Yandex memiliki layanan pengembangan komponen pencarian yang membangun basis pencarian di MapReduce, menyediakan data untuk pengaturan huruf untuk rendering, menghasilkan algoritma dan struktur data, dan menyelesaikan tugas pertumbuhan pertumbuhan ML. Alexey Shlyunkin, kepala salah satu grup dalam layanan ini, menjelaskan tentang apa yang terdiri dari runtime pencarian dan bagaimana kami mengelolanya.
Ingin menyodok di ML - menyodok. Anda hanya menginginkan MapReduce - ok. Ingin runtime - runtime.
- Apa pencarian hari ini? Yandex mulai dengan melakukan pencarian, mengembangkannya. 20 tahun telah berlalu. Kami memiliki basis pencarian untuk ratusan miliar dokumen.
Kami menyebut dokumen halaman apa pun di Internet, tetapi, pada kenyataannya, tidak hanya itu. Masih - isinya, berbagai statistik tentang pengguna yang suka ke sana, berapa banyak dari mereka. Ditambah data yang kami hitung.
Mereka juga puluhan ribu contoh yang, dalam menanggapi setiap permintaan, memproses data, mencari sesuatu, memperkaya respons pencarian. Beberapa contoh sedang mencari gambar, beberapa untuk dokumen teks biasa, beberapa untuk video, dll. Artinya, puluhan ribu mesin diaktifkan untuk setiap permintaan Anda. Mereka semua mencoba menemukan sesuatu dan meningkatkan hasil yang ditunjukkan kepada Anda. Dengan demikian, puluhan ribu mesin melayani ribuan permintaan per detik. Ini puluhan ribu contoh digabungkan menjadi ratusan layanan yang dirancang untuk memecahkan masalah.

Ada inti pencarian - layanan pencarian web. Dan ada layanan pencarian video, dll. Oleh karena itu, ada hal yang menggabungkan jawaban dari pencarian yang berbeda dan mencoba untuk memilih apa dan dalam urutan mana lebih baik untuk menunjukkan kepada pengguna. Jika ini adalah semacam permintaan tentang musik, maka mungkin lebih baik untuk menampilkan Yandex.Music terlebih dahulu, dan kemudian, misalnya, sebuah halaman tentang grup musik ini. Ini disebut blender. Sudah ada ratusan layanan seperti itu, dan mereka juga melakukan sesuatu untuk setiap permintaan dan mencoba membantu pengguna dengan cara apa pun. Dan, tentu saja, ini semua menggunakan pembelajaran mesin dari segala jenis, dari beberapa statistik sederhana, model linier, hingga peningkatan gradien, jaringan saraf dan sebagainya.
Saya akan berbicara tentang infrastruktur dan ML sekarang.
Grup saya disebut grup pengembangan runtime baru, itu adalah bagian dari layanan pengembangan komponen pencarian. Agar Anda memiliki ide, saya akan memberi tahu Anda sedikit tentang apa yang dilakukan layanan kami.

Bahkan, untuk semua orang. Jika Anda mengirimkan pencarian, maka kami meluncurkan hampir semua hal, mulai dari membangun basis pencarian. Artinya, kami memiliki MapReduce, kami mengumpulkan semua data tentang dokumen di sana, merebusnya, membangun semua jenis struktur data, sehingga ketika kami meminta mereka, kami dapat menghitung sesuatu secara efisien. Oleh karena itu, kami bekerja dari bawah ketika dokumen baru sampai kepada kami, dari tahap pertama, ketika dokumen-dokumen ini mendapatkan sesuatu dan memeringkatnya, dan ke atas, di mana tata letak menerima JSON bersyarat dan menariknya dengan semua gambar dan hal-hal indah. Dari bawah ke atas, kami sedang mengembangkan sesuatu di seluruh tumpukan.
Tetapi kami tidak hanya menulis kode dan, karenanya, kami melakukan semua ini dalam infrastruktur. Kami sebenarnya melatih jaringan saraf, CatBoost. Dan hal-hal ML lainnya yang dapat Anda bayangkan dan bakar, kami juga ajarkan. Juga, karena kita memiliki muatan besar, data besar, kita, tentu saja, menggeledah melalui algoritma dan struktur data dan tidak pernah menahan diri dari memperkenalkan mereka di suatu tempat. Misalnya, di beberapa tempat kami menggunakan pohon segmen. Kami memiliki kompresi indeks kami sendiri yang membangun boron dan menurutnya mempertimbangkan dinamika cara terbaik untuk membangun kamus.
