Setiap operasi dengan data besar membutuhkan banyak daya komputasi. Pemindahan data dari basis data ke Hadoop dapat memakan waktu berminggu-minggu atau biaya sebanyak sayap pesawat. Tidak ingin menunggu dan berbelanja secara royal? Seimbangkan muatan pada platform yang berbeda. Salah satu caranya adalah optimasi pushdown.
Saya bertanya kepada Alexei Ananyev, pelatih Rusia terkemuka untuk pengembangan dan administrasi produk Informatica, untuk berbicara tentang fungsi optimisasi pushdown di Informatica Big Data Management (BDM). Pernah belajar bekerja dengan produk Informatica? Kemungkinan besar, Alex yang memberi tahu Anda dasar-dasar PowerCenter dan menjelaskan cara membuat pemetaan.
Alexey Ananiev, Kepala Pelatihan di DIS Group
Apa itu pushdown?
Banyak dari Anda sudah terbiasa dengan Informatica Big Data Management (BDM). Produk ini dapat mengintegrasikan data besar dari sumber yang berbeda, memindahkannya di antara sistem yang berbeda, menyediakan akses mudah ke mereka, memungkinkan Anda untuk membuat profil mereka dan banyak lagi.
Di tangan yang terampil, BDM dapat bekerja dengan sangat baik: tugas akan diselesaikan dengan cepat dan dengan sumber daya komputasi yang minimal.
Anda menginginkannya juga? Pelajari cara menggunakan fitur pushdown dalam BDM untuk mendistribusikan beban komputasi lintas platform. Teknologi pushdown memungkinkan Anda untuk mengubah pemetaan menjadi skrip dan memilih lingkungan di mana skrip ini akan berjalan. Kemungkinan pilihan semacam itu memungkinkan Anda untuk menggabungkan kekuatan platform yang berbeda dan mencapai kinerja maksimalnya.
Untuk mengkonfigurasi runtime skrip, pilih jenis pushdown. Skrip dapat sepenuhnya dijalankan di Hadoop atau didistribusikan sebagian antara sumber dan penerima. Ada 4 jenis kemungkinan pushdown. Pemetaan tidak dapat diubah menjadi skrip (asli). Pemetaan dapat dilakukan sebanyak mungkin di sumber (sumber) atau sepenuhnya pada sumber (penuh). Pemetaan juga dapat diubah menjadi skrip Hadoop (tidak ada).
Optimalisasi pushdown
4 tipe yang terdaftar dapat dikombinasikan dengan berbagai cara - mengoptimalkan pushdown untuk kebutuhan spesifik sistem. Misalnya, seringkali lebih disarankan untuk mengekstrak data dari database menggunakan kemampuannya sendiri. Dan untuk mengubah data - oleh Hadoop, sehingga database itu sendiri tidak kelebihan beban.
Mari kita lihat kasus ketika sumber dan penerima berada di database, dan platform eksekusi transformasi dapat dipilih: tergantung pada pengaturan, itu akan menjadi Informatica, server database atau Hadoop. Contoh seperti itu akan memungkinkan untuk paling akurat memahami sisi teknis dari mekanisme ini. Secara alami, dalam kehidupan nyata, situasi ini tidak muncul, tetapi paling cocok untuk menunjukkan fungsinya.
