Halo, Habr!
Saya bekerja untuk perusahaan game yang mengembangkan game online. Saat ini, semua permainan kami dibagi menjadi banyak "pasar" (satu "pasar" per negara) dan di setiap "pasar" ada selusin dunia di mana para pemain didistribusikan selama pendaftaran (baik, atau kadang-kadang mereka dapat memilih sendiri). Setiap dunia memiliki satu basis data dan satu atau lebih server web / aplikasi. Dengan demikian, bebannya dibagi dan didistribusikan di seluruh dunia / server hampir secara merata dan sebagai hasilnya, kami mendapatkan online maksimum dari pemain 6K-8K (ini adalah jumlah maksimum, kebanyakan beberapa kali lebih sedikit) dan 200-300 permintaan per waktu "perdana" untuk satu dunia.
Struktur seperti ini dengan pembagian pemain ke pasar dan dunia menjadi usang, pemain menginginkan sesuatu yang global. Dalam pertandingan terakhir, kami berhenti membagi orang berdasarkan negara dan hanya menyisakan satu / dua pasar (Amerika dan Eropa), tetapi masih dengan banyak dunia di masing-masingnya. Langkah selanjutnya adalah pengembangan game dengan arsitektur baru dan penyatuan semua pemain dalam satu dunia dengan
satu basis data .
Hari ini saya ingin berbicara sedikit tentang bagaimana saya ditugaskan memeriksa bagaimana jika keseluruhan online (dan itu adalah 50-200 ribu pengguna sekaligus) dari salah satu game populer kami “kirim” untuk memainkan game berikutnya yang dibangun di atas arsitektur baru dan apakah seluruh sistem, terutama database (
PostgreSQL 11 ) secara praktis dapat menahan beban seperti itu dan, jika tidak, cari tahu di mana maksimum kami. Saya akan memberi tahu Anda sedikit tentang masalah yang muncul dan keputusan untuk mempersiapkan pengujian banyak pengguna, proses itu sendiri, dan sedikit tentang hasilnya.
Intro
Di masa lalu, di
InnoGames GmbH, setiap tim game membuat proyek game sesuai dengan selera dan warna mereka, seringkali menggunakan berbagai teknologi, bahasa pemrograman, dan basis data. Selain itu, kami memiliki banyak sistem eksternal yang bertanggung jawab untuk pembayaran, mengirimkan pemberitahuan push, pemasaran, dan lainnya. Untuk bekerja dengan sistem ini, pengembang juga menciptakan antarmuka unik mereka sebaik mungkin.
Saat ini di bisnis game mobile banyak
uang dan, karenanya, banyak persaingan. Sangat penting di sini untuk mendapatkannya kembali dari setiap dolar yang dihabiskan untuk pemasaran dan sedikit lebih banyak dari atas, oleh karena itu semua perusahaan game sangat sering "menutup" game bahkan pada tahap pengujian tertutup, jika mereka tidak memenuhi ekspektasi analitis. Dengan demikian, kehilangan waktu pada penemuan roda berikutnya tidak menguntungkan, sehingga diputuskan untuk membuat platform terpadu yang akan memberikan pengembang solusi siap pakai untuk integrasi dengan semua sistem eksternal, database dengan replikasi dan semua praktik terbaik. Yang dibutuhkan pengembang adalah mengembangkan dan "menempatkan" game yang bagus di atas ini dan tidak membuang waktu untuk pengembangan yang tidak terkait dengan game itu sendiri.
Platform ini disebut
GameStarter :

Jadi, to the point. Semua game InnoGames di masa depan akan dibangun di platform ini, yang memiliki dua database - master dan game (PostgreSQL 11). Master menyimpan informasi dasar tentang para pemain (login, kata sandi, dll.) Dan berpartisipasi, terutama, hanya dalam proses login / registrasi dalam game itu sendiri. Game - database game itu sendiri, di mana, dengan demikian, semua data game dan entitas disimpan, yang merupakan inti dari game, di mana seluruh beban akan pergi.
Dengan demikian, timbul pertanyaan apakah seluruh struktur ini dapat bertahan dari jumlah pengguna yang potensial yang sama dengan online maksimum dari salah satu permainan kami yang paling populer.
Tantangan
Tugasnya sendiri adalah ini: untuk memeriksa apakah database (PostgreSQL 11), dengan replikasi yang diaktifkan, dapat menahan semua beban yang saat ini kami miliki dalam gim yang paling banyak dimuat, dengan memiliki seluruh hypervisor PowerEdge M630 (HV).
Saya akan mengklarifikasi bahwa tugas saat ini
hanya untuk memverifikasi , menggunakan konfigurasi basis data yang ada, yang kami bentuk dengan mempertimbangkan praktik terbaik dan pengalaman kami sendiri.
