Kami terlibat dalam pembelian lalu lintas dari Adwords (platform iklan dari Google). Salah satu tugas rutin di bidang ini adalah pembuatan spanduk baru. Pengujian menunjukkan bahwa spanduk kehilangan keefektifan seiring waktu, karena pengguna terbiasa dengan spanduk; Musim dan tren sedang berubah. Selain itu, kami memiliki tujuan untuk menangkap ceruk pemirsa yang berbeda, dan spanduk yang ditargetkan secara sempit berfungsi lebih baik.
Sehubungan dengan memasuki negara-negara baru, masalah lokalisasi spanduk muncul. Untuk setiap spanduk, Anda perlu membuat versi dalam bahasa yang berbeda dan dengan mata uang yang berbeda. Anda dapat meminta desainer untuk melakukan ini, tetapi pekerjaan manual ini akan menambah beban tambahan untuk sumber daya yang sudah langka.
Sepertinya tugas yang mudah diotomatisasi. Untuk melakukan ini, cukup membuat program yang akan membebankan pada spanduk kosong harga yang dilokalkan untuk "label harga" dan ajakan untuk bertindak (frasa seperti "beli sekarang") pada tombol. Jika mencetak teks dalam gambar cukup sederhana, maka menentukan di mana Anda harus meletakkannya tidak selalu sepele. Peppercorns menambahkan bahwa tombolnya hadir dalam warna berbeda, dan bentuknya sedikit berbeda.
Artikel ini didedikasikan untuk: bagaimana menemukan objek yang ditentukan dalam gambar? Metode populer akan disortir; Area aplikasi, fitur, pro dan kontra. Metode di atas dapat digunakan untuk tujuan lain: mengembangkan program untuk kamera keamanan, otomatisasi UI pengujian, dan sejenisnya. Kesulitan yang dijelaskan dapat ditemukan dalam tugas-tugas lain, dan metode yang digunakan dapat digunakan untuk tujuan lain. Sebagai contoh, Canny Edge Detector sering digunakan untuk preproses gambar, dan jumlah titik kunci dapat digunakan untuk mengevaluasi "kompleksitas" visual suatu gambar.
Saya harap solusi yang dijelaskan ini akan mengisi kembali alat dan trik Anda untuk menyelesaikan masalah.
Kode ini dalam Python 3.6 ( repositori ); Diperlukan pustaka OpenCV. Pembaca diharapkan memahami dasar-dasar aljabar linier dan visi komputer.
Kami akan fokus pada menemukan tombol itu sendiri. Kita akan ingat tentang menemukan label harga (karena menemukan persegi panjang juga dapat diselesaikan dengan cara yang lebih sederhana), tetapi hilangkan itu, karena solusi akan terlihat dengan cara yang sama.
Pencocokan template
Pikiran pertama yang terlintas dalam pikiran adalah mengapa tidak hanya memilih dan menemukan dalam gambar wilayah yang paling mirip dengan tombol dalam hal perbedaan warna piksel? Inilah yang membuat pencocokan templat - metode yang didasarkan pada menemukan ruang pada gambar yang paling mirip dengan templat. "Kesamaan" gambar didefinisikan oleh metrik tertentu. Yaitu, templat “ditumpangkan” pada gambar, dan perbedaan antara gambar dan templat dipertimbangkan. Posisi templat di mana perbedaan ini akan minimal, dan akan menunjukkan lokasi objek yang diinginkan.
Anda dapat menggunakan opsi yang berbeda sebagai metrik, misalnya, jumlah perbedaan kuadrat antara templat dan gambar (jumlah perbedaan kuadrat, SSD), atau gunakan korelasi silang (CCORR). Biarkan f dan g masing-masing menjadi gambar dan pola dengan dimensi (k, l) dan (m, n) (kita akan mengabaikan saluran warna untuk saat ini); i, j - posisi pada gambar yang kami "lampirkan" templat.
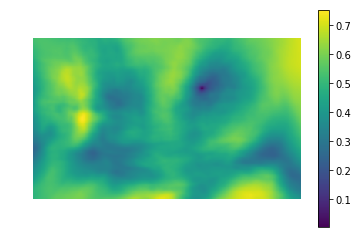
Mari kita coba menerapkan perbedaan kuadrat untuk menemukan anak kucing

Dalam gambar

(gambar diambil dari PETA Caring for Cats).
Gambar kiri adalah nilai metrik kesamaan tempat pada gambar dengan templat (mis., Nilai SSD untuk berbagai i, j). Area gelap adalah tempat di mana perbedaannya minimal. Ini adalah penunjuk ke tempat yang paling menyerupai templat - di gambar kanan tempat ini dilingkari.

Korelasi silang sebenarnya adalah konvolusi dua gambar. Konvolusi dapat diimplementasikan dengan cepat menggunakan transformasi Fourier cepat. Menurut teorema konvolusi, setelah transformasi Fourier, konvolusi berubah menjadi perkalian elemen sederhana:
Dimana - operator konvolusi. Dengan cara ini kita dapat dengan cepat menghitung korelasi silang. Ini memberikan keseluruhan kompleksitas O (kllog (kl) + mnlog (mn)) , dibandingkan O (klmn) ketika diimplementasikan secara langsung. Kuadrat perbedaan juga dapat direalisasikan menggunakan konvolusi, karena setelah kurung dibuka akan berubah menjadi perbedaan antara jumlah kuadrat dari nilai piksel gambar dan korelasi silang:
Detailnya bisa dilihat di presentasi ini.
Mari beralih ke implementasi. Untungnya, kolega dari departemen Intel Nizhny Novgorod merawat kami dengan membuat pustaka OpenCV, itu sudah mengimplementasikan pencarian templat menggunakan metode matchTemplate (omong-omong, ia menggunakan implementasi FFT, meskipun ini tidak disebutkan dalam dokumentasi), menggunakan metrik perbedaan yang berbeda :
- CV_TM_SQDIFF - jumlah kuadrat dari perbedaan nilai piksel
- CV_TM_SQDIFF_NORMED - jumlah kuadrat dari perbedaan warna, dinormalisasi ke kisaran 0..1.
- CV_TM_CCORR - jumlah produk elemen demi elemen dari segmen template dan gambar
- CV_TM_CCORR_NORMED - jumlah elemen berfungsi, dinormalisasi ke rentang -1..1.
- CV_TM_CCOEFF - korelasi silang gambar tanpa rata-rata
- CV_TM_CCOEFF_NORMED - korelasi silang antara gambar tanpa rata-rata, dinormalisasi ke -1..1 (korelasi Pearson)
Kami akan menggunakannya untuk menemukan anak kucing:

Dapat dilihat bahwa hanya TM_CCORR yang tidak mengatasi tugasnya. Ini bisa dimengerti: karena ini adalah produk skalar, nilai terbesar dari metrik ini adalah ketika membandingkan templat dengan persegi panjang putih.
Anda mungkin memperhatikan bahwa metrik ini membutuhkan pencocokan pola piksel-demi-piksel pada gambar yang diinginkan. Setiap penyimpangan gamma, cahaya atau ukuran akan menghasilkan metode yang tidak berfungsi. Biarkan saya mengingatkan Anda bahwa ini persis kasus kami: tombol dapat dari berbagai ukuran dan warna yang berbeda.
Masalah berbagai warna dan cahaya dapat diselesaikan dengan menerapkan filter deteksi tepi. Metode ini hanya menyisakan informasi tentang di mana dalam gambar ada perubahan warna yang tajam. Mari kita terapkan Canny Edge Detector (kami akan menganalisanya sedikit lebih jauh) ke tombol dengan warna dan kecerahan yang berbeda. Di sebelah kiri adalah spanduk asli, dan di sebelah kanan adalah hasil menerapkan filter Canny.

Dalam kasus kami, ada juga masalah ukuran yang berbeda, tetapi sudah diselesaikan. Transformasi log-polar mengubah gambar menjadi ruang di mana zoom dan rotasi akan muncul sebagai offset. Dengan menggunakan transformasi ini, kita dapat mengembalikan skala dan sudut. Setelah itu, dengan menskalakan dan memutar templat, Anda dapat menemukan posisi templat pada gambar asli. Anda juga dapat menggunakan FFT di seluruh prosedur ini, seperti yang dijelaskan dalam Teknik Berbasis FFT untuk Penerjemahan, Rotasi, dan Registrasi Gambar Invarian Skala . Dalam literatur, kasus ini dipertimbangkan ketika pola horizontal dan vertikal diubah secara proporsional, sedangkan faktor skala bervariasi dalam batas kecil (2.0 ... 0.8). Sayangnya, mengubah ukuran tombol bisa menjadi besar dan tidak proporsional, yang dapat menyebabkan hasil yang salah.