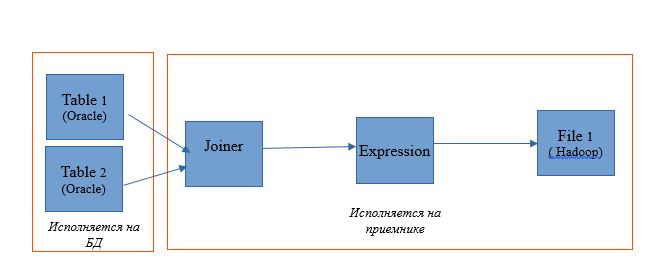
Ambil pemetaan untuk membaca dua tabel dalam satu basis data Oracle. Dan biarkan hasil bacaan ditulis ke tabel di database yang sama. Skema pemetaan adalah sebagai berikut:

Dalam bentuk pemetaan pada Informatica BDM 10.2.1, terlihat seperti ini:
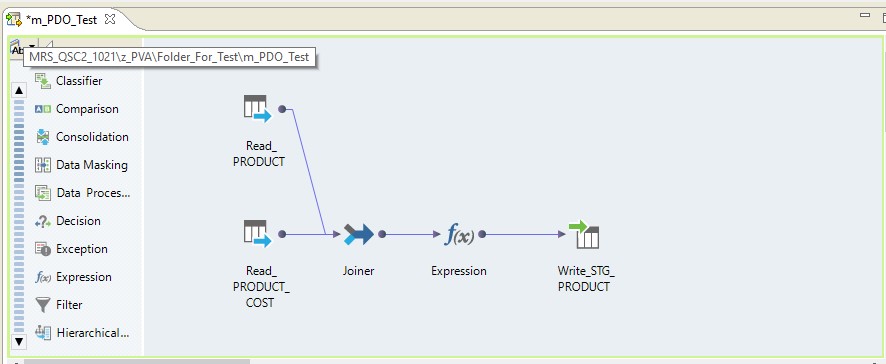
Ketik pushdown - asli
Jika kami memilih jenis asli pushdown, pemetaan akan dilakukan pada server Informatica. Data akan dibaca dari server Oracle, ditransfer ke server Informatica, diubah di sana dan ditransfer ke Hadoop. Dengan kata lain, kami mendapatkan proses ETL biasa.
Ketik pushdown - source
Saat memilih sumber jenis, kami mendapat kesempatan untuk mendistribusikan proses kami antara server database (DB) dan Hadoop. Saat menjalankan proses dengan pengaturan ini, permintaan untuk memilih data dari tabel akan terbang ke database. Dan sisanya akan dilakukan dalam bentuk langkah-langkah di Hadoop.
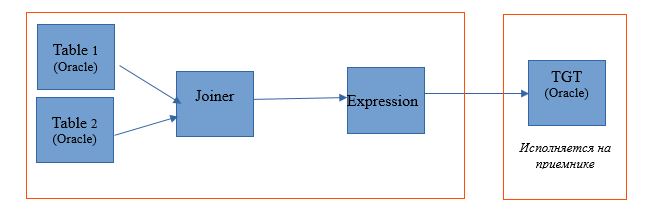
Skema eksekusi akan terlihat seperti ini:
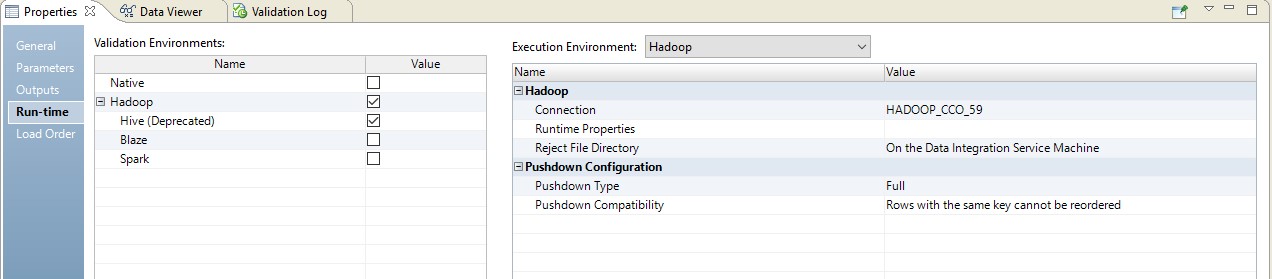
Di bawah ini adalah contoh pengaturan runtime.