Saya akan segera mengatakan databasenya, dan seluruh sistem menunjukkan dirinya dengan baik, dengan pengecualian beberapa poin. Tetapi proyek game khusus ini berada pada tahap prototipe dan di masa depan, dengan kerumitan mekanik game, permintaan ke basis data akan menjadi lebih rumit dan bebannya sendiri dapat meningkat secara signifikan dan sifatnya dapat berubah. Untuk mencegah hal ini, perlu untuk menguji proyek secara iteratif dengan masing-masing tonggak yang kurang lebih signifikan. Mengotomatiskan kemampuan untuk menjalankan tes semacam ini dengan beberapa ratus ribu pengguna telah menjadi tugas utama pada tahap ini.
Profil
Seperti halnya pengujian beban, semuanya dimulai dengan profil beban.
Nilai potensial kami CCU60 (CCU adalah jumlah maksimum pengguna untuk periode waktu tertentu, dalam hal ini 60 menit) dianggap
250.000 pengguna. Jumlah pengguna virtual kompetitif (VU) lebih rendah dari CCU60 dan analis telah menyarankan bahwa itu dapat dibagi dengan aman menjadi dua. Kumpulkan dan terima
150.000 VU kompetitif.
Jumlah total permintaan per detik diambil dari satu game yang agak dimuat:
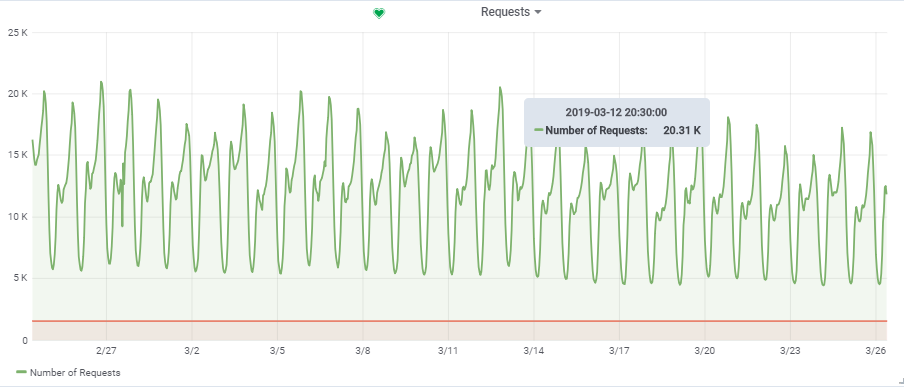
Dengan demikian, target beban kami adalah ~
20.000 permintaan / s pada
150.000 VU.
Struktur
Karakteristik "berdiri"
Dalam
artikel sebelumnya
, saya sudah berbicara tentang mengotomatisasi seluruh proses pengujian beban. Lebih jauh, saya mungkin akan mengulangi diri saya sedikit, tetapi saya akan memberi tahu Anda beberapa poin lebih terinci.

Dalam diagram, kotak biru adalah hypervisor kami (HV), awan yang terdiri dari banyak server (Dell M620 - M640). Pada setiap HV, selusin mesin virtual (VM) diluncurkan melalui KVM (web / aplikasi dan db dalam campuran). Saat membuat VM baru, penyeimbangan dan pencarian melalui set parameter HV yang sesuai terjadi dan pada awalnya tidak diketahui server mana yang akan dihidupkan.
Basis Data (Game DB):
Tetapi untuk tujuan db1 kami, kami memesan
targer_hypervisor HV terpisah berdasarkan M630.
Karakteristik singkat dari targer_hypervisor:
Dell M_630
Nama model: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
CPU: 48
Utas per inti: 2
Inti per soket: 12
Soket: 2
RAM: 128 GB
Debian GNU / Linux 9 (peregangan)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
Spesifikasi detailDebian GNU / Linux 9 (peregangan)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
Arsitektur: x86_64
Mode operasi CPU: 32-bit, 64-bit
Byte Order: Little Endian
CPU: 48
Daftar CPU online: 0-47
Utas per inti: 2
Inti per soket: 12
Soket: 2
NUMA simpul: 2
ID Vendor: GenuineIntel
Keluarga CPU: 6
Model: 63
Nama model: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
Melangkah: 2
CPU MHz: 1309.356
CPU maks MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988.42
Virtualisasi: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256 ribu
L3 cache: 30720K
NUMA node0 CPU: 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44.46
NUMA node1 CPU: 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,39,41,43 , 45,47
Tandai: fpu vme de pse tsc msr pae mc cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm konstantaoptoptsoptsoptsoptoktokkahsampaisampaisampunangkungtoptoptoptoptoptoptoptsoptoptsoptsoptspts. smx est tm2 SSSE3 sdbg FMA cx16 xtpr pdcm PCID DCA sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave AVX f16c rdrand lahf_lm ABM EPB invpcid_single ssbd IBRS ibpb stibp kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 AVX2 SMEP bmi2 Erms invpcid CQM xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts flush_l1d
/ usr / bin / qemu-system-x86_64 --version
QEMU versi emulator 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
Hak Cipta © 2003-2016 Fabrice Bellard dan pengembang Proyek QEMU
Karakteristik singkat dari db1:
Arsitektur: x86_64
CPU: 48
RAM: 64 GB
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU / Linux
Debian GNU / Linux 9 (peregangan)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 +1)
Konfigurasi PostgreSQL dengan beberapa penjelasanseq_page_cost = 1.0
random_page_cost = 1.1 # Kami memiliki SSD
termasuk '/etc/postgresql/11/main/extension.conf'
log_line_prefix = '% t [% p-% l]% q% u @% h'
log_checkpoints = on
log_lock_waits = on
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128MB
syncous_commit = off
checkpoint_timeout = 30 menit
listen_addresses = '*'
work_mem = 32MB
effective_cache_size = 26214MB # 50% dari memori yang tersedia
shared_buffers = 16384MB # 25% dari memori yang tersedia
max_wal_size = 15GB
min_wal_size = 80MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = aktif
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = aktif
wal_log_hints = on
hot_standby_feedback = aktif
hot_standby_feedback default tidak aktif, kami telah dihidupkan, tetapi kemudian harus dimatikan untuk melakukan tes yang berhasil. Saya akan jelaskan nanti mengapa.