Kami menerapkan konstruksi yang dihasilkan (Canny filter, hanya mengembalikan skala melalui transformasi log-polar, mendapatkan posisi melalui menemukan tempat dengan perbedaan kuadrat minimum), untuk menemukan tombol dalam tiga gambar. Kami akan menggunakan tombol kuning besar sebagai templat:

Pada saat yang sama, tombol pada spanduk akan terdiri dari berbagai jenis, warna, dan ukuran:

Dalam hal mengubah ukuran tombol, metode ini tidak berfungsi dengan benar. Hal ini disebabkan oleh fakta bahwa metode ini melibatkan pengubahan ukuran tombol dalam jumlah yang sama baik secara horizontal maupun vertikal. Namun, ini tidak selalu terjadi. Pada gambar kanan, ukuran tombol tidak berubah secara vertikal, tetapi secara horizontal telah sangat menurun. Jika ukurannya terlalu besar, distorsi yang disebabkan oleh transformasi log-polar membuat pencarian menjadi tidak stabil. Dalam hal ini, metode ini tidak dapat mendeteksi tombol dalam kasus ketiga.
Deteksi keypoint
Anda dapat mencoba pendekatan yang berbeda: alih-alih mencari seluruh tombol, mari temukan bagian-bagiannya yang khas, misalnya, sudut tombol, atau elemen pembatas (ada goresan dekoratif di sepanjang kontur tombol). Tampaknya menemukan sudut dan perbatasan lebih mudah, karena ini adalah benda kecil (dan karenanya sederhana). Apa yang terletak di antara empat sudut dan perbatasan akan menjadi tombol. Kelas metode untuk menemukan titik kunci disebut "deteksi titik kunci", dan algoritma untuk membandingkan dan mencari gambar menggunakan titik kunci disebut "pencocokan titik kunci". Mencari suatu pola dalam gambar dimulai dengan menerapkan algoritme untuk mendeteksi titik-titik kunci pada suatu pola dan gambar, dan membandingkan titik-titik kunci dari suatu pola dan gambar.
Biasanya "titik kunci" secara otomatis ditemukan dengan menemukan piksel yang sekelilingnya memiliki properti tertentu. Banyak metode dan kriteria untuk menemukan mereka diciptakan. Semua algoritma ini adalah heuristik yang menemukan beberapa elemen gambar karakteristik, sebagai aturan - sudut atau perubahan warna yang tajam. Detektor yang baik harus bekerja dengan cepat dan tahan terhadap transformasi gambar (saat mengubah gambar, poin-poin utama tidak boleh berhenti / bergerak).
Detektor sudut Harris
Salah satu algoritma yang paling mendasar adalah detektor sudut Harris . Untuk gambar (selanjutnya kami menganggap bahwa kami beroperasi dengan "intensitas" - gambar yang diterjemahkan ke dalam skala abu-abu), ia mencoba menemukan titik di sekitar di mana perbedaan intensitas lebih besar dari ambang batas tertentu. Algoritma terlihat seperti ini:
Dari intensitas adalah turunan sepanjang sumbu x dan y ( dan masing-masing). Mereka dapat ditemukan, misalnya, dengan menerapkan filter Sobel.
Untuk piksel, pertimbangkan persegi persegi dan bekerja dan . Beberapa sumber menyebut mereka sebagai , dan - yang tidak menambah kejelasan, karena orang mungkin berpikir bahwa ini adalah turunan kedua dari intensitas (dan ini tidak demikian).
Untuk setiap piksel, kami mempertimbangkan jumlah dalam lingkungan tertentu (lebih dari 1 piksel) dengan karakteristik berikut:
Seperti dalam Deteksi Templat, prosedur untuk jendela besar ini dapat dilakukan secara efisien menggunakan teorema konvolusi.
Untuk setiap piksel, hitung nilainya heuristik R
Nilai dipilih secara empiris dalam kisaran [0,04, 0,06] Jika beberapa piksel memiliki ambang tertentu, kemudian lingkungan piksel ini mengandung sudut, dan kami menandainya sebagai titik kunci.
Formula sebelumnya dapat membuat kelompok titik-titik kunci yang terletak bersebelahan, dalam hal ini layak untuk dihilangkan. Ini dapat dilakukan dengan memeriksa setiap titik apakah memiliki nilai maksimum di antara tetangga terdekat. Jika tidak, maka titik kunci disaring. Prosedur ini disebut penindasan non-maksimal .