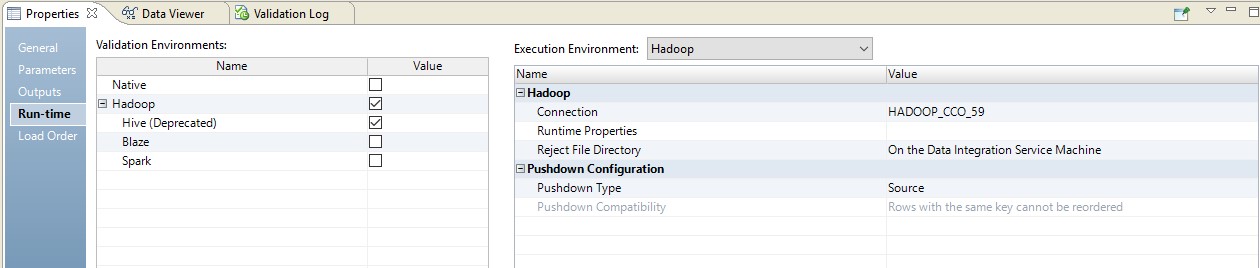
Dalam hal ini, pemetaan akan dilakukan dalam dua langkah. Dalam pengaturannya, kita akan melihat bahwa ia berubah menjadi skrip yang akan dikirim ke sumbernya. Selain itu, kombinasi tabel dan konversi data akan dilakukan dalam bentuk kueri yang diganti di sumbernya.
Pada gambar di bawah, kami melihat pemetaan yang dioptimalkan pada BDM, dan pada sumber - permintaan yang diganti.
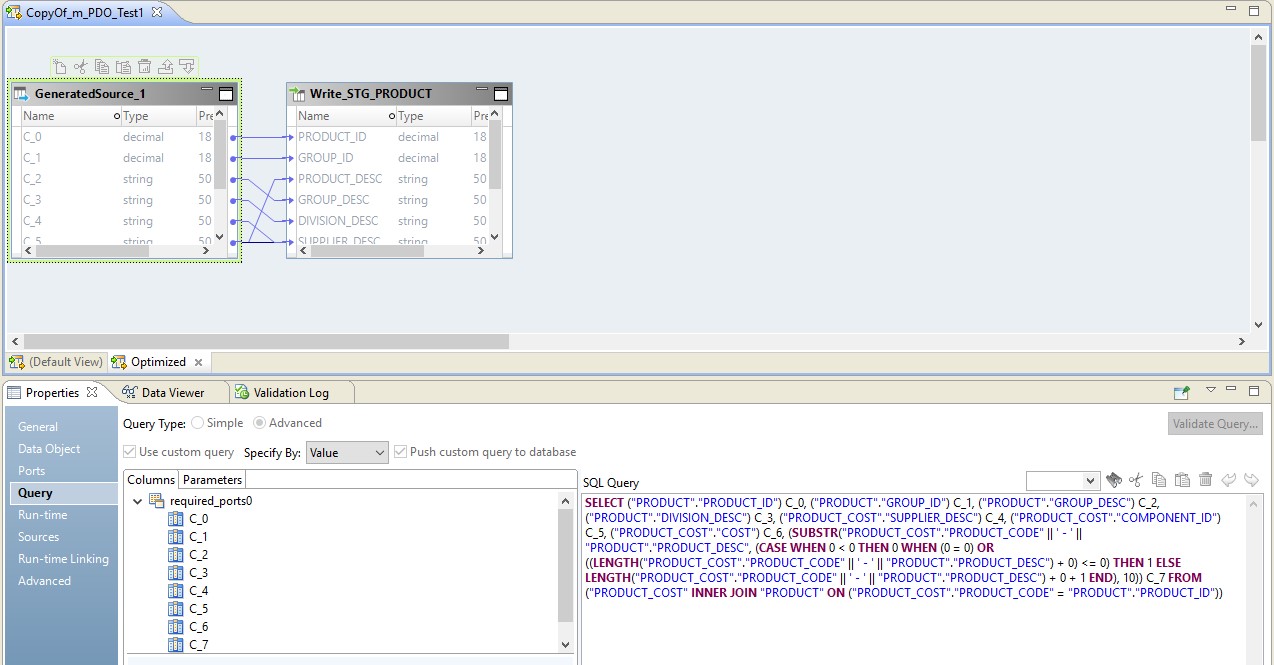
Peran Hadoop dalam konfigurasi ini adalah mengelola aliran data - menjalankannya. Hasil dari permintaan akan dikirim ke Hadoop. Setelah membaca, file dari Hadoop akan ditulis ke penerima.
