Hari ini saya akan memberi tahu Anda bagaimana kami berhasil menyelesaikan masalah porting
Aplikasi Streaming Terstruktur ke
Kubernetes (K8s) dan mengimplementasikan streaming CI.
Bagaimana semuanya dimulai?
Streaming adalah komponen kunci dari platform FASTEN RUS BI. Data waktu nyata digunakan oleh tim analisis tanggal untuk membuat laporan operasional.
Aplikasi streaming diimplementasikan menggunakan
Spark Structured Streaming . Kerangka kerja ini menyediakan API transformasi data yang nyaman yang memenuhi kebutuhan kita dalam hal kecepatan perbaikan.
Streaming sendiri naik di
AWR EMR cluster. Jadi, ketika meningkatkan aliran baru ke cluster, skrip ssh diletakkan untuk mengirimkan Spark-jobs, setelah itu aplikasi diluncurkan. Dan pada awalnya semuanya tampak cocok untuk kita. Tetapi dengan meningkatnya jumlah aliran, kebutuhan untuk menerapkan streaming CI menjadi semakin jelas, yang akan meningkatkan otonomi perintah tanggal analisis ketika meluncurkan aplikasi untuk mengirimkan data pada entitas baru.
Dan sekarang kita akan melihat bagaimana kita berhasil menyelesaikan masalah ini dengan memindahkan streaming ke Kubernetes.
Kenapa Kubernetes?
Kubernetes, sebagai manajer sumber daya, paling sesuai dengan kebutuhan kita. Ini adalah penyebaran tanpa downtime, dan berbagai alat implementasi CI di Kubernetes, termasuk Helm. Selain itu, tim kami memiliki keahlian yang memadai dalam implementasi pipa CI pada K8. Karena itu, pilihannya jelas.
Bagaimana model manajemen aplikasi Spark berbasis Kubernetes diorganisasikan?

Klien menjalankan percikan-kirim pada K8s. Pod driver aplikasi dibuat. Penjadwal Kubernetes mengikat pod ke node cluster. Kemudian driver mengirim permintaan untuk membuat pod untuk menjalankan eksekutif, pod dibuat dan dilampirkan ke node cluster. Setelah itu, serangkaian operasi standar dilakukan dengan konversi kode aplikasi selanjutnya menjadi DAG, dekomposisi menjadi beberapa tahapan, dipecah menjadi tugas-tugas dan peluncurannya pada executable.
Model ini bekerja cukup berhasil ketika memulai aplikasi Spark secara manual. Namun, pendekatan peluncuran spark-submit di luar cluster tidak sesuai dengan kami dalam hal implementasi CI. Itu perlu untuk menemukan solusi yang akan memungkinkan Spark untuk menjalankan (melakukan percikan-kirim) langsung pada node cluster. Dan di sini model Operator Kubernetes sepenuhnya memenuhi persyaratan kami.
Operator Kubernetes sebagai Model Manajemen Siklus Hidup Aplikasi Spark
Operator Kubernetes adalah konsep mengelola aplikasi statefull di Kubernetes, yang diusulkan oleh
CoreOS , yang melibatkan otomatisasi tugas-tugas operasional, seperti menyebarkan aplikasi, memulai kembali aplikasi dalam kasus file, memperbarui konfigurasi aplikasi. Salah satu pola utama Operator Kubernetes adalah CRD (
CustomResourceDefinitions ), yang melibatkan penambahan sumber daya kustom ke kluster K8s, yang, pada gilirannya, memungkinkan Anda untuk bekerja dengan sumber daya ini seperti dengan objek Kubernetes asli.
Operator adalah daemon yang hidup di pod cluster dan merespons pembuatan / perubahan status sumber daya khusus.
Pertimbangkan konsep ini untuk manajemen siklus hidup aplikasi Spark.
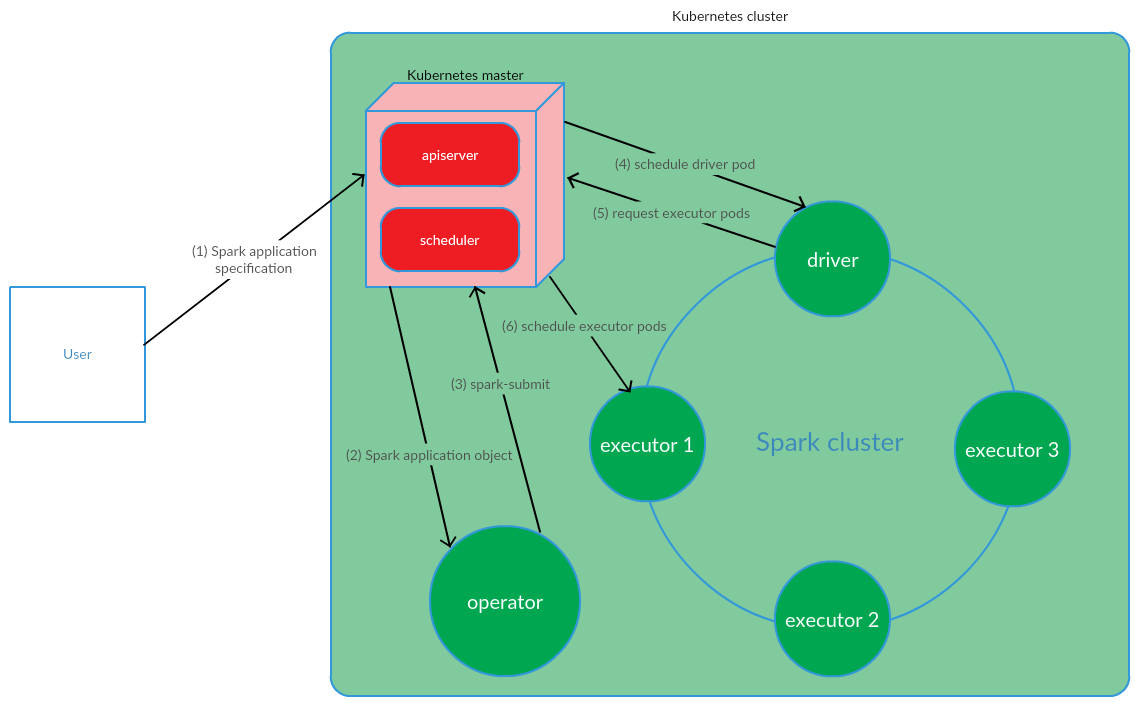
Pengguna menjalankan kubectl apply -f spark-application.yaml command, di mana spark-application.yaml adalah spesifikasi dari aplikasi Spark. Operator menerima objek aplikasi Spark dan menjalankan spark-submit.
Seperti yang dapat kita lihat, model Operator Kubernetes melibatkan pengelolaan siklus hidup aplikasi Spark secara langsung di kluster Kubernetes, yang merupakan argumen serius yang mendukung model ini dalam konteks memecahkan masalah kita.
Sebagai Operator Kubernetes untuk mengelola aplikasi streaming, diputuskan untuk menggunakan
operator spark-on-k8s . Operator ini menawarkan API yang cukup nyaman, serta fleksibilitas dalam mengonfigurasi kebijakan mulai ulang untuk aplikasi Spark (yang cukup penting dalam konteks mendukung aplikasi streaming).
Implementasi CI
Untuk menerapkan streaming CI,
GitLab CI / CD digunakan . Penyebaran aplikasi Spark di K8 dilakukan menggunakan alat
Helm .
Pipa itu sendiri melibatkan 2 tahap:
- tes - pemeriksaan sintaksis dilakukan, serta rendering dari Helm-templates;
- deploy - penyebaran aplikasi streaming ke lingkungan pengujian (dev) dan produk (prod).
Mari kita perhatikan tahapan-tahapan ini secara lebih rinci.
Pada tahap pengujian, template Helm aplikasi Spark (CRD -
SparkApplication )
diberikan dengan nilai-nilai khusus lingkungan.
Bagian utama dari Helm-template adalah:
- percikan:
- versi - versi Apache Spark
- image - Gambar Docker digunakan
- nodeSelector - berisi daftar (kunci → nilai) yang sesuai dengan label perapian.
- toleransi - menunjukkan daftar toleransi aplikasi Spark.
- mainClass - Kelas aplikasi Spark
- applicationFile - jalur lokal tempat jar aplikasi Spark berada
- restartPolicy - Kebijakan mulai ulang aplikasi Spark
- Tidak pernah - aplikasi Spark yang lengkap tidak restart
- Selalu - aplikasi Spark yang telah selesai dinyalakan ulang terlepas dari alasan pemberhentiannya.
- OnFailure - Aplikasi Spark me-restart hanya jika file
- maxSubmissionRetries - jumlah maksimum pengajuan aplikasi Spark
- driver / pelaksana:
- core - jumlah kernel yang dialokasikan untuk driver / pelaksana
- contoh (hanya digunakan untuk konfigurasi eksekutif) - jumlah eksekutif
- memori - jumlah memori yang dialokasikan untuk proses driver / pelaksana
- memoryOverhead - jumlah memori off-heap yang dialokasikan untuk driver / pelaksana
- stream:
- nama - nama aplikasi streaming
- argumen - argumen ke aplikasi streaming
- wastafel - jalur menuju dataset Data Lake di S3
Setelah merender template, aplikasi dikerahkan ke lingkungan pengujian dev menggunakan Helm.
Mengerjakan pipa CI.
Lalu kami meluncurkan pekerjaan deploy-prod - meluncurkan aplikasi dalam produksi.
Kami yakin kinerja pekerjaan yang sukses.
Seperti yang dapat kita lihat di bawah, aplikasi sedang berjalan, pod berada dalam status MENJALANKAN.

Kesimpulan
Porting Aplikasi Streaming Terstruktur Spark ke K8 dan implementasi CI selanjutnya memungkinkan kami untuk mengotomatiskan peluncuran stream untuk mengirimkan data ke entitas baru. Untuk meningkatkan aliran berikutnya, cukup untuk menyiapkan Permintaan Gabung dengan deskripsi konfigurasi aplikasi Spark dalam file nilai-nilai yaml dan ketika pekerjaan deploy-prod dimulai, pengiriman data ke Data Lake (S3) akan dimulai. Solusi ini memastikan otonomi perintah tanggal analisis ketika melakukan tugas yang berkaitan dengan menambahkan entitas baru ke repositori. Selain itu, porting streaming ke K8s, dan khususnya, mengelola aplikasi Spark menggunakan Operator Kubernetes spark-on-k8s-operator secara signifikan meningkatkan ketahanan streaming. Tetapi lebih lanjut tentang itu di artikel berikutnya.