Dalam posting ini, kita akan berbicara tentang studi ML percontohan untuk hypermarket online Utkonos, di mana kami memperkirakan pembelian kembali barang yang mudah rusak. Pada saat yang sama, kami memperhitungkan data tidak hanya pada saldo stok, tetapi juga kalender produksi dengan akhir pekan dan hari libur dan bahkan cuaca (panas, salju, hujan dan hujan es tidak lain adalah Taft Three Weathers, tetapi tidak untuk pelanggan). Sekarang kita tahu, misalnya, bahwa "jiwa Rusia yang misterius" sangat lapar akan daging pada hari Sabtu, dan menghargai telur putih di atas yang berwarna cokelat. Tetapi hal pertama yang pertama.

Pilot ritel lebih dari pilot
Di ritel, pembelajaran mesin ada di posisi ganda. Di satu sisi, pengecer telah mengakumulasikan jumlah data yang mengesankan selama periode waktu yang sangat mengesankan: kwitansi pembelian individu, data dari kartu loyalitas ... Di sisi lain, pengecer sudah ada begitu lama sehingga masalah perkiraan permintaan mulai diselesaikan jauh sebelum mode ilmu data muncul dan saat ini sudah siap untuk digunakan. alat BI yang diperlukan.
Ternyata ritel adalah salah satu bidang yang paling menjanjikan untuk eksperimen para ilmuwan data dan pengenalan pembelajaran mesin, tetapi bisnis memandang semua ini dengan skeptis: apakah ini benar-benar baik untuk saya? Bagaimanapun, sudah ada solusi yang terbukti dengan pengalaman bertahun-tahun.
Dan sekarang saatnya untuk menyetujui studi percontohan!
Pilot sendiri, dibandingkan dengan proyek ML penuh, memiliki keterbatasan dan spesifik yang dapat dimengerti.
- Cukup waktu dihabiskan untuk studi percontohan untuk menunjukkan kepada pelanggan kemungkinan pembelajaran mesin pada data mereka, tetapi tidak sebanyak kehilangan uang.
- Selain itu, sebagai suatu peraturan, dataaintists tidak akan lagi memiliki kesempatan kedua: jika hasil pertama dari bisnis tidak tampak menarik, maka itu akan tetap skeptis dan setia pada metode peramalan yang lama. Jadi, Anda perlu membidik dengan akurat.
- Selama proyek percontohan, tidak ada hubungan saling percaya yang muncul antara pelanggan dan pusat data. Dan unit dan spesialis yang memiliki data penting untuk interpretasi kemungkinan besar tidak dapat diakses selama uji coba, serta wawasan yang penting secara komersial.
Tentu saja, fitur-fitur ini tidak dimanifestasikan dalam setiap proyek percontohan, tetapi mereka merupakan bagian penting dari risikonya.
Sedikit tentang tugas
Jauh sebelum berkenalan dengan pembelajaran mesin, Utkonos sudah menggunakan sistem analitiknya sendiri, yang memperkirakan pembayaran barang selama seminggu dengan akurasi yang sangat tinggi. Namun, pengecer tertarik pada kemungkinan meningkatkan efektivitas perencanaan. Ini terutama menyangkut produk yang mudah rusak, banyak di antaranya juga sangat mahal. Garpu tradisional: jika Anda membeli banyak - akan ada kerugian, jika Anda membeli tidak cukup - pembeli akan pergi ke pesaing untuk tenderloin anak sapi kesayangannya yang dipanen dengan bulan purnama dan hujan gerimis. Untuk perkiraan yang cukup akurat untuk lusa, solusi yang didasarkan pada pembelajaran mesin lebih cocok, memungkinkan lebih banyak faktor diperhitungkan daripada alat BI klasik. Utkonos setuju untuk bertindak sebagai mitra kami untuk percobaan yang bertujuan menguji hipotesis penerapan Machine Learning untuk e-commerce.