Secara umum, berurusan dengan raksasa besar seperti pencarian, kami jenuh dengan tugas-tugas sederhana. Karena itu, kami, tentu saja, menyukai sesuatu yang kompleks, baru, sesuatu yang menantang kami. Dan kami tidak hanya pergi dan menulis, seperti biasa, sepuluh baris kode. Kita perlu memikirkan beberapa eksperimen. Secara umum, tugas-tugas yang kita tetapkan sendiri sering berada di ambang fiksi. Terkadang Anda berpikir: itu mungkin tidak mungkin. Tetapi kemudian Anda, mungkin, entah bagaimana bereksperimen - eksperimen dapat memakan waktu satu tahun penuh - tetapi pada akhirnya sesuatu berubah. Lalu kami mulai memperkenalkan, membuat kembali sesuatu.
Dan selain proyek, keterampilan, dan sebagainya, secara umum, kami adalah salah satu tim yang paling ambisius dan berkembang pesat di Yandex. Sebagai contoh, saya datang dua tahun lalu, adalah orang kesembilan dalam pelayanan kami. Sekarang kami memiliki layanan hampir 60 orang. Faktanya, ini adalah untuk pekerja magang, tetapi, secara umum, empat kali kami telah tumbuh dengan tepat dalam dua tahun. Ini untuk memberi Anda gambaran tentang apa yang dilakukan layanan kami.
Sekarang saya ingin memberi tahu Anda sedikit tentang bagian atas tentang tugas-tugas kami dan arah yang menurut saya, dalam waktu dekat kami akan semakin relevan. Tetapi untuk ini, Anda harus terlebih dahulu menjelaskan secara singkat cara kerja lapisan pencarian paling dasar.
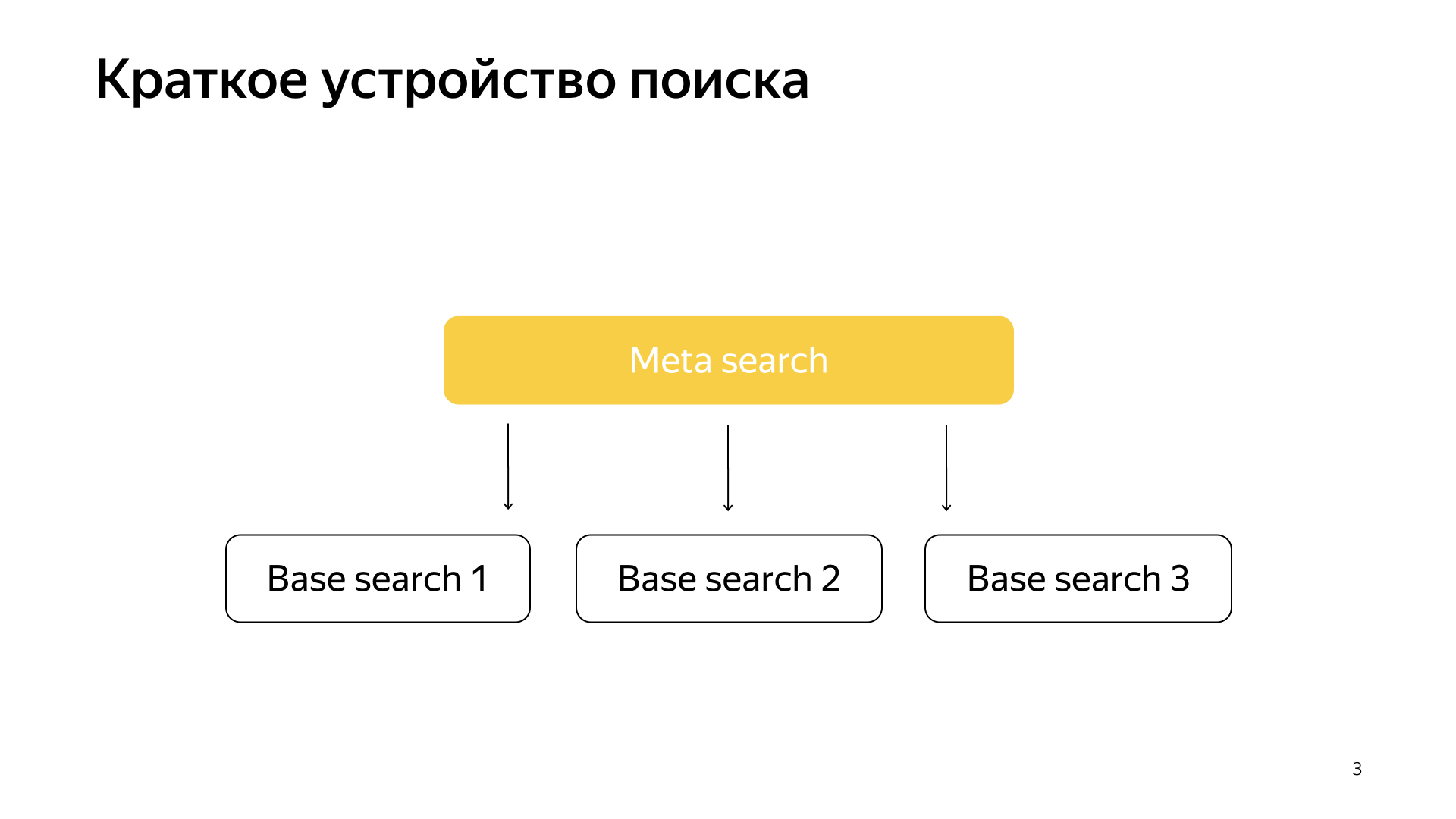