Ketik pushdown - penuh
Saat memilih tipe lengkap, pemetaan akan sepenuhnya berubah menjadi permintaan basis data. Dan hasil permintaan akan diarahkan ke Hadoop. Diagram proses semacam itu disajikan di bawah ini.
Contoh setup ditunjukkan di bawah ini.
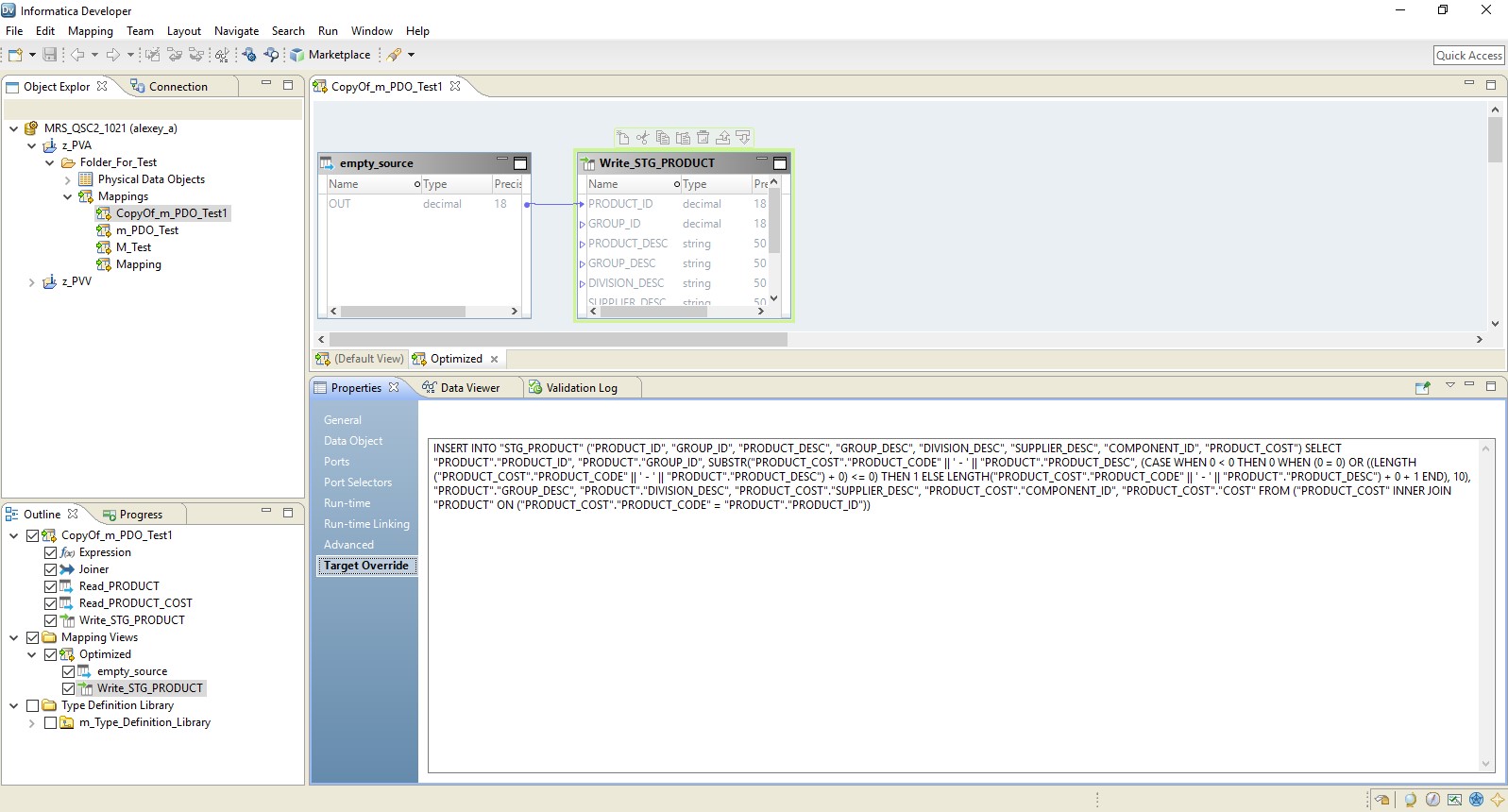
Sebagai hasilnya, kami mendapatkan pemetaan yang dioptimalkan mirip dengan yang sebelumnya. Satu-satunya perbedaan adalah bahwa semua logika ditransfer ke penerima dalam bentuk override dari penyisipannya. Contoh pemetaan yang dioptimalkan disajikan di bawah ini.
Di sini, seperti dalam kasus sebelumnya, Hadoop bertindak sebagai konduktor. Tapi di sini sumbernya dibaca secara keseluruhan, dan kemudian di tingkat penerima logika pemrosesan data dieksekusi.