Untuk menunjukkan kemungkinan pembelajaran mesin untuk memecahkan masalah ini, dalam perjanjian dengan bisnis, beberapa nama dagang dipilih:
- dua produk dari kategori “Daging Dingin” - sebagai produk yang mudah rusak, data yang paling penting untuk diperbarui segera;
- dan dua produk dari kategori "Telur Ayam" - sebagai produk dengan permintaan musiman tertentu, yang tidak dapat diprediksi hanya sebagai "pada hari Kamis semua orang membeli X, dan pada hari Jumat - X dikalikan dengan faktor". Meskipun telur ayam tidak sulit untuk memprediksi penyitaan dan hanya untuk mereka cakrawala perencanaan mingguan cukup dapat diterima, itu pada produk-produk ini yang perlu untuk menunjukkan bahwa pembelajaran mesin benar-benar melihat hubungan yang kompleks dan membangun ramalan yang tidak sepele.
Kami telah memilih produk tertentu sesuai selera kami, dengan mengandalkan kelengkapan data historis. Beberapa barang diperkenalkan ke dalam barisan baru-baru ini, beberapa - sebaliknya, dijual sekali, tetapi pada saat itu mereka sudah dikeluarkan dari bermacam-macam, sehingga nilai data pada mereka hanya historis.
Data yang disediakan oleh Utkonos berisi informasi tentang penjualan empat nama komoditas selama 2 tahun sebelumnya dan ketersediaan barang-barang ini dalam stok pada periode yang relevan. Dari kumpulan data umum, kami segera "memotong" enam bulan terakhir, dari awal November hingga akhir April - ini akan menjadi rangkaian pengujian kami. Itu termasuk bulan-bulan musim gugur yang relatif tenang dan serangkaian liburan musim dingin dan liburan musim semi.
Petualangan singkat tapi menarik menunggu kami.
Data dari gudang: misterius dan perlu
Ketika bekerja dengan data historis, pertanyaan pertama yang muncul di hadapan kami adalah bagaimana memisahkan penjualan nyata dari "penjualan maksimum yang tersedia" (yaitu, kasus ketika barang yang berakhir di gudang ditebus 100%, tetapi jika tersedia, volume penjualan dapat lebih tinggi)? Keinginan pembeli yang tidak terpenuhi seperti itu tidak ditampilkan dalam data.
Ketersediaan barang dalam persediaan. Ngomong-ngomong, dari pengalaman proyek-proyek sebelumnya di ritel, kami berharap ini akan menjadi saldo yang dinyatakan dalam satuan pengukuran. Namun, dalam kasus ini, kami berhadapan dengan indikator relatif “aksesibilitas”, yang diukur dalam persen pada siang hari. Adapun ketersediaan barang di gudang, indikator ini sangat relatif: fakta bahwa tidak ada barang setiap saat tidak berarti bahwa mereka ingin membelinya.
Setelah bereksperimen dengan berbagai opsi (rekonstruksi "permintaan nyata" berdasarkan koefisien yang dihitung secara berbeda dan memfilter dataset penjualan dengan ambang aksesibilitas yang berbeda), kami akhirnya memilih ambang optimal yang tidak membuat kumpulan data terlalu sempit. Cita-cita - ketersediaan barang sepanjang hari - secara signifikan mengurangi data bahkan untuk barang-barang terlaris.
Butir 1: daging dingin (unggas tidak biasa)
Kami mulai bekerja dengan daging dingin, karena kami tidak meragukan kemampuan prediktif model, segera setelah siap dalam bentuk draft. (Spoiler: tetapi sia-sia - dalam dataset dengan penjualan telur kejutan yang menarik sedang menunggu kami, tetapi lebih lanjut tentang itu nanti).
Untuk menghemat waktu "di luar kotak" kami mendapat perpustakaan siap pakai yang berfungsi baik dengan deret waktu - Nabi dari Facebook .

