 ProxylessNAS secara langsung mengoptimalkan arsitektur jaringan saraf untuk tugas dan peralatan tertentu, yang secara signifikan dapat meningkatkan produktivitas dibandingkan dengan pendekatan proxy sebelumnya. Pada dataset ImageNet, jaringan saraf dirancang dalam 200 jam GPU (200–378 kali lebih cepat daripada rekan-rekannya), dan model CNN yang dirancang secara otomatis untuk perangkat seluler mencapai tingkat akurasi yang sama dengan MobileNetV2 1.4, bekerja 1,8 kali lebih cepat.
ProxylessNAS secara langsung mengoptimalkan arsitektur jaringan saraf untuk tugas dan peralatan tertentu, yang secara signifikan dapat meningkatkan produktivitas dibandingkan dengan pendekatan proxy sebelumnya. Pada dataset ImageNet, jaringan saraf dirancang dalam 200 jam GPU (200–378 kali lebih cepat daripada rekan-rekannya), dan model CNN yang dirancang secara otomatis untuk perangkat seluler mencapai tingkat akurasi yang sama dengan MobileNetV2 1.4, bekerja 1,8 kali lebih cepat.Para peneliti di Massachusetts Institute of Technology telah mengembangkan algoritma yang efektif untuk secara otomatis merancang jaringan saraf berkinerja tinggi untuk perangkat keras tertentu,
tulis publikasi
MIT News .
Algoritma untuk desain otomatis sistem pembelajaran mesin adalah bidang penelitian baru di bidang AI. Teknik ini disebut neural architecture search (NAS) dan dianggap sebagai tugas komputasi yang sulit.
Jaringan saraf yang dirancang secara otomatis memiliki desain yang lebih akurat dan efisien daripada yang dikembangkan oleh manusia. Tetapi pencarian arsitektur saraf membutuhkan perhitungan yang sangat besar. Sebagai contoh, algoritma NASNet-F modern, yang baru-baru ini dikembangkan oleh Google untuk berjalan pada GPU, membutuhkan 48.000 jam komputasi GPU untuk membuat satu jaringan saraf convolutional, yang digunakan untuk mengklasifikasikan dan mendeteksi gambar. Tentu saja, Google dapat menjalankan ratusan GPU dan perangkat keras khusus lainnya secara paralel. Misalnya, pada seribu GPU perhitungan ini hanya akan memakan waktu dua hari. Tetapi tidak semua peneliti memiliki peluang seperti itu, dan jika Anda menjalankan algoritme di cloud komputasi Google, maka itu dapat terbang dengan sangat mahal.
Peneliti MIT telah menyiapkan sebuah artikel untuk Konferensi Internasional tentang Representasi Pembelajaran,
ICLR 2019 , yang akan diselenggarakan dari 6 hingga 9 Mei 2019. Artikel
ProxylessNAS: Pencarian Neural Architecture Langsung pada Target Task and Hardware menjelaskan algoritma ProxylessNAS yang secara langsung dapat mengembangkan jaringan saraf convolutional khusus untuk platform perangkat keras tertentu.
Saat dijalankan pada kumpulan data gambar yang sangat besar, algoritma ini merancang arsitektur optimal hanya dalam 200 jam operasi GPU. Ini adalah dua urutan besarnya lebih cepat daripada pengembangan arsitektur CNN menggunakan algoritma lain (lihat tabel).
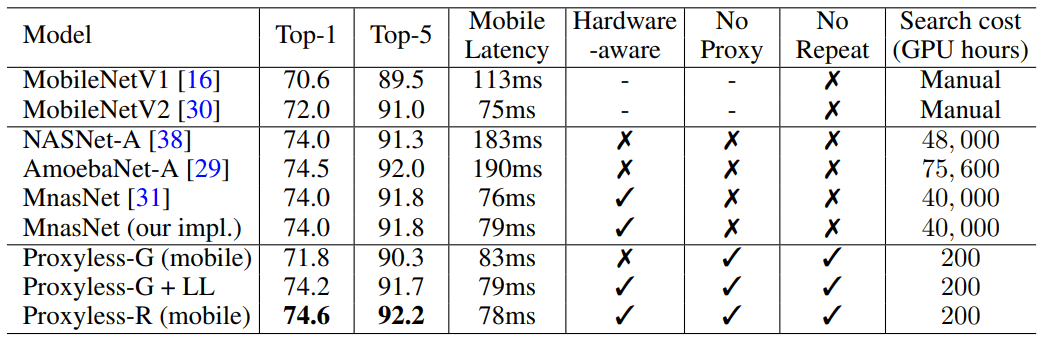
Para peneliti dan perusahaan dengan sumber daya terbatas akan mendapat manfaat dari algoritma. Tujuan yang lebih umum adalah untuk "mendemokratisasikan AI," kata rekan penulis sains Song Han, seorang profesor teknik elektro dan ilmu komputer di Laboratorium Teknologi Sistem Mikro MIT.