Secara umum, semuanya berjalan sangat sederhana. Kami memiliki basis pencarian kami, kami memiliki semua dokumen, dan kami membagi semua dokumen ini lebih atau kurang secara merata menjadi potongan-potongan N. Mereka disebut pecahan. Dan sebuah program yang disebut "Pencarian Dasar" diluncurkan di beling. Tugasnya adalah mencari, dengan demikian, pada bagian Internet ini. Artinya, dia tahu bagaimana mencarinya dan tidak tahu apa-apa lagi tentang Internet lainnya. Dan kami memiliki pecahan N seperti itu. Pencarian dasar diluncurkan di atas mereka, dan, karenanya, ada pencarian meta atas ini. Permintaan pengguna jatuh ke dalamnya dan, karenanya, ia pergi ke semua pecahan, dan setiap pecahan melakukan pencarian, kemudian masing-masing mengembalikan hasil, dan melakukan semacam penggabungan dan memberikan jawaban.
Begitulah cara pencarian diatur selama hampir 20 tahun, dan, secara umum, untuk waktu yang lama mereka berpikir bahwa ini akan tetap demikian, dan tidak ada yang lebih baik yang bisa dilakukan. Tetapi semuanya berubah, teknologi baru sedang muncul, dan pembelajaran mesin sekarang tidak hanya memungkinkan Anda untuk meningkatkan kualitas, tetapi juga memungkinkan Anda untuk memecahkan beberapa jenis masalah infrastruktur. Baru-baru ini, dalam pencarian kami, proyek telah ditembak sangat banyak, tepat di persimpangan infrastruktur dan pembelajaran mesin. Ketika dua mastodon tersebut bergabung, hasil yang sangat menarik diperoleh.

Baru-baru ini, jaringan saraf telah muncul. Kami memiliki teks permintaan, ada teks dokumen. Kami ingin mendapatkan beberapa vektor angka dari permintaan, untuk mendapatkan beberapa vektor angka dari dokumen sehingga produk skalar memprediksi nilai yang kami inginkan. Misalnya, kami ingin melatih produk skalar untuk memprediksi kemungkinan pengguna mengklik dokumen ini. Hal yang cukup dimengerti.
