan menambahkan dukungan GiST untuk mereka. Dua kelas operator diimplementasikan: "gist__int_ops" (RD-tree dengan representasi penuh kunci dalam baris indeks) dan "gist__bigint_ops" (signature RD-tree). Kelas pertama dapat digunakan untuk array kecil, dan yang kedua - untuk ukuran yang lebih besar.
- ltree menambahkan tipe data "ltree" untuk struktur seperti pohon dan dukungan GiST untuk tipe data ini (RD-tree).
- pg_trgm menambahkan kelas operator khusus "gist_trgm_ops" untuk penggunaan trigram dalam pencarian teks lengkap. Tapi ini akan dibahas lebih lanjut, bersama dengan indeks GIN.
Baca terus .