Khan menambahkan bahwa algoritma NAS semacam itu tidak akan pernah menggantikan pekerjaan intelektual para insinyur: "Tujuannya adalah untuk menurunkan pekerjaan yang berulang dan membosankan yang datang dengan merancang dan meningkatkan arsitektur jaringan saraf."
Dalam pekerjaan mereka, para peneliti menemukan cara untuk menghapus komponen yang tidak perlu dari jaringan saraf, mengurangi waktu komputasi, dan hanya menggunakan sebagian dari memori perangkat keras untuk menjalankan algoritma NAS. Ini memastikan bahwa CNN yang dikembangkan bekerja lebih efisien pada platform perangkat keras tertentu: CPU, GPU dan perangkat seluler.
Arsitektur CNN terdiri dari lapisan dengan parameter yang dapat disesuaikan yang disebut "filter" dan kemungkinan hubungan di antara mereka. Filter memproses piksel gambar dalam kotak persegi - seperti 3 × 3, 5 × 5 atau 7 × 7 - di mana setiap filter mencakup satu kotak. Bahkan, filter bergerak di sekitar gambar dan menggabungkan warna kotak piksel menjadi satu piksel. Dalam lapisan yang berbeda, filter memiliki ukuran yang berbeda, yang terhubung dengan berbagai cara untuk bertukar data. Output CNN menghasilkan gambar terkompresi yang dikombinasikan dari semua filter. Karena jumlah arsitektur yang mungkin - yang disebut "ruang pencarian" - sangat besar, penggunaan NAS untuk membuat jaringan saraf pada set besar data gambar membutuhkan sumber daya yang sangat besar. Biasanya, pengembang menjalankan NAS pada set data yang lebih kecil (proksi) dan mentransfer arsitektur CNN yang dihasilkan ke target. Namun, metode ini mengurangi keakuratan model. Selain itu, arsitektur yang sama berlaku untuk semua platform perangkat keras, menghasilkan masalah kinerja.
Peneliti MIT melatih dan menguji algoritma baru pada tugas mengklasifikasikan gambar secara langsung dalam dataset ImageNet, yang berisi jutaan gambar dalam seribu kelas. Pertama, mereka menciptakan ruang pencarian yang berisi semua "jalur" yang mungkin untuk kandidat CNN sehingga algoritma menemukan arsitektur optimal di antara mereka. Untuk menyesuaikan ruang pencarian ke dalam memori GPU, mereka menggunakan metode yang disebut binarisasi tingkat-jalan, yang hanya menyimpan satu jalur pada satu waktu dan menyimpan memori dengan urutan besarnya. Binarisasi dikombinasikan dengan pemangkasan tingkat-jalan, suatu metode yang secara tradisional mempelajari neuron-neuron mana dalam jaringan saraf yang dapat dihilangkan dengan aman tanpa merusak sistem. Hanya alih-alih menghapus neuron, algoritma NAS menghapus seluruh jalur, sepenuhnya mengubah arsitektur.
Pada akhirnya, algoritma memotong semua jalur yang tidak mungkin dan hanya menyimpan jalur dengan probabilitas tertinggi - ini adalah arsitektur CNN tertinggi.
Ilustrasi menunjukkan sampel jaringan saraf untuk mengklasifikasikan gambar yang dikembangkan ProxylessNAS untuk GPU, CPU, dan prosesor seluler (masing-masing dari atas ke bawah).