Tabel aktif utama dalam database (konstruksi, produksi, game_entity, bangunan, core_inventory_player_resource, survivor) sudah diisi sebelumnya dengan data (sekitar 80GB) menggunakan skrip bash.
Replikasi:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Server aplikasi
Kemudian, pada HV produktif (prod_hypervisors) dari berbagai konfigurasi dan kapasitas, 15 server aplikasi diluncurkan: 8 core, 4GB. Hal utama yang bisa dikatakan: openjdk 11.0.1 2018-10-16, spring, interaksi dengan database via
hikari (hikari.maximum-pool-size: 50)
Lingkungan uji stres
Seluruh lingkungan pengujian beban terdiri dari satu server
admin.loadtest utama, dan beberapa server
generatorN.loadtest (dalam hal ini ada 14).
generatorN.loadtest - "telanjang" VM Debian Linux 9, dengan Java yang diinstal 8. 32 kernel / 32 gigabytes. Mereka berada di HV non-produktif sehingga tidak secara tidak sengaja membunuh kinerja VM penting.
admin.loadtest -
Mesin virtual Debian Linux 9, 16 core / 16 gigs, menjalankan Jenkins, JLTC, dan perangkat lunak tambahan lainnya yang tidak penting.
JLTC -
pusat uji beban jmeter . Sistem pada Py / Django yang mengontrol dan mengotomatiskan peluncuran tes, serta analisis hasil.
Skema Peluncuran Tes

Proses menjalankan tes terlihat seperti ini:
- Tes diluncurkan dari Jenkins . Pilih Pekerjaan yang diperlukan, maka Anda harus memasukkan parameter tes yang diinginkan:
- DURASI - durasi tes
- RAMPUP - waktu "pemanasan"
- THREAD_COUNT_TOTAL - jumlah pengguna virtual (VU) atau utas yang diinginkan
- TARGET_RESPONSE_TIME adalah parameter penting, agar tidak membebani seluruh sistem dengan bantuannya, kami menetapkan waktu respons yang diinginkan, sehingga pengujian akan menjaga beban pada tingkat di mana waktu respons seluruh sistem tidak lebih dari yang ditentukan.
- Luncurkan
- Jenkins mengkloning rencana tes dari Gitlab, mengirimkannya ke JLTC.
- JLTC bekerja sedikit dengan rencana pengujian (misalnya, menyisipkan penulis sederhana CSV).
- JLTC menghitung jumlah server Jmeter yang diperlukan untuk menjalankan jumlah VU yang diinginkan (THREAD_COUNT_TOTAL).
- JLTC terhubung ke setiap generator loadgeneratorN dan memulai server jmeter.
Selama pengujian,
klien JMeter menghasilkan file CSV dengan hasilnya. Jadi selama pengujian, jumlah data dan ukuran file ini tumbuh pada kecepatan yang
gila , dan itu tidak dapat digunakan untuk analisis setelah pengujian -
Daemon ditemukan (sebagai percobaan), yang menguraikannya
"dengan cepat" .
Rencana uji
Anda dapat mengunduh paket tes di
sini .