Ketik pushdown - null
Nah, opsi terakhir adalah tipe pushdown, di mana pemetaan kita akan berubah menjadi skrip Hadoop.
Pemetaan yang dioptimalkan sekarang akan terlihat seperti ini:
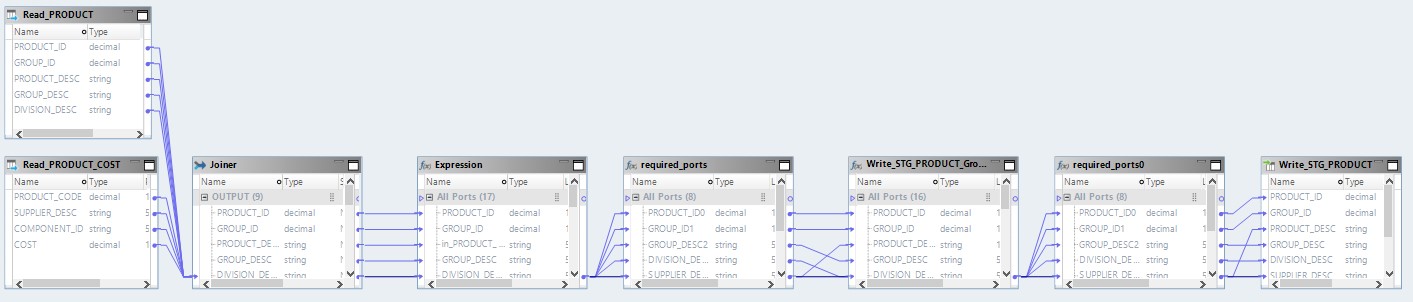
Di sini, data dari file sumber pertama akan dibaca di Hadoop. Kemudian, dengan caranya sendiri, kedua file ini akan digabungkan. Setelah itu, data akan dikonversi dan diunggah ke database.
Memahami prinsip-prinsip optimasi pushdown, Anda dapat dengan sangat efektif mengatur banyak proses untuk bekerja dengan data besar. Jadi, baru-baru ini, sebuah perusahaan besar hanya dalam beberapa minggu mengunggah data besar dari penyimpanan ke Hadoop, yang telah dikumpulkannya selama beberapa tahun sebelumnya.