Formula dipilih karena suatu alasan. - komponen tensor struktural - matriks yang menggambarkan perilaku gradien di lingkungan:
H = \ begin {pmatrix} A & C \\ C & B \ end {pmatrix}
Matriks ini mirip dalam banyak hal dengan matriks kovariannya. Sebagai contoh, keduanya adalah matriks semidefinit positif, tetapi kesamaannya tidak terbatas pada hal ini. Biarkan saya mengingatkan Anda bahwa matriks kovarians memiliki interpretasi geometris. Vektor eigen dari matriks kovarians menunjukkan arah varians terbesar dari sumber data (di mana kovarians dihitung), dan nilai-nilai eigen menunjukkan hamburan sepanjang sumbu:

Gambar diambil dari http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/
Nilai eigen dari tensor struktural juga berperilaku dengan cara yang sama: mereka menggambarkan penyebaran gradien. Pada permukaan yang datar, nilai eigen dari tensor struktural akan kecil (karena penyebaran gradien itu sendiri akan kecil). Nilai eigen dari tensor struktural yang dibangun di atas selembar gambar dengan wajah akan sangat bervariasi: satu bilangan akan besar (dan sesuai dengan vektornya sendiri yang diarahkan tegak lurus ke wajah), dan yang kedua akan kecil. Pada tensor sudut, kedua nilai eigen akan menjadi besar. Berdasarkan ini, kita dapat membangun heuristik ( Apakah nilai eigen dari tensor struktural).
Nilai heuristik ini akan besar ketika kedua nilai eigen itu besar.
Jumlah nilai eigen adalah jejak matriks, yang dapat dihitung sebagai jumlah elemen pada diagonal (dan jika Anda melihat rumus A dan B, menjadi jelas bahwa ini juga jumlah kuadrat dari panjang gradien di wilayah tersebut):
Produk dari nilai eigen adalah penentu matriks, yang juga mudah ditulis dalam kasus 2x2:
Dengan demikian, kita dapat menghitung secara efektif , mengekspresikannya dalam hal komponen tensor struktural.
Cepat
Metode Harris bagus, tetapi ada banyak alternatif untuk itu. Kami tidak akan mempertimbangkan semuanya dengan cara yang sama seperti metode di atas, kami hanya akan menyebutkan beberapa yang populer untuk menunjukkan trik yang menarik dan membandingkannya dalam aksi.

Piksel diverifikasi oleh algoritma FAST
Alternatif untuk metode Harris adalah FAST . Seperti namanya, FAST jauh lebih cepat daripada metode di atas. Algoritma ini mencoba untuk menemukan titik-titik yang terletak di tepi dan sudut objek, yaitu di tempat-tempat perbedaan kontras. Lokasi mereka adalah sebagai berikut: FAST membangun lingkaran jari-jari R di sekitar piksel kandidat dan memeriksa untuk melihat apakah ia memiliki segmen berkelanjutan dari piksel dengan panjang t yang lebih gelap (atau lebih terang) dari piksel kandidat oleh unit K. Jika kondisi ini terpenuhi, maka piksel dianggap sebagai "titik kunci". Untuk t tertentu, kita dapat mengimplementasikan heuristik ini secara efisien dengan menambahkan beberapa pemeriksaan pendahuluan yang akan memotong piksel yang dijamin non-sudut. Misalnya kapan dan , cukup untuk memeriksa apakah ada 3 piksel berurutan di antara 4 piksel ekstrim yang benar-benar lebih gelap / lebih terang dari pusat pada K (dalam gambar - 1, 5, 9, 13). Kondisi ini memungkinkan Anda untuk secara efektif memotong kandidat yang jelas bukan poin kunci.
SIFT
Kedua algoritma sebelumnya tidak tahan untuk mengubah ukuran gambar. Mereka tidak memungkinkan Anda menemukan templat dalam gambar jika skala objek telah diubah. SIFT (Transformasi fitur Invarian-Skala) menawarkan solusi untuk masalah ini. Ambil gambar dari mana kita mengekstrak titik-titik kunci, dan mulai secara bertahap mengurangi ukurannya dengan beberapa langkah kecil, dan untuk setiap opsi skala kita akan menemukan titik-titik kunci. Penskalaan adalah prosedur yang sulit, tetapi menguranginya dengan 2/4/8 / ... kali dapat dilakukan secara efisien dengan melewatkan piksel (dalam SIFT beberapa skala ini disebut "oktaf"). Skala menengah dapat diperkirakan dengan menerapkan Gaussian bluer dengan ukuran inti yang berbeda pada gambar. Seperti yang kami jelaskan di atas, ini dapat dilakukan secara efisien secara komputasi. Hasilnya akan terlihat seperti jika kita mengurangi gambar terlebih dahulu dan kemudian memperbesarnya ke ukuran aslinya - detail kecil hilang, gambar menjadi "kabur".