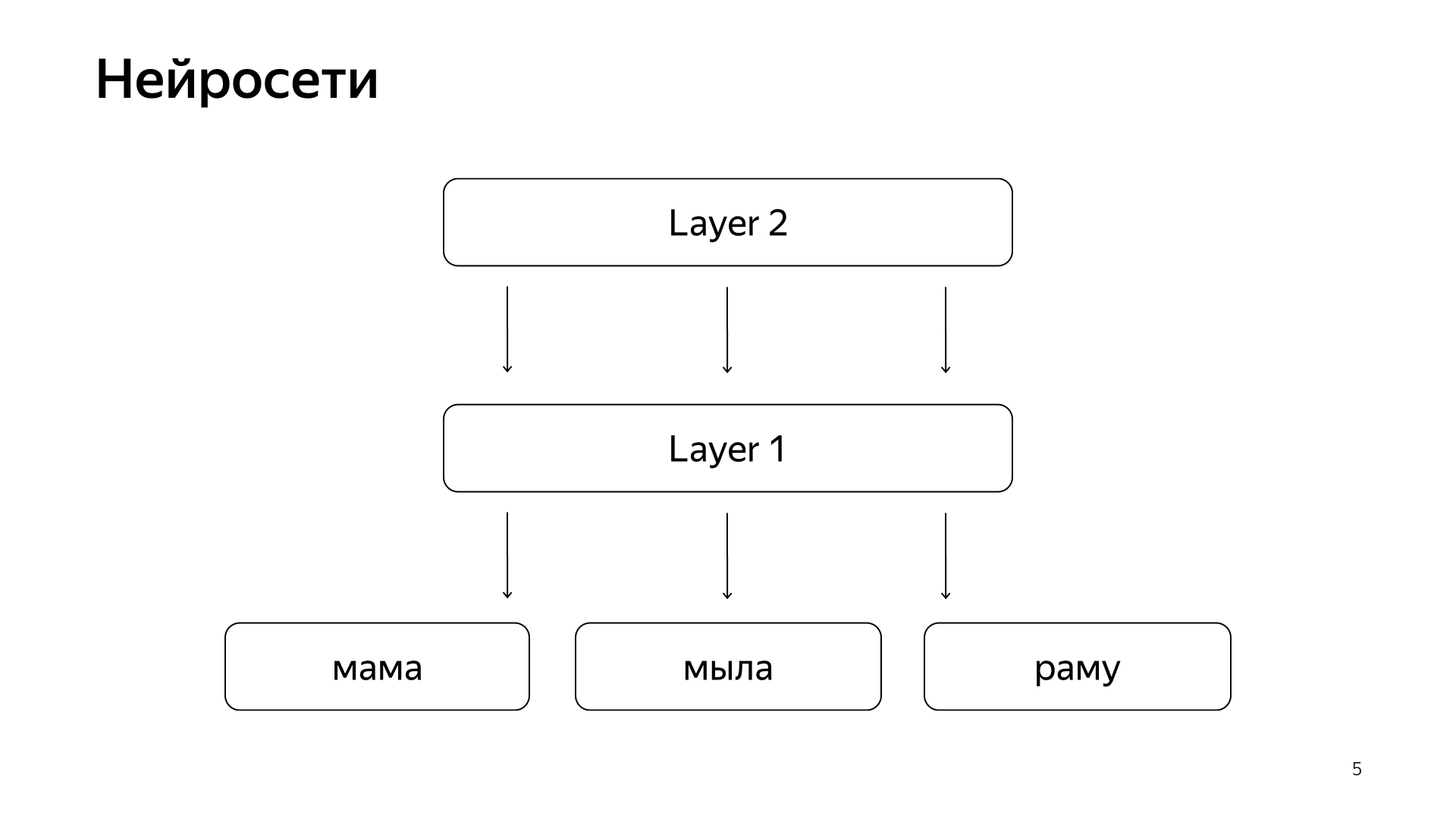
Ini diatur kira-kira seperti ini. Jika sangat, sangat kasar, maka kita memiliki beberapa kata di lapisan bawah, dan kemudian ada beberapa lapisan jaringan. Setiap lapisan, pada kenyataannya, mengambil vektor sebagai inputnya. Artinya, lapisan bawah adalah vektor yang jarang, di mana setiap kata adalah permintaan. Mengalikannya dengan matriks, mendapat semacam vektor, dan kemudian, dengan demikian, menerapkan beberapa nonlinier untuk masing-masing komponen, dan melakukan ini beberapa kali. Dan lapisan terakhir, ini disebut hanya vektor yang baru saja kita ambil permintaannya, menerapkan lapisan seperti itu, dan di sini lapisan terakhir adalah vektor yang sangat diminta.
Dengan demikian, jaringan saraf ini telah secara aktif diperkenalkan ke dalam pencarian dalam beberapa tahun terakhir, mereka membawa banyak manfaat bagi kualitas. Tetapi mereka memiliki satu masalah karena semua jumlah yang ingin kita prediksi bagus, tetapi cukup kasar, karena untuk melatih jaringan saraf seperti itu, lapisan bawahnya sangat besar - semua kata berasal dari puluhan juta kata, jadi Anda harus dapat menulis dia input beberapa miliar data.
Misalnya, kita dapat melatih beberapa klik pengguna, dan sebagainya. Tetapi sinyal utama yang dianggap paling penting dalam pencarian kami adalah penandaan manual oleh orang-orang khusus. Mereka menerima permintaan itu, mengambil dokumen itu, membacanya, memahami betapa baiknya itu dan memberi tanda, yaitu seberapa besar dokumen ini sesuai dengan permintaan ini. Untuk waktu yang lama, kami tidak dapat memprediksi besarnya seperti itu oleh jaringan saraf, karena kami masih memiliki jutaan perkiraan, karena mempekerjakan seluruh planet untuk terus-menerus menandai semuanya sangat mahal. Karena itu, kami melakukan peretasan.
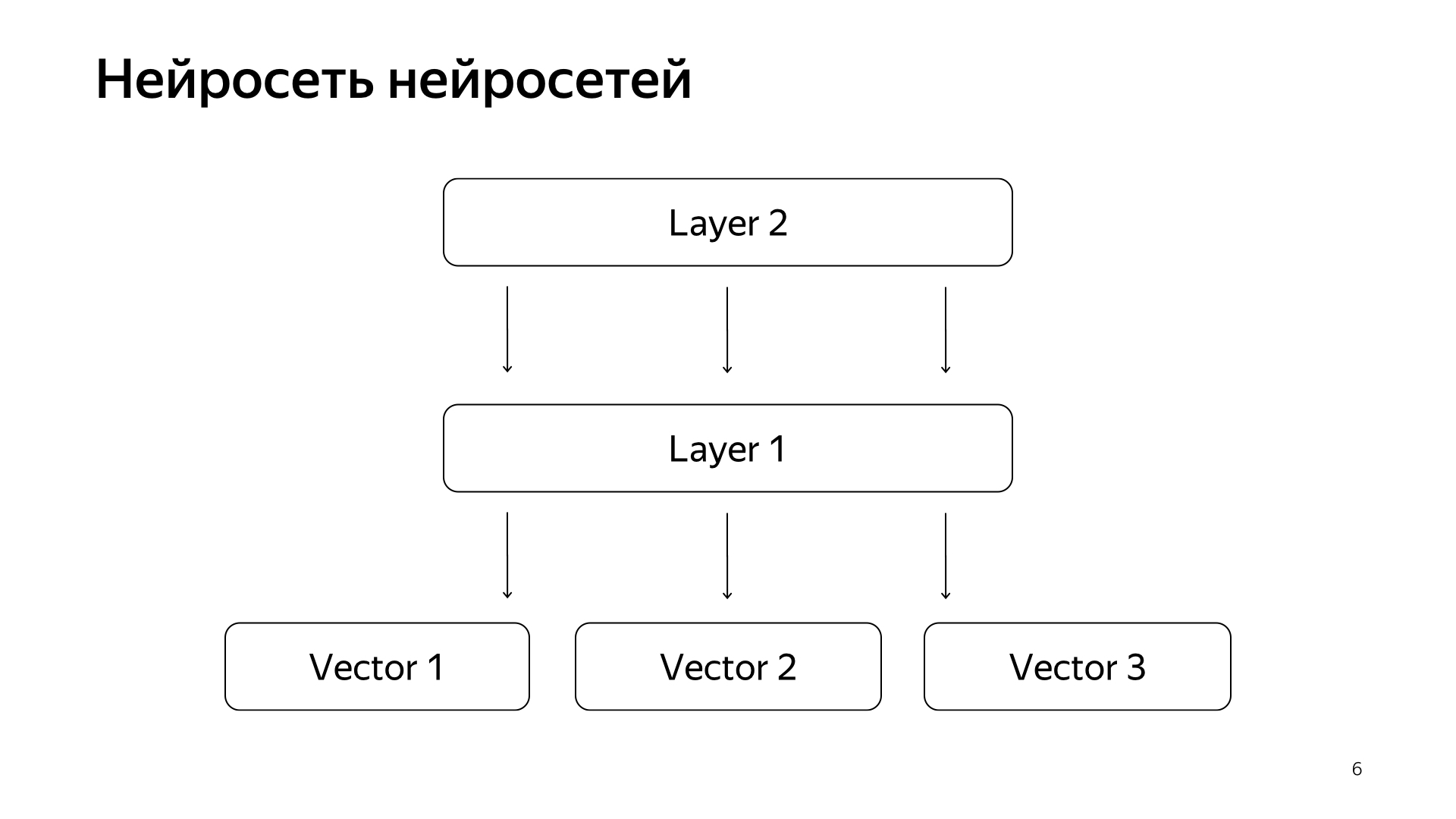
Jaringan saraf jaringan saraf. Selama beberapa tahun terakhir, kami telah mengumpulkan cukup banyak beberapa jaringan saraf yang memprediksi sinyal yang baik, tetapi sedikit lebih kasar daripada penilaian orang-orang khusus. Oleh karena itu, kami memutuskan bahwa kami akan mengirimkan vektor siap pakai dari jaringan ini ke lapisan bawah, dan kemudian kami akan melatih jaringan saraf untuk memprediksi relevansi pencarian kami hanya pada jaringan data yang lebih kecil.
Hasilnya adalah model yang sangat bagus. Dia membawa permintaan dokumen ke dalam vektor, dan produk skalar mereka secara langsung memprediksi relevansi nyata yang telah lama kita ingin prediksi.
Selanjutnya, kami punya ide cara mengulang sedikit pencarian. Proyek ini disebut pangkalan KNN (bahasa Inggris tetangga terdekat k, metode tetangga terdekat k).

Ide dasarnya adalah ini. Kami memiliki vektor kueri dan vektor dokumen. Kita perlu menemukan yang terdekat. Kami memiliki setiap dokumen yang diwakili oleh vektor. Mari kita sorot N cluster, yang mencirikan seluruh ruang dokumen. Secara kasar. Sangat kecil dari jumlah dokumen, tetapi misalnya, mereka mencirikan topik. Secara sederhana, ada sekelompok kucing, sekelompok bahan makanan, sekelompok program, dan sebagainya.
Oleh karena itu, kami tidak akan menyebarkan dokumen secara acak ke dalam pecahan, seperti sebelumnya, tetapi kami akan meletakkan dokumen di beling itu, yaitu, pusat massa yang paling dekat dengan dokumen. Dengan demikian, kita akan memiliki dokumen seperti itu yang dikelompokkan berdasarkan topik dalam pecahan.
Dan lebih jauh, hanya untuk sebuah permintaan, sekarang kita tidak bisa pergi ke semua pecahan, tetapi hanya untuk pergi ke beberapa bagian kecil dari mereka yang paling dekat dengan permintaan ini.
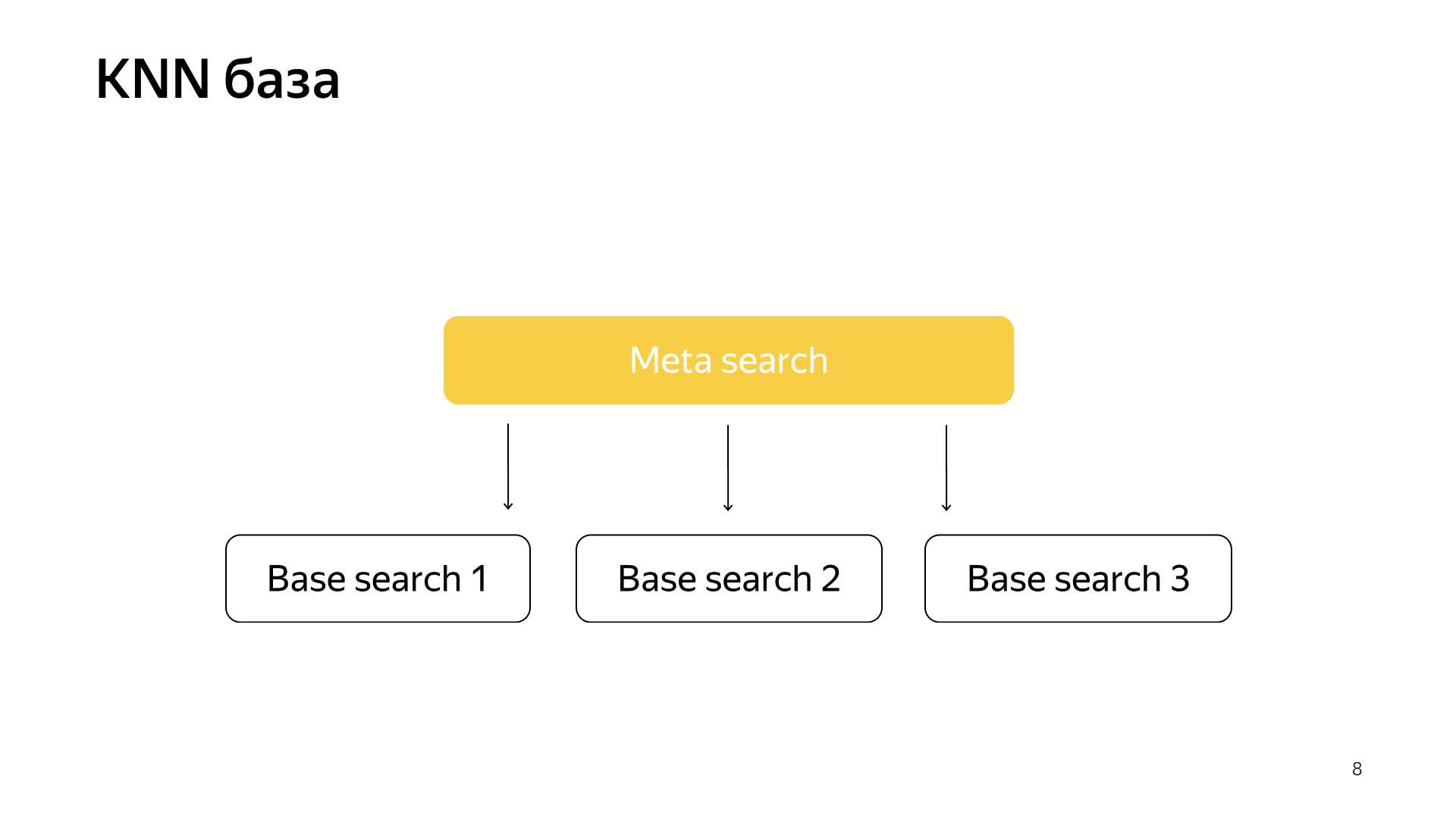
Karenanya, kami memiliki skema seperti itu, meta-search termasuk dalam semua pecahan. Dan sekarang dia harus pergi ke jumlah yang jauh lebih kecil, dan pada saat yang sama kita masih akan mencari dokumen terdekat.
Apa yang sebenarnya kita dapatkan dari desain ini? Ini secara signifikan mengurangi konsumsi sumber daya komputasi, hanya karena kita pergi ke lebih sedikit cluster. Ini, seperti yang telah saya katakan, saya menganggap salah satu hal penting dari layanan kami, ini adalah paduan infrastruktur dan pembelajaran mesin yang memberikan hasil sedemikian rupa sehingga tidak ada yang bisa memikirkan sebelumnya.

Dan, pada akhirnya, itu hanya hal yang sangat lucu, karena Anda punya model di sini, dan kemudian Anda pergi, redid seluruh pencarian, mematikan petabyte data, dan pencarian Anda berhasil, itu membakar sepuluh kali lebih sedikit sumber daya. Anda menghemat satu miliar dolar untuk perusahaan, semua orang senang.

Saya berbicara tentang salah satu proyek yang muncul dalam pencarian kami dan yang sedang dilaksanakan dan dilakukan bersama dengan semua percobaan selama satu tahun ditangguhkan. Tugas khas kami yang lain adalah menggandakan basis pencarian, karena Internet terus berkembang dan kami ingin mengejar ketinggalan dan mencari di semua halaman di Internet. Dan tentu saja, ini adalah percepatan lapisan dasar, di mana ada banyak contoh, sebagian besar besi. Misalnya, mempercepat pencarian basis Anda dengan satu persen berarti menghemat sekitar satu juta dolar.
Kami juga terlibat dalam pencarian sebagai inkubator startup. Saya akan jelaskan. Pencarian telah dilakukan selama 20 tahun. Itu telah melakukan banyak hal, berkali-kali kami menghadapi jalan buntu dan berpikir bahwa tidak ada lagi yang bisa dilakukan. Lalu ada serangkaian percobaan panjang. Kami kembali menembus jalan buntu ini. Dan selama ini kami telah mengumpulkan banyak keahlian tentang bagaimana melakukan hal-hal besar dan keren. Karenanya, sekarang sebagian besar arah baru di Yandex dilakukan dalam pencarian, karena orang-orang dalam pencarian sudah tahu bagaimana melakukan semua ini, dan logis untuk meminta mereka setidaknya merancang beberapa sistem baru. Dan sebagai maksimum - pergi dan lakukan sendiri.
Sekarang, saya harap Anda memiliki sedikit gagasan tentang pekerjaan kami. Saya akan segera menceritakan bagian tematik dari cerita saya tentang pekerja magang di layanan kami. Kami sangat mencintai mereka. Kami memiliki banyak dari mereka, musim panas lalu hanya dalam kelompok saya ada 20 peserta pelatihan, dan saya pikir ini bagus. Ketika Anda mengambil satu atau tiga pekerja magang, mereka merasa sedikit kesepian, kadang-kadang mereka takut untuk bertanya pada kawan yang lebih tua. Dan ketika ada banyak dari mereka, mereka berkomunikasi satu sama lain sebagai kawan sial. Jika mereka takut meminta sesuatu kepada pengembang, mereka akan pergi, mereka akan berbisik di sudut. Suasana seperti itu membantu melakukan segalanya dengan efisien.
Kami memiliki sejuta tugas, timnya tidak terlalu besar, sehingga pekerja magang kami penuh. Kami tidak meminta peserta pelatihan untuk duduk di log sepanjang waktu, menulis tes, refactor kode, tetapi segera memberikan semacam tugas produksi yang rumit: mempercepat pencarian, meningkatkan kompresi indeks. Tentu saja kami membantu. Kami tahu bahwa ini semua terbayar, jadi kami senang berbagi keahlian kami. Karena bidang kegiatan kita cukup luas, kita masing-masing akan menemukan tugas untuk dirinya sendiri sesuai dengan kesukaannya. Ingin menyodok di ML - menyodok. Anda hanya menginginkan MapReduce - ok. Ingin runtime - runtime. Ada sesuatu.
Apa yang perlu Anda sampaikan kepada kami? Kami melakukan segalanya terutama dalam C ++ dan Python. Tidak perlu mengetahui keduanya. Seseorang dapat mengetahui satu hal. Kami menyambut baik pengetahuan tentang algoritma. Ini membentuk gaya berpikir tertentu, dan sangat membantu. Tetapi ini juga tidak perlu: sekali lagi, kita siap untuk mengajarkan segalanya, kita siap untuk menginvestasikan waktu kita, karena kita tahu bahwa itu terbayar. Syarat terpenting yang kita buat, moto kita, jangan takut pada apa pun dan banyak tokoh. Jangan takut untuk menghentikan produksi, jangan takut untuk mulai melakukan sesuatu yang rumit. Karena itu, kita membutuhkan orang-orang yang juga tidak takut pada apa pun dan yang juga siap untuk mengubah gunung. Terima kasih banyak