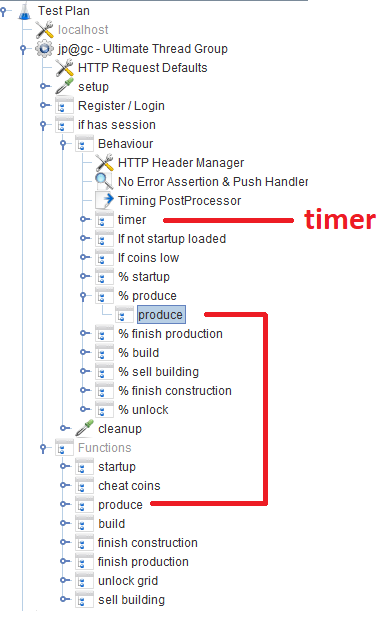
Setelah pendaftaran / masuk, pengguna bekerja dalam modul
Behavior , yang terdiri dari beberapa
pengontrol Throughput yang menentukan kemungkinan fungsi game tertentu. Di setiap pengontrol Throughput, ada
Pengontrol modul , yang merujuk ke modul terkait yang mengimplementasikan fungsi.
Di luar topik
Selama pengembangan skrip, kami mencoba menggunakan Groovy secara maksimal, dan terima kasih kepada programmer Java kami, saya menemukan beberapa trik untuk diri saya sendiri (mungkin ini akan berguna bagi seseorang):
VU / Utas
Ketika pengguna memasukkan jumlah VU yang diinginkan menggunakan parameter THREAD_COUNT_TOTAL ketika mengkonfigurasi pekerjaan di Jenkins, perlu untuk memulai jumlah server Jmeter yang diperlukan dan mendistribusikan jumlah VU terakhir yang diperlukan di antara mereka. Bagian ini terletak pada JLTC di bagian yang disebut
pengontrol / ketentuan .
Intinya, algoritma ini adalah sebagai berikut:
- Kami membagi jumlah VU threads_num yang diinginkan menjadi 200-300 utas dan berdasarkan pada ukuran yang kurang lebih -Xmsm -Xmxm, kami menentukan nilai memori yang diperlukan untuk satu jmeter-server required_memory_for_jri (JRI - Saya memanggil instance jarak jauh Jmeter, bukan Jmeter-server).
- Dari threads_num dan required_memory_for_jri kami menemukan jumlah total jmeter-server: target_amount_jri dan nilai total memori yang diperlukan : required_memory_total .
- Kami memilah-milah semua generator loadgeneratorN satu per satu dan memulai jumlah maksimum server-jmeter berdasarkan memori yang tersedia di dalamnya. Selama jumlah instance instalan current_amount_jri tidak sama dengan target_amount_jri.
- (Jika jumlah generator dan total memori tidak cukup, tambahkan yang baru ke kumpulan)
- Kami terhubung ke setiap generator, menggunakan netstat yang kami ingat semua port sibuk, dan berjalan pada port acak (yang tidak dihuni) jumlah yang diperlukan dari server-jmeter:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- Kami mengumpulkan semua server jmeter yang berjalan dalam satu waktu dalam format alamat: port, misalnya generator13: 15576, generator9: 14015, generator11: 19152, generator14: 12125, generator2: 17602
- Daftar dan threads_per_host yang dihasilkan dikirim ke JMeter-client ketika tes dimulai:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
Dalam kasus kami, pengujian berlangsung secara simultan dari 300 server Jmeter, masing-masing 500 utas, format peluncuran satu server Jmeter dengan parameter Java tampak seperti ini:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50 ms
Tugasnya adalah untuk menentukan seberapa banyak basis data kita dapat bertahan, daripada membebani secara berlebihan dan keseluruhan sistem secara keseluruhan hingga ke kondisi kritis. Dengan begitu banyak server Jmeter, Anda perlu mempertahankan beban pada tingkat tertentu dan tidak mematikan keseluruhan sistem. Parameter
TARGET_RESPONSE_TIME yang ditentukan saat memulai tes bertanggung jawab untuk ini. Kami sepakat bahwa
50ms adalah waktu respons optimal yang menjadi tanggung jawab sistem.
Di JMeter, secara default, ada banyak timer berbeda yang memungkinkan Anda untuk mengontrol throughput, tetapi tidak diketahui di mana mendapatkannya dalam kasus kami. Tetapi ada
JSR223-Timer yang dengannya Anda dapat menemukan sesuatu menggunakan
waktu respons sistem
saat ini . Timer itu sendiri ada di blok
Perilaku utama:

Analisis hasil (daemon)
Selain grafik di Grafana, juga perlu memiliki hasil tes agregat sehingga tes selanjutnya dapat dibandingkan di JLTC.
Salah satu tes tersebut menghasilkan 16k-20k permintaan per detik, mudah untuk menghitung bahwa dalam 4 jam itu menghasilkan file CSV berukuran beberapa ratus GB, jadi perlu untuk membuat pekerjaan yang mem-parsing data setiap menit, mengirimkannya ke database dan membersihkan file utama.
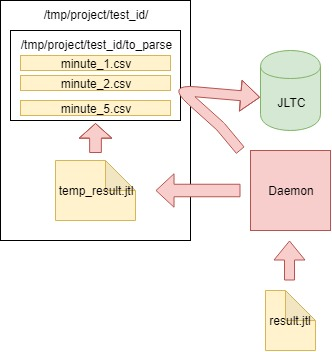
Algoritma adalah sebagai berikut:
- Kami membaca data dari file CSV result.jtl yang dihasilkan oleh jmeter-client, simpan dan bersihkan file tersebut (Anda harus membersihkannya dengan benar, jika tidak, file yang tampak kosong akan memiliki FD yang sama dengan ukuran yang sama):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- Kami menulis data baca ke file sementara temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- Kami membaca file temp_result.jtl . Kami mendistribusikan data baca "dalam hitungan menit":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- Data untuk setiap menit dari minutes_data ditulis ke file yang sesuai di folder to_parse . (dengan demikian, pada saat ini, setiap menit tes memiliki file datanya sendiri, maka selama agregasi itu tidak masalah dalam urutan apa data masuk ke setiap file):
for key, value in minutes_data.iteritems():
- Sepanjang jalan, kami menganalisis file dalam folder to_parse dan jika ada yang tidak berubah dalam satu menit, maka file ini adalah kandidat untuk analisis data, agregasi, dan mengirim ke database JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- Jika ada file seperti itu (satu atau beberapa), maka kami mengirimnya diurai ke fungsi parse_csv_data (setiap file secara paralel):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
Daemon itu sendiri di cron.d dimulai setiap menit:
daemon dimulai setiap menit dengan cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Dengan demikian, file dengan hasil tidak membengkak ke ukuran yang tak terbayangkan, tetapi dianalisis
dengan cepat dan dibersihkan.
Hasil
Aplikasi
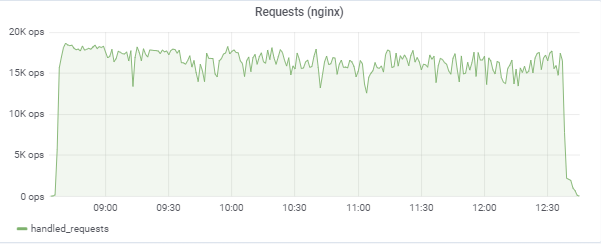
150.000 pemain virtual kami:

Tes ini mencoba untuk "mencocokkan" waktu respons 50 ms, sehingga beban itu sendiri secara konstan melompat di wilayah antara 16k-18k permintaan / c:
Aplikasi memuat server (15 aplikasi). Dua server "sial" berada di M620 yang lebih lambat:
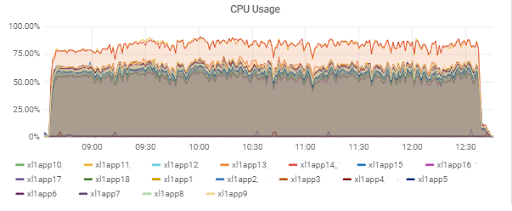
Waktu respons basis data (untuk server aplikasi):

Basis data
Penggunaan CPU pada db1 (VM):
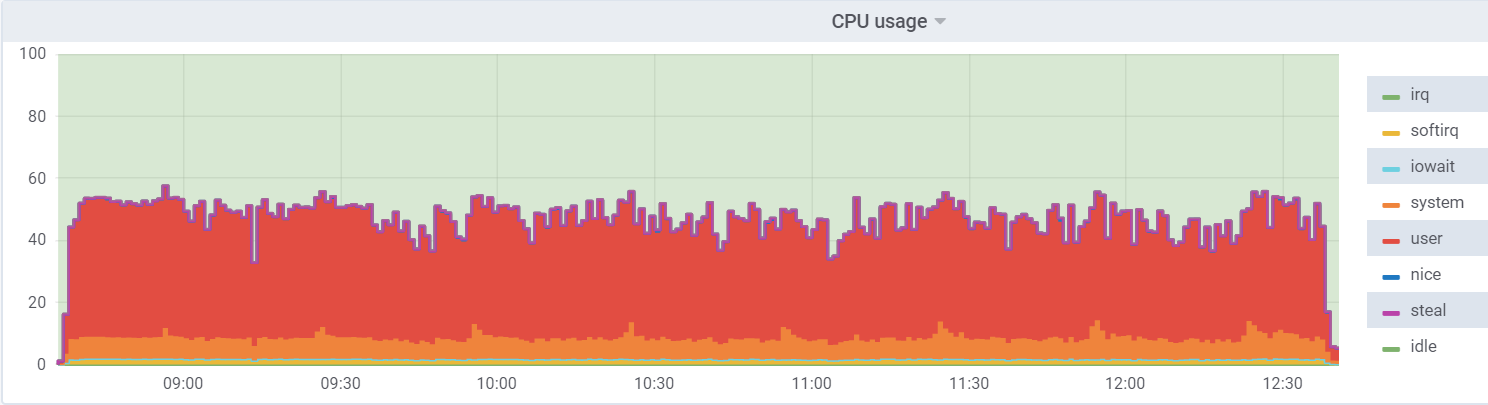
Penggunaan CPU pada hypervisor:
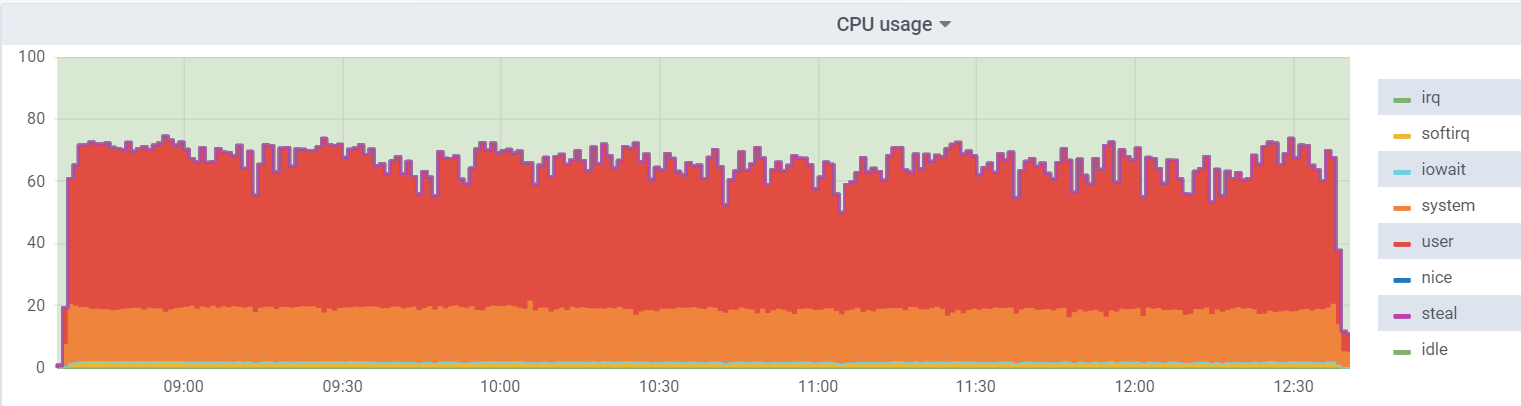
Beban pada mesin virtual lebih rendah, karena ia percaya bahwa ia memiliki 48 core nyata yang tersedia, pada kenyataannya, ada 24 core
hyperhreading pada hypervisor.
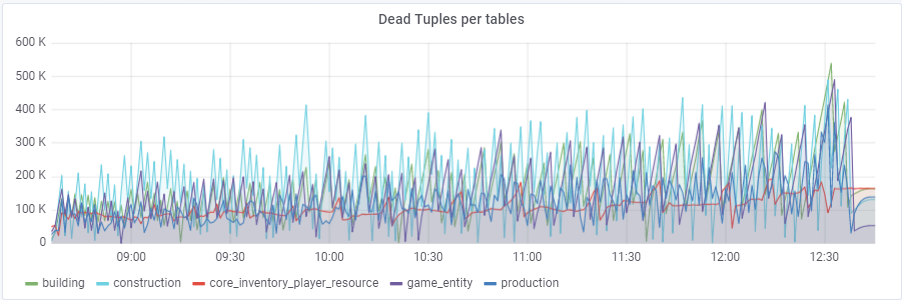
Maksimal ~ 250K kueri / s masuk ke basis data, terdiri dari (83% selektif, 3% - sisipan, 11,6% - pembaruan (90% HOT), 1,6% dihapus):

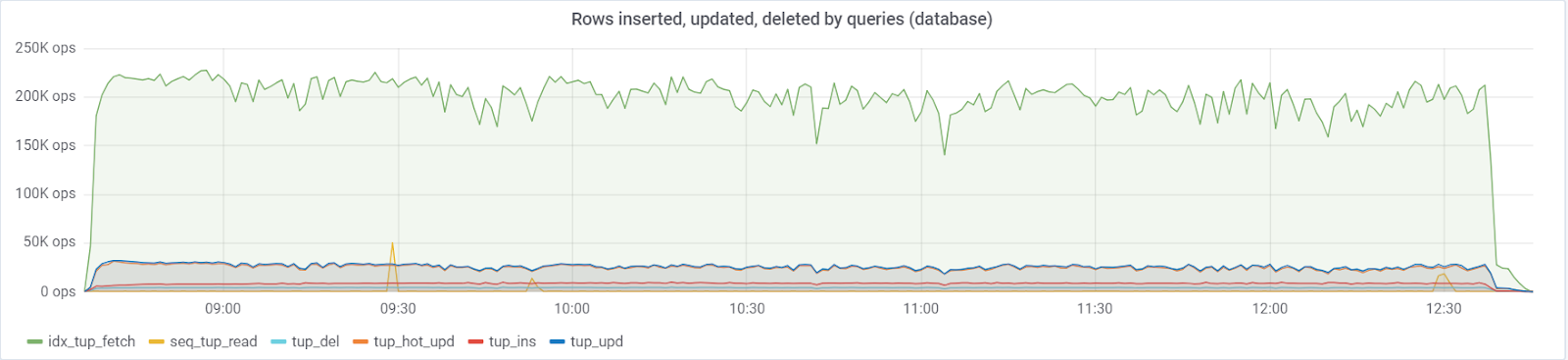
Dengan nilai default
autovacuum_vacuum_scale_factor = 0,2, jumlah tupel mati tumbuh sangat cepat dengan pengujian (dengan meningkatnya ukuran tabel), yang menyebabkan beberapa kali masalah pendek kinerja database yang merusak seluruh tes beberapa kali. Saya harus "menjinakkan" pertumbuhan ini untuk beberapa tabel dengan menetapkan nilai pribadi ke parameter ini autovacuum_vacuum_scale_factor:
ALTER TABEL ... SET (autovacuum_vacuum_scale_factor = ...)SET konstruksi ALTER TABEL (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE SET produksi (autovacuum_vacuum_scale_factor = 0,01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0,01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0,01);
SET bangunan ALTER TABEL (autovacuum_vacuum_scale_factor = 0,01);
SET bangunan ALTER TABEL (autovacuum_analyze_scale_factor = 0,01);
ALTER TABLE core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0,10);
SET ALTER TABEL selamat (autovacuum_vacuum_scale_factor = 0,01);
SET ALTER TABEL selamat (autovacuum_analyze_scale_factor = 0,01);
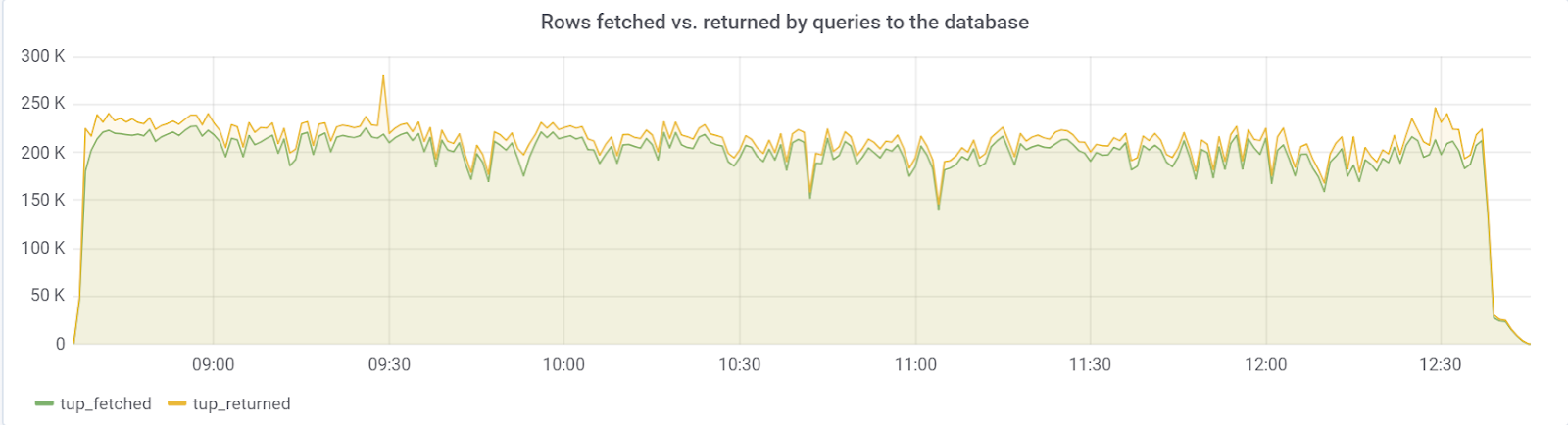
Idealnya, rows_fetched harus dekat dengan rows_returned, yang kami, untungnya, kami amati:
hot_standby_feedback
Masalahnya adalah dengan parameter
hot_standby_feedback , yang dapat sangat mempengaruhi kinerja server
utama jika server
siaga tidak punya waktu untuk menerapkan perubahan dari file WAL. Dokumentasi (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) menyatakan bahwa ia "menentukan apakah server siaga panas akan memberi tahu master atau budak superior tentang permintaan yang saat ini dieksekusi." Secara default tidak aktif, tetapi dihidupkan dalam konfigurasi kami. Yang menyebabkan konsekuensi yang menyedihkan, jika ada 2 server siaga dan jeda replikasi selama pemuatan berbeda dari nol (karena berbagai alasan), Anda dapat mengamati gambar seperti itu, yang dapat menyebabkan runtuhnya seluruh pengujian:
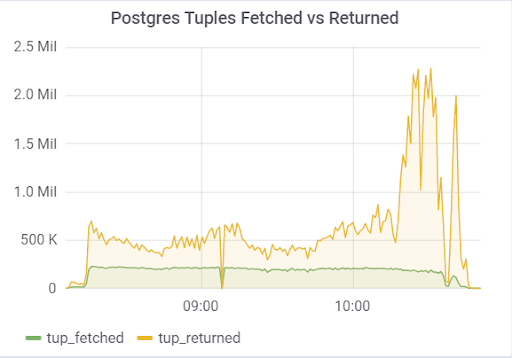

Ini disebabkan oleh fakta bahwa ketika hot_standby_feedback diaktifkan, VACUUM tidak ingin menghapus tupel mati jika server siaga ketinggalan dalam id transaksi mereka untuk mencegah konflik replikasi. Artikel terperinci
Apa sebenarnya hot_standby_feedback di PostgreSQL :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Sejumlah besar tupel mati mengarah ke gambar yang ditunjukkan di atas. Berikut adalah dua tes, dengan hot_standby_feedback dihidupkan dan dimatikan:
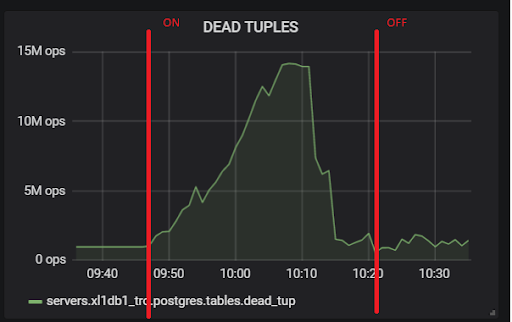
Dan ini adalah keterlambatan replikasi kami selama pengujian, yang dengannya diperlukan untuk melakukan sesuatu di masa depan:
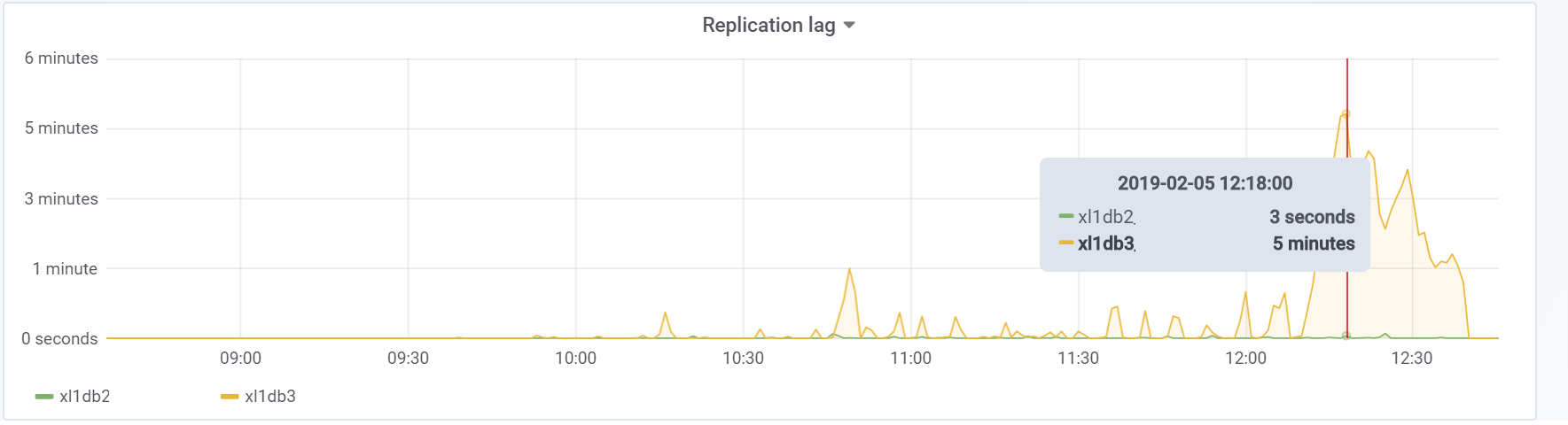
Kesimpulan
Tes ini, untungnya (atau sayangnya untuk konten artikel) menunjukkan bahwa pada tahap prototipe permainan ini sangat mungkin untuk menyerap beban yang diinginkan pada bagian pengguna, yang cukup memberikan lampu hijau untuk prototipe dan pengembangan lebih lanjut. Pada tahap pengembangan selanjutnya, perlu untuk mengikuti aturan dasar (untuk menjaga kesederhanaan dari pertanyaan yang dieksekusi, untuk mencegah kelebihan indeks, serta pembacaan yang tidak diindeks, dll.) Dan yang paling penting, uji proyek pada setiap tahap perkembangan yang signifikan untuk menemukan dan memperbaiki masalah seperti bisa lebih awal. Mungkin sebentar lagi, saya akan menulis artikel karena kami telah memecahkan masalah khusus.
Semoga beruntung untuk semuanya!
GitHub kami untuk jaga-jaga;)