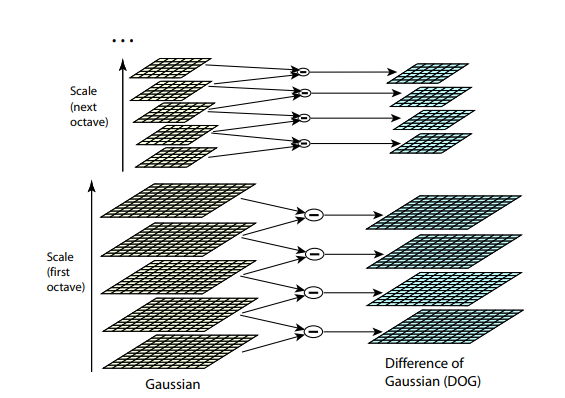
Setelah prosedur ini, kami menghitung perbedaan antara skala tetangga. Nilai besar (dalam nilai absolut) dalam perbedaan ini akan berubah jika beberapa detail kecil tidak lagi terlihat pada skala skala berikutnya, atau, sebaliknya, skala skala berikutnya mulai menangkap beberapa bagian yang tidak terlihat pada bagian sebelumnya. Teknik ini disebut DoG, Difference of Gaussian. Kita dapat mengasumsikan bahwa kepentingan terbesar dalam perbedaan ini sudah merupakan sinyal bahwa ada sesuatu yang menarik pada gambar ini. Tetapi kami tertarik pada skala yang titik kunci ini paling ekspresif. Untuk melakukan ini, kami akan mempertimbangkan titik kunci tidak hanya sebagai titik yang berbeda dari lingkungannya, tetapi juga berbeda paling kuat di antara skala gambar yang berbeda. Dengan kata lain, kita akan memilih titik kunci tidak hanya di ruang X dan Y, tetapi di ruang . Dalam SIFT, ini dilakukan dengan menemukan poin dalam DoG (Perbedaan Gaussians), yang merupakan tertinggi atau terendah lokal di kubus ruang di sekelilingnya:
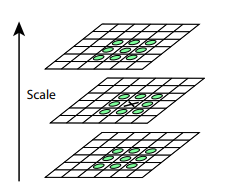
Algoritma untuk menemukan poin-poin utama dan membangun deskriptor SIFT dan SURF telah dipatenkan. Artinya, untuk penggunaan komersial mereka perlu mendapatkan lisensi. Itu sebabnya mereka tidak tersedia dari paket opencv utama, tetapi hanya dari paket opencv_contrib yang terpisah. Namun, sejauh ini penelitian kami bersifat akademis murni, oleh karena itu, tidak ada yang menghalangi kami untuk berpartisipasi dalam SIFT sebagai perbandingan.
Penjelas
Mari kita coba menerapkan beberapa jenis detektor (misalnya, Harris) ke template dan gambar.


Setelah menemukan titik-titik utama dalam gambar dan templat, Anda perlu membandingkannya satu sama lain. Biarkan saya mengingatkan Anda bahwa sejauh ini kami hanya mengekstraksi posisi poin-poin penting. Apa artinya titik ini (misalnya, ke arah mana sudut yang ditemukan diarahkan), kita belum menentukan. Dan deskripsi semacam itu dapat membantu saat membandingkan titik dan pola gambar satu sama lain. Beberapa titik templat dalam gambar dapat digeser oleh distorsi, ditutupi oleh objek lain, jadi hanya mengandalkan posisi titik-titik relatif satu sama lain tampaknya tidak dapat diandalkan. Oleh karena itu, mari kita ambil lingkungan untuk setiap titik kunci untuk membangun deskripsi (deskriptor) tertentu, yang kemudian memungkinkan kita untuk mengambil beberapa poin (satu titik dari templat, satu dari gambar), dan membandingkan kesamaannya.
SINGKAT
(.. 0 1), , XOR , . ? , N . , i- , , — i- 1. N. - (, — ), : , “”. , ( ). BRIEF .

. . , GII .
, , (.. , , ). OpenCV .
SIFT
SIFT , . SIFT 1616 , 44 . ( , ). 8 (, -, , ..). — 8 , , . . , 8- . 128 ( 4*4 = 16 , 8 ). .
Perbandingan
( — , ), - :

— . ?
, . , , . , , , , . ? BRIEF, , , . , BRIEF 1/16 . SIFT — - 1/4 .
SIFT.
Sekarang kami menerapkan semua pengetahuan yang diperoleh untuk menyelesaikan masalah kami. Dalam kasus kami, persyaratan untuk detektor titik kunci sudah cukup: kita tidak perlu invarian untuk mengubah ukuran, serta kinerja yang sangat tinggi. Bandingkan ketiga detektor.
| Detektor sudut Harris | Cepat | SIFT |
|---|
 |  |  |
 |  |  |
 |  |  |
SIFT menemukan sangat sedikit poin kunci pada tombol. Ini dapat dimengerti - tombolnya adalah objek yang cukup kecil dan datar, dan pembesaran tidak membantu untuk menemukan titik kunci.
Juga, tidak ada satu pun detektor yang mengelola kasus ketiga. Ini bisa dijelaskan dan diharapkan. Biasanya, metode di atas digunakan untuk menemukan objek dari templat dalam gambar yang sebagiannya dapat disembunyikan, diputar, atau sedikit terdistorsi. Dalam kasus kami, kami ingin menemukan bukan objek yang persis sama , tetapi objek yang sangat mirip dengan templat (tombol) . Ini adalah tugas yang sedikit berbeda. Jadi, mengubah bentuk tombol itu sendiri (misalnya, jari-jari pembulatan sudut, atau ketebalan bingkai titik) mengubah titik kunci di dalamnya, dan deskriptornya. Selain itu, titik-titik kunci akan terletak di sudut tombol. Karena posisi di tepi, titik-titiknya akan tidak stabil: lokasi tepatnya dan deskriptornya dipengaruhi oleh apa yang digambarkan di sebelah tombol.
Kesimpulan - metode ini baik, dan memenuhi situasi dengan benar ketika objek yang diinginkan diputar, ukurannya diubah, atau objek disembunyikan sebagian (yang baik untuk menemukan objek yang kompleks, atau label harga, misalnya). Namun, jika ada beberapa titik pada objek yang dapat "ditangkap", atau bentuk objek berubah terlalu banyak, maka titik kunci dan mereka pada template dan gambar mungkin tidak bersamaan. Juga, latar belakang dengan banyak detail kecil dapat menggeser "poin utama" atau mengubah deskriptornya.
Kami dapat menemukan pertandingan yang menggunakan koordinat poin-poin penting. Alih-alih mencari pasangan poin pada template dan gambar, lingkungan yang serupa, Anda dapat mencari set poin tersebut, penempatan titik-titik kunci pada template dan gambar akan serupa. Dalam kasus umum, ini adalah tugas yang agak rumit (baik secara komputasi maupun dari sudut pandang pemrograman), terutama dalam situasi di mana beberapa titik mungkin bergeser atau tidak ada. Tetapi, mengingat bahwa kita memiliki poin utama - sudut, cukup bagi kita untuk menemukan grup yang secara kasar akan membentuk persegi panjang dari proporsi yang diinginkan, dan di dalamnya tidak akan ada poin kunci. Secara bertahap kami sampai pada metode berikut:
Deteksi kontur
Biasanya tombol adalah semacam objek persegi panjang (kadang-kadang dengan sudut bulat), yang sisi-sisinya sejajar dengan sumbu koordinat. Kemudian mari kita coba untuk membedakan zona perbedaan kontras (tepi), dan di antara mereka kita akan menemukan wajah yang garis besarnya mirip dengan garis besar objek yang kita butuhkan. Metode ini disebut deteksi kontur.
Deteksi tepi
Tidak seperti deteksi keypoint, kami tertarik tidak hanya sudut titik kunci, tetapi juga tepi. Namun, ide dasar bisa kita ambil dari sana. Menghaluskan gambar dengan filter Gaussian, dan seperti di detektor sudut Harris. Lalu kami menghitung turunan dari intensitas dan . Karena kita tidak perlu membedakan sudut dari tepi, kita tidak perlu mempertimbangkan tensor struktural - cukup untuk menghitung kekuatan gradien: (Omong-omong, ini adalah akar dari , atau dari jumlah diagonal dari tensor struktural). Setelah itu, kami hanya menyisakan piksel yang merupakan maksimal lokal dalam hal (menggunakan penindasan non-maksimum yang sudah dianggap), tetapi sebagai lokal kami akan memilih bukan 8 piksel tetangga, tetapi piksel dari 8 ini, yang saya arahkan, dan dari sisi yang berlawanan:
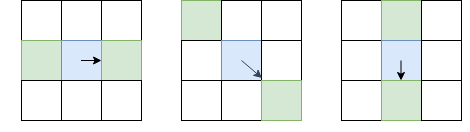
Pixel yang dimaksud adalah biru, panahnya adalah arah I. Pixel hijau adalah yang akan diperhitungkan selama penindasan yang tidak maksimal.
Pilihan piksel yang tidak biasa untuk perbandingan ini disebabkan oleh kenyataan bahwa kami tidak ingin membuat celah di perbatasan. Dalam gambar kiri, wajah bergerak dari atas ke bawah, dan karena penindasan yang tidak maksimal tidak akan membandingkan intensitas dengan piksel di atas dan di bawah biru, kami mendapatkan wajah yang berkelanjutan.
Jelas, satu penindasan non-maksimum tidak cukup, dan Anda perlu menerapkan semacam penyaringan untuk menghilangkan tepi dengan Il terlalu rendah. Untuk melakukan ini, kami menerapkan teknik "ambang ganda": kami menghapus semua piksel dengan Il, dengan kekuatan gradien di bawah ambang Rendah, dan menetapkan semua piksel di atas ambang tinggi untuk menjadi "tepi yang kuat". Piksel di mana kekuatan gradien terletak di antara Rendah dan Tinggi akan disebut "tepi lemah", kami hanya meninggalkannya jika terhubung ke "tepi kuat":
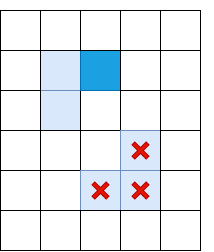
Biru muda menunjukkan "tulang rusuk lemah", biru tua - kuat. Tulang rusuk di bagian bawah diayak, karena tidak terhubung ke tulang rusuk yang kuat.
Kami baru saja menggambarkan Canny Edge Detector. Ini sangat banyak digunakan hingga hari ini sebagai prosedur sederhana dan cepat yang memungkinkan Anda untuk menemukan kontur benda.
Pelacakan perbatasan
Tindakan selanjutnya adalah memilih kontur di antara peta dengan wajah yang ditemukan. Temukan komponen terkait (pulau piksel yang berdekatan yang telah melewati semua pemeriksaan), dan periksa masing-masing, seberapa mirip sebuah tombol. Setelah menerapkan penindasan non-maksimum di Canny, kami memiliki jaminan bahwa tepiannya akan setebal satu piksel, tetapi mari kita mengandalkannya. Untuk setiap piksel yang ditetapkan ke wajah, dan di sebelahnya ada piksel non-wajah, kami menetapkannya ke "batas". Pindah dari satu piksel perbatasan ke yang lain, kami kembali ke piksel yang sama (dan kemudian kami menemukan garis besarnya), atau ke jalan buntu (maka Anda dapat mencoba untuk kembali jika ada garpu di suatu tempat di sepanjang jalan):

Algoritma pelacakan perbatasan penuh, dengan mempertimbangkan kasus tepi yang berbeda (misalnya, ketika sebuah objek dengan wajah tebal menghasilkan dua kontur, internal dan eksternal), dijelaskan di sini . Setelah menerapkan algoritma ini, kami akan memiliki serangkaian kontur yang berpotensi menjadi tombol.
Penyaringan Path
Bagaimana cara mengetahui bahwa sirkuit kita adalah sebuah tombol? Untuk persegi panjang dan poligon ada> metode yang sangat baik berdasarkan penyederhanaan garis besar . Cukup untuk "merobohkan" tulang rusuk secara bertahap, jika mereka hampir berada di garis lurus, dan kemudian menghitung jumlah tulang rusuk yang tersisa dan memeriksa sudut di antara mereka. Sayangnya, untuk kasus kami metode ini tidak cocok - persegi panjang kami memiliki sudut membulat. Juga, ada pencocokan garis untuk gambar dengan geometri kompleks - tetapi ini juga bukan tentang kita, karena kita hanya memiliki persegi panjang (contoh dengan garis besar manusia diberikan dalam artikel). Oleh karena itu, lebih baik membuat filter berdasarkan sifat-sifat gambar itu sendiri. Kita tahu itu:
- Tombolnya cukup besar (luas lebih dari 100 piksel)
- Sisi-sisinya sejajar dengan sumbu koordinat
- Rasio area gambar ke area persegi panjang yang terikat harus cukup dekat dengan persatuan. Kami menetapkan ambang batas ke 0,8, karena tombol adalah persegi panjang dengan sisi yang sejajar dengan sumbu koordinat, dan 20% yang hilang adalah sudut bulat.
Selain itu, dari pengalaman menggunakan detektor titik kunci, kami ingat bahwa mungkin ada masalah dengan situasi ketika ada objek kontras di bawah tombol. Karena itu, setelah menerapkan Canny, kami mengaburkan tepi untuk menutup lubang kecil yang bisa timbul dari benda-benda tersebut.
Kami menerapkan pendekatan yang dihasilkan:

Aplikasi Canny filter (gambar 2) menemukan bentuk yang diperlukan, tetapi karena bentuk kompleks tombol dan gradien, banyak kontur ditemukan sekaligus, dan karena penindasan non-max beberapa dari mereka tidak ditutup. Menerapkan blur (3 gambar) memperbaiki masalah.
Pendekatan pengujian
Jalankan pencarian kontur di gambar yang dihasilkan. Warnai kontur yang lulus uji merah. Jika ada beberapa dari mereka, maka kita perlu memilih opsi yang paling sukses di antara mereka. Kami memilih garis besar area terbesar, dan mengecatnya dengan warna hijau.
|  |
|  |
|  |
|
Desain yang dihasilkan menemukan tombol pada gambar uji. Tanda pada semua spanduk menunjukkan bahwa kadang-kadang (1 case dari ~ 20), alih-alih sebuah tombol, ia memilih ubin persegi panjang iOS Appstore dan Google Apps, atau objek persegi panjang lainnya (case telepon). Oleh karena itu, dengan menambahkan kemampuan untuk secara manual menunjukkan posisi dalam kasus yang jarang dari penentuan yang salah, kami menerapkan opsi ini di alat pelokalan.
Kesimpulan
Untuk meringkas. CV "klasik" tanpa pembelajaran mendalam masih berfungsi, dan berdasarkan itu Anda dapat memecahkan masalah. Mereka bersahaja dan tidak memerlukan sejumlah besar data yang ditandai, perangkat keras yang kuat, dan lebih mudah untuk di-debug. Namun, mereka memperkenalkan asumsi tambahan, dan karenanya dengan bantuan mereka tidak setiap masalah dapat diselesaikan secara efektif.
- Pencocokan Templat adalah cara termudah, berdasarkan pada menemukan tempat di gambar yang paling mirip (dengan beberapa metrik sederhana) dengan templat. Efektif dengan pencocokan piksel demi piksel. Itu bisa dibuat tahan terhadap tikungan dan perubahan kecil dalam ukuran, tetapi dengan perubahan besar itu mungkin tidak berfungsi dengan benar.
- Deteksi / pencocokan titik kunci - temukan titik kunci, cocokkan dengan titik gambar dan templat. Detektor tahan terhadap rotasi, zoom (tergantung pada detektor dan deskriptor yang dipilih), dan cocok - untuk tumpang tindih sebagian. Tetapi metode ini hanya berfungsi dengan baik jika ada cukup "titik kunci" pada objek, dan lokasi templat dan titik gambar bertepatan cukup baik (yaitu, objek yang sama pada templat dan gambar).
- Deteksi kontur - menemukan kontur objek, dan menemukan kontur yang mirip dengan kontur objek yang diinginkan. Solusi ini hanya memperhitungkan bentuk objek, dan mengabaikan konten dan warnanya (yang bisa berupa plus dan minus).
Pembaca yang berpengetahuan luas mungkin memperhatikan bahwa masalah kita dapat dipecahkan dengan bantuan metode penglihatan komputer terlatih modern. Misalnya, jaringan YOLO mengembalikan kotak pembatas dari objek yang diinginkan - dan inilah yang menarik minat kami. Ya, kami berhasil menguji dan meluncurkan solusi berdasarkan pembelajaran mendalam - tetapi sebagai iterasi kedua (sudah setelah alat pelokalan diluncurkan dan mulai bekerja). Solusi ini lebih tahan terhadap perubahan parameter tombol, dan memiliki banyak sifat positif: misalnya, alih-alih mengambil ambang dan parameter dengan tangan Anda, Anda dapat menambahkan contoh spanduk yang kesalahan jaringan (Pembelajaran Aktif) dalam set pelatihan. Menggunakan pembelajaran yang mendalam untuk tugas kita memiliki masalah dan poin menarik. Misalnya, banyak metode penglihatan komputer modern membutuhkan gambar mark-up dalam jumlah besar, tetapi kami tidak memiliki markup (seperti dalam banyak kasus nyata), dan jumlah total spanduk yang berbeda tidak melebihi beberapa ribu. Oleh karena itu, kami memutuskan untuk membuat sendiri sejumlah kecil gambar, dan menulis generator yang akan membuat spanduk serupa lainnya atas dasar gambar. Dalam arah ini ada banyak trik menarik . Ada banyak perangkap lain, dan tugas menentukan posisi objek visi komputer sangat luas, dan memiliki banyak solusi. Oleh karena itu, diputuskan untuk membatasi bidang pandang artikel, dan keputusan berdasarkan pembelajaran yang mendalam tidak dipertimbangkan.
Kode dengan notes yang menerapkan metode yang dijelaskan dan menggambar gambar artikel dapat ditemukan di repositori ).