
Dalam artikel ini, saya akan berbicara tentang solusi saya ke bagian teks dari tugas
SNA Hackathon 2019 . Beberapa gagasan yang diusulkan akan bermanfaat bagi para peserta bagian penuh waktu dari hackathon, yang akan diadakan di kantor Moskow Grup Mail.ru mulai 30 Maret hingga 1 April. Selain itu, cerita ini mungkin menarik bagi pembaca untuk memecahkan masalah praktis pembelajaran mesin. Karena saya tidak dapat mengklaim hadiah (saya bekerja di Odnoklassniki), saya mencoba menawarkan solusi yang paling sederhana, tetapi pada saat yang sama efektif dan menarik.
Membaca tentang model baru pembelajaran mesin, saya ingin memahami bagaimana alasan penulis saat mengerjakan tugas. Oleh karena itu, dalam artikel ini saya akan mencoba untuk membuktikan secara terperinci semua komponen solusi saya. Pada bagian pertama saya akan berbicara tentang pernyataan masalah dan batasannya. Yang kedua - tentang evolusi model. Bagian ketiga dikhususkan untuk hasil dan analisis model. Akhirnya, dalam komentar saya akan mencoba menjawab pertanyaan yang muncul. Pembaca yang tidak sabar dapat segera melihat
arsitektur terakhir .
Tantangan
Penyelenggara Hackathon menyarankan agar kami memecahkan masalah membentuk pita pintar. Untuk setiap pengguna, perlu untuk mengurutkan set posting sehingga jumlah posting maksimum yang ditetapkan pengguna "kelas" ada di bagian atas daftar. Untuk mengonfigurasi algoritme peringkat, seharusnya menggunakan data historis formulir (pengguna, pos, umpan balik). Tabel ini memberikan deskripsi singkat tentang data dari bagian teks dan notasi yang akan saya gunakan dalam artikel ini.
Sumber
| Penunjukan
| Jenis
| Deskripsi
|
|---|
pengguna
| user_id
| kategorikal
| ID pengguna
|
pos
| post_id
| kategorikal
| kirim id
|
pos
| teks
| daftar kategori
| daftar kata-kata yang dinormalisasi
|
pos
| fitur
| kategorikal
| sekelompok karakteristik tulisan (penulis, bahasa, dll.)
|
umpan balik
| umpan balik
| daftar biner
| berbagai tindakan yang dapat dilakukan pengguna dengan pos (tampilan, kelas, komentar, dll.)
|
Sebelum mulai membangun model, saya memperkenalkan beberapa batasan pada solusi masa depan. Ini diperlukan untuk memenuhi persyaratan kesederhanaan dan kepraktisan, minat saya dan untuk mengurangi jumlah opsi yang mungkin. Berikut adalah batasan terpenting dari ini.
Prediksi probabilitas "kelas" . Saya segera memutuskan bahwa saya akan menyelesaikan masalah ini sebagai masalah klasifikasi. Seseorang dapat menerapkan metode yang digunakan dalam pemeringkatan, misalnya, untuk memprediksi urutan berpasangan posting. Tapi saya memilih formulasi yang lebih sederhana, di mana posting diurutkan sesuai dengan probabilitas yang diperkirakan untuk mendapatkan "kelas". Perlu dicatat bahwa pendekatan yang dijelaskan di bawah ini dapat diperluas untuk merumuskan peringkat.
Model monolitik . Terlepas dari kenyataan bahwa ansambel model cenderung memenangkan kompetisi, mempertahankan ansambel pada sistem pertempuran lebih sulit daripada model tunggal. Selain itu, saya ingin memiliki setidaknya beberapa kemampuan interpretasi non-kotak hitam.
Grafik komputasi yang dapat dibedakan . Pertama, model kelas ini (jaringan saraf) menentukan state-of-the-art dalam banyak tugas, termasuk yang terkait dengan
analisis data teks . Kedua, kerangka kerja modern, dalam kasus saya
Apache MXNet , memungkinkan Anda untuk mengimplementasikan arsitektur yang sangat beragam. Oleh karena itu, Anda dapat bereksperimen dengan model yang berbeda dengan mengubah hanya beberapa baris kode.
Pekerjaan minimum dengan tanda . Saya ingin modelnya mudah diperluas dengan data baru. Ini mungkin diperlukan pada bagian penuh waktu, di mana akan ada sedikit waktu untuk mempersiapkan tanda-tanda. Oleh karena itu, saya menetapkan pendekatan paling sederhana untuk mengidentifikasi atribut:
- data biner diwakili oleh tag dengan nilai 1 atau 0;
- data numerik tetap seperti apa adanya atau tidak lagi dikategorikan ke dalam kategori;
- data kategori disajikan dengan embeddings.
Setelah memutuskan strategi umum, saya mulai mencoba berbagai model.
Evolusi model
Titik awalnya adalah pendekatan faktorisasi matriks, yang sering digunakan dalam tugas-tugas rekomendasi:
pi,j= sigma(ui cdotvj)
Kerugian(yi,j,pi,j) rightarrowminu,v
Dalam bahasa grafik komputasi, ini berarti bahwa perkiraan probabilitas bahwa pengguna
saya akan meletakkan "kelas" pada posting
j adalah sigmoid dari produk skalar embeddings dari pengidentifikasi pengguna dan pengidentifikasi pos. Hal yang sama dapat diungkapkan oleh diagram:

Model seperti itu tidak terlalu menarik: tidak menggunakan semua fitur, tidak terlalu berguna untuk pengidentifikasi frekuensi rendah, dan menderita masalah awal yang dingin. Tapi, setelah merumuskan tugas dalam bentuk grafik komputasi, kami "melepaskan ikatan tangan kami" dan sekarang dapat memecahkan masalah secara bertahap. Pertama-tama, untuk nilai frekuensi rendah, kami akan membuat satu-satunya penyematan
Kosakata . Selanjutnya, singkirkan kebutuhan untuk memiliki embeddings dari dimensi yang sama. Untuk melakukan ini, kami mengganti produk skalar dengan perceptron dangkal, yang menerima fitur gabungan sebagai input. Hasilnya disajikan dalam diagram:

Setelah kami menyingkirkan dimensi tetap, tidak ada yang mencegah kami untuk mulai menambahkan atribut baru. Mewakili posting dengan semua jenis karakteristik (bahasa, penulis, teks, ...), kami akan menyelesaikan masalah mulai dingin posting. Model akan belajar, misalnya, bahwa pengguna dengan
user_id = 42 menempatkan "kelas" pada tulisan dalam bahasa Rusia yang mengandung kata "karpet". Di masa mendatang, kami akan dapat merekomendasikan pengguna ini semua posting berbahasa Rusia tentang karpet, bahkan jika itu tidak muncul dalam data pelatihan. Untuk penyematan teks, untuk saat ini, kami hanya akan rata-rata embeddings dari kata-kata yang disertakan di dalamnya. Hasilnya, modelnya terlihat seperti ini:
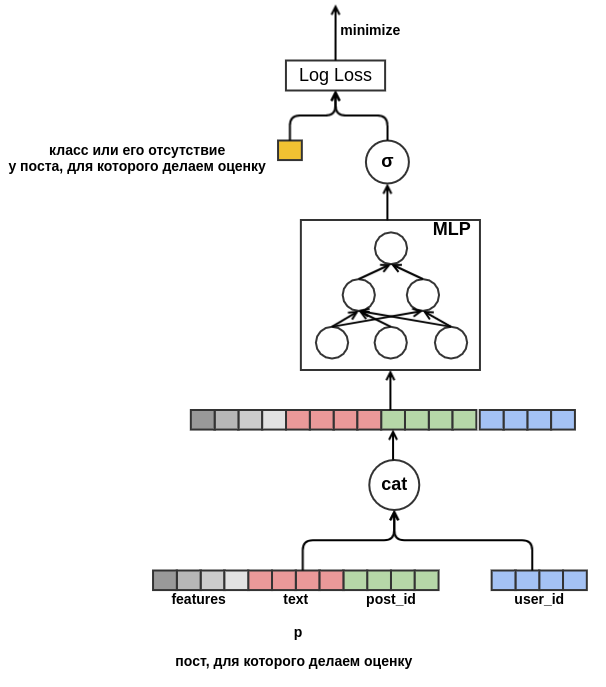
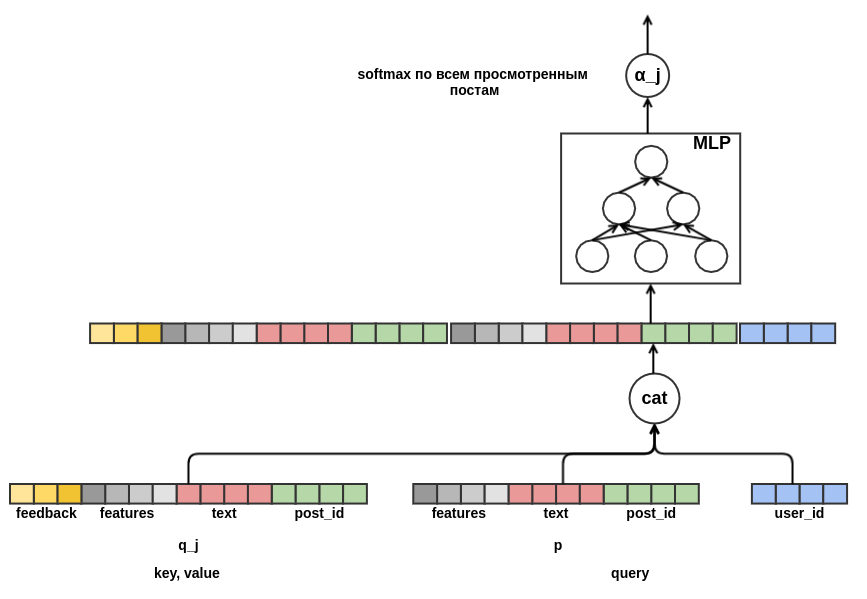
Akhirnya, saya ingin berurusan dengan awal yang dingin dari pengguna. Dimungkinkan untuk membuat fitur dari data historis pada pandangan pengguna atas tulisan. Pendekatan ini tidak memenuhi strategi yang dipilih: kami memutuskan untuk meminimalkan pembuatan atribut secara manual. Oleh karena itu, saya memberikan model dengan kesempatan untuk secara mandiri mempelajari presentasi pengguna dari urutan posting yang dilihat sebelum posting yang mana probabilitas "kelas" sedang dievaluasi. Tidak seperti posting yang dievaluasi, semua umpan balik diketahui untuk setiap posting dalam urutan. Ini berarti bahwa model akan memiliki akses ke informasi tentang apakah pengguna telah mengatur "posting" ke posting sebelumnya atau, sebaliknya, menghapusnya dari umpan.

Tetap memutuskan bagaimana menggabungkan urutan tulisan dengan panjang berbeda menjadi representasi dengan lebar tetap. Sebagai kombinasi seperti itu, saya menggunakan jumlah tertimbang dari representasi masing-masing posting. Pada bagan, pos bobot
j dilambangkan dengan
α_j . Bobot dihitung menggunakan mekanisme perhatian nilai kunci kueri, mirip dengan yang digunakan dalam
transformator atau
NMT . Dengan demikian, presentasi yang dipelajari pengguna juga dikonfigurasikan untuk pos di mana penilaian sedang dilakukan. Ini adalah bagian dari grafik yang bertanggung jawab untuk menghitung
α_j :
Setelah saya
merasakan nyanyian pesta pora, saya menjadi yakin akan efektivitas pendekatan perhatian, diputuskan untuk menggunakan perhatian dalam presentasi teks. Demi menghemat waktu dan besi, saya memutuskan untuk tidak menggunakan perhatian-diri seperti pada transformator yang sama, tetapi langsung melatih kata bobot dalam teks, seperti ini:
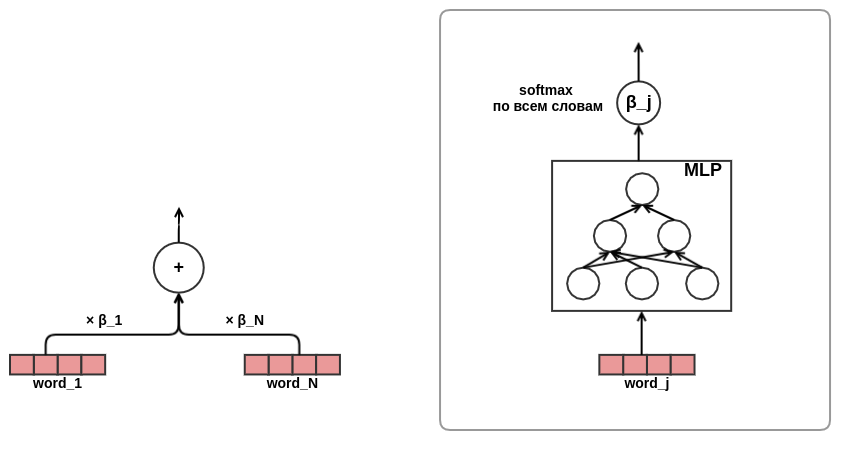
Pada ini, pengembangan arsitektur model selesai. Akibatnya, saya beralih dari faktorisasi matriks klasik ke model urutan yang agak rumit.
Hasil dan Analisis
Saya mengembangkan dan men-debug solusi saya di ketujuh dari data di laptop dengan memori 16 GB dan kartu grafis GeForce 930MX. Eksperimen data lengkap dijalankan pada server khusus dengan 256 GB memori dan kartu Tesla T4. Untuk optimasi, algoritma Adam dengan parameter default dari MXNet digunakan. Tabel menunjukkan hasil untuk model stripped-down - panjang urutan posting dibatasi hingga sepuluh. Dalam ajang kontes, saya menggunakan urutan panjang lima puluh.
Model
| Kehilangan log
| Peningkatan dari baris sebelumnya
| Waktu pelatihan
|
|---|
Acak
| 0,4374 ± 0,0009
| | |
Perceptron
| 0,4330 ± 0,0010
| 0,0043 ± 0,0002
| 7 mnt
|
Perceptron dengan tanda
| 0,4119 ± 0,0008
| 0,0212 ± 0,0003
| 44 mnt
|
Perceptron dengan urutan tulisan
| 0,3873 ± 0,0008
| 0,0247 ± 0,0003
| 4 jam 16 menit
|
Perceptron dengan urutan tulisan dan perhatian dalam teks
| 0,3874 ± 0,0008
| 0,0001 ± 0,0001
| 4 jam 43 menit
|
Baris terakhir ternyata menjadi yang paling tidak terduga bagi saya: menggunakan perhatian dalam presentasi teks tidak memberikan peningkatan yang terlihat dalam hasilnya. Saya mengharapkan jaringan perhatian untuk mempelajari bobot kata dalam teks, sesuatu seperti
idf . Mungkin ini tidak terjadi, karena panitia menghapus kata-kata penghentian di muka dan kata-kata yang kurang lebih penting tetap ada dalam daftar yang telah disiapkan. Oleh karena itu, penimbangan "pintar" tidak memberikan keuntungan nyata dibandingkan dengan rata-rata sederhana. Alasan lain yang mungkin adalah bahwa jaringan perhatian untuk kata-kata sangat kecil: hanya berisi satu lapisan tersembunyi yang sempit. Mungkin dia kurang memiliki kapasitas representasi untuk belajar sesuatu yang bermanfaat.
Mekanisme perhatian nilai kunci-permintaan memungkinkan Anda untuk melihat ke dalam model dan mencari tahu apa yang “diperhatikan” ketika membuat keputusan. Untuk menggambarkan hal ini, saya
memilih beberapa contoh:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
Baris pertama menunjukkan teks tulisan yang perlu dievaluasi, lalu tulisan yang dilihat sebelumnya dan skor perhatian yang sesuai. Dengan lega, kami memperhatikan bahwa model telah belajar untuk mengabaikan bantalan. Model menganggap posting sebagai yang paling penting tentang jenis-jenis jiwa dan tentang Windows. Perlu diingat bahwa perhatian dapat berupa positif (pengguna akan menanggapi posting tentang aura dengan cara yang sama seperti posting tentang jenis jiwa) atau negatif (kami mengevaluasi posting tentang aura - oleh karena itu, reaksi tidak akan sama dengan reaksi terhadap posting tentang teknologi). Contoh berikut adalah perhatian "dengan segala kemuliaan":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
Di sini, sang model dengan jelas melihat tema liburan musim panas. Bahkan anak-anak dan anak kucing pun pergi ke pinggir jalan. Contoh berikut menunjukkan bahwa menafsirkan perhatian tidak selalu memungkinkan. Kadang-kadang bahkan tidak ada yang jelas:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
Setelah melihat sejumlah daftar seperti itu, saya menyimpulkan bahwa model tersebut dapat mempelajari apa yang saya harapkan. Hal berikutnya yang saya lakukan adalah melihat embedding kata-kata. Dalam masalah kami, kami tidak dapat berharap bahwa embeddings akan menjadi seindah ketika mempelajari
model bahasa : kami mencoba untuk memprediksi variabel yang agak bising, di samping itu, kami tidak memiliki jendela konteks kecil - embeddings dari semua kata hanya dirata-ratakan tanpa memperhitungkan urutannya dalam teks. Contoh token dan tetangga terdekat mereka di ruang penyematan:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
Beberapa daftar ini mudah dijelaskan (program - bl), ada sesuatu yang membingungkan (iPhone - youki), tetapi secara umum, hasilnya kembali memenuhi harapan saya.
Kesimpulan
Saya suka pendekatan untuk membangun model berdasarkan grafik yang dapat dibedakan (
banyak yang setuju ). Hal ini memungkinkan Anda untuk keluar dari pemilihan fitur manual yang membosankan dan fokus pada perumusan masalah yang benar dan desain arsitektur yang menarik. Dan meskipun model saya hanya menempati posisi kedua dalam tugas teks SNA Hackathon 2019, saya cukup senang dengan hasil ini, mengingat kesederhanaannya dan opsi ekspansi yang hampir tidak terbatas. Saya yakin bahwa di masa depan akan ada model yang lebih menarik dan dapat diterapkan dalam sistem pertempuran berdasarkan ide yang sama.