Hasil model pada data pelatihan segera menunjukkan kelebihan dan kekurangan. Model mengambil musiman permintaan dengan baik, tetapi mengambil buruk. Juga hari libur ditransfer oleh Nabi secara default. Deviasi relatif adalah 31,36%, kami akan terus menggunakannya sebagai hasil dasar.
Alat visualisasi musiman built-in, yang dilihat oleh Nabi, memungkinkan Anda untuk segera mendapatkan wawasan kecil tentang bagaimana pembelian salah satu produk berubah selama dua tahun, fitur apa yang mereka miliki sepanjang tahun dan selama seminggu:

Daging dingin kami memiliki tren kenaikan yang jelas dalam jumlah total pembelian, jumlah pembelian naik dari Senin hingga Sabtu dan jatuh pada hari Minggu, di musim panas pembelian terasa “melorot”. Buruknya musim panas tidak masuk dalam periode pengujian kami; di sisi lain, ingatlah bahwa periode liburan dan liburan penting untuk tingkat penjualan, karena liburan musim panas jauh dari yang ada di Rusia.
Pertanyaan logisnya adalah: apakah mungkin untuk menggunakan model ini segera untuk perkiraan selama enam bulan ke depan?
Secara intuitif, sepertinya tidak. Percobaan menunjukkan itu. Pola umum musiman selama seminggu adalah benar. Tetapi segera menjadi jelas bahwa ada sejuta penyimpangan dari pola musiman umum, baik naik turun, dan deviasi rata-rata 45,71% jauh lebih tinggi daripada hasil pada data pelatihan. Jelas ini tidak baik.
Untuk memulainya, mari kita coba latih model tersebut setiap hari, bayangkan bahwa setiap hari setelah toko selesai, dataset dilengkapi dengan penjualan untuk "hari ini". Kita sudah tahu bahwa dalam penjualan ada kecenderungan naik secara umum - ada kemungkinan bahwa pergantian pada data pengujian kami tumbuh dengan intensitas yang lebih besar karena aktivitas pemasaran yang lebih aktif daripada pada rangkaian pelatihan.
Keberhasilan relatif: dengan pelatihan ulang model setiap hari, deviasi relatif adalah 33,79%. Kami melengkapi parameter model dengan informasi tentang akhir pekan yang ditunda, puasa keagamaan dan hari libur tradisional untuk Rusia (seperti Tahun Baru, Paskah dan sejumlah lainnya). Perubahan cuaca mendadak juga ditambahkan: hari-hari ketika suhu melonjak naik atau turun sebesar 10+ derajat atau hanya terasa lebih tinggi atau lebih rendah daripada hari-hari lain di bulan ini. Sekarang, rata-rata selama enam bulan, perkiraan kami menyimpang dari penjualan riil sebesar 28,48%, dan secara umum, model mulai lebih baik memperhitungkan lonjakan akun dalam aktivitas konsumen. Kami meningkatkan deviasi rata-rata sebesar lima persen! Terlepas dari kenyataan bahwa Nabi, pada prinsipnya, bekerja dengan buruk dan dianjurkan untuk menghapus data dari mereka, itu adalah gerakan maju yang nyata.


Sebelum menunjukkan hasil awal, muncul pertanyaan: bisakah kita meningkatkan ramalan sedikit lagi? Jika Anda melihat korelasi antara penjualan produk dan harga rata-rata per hari, jelas bahwa ini adalah fitur terkait, dan harga tidak diperhitungkan saat membangun model. Namun jika dilihat dari kumpulan data, kami hanya dapat mengambil "harga rata-rata per unit" tertentu: dalam pesanan sering bervariasi pada hari yang sama, mis. direkam dengan diskon pribadi pembeli, dan harga "etalase" tidak termasuk dalam kumpulan data.

Koefisien korelasi antara harga rata-rata per unit per hari dan jumlah volume penjualan jenis daging dingin ini adalah -0,61 pada p <0,01. Jelas bahwa "harga rata-rata unit" bukan merupakan indikator yang ideal: jika selama hari itu ada banyak pembelian dari, katakanlah, mitra dengan diskon besar konstan, kebisingan berbahaya akan masuk ke dalam data. Tetapi kami ingin menyoroti hari-hari ketika ada dampak pemasaran: diskon umum untuk sekelompok barang, diskon untuk semua orang yang memperkenalkan kode promosi distribusi gratis, dll.
Namun demikian, bahkan setelah hari-hari dengan harga rata-rata dalam kuantil 5% dialokasikan sebagai hari promosi, tidak ada peningkatan keakuratan model. Akurasi meningkat pada hari-hari penjualan ekstrem, dan rata-rata penyimpangan relatif selama enam bulan tetap sama.
Tetapi gagasan tentang hubungan statistik yang nyata dengan harga telah dipertahankan untuk masa depan.

Kami cukup puas dengan hasil awal, sudah waktunya untuk beralih ke barang lain sebelum waktu yang diberikan untuk proyek percontohan berakhir.
Butir 2: Telur Ayam
Kami segera diperingatkan bahwa telur adalah salah satu kategori produk yang paling indikatif dalam hal dampak peristiwa eksternal. Pertama-tama, volume pembelian tumbuh pada Paskah: telur dicat dan dimasak dengan telur. Tetapi lebih banyak, tentu saja, dicat. Ini mudah dipahami dengan membandingkan penjualan telur putih dan coklat.

Secara umum, model kami mengharapkan bahwa akan ada beberapa peningkatan permintaan di Paskah, tetapi perkiraannya hampir 2 kali lebih kecil dari indikator sebenarnya (dan penyimpangan ~ 100% selama minggu Paskah ini membuat penyimpangan rata-rata selama enam bulan sangat besar). Mengapa Lagipula, minggu Paskah terjadi setiap tahun - harus ada pola dalam data 2 tahun sebelumnya!
Analisis penelitian menunjukkan bahwa tidak ada pola. Pada tahun 2018 (ini adalah data pengujian kami), puncak pembelian turun sepanjang minggu sebelum Paskah hingga 7 April. Pada Paskah itu sendiri (8 April 2018), pembelian telur selalu jatuh, yang dilihat modelnya dengan benar. Tetapi pada 2017 Paskah jatuh pada 16 April, dan puncak pembelian dalam data historis adalah 8 April, dan tahun ini puncaknya adalah satu hari. Pada 2016, Paskah jatuh pada 1 Mei. Puncak pembelian adalah 29 April, dengan naik sehari sebelum dan sehari sesudahnya. Pada 2015, Paskah jatuh pada 12 April, puncak pembelian lagi satu hari, 9 April.

Versi pertama kami adalah pengaruh hari-hari dalam seminggu (dan imajinasi melukis orang tua yang, besok, perlu melukis selusin telur, karena pelajaran tematik, dan anak mengatakan ini hari ini). Sayangnya, ini tidak benar. Mungkin, selama Paskah ada beberapa faktor yang belum kita temukan (dan belum memperhitungkan) - baik eksternal maupun yang terkait dengan pemasaran perusahaan itu sendiri.
Kita bisa berbuat lebih baik!
Kisah ini tentang bekerja dengan data pengecer untuk waktu yang terbatas, dan bukan tentang teknik pembelajaran mesin rahasia. Tetapi dalam bekerja dengan data ada peluang untuk meningkatkan hasilnya.
Setelah bekerja dengan produk dari kategori "Telur Ayam", menjadi jelas bahwa model dapat ditingkatkan dengan menambahkan faktor-faktor yang tidak kami gunakan dalam proyek percontohan. Oleh karena itu, diputuskan untuk melakukan percobaan kecil dengan hutan acak dan data yang dapat kami kumpulkan dari sumber terbuka. Plus, kita akan dapat melihat bagaimana model berperilaku, di mana hari-hari penjualan akan memiliki serangkaian tanda yang beragam, dan bukan hanya satu set "hari istimewa" yang dialokasikan pada satu atau lain dasar.
Informasi berikut dikumpulkan dalam kumpulan data tentang "dunia luar":
- kalender produksi penuh untuk setiap tahun;
- pos dan hari libur keagamaan, hari libur sekuler;
- kondisi cuaca dan penyimpangan mereka dari nilai rata-rata selama sebulan di wilayah tersebut, serta fluktuasi selama bulan, hari, dan minggu terakhir;
- nilai tukar dolar dan euro untuk Bank Sentral dan fluktuasi mereka sebagai indikator kondisi ekonomi secara umum.
Secara terpisah, rambu-rambu ditambahkan untuk melakukan kampanye pemasaran terpisah dan harga per unit barang.
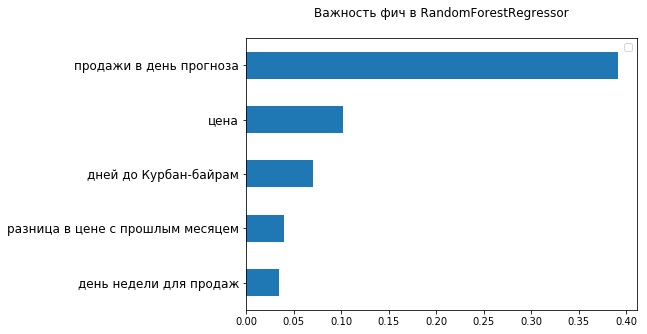
Pada set data yang diperluas, kami kembali membangun model yang setiap hari dilatih pada data baru, sekarang menggunakan RandomForestRegressor. Penyimpangan relatif sedikit meningkat: menjadi 27,29%. Grafik menunjukkan bahwa model baru lebih baik memprediksi dampak kampanye pemasaran, tetapi lebih buruk - musiman mingguan.

Melihat 5 tanda paling penting dari sudut pandang RandomForestRegressor yang digunakan, Anda dapat memastikan bahwa sudah ada dua tanda yang terkait dengan nilai barang - harga saat ini dan perubahannya dibandingkan dengan bulan lalu. Jelas, fakta bahwa kisaran harga tidak dapat ditetapkan dengan baik di FB Nabi mempengaruhi akurasinya.
Pada memeriksa apakah kita dapat berpikir sedikit lebih banyak dan meningkatkan hasilnya, studi percontohan telah selesai. Tujuan utama tercapai: kami menunjukkan bahwa pembelajaran mesin pada prinsipnya berlaku untuk data pengecer dan menunjukkan hasil yang baik bahkan dalam mode "mulai cepat".
Alexandra Tsareva, Spesialis, Analisis Cerdas, Jet Infosystems