
Database time series (TSDB) di Prometheus 2 adalah contoh yang bagus dari solusi teknik yang menawarkan peningkatan besar pada penyimpanan v2 di Prometheus 1 dalam hal kecepatan penyimpanan data dan eksekusi permintaan, efisiensi sumber daya. Kami menerapkan Prometheus 2 di Percona Monitoring and Management (PMM), dan saya berkesempatan untuk memahami kinerja Prometheus 2 TSDB. Pada artikel ini saya akan berbicara tentang hasil pengamatan ini.
Prometheus beban kerja rata-rata
Bagi mereka yang terbiasa berurusan dengan basis data primer, beban kerja reguler Prometheus sangat ingin tahu. Kecepatan akumulasi data cenderung ke nilai yang stabil: biasanya layanan yang Anda pantau mengirim metrik dengan jumlah yang sama, dan perubahan infrastruktur relatif lambat.
Permintaan informasi dapat berasal dari berbagai sumber. Beberapa dari mereka, seperti peringatan, juga berusaha untuk nilai yang stabil dan dapat diprediksi. Lainnya, seperti permintaan pengguna, dapat menyebabkan lonjakan, meskipun ini tidak khas untuk sebagian besar beban.
Uji beban
Selama pengujian, saya fokus pada kemampuan mengumpulkan data. Saya menggunakan Prometheus 2.3.2 yang dikompilasi dengan Go 1.10.1 (sebagai bagian dari PMM 1.14) pada layanan Linode menggunakan skrip ini:
StackScript . Untuk generasi pemuatan yang paling realistis, menggunakan
StackScript ini
, saya meluncurkan beberapa node MySQL dengan beban nyata (Sysbench TPC-C Test), yang masing-masing ditiru 10 node Linux / MySQL.
Semua tes berikut dilakukan pada server Linode dengan delapan core virtual dan memori 32 GB, di mana 20 memuat simulasi pemantauan dua ratus instance MySQL diluncurkan. Atau, dalam istilah Prometheus, 800 target, 440 goresan per detik, 380 ribu sampel per detik, dan 1,7 juta deret waktu aktif.
Desain
Pendekatan biasa dari database tradisional, termasuk yang digunakan oleh Prometheus 1.x, adalah
batas memori . Jika tidak cukup untuk menahan beban, Anda akan mengalami penundaan besar dan beberapa permintaan tidak akan dipenuhi.
Penggunaan memori dalam Prometheus 2 dikonfigurasikan menggunakan kunci
storage.tsdb.min-block-duration , yang menentukan berapa lama catatan akan disimpan dalam memori sebelum dibilas ke disk (secara default, ini adalah 2 jam). Jumlah memori yang dibutuhkan akan tergantung pada jumlah deret waktu, label, dan intensitas pengumpulan data (goresan) secara total dengan aliran input bersih. Dalam hal ruang disk, Prometheus bertujuan untuk menggunakan 3 byte per record (sampel). Di sisi lain, persyaratan memori jauh lebih tinggi.
Terlepas dari kenyataan bahwa dimungkinkan untuk mengonfigurasi ukuran blok, tidak disarankan untuk mengonfigurasinya secara manual, sehingga Anda dihadapkan dengan kebutuhan untuk memberikan Prometheus memori sebanyak yang diminta untuk memuat Anda.
Jika tidak ada cukup memori untuk mendukung aliran metrik yang masuk, Prometheus akan jatuh dari kehabisan memori atau pembunuh OOM akan mencapainya.
Menambahkan swap untuk menunda kerusakan saat Prometheus kehabisan memori tidak terlalu membantu, karena menggunakan fitur ini menyebabkan konsumsi memori yang eksplosif. Saya pikir masalahnya adalah Go, pengumpul sampahnya dan cara kerjanya dengan swap.
Pendekatan lain yang menarik adalah mengatur blok kepala untuk diatur ulang ke disk pada waktu tertentu, alih-alih menghitungnya dari awal proses.
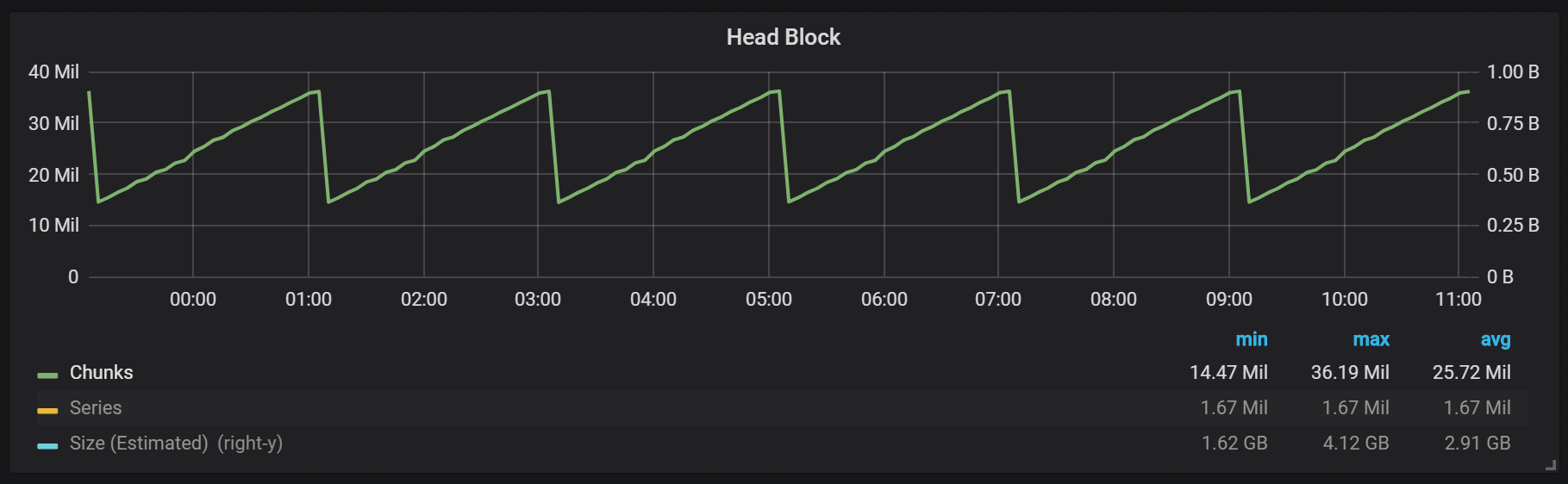
Seperti yang dapat Anda lihat dari grafik, flush disk terjadi setiap dua jam. Jika Anda mengubah parameter durasi blok-min menjadi satu jam, maka pelepasan ini akan terjadi setiap jam, mulai setengah jam.
Jika Anda ingin menggunakan ini dan gambar lain di instalasi Prometheus Anda, Anda dapat menggunakan dasbor ini. Ini dikembangkan untuk PMM, tetapi, dengan sedikit modifikasi, cocok untuk semua pemasangan Prometheus.Kami memiliki blok aktif yang disebut blok kepala, yang disimpan dalam memori; blok dengan data yang lebih lama dapat diakses melalui
mmap() . Ini menghilