
Peningkatan kecepatan CPU melambat, dan kami melihat industri semikonduktor beralih ke kartu akselerator sehingga hasilnya terus meningkat secara nyata. Nvidia mendapat manfaat paling besar dari transisi ini, namun, itu adalah bagian dari tren yang sama, memicu penelitian akselerator jaringan saraf, FPGA, dan produk-produk seperti Google's TPUs. Akselerator ini telah sangat meningkatkan kecepatan elektronik dalam beberapa tahun terakhir, dan banyak yang mulai berharap bahwa mereka mewakili jalur baru pengembangan, sehubungan dengan perlambatan hukum Moore. Tetapi sebuah karya ilmiah baru menunjukkan bahwa pada kenyataannya, semuanya tidak semerah beberapa orang inginkan.
Arsitektur khusus seperti GPU, TPU, FPGA, dan ASIC, bahkan jika mereka bekerja sangat berbeda dari CPU untuk keperluan umum, masih menggunakan node fungsional yang sama seperti x86, ARM, atau prosesor POWER. Dan ini berarti bahwa peningkatan kecepatan akselerator ini juga sampai batas tertentu tergantung pada peningkatan yang terkait dengan penskalaan transistor. Tetapi berapa proporsi dari perbaikan ini tergantung pada peningkatan teknologi produksi dan peningkatan kepadatan yang terkait dengan hukum Moore, dan bagian mana pada perbaikan di area target yang menjadi tujuan prosesor ini? Berapa persentase peningkatan yang hanya terkait dengan transistor?
Associate Professor Princeton University dari Teknik Elektro David Wenzlaf dan mahasiswa pascasarjananya Adi Fuchs telah menciptakan model yang memungkinkan mereka untuk mengukur kecepatan peningkatan. Model mereka menggunakan karakteristik 1612 CPU dan 1001 GPU dari berbagai kapasitas, dibuat berdasarkan berbagai unit fungsional, untuk mengevaluasi secara numerik manfaat yang terkait dengan peningkatan unit. Wenzlaf dan Fuchs telah menciptakan
metrik untuk meningkatkan kinerja terkait dengan kemajuan CMOS (CMOS-Driven return, CDR), yang dapat dibandingkan dengan peningkatan yang diperoleh melalui pengembalian spesialisasi chip (CSR).
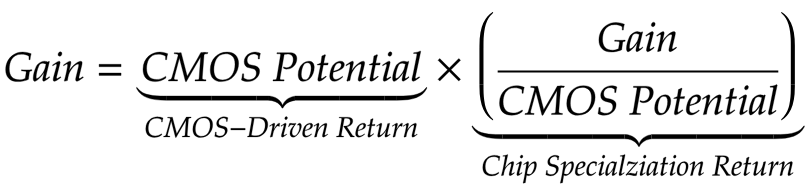
Tim sampai pada kesimpulan yang mengecewakan. Keuntungan yang diperoleh karena spesialisasi chip pada dasarnya terkait dengan jumlah transistor yang ditempatkan dalam milimeter silikon dalam jangka panjang, serta peningkatan transistor yang terkait dengan setiap unit fungsional baru. Lebih buruk lagi, ada batasan mendasar pada seberapa banyak kecepatan yang dapat kita ekstrak dari meningkatkan sirkuit akselerator tanpa meningkatkan skala CMOS.
Penting bahwa semua hal di atas berlaku dalam jangka panjang. Sebuah studi oleh Wenzlaf dan Fuchs menunjukkan bahwa kecepatan sering meningkat secara dramatis ketika akselerator pertama kali ditugaskan. Seiring waktu, ketika metode akselerasi optimal ternyata dipelajari, dan praktik terbaik dijelaskan, para peneliti sampai pada pendekatan yang paling optimal. Selain itu, pada akselerator, tugas yang ditentukan dengan baik dari area yang dipelajari dengan baik yang dapat diparalelkan (GPU) diselesaikan dengan baik. Namun, ini juga berarti bahwa sifat yang sama, karena tugas yang dapat diadaptasi untuk akselerator, membatasi keuntungan yang diperoleh dari akselerasi ini dalam jangka panjang. Tim menyebut masalah ini "akselerator jalan buntu."
Dan pasar komputasi berkinerja tinggi mungkin telah merasakan ini selama beberapa waktu. Pada 2013, kami menulis tentang
jalan yang sulit menuju bekas superkomputer. Dan bahkan kemudian, Top500 memperkirakan bahwa akselerator akan memberikan lompatan satu kali dalam peringkat kinerja, tetapi tidak akan meningkatkan kecepatan peningkatan kecepatan.

Namun, konsekuensi dari penemuan ini melampaui pasar komputasi kinerja tinggi. Sebagai contoh, setelah mempelajari GPU, Wenzlaf dan Fuchs menemukan bahwa manfaat yang tidak dapat dikaitkan dengan peningkatan CMOS sangat kecil.
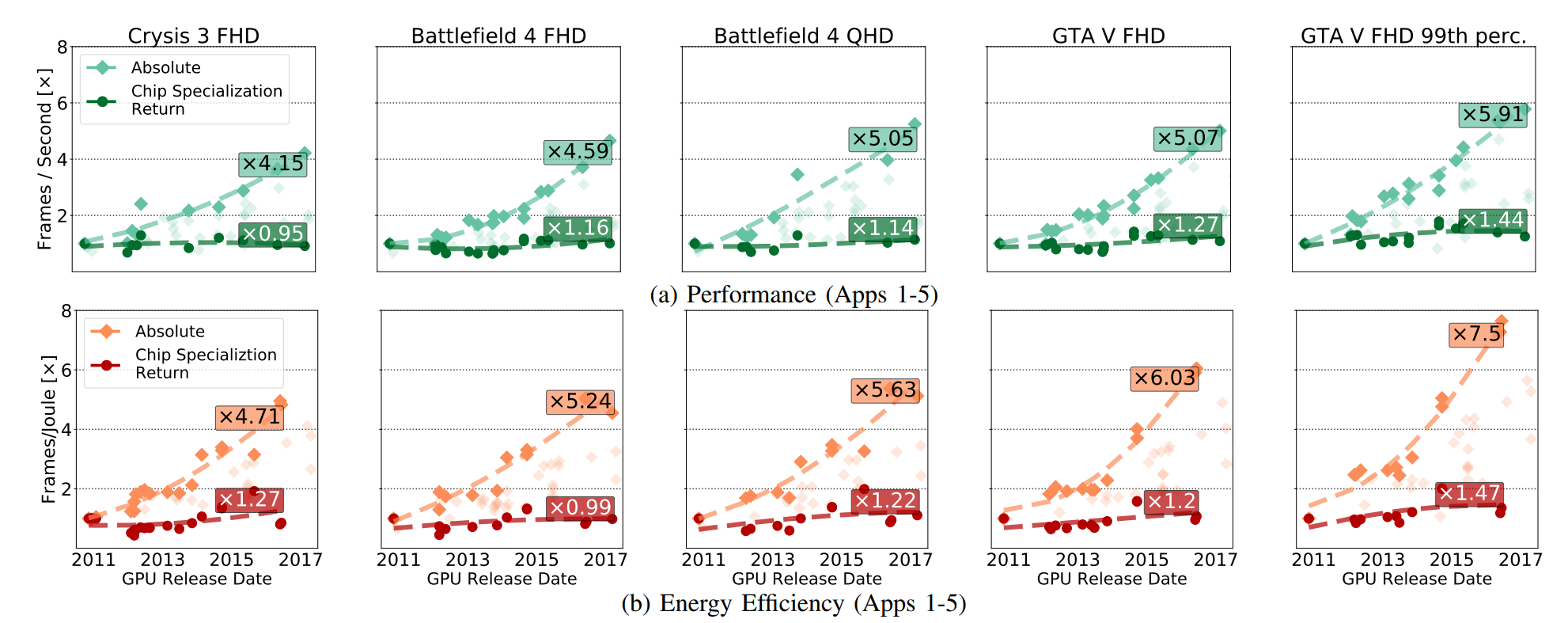
Dalam gbr. Pertumbuhan kinerja absolut GPU telah ditunjukkan (termasuk manfaat yang diperoleh dari pengembangan CMOS), dan manfaat ini hanya muncul dari pengembangan CSR. CSR adalah tentang perbaikan yang tetap ada jika Anda menghapus semua terobosan dalam teknologi CMOS dari sirkuit GPU.
Gambar berikut menjelaskan hubungan jumlah:
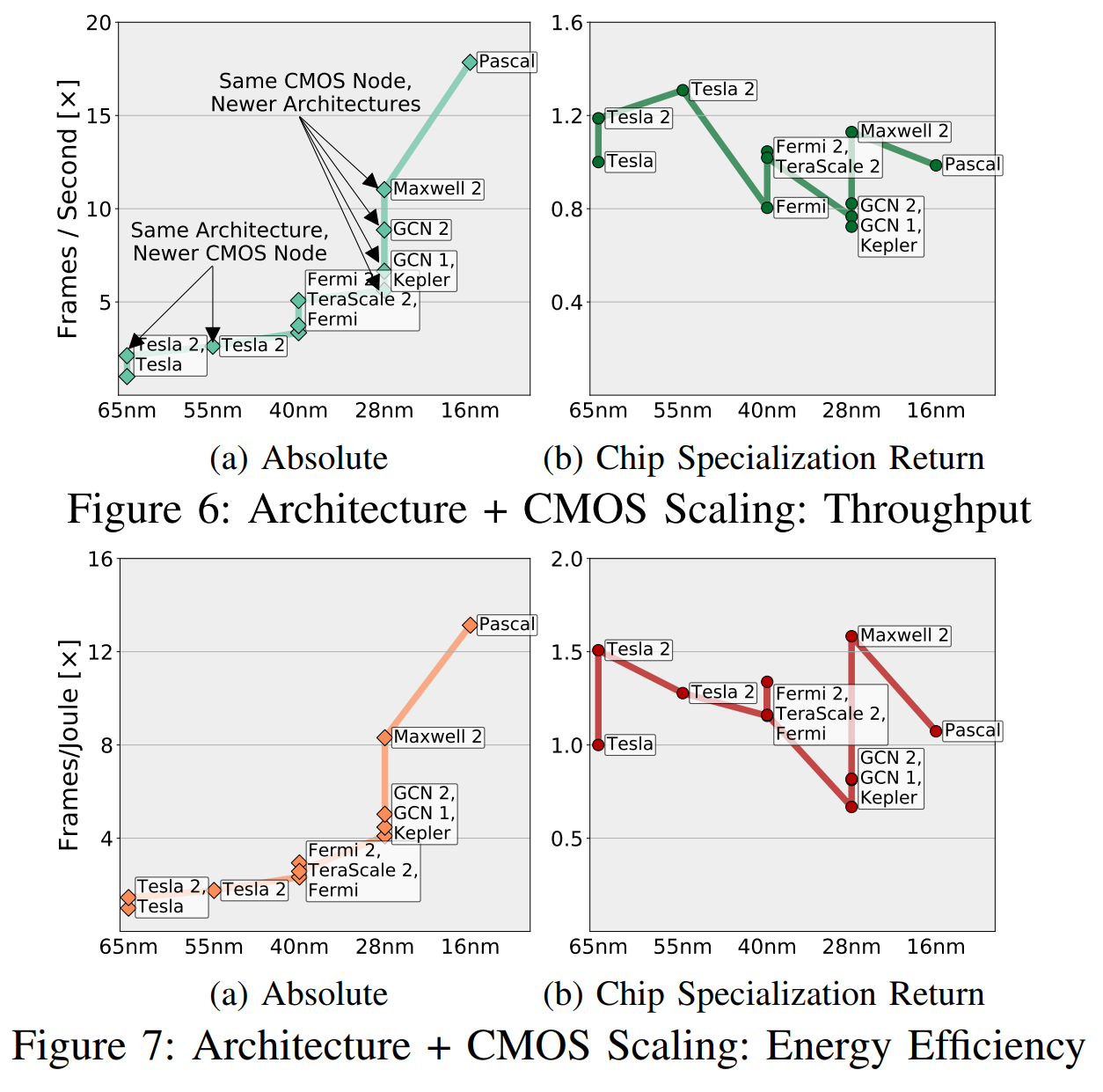
Mengurangi CSR tidak berarti memperlambat GPU dalam angka absolut. Seperti yang ditulis Fuchs:
CSR menormalkan keuntungan "berdasarkan potensi CMOS", dan "potensi" ini memperhitungkan jumlah transistor dan perbedaan kecepatan, efisiensi dalam penggunaan energi, area, dll. (dalam berbagai generasi CMOS). Dalam gbr. 6, kami memberikan perbandingan perkiraan kombinasi "arsitektur + CMOS node", dengan melakukan triangulasi kecepatan terukur dari semua aplikasi pada kombinasi yang berbeda, dan menerapkan hubungan transitif antara kombinasi yang tidak memiliki cukup aplikasi umum (kurang dari lima).
Secara intuitif, grafik ini dapat dipahami seperti pada Gambar. 6a menunjukkan apa yang "dilihat oleh insinyur dan manajer," dan gambar. 6b adalah "apa yang kita lihat, tidak termasuk potensi CMOS." Saya berani menyarankan agar Anda lebih peduli dengan apakah chip baru Anda ada di depan yang sebelumnya daripada jika itu karena transistor yang lebih baik atau karena spesialisasi yang lebih baik.
Pasar GPU terdefinisi dengan baik, dirancang dan terspesialisasi, dan baik AMD maupun Nvidia punya alasan untuk saling unggul, meningkatkan sirkuit. Namun, meskipun demikian, kita melihat bahwa sebagian besar, akselerasi disebabkan oleh faktor-faktor yang terkait dengan CMOS, dan bukan karena CSR.
FPGA dan papan khusus untuk memproses video codec, dipelajari oleh para ilmuwan, juga termasuk dalam karakteristik tersebut, bahkan jika peningkatan relatif dari waktu ke waktu menjadi lebih atau kurang karena pasar yang berkembang. Karakteristik yang sama yang memungkinkan Anda merespons akselerasi secara aktif, pada akhirnya membatasi kemampuan akselerator untuk meningkatkan efisiensinya. Fuchs dan Wenzlaf menulis tentang GPU: "Meskipun frame rate grafis GPU telah meningkat 16 kali, kami menganggap bahwa peningkatan lebih lanjut dalam kecepatan dan efisiensi energi akan mengikuti 1,4-2,4 kali dan 1,4-1,7 kali, masing-masing" . AMD dan Nvidia tidak memiliki ruang khusus untuk bermanuver di mana Anda dapat meningkatkan kecepatan dengan meningkatkan CMOS.
Implikasi dari pekerjaan ini penting. Dia mengatakan bahwa khusus untuk bidang arsitektur mereka tidak akan lagi memberikan peningkatan kecepatan yang signifikan ketika hukum Moore berhenti bekerja. Dan bahkan jika desainer chip dapat berkonsentrasi pada peningkatan kinerja dalam jumlah tetap transistor, peningkatan ini akan dibatasi oleh fakta bahwa proses yang dipelajari dengan baik hampir tidak memiliki tempat untuk meningkatkan.
Pekerjaan menunjukkan perlunya mengembangkan pendekatan baru yang fundamental untuk komputasi. Salah satu alternatif potensial adalah
arsitektur Intel Meso . Fuchs dan Wenzlaf juga
menyarankan penggunaan bahan alternatif dan solusi lain yang melampaui ruang lingkup CMOS, termasuk penelitian kemungkinan menggunakan memori non-volatile sebagai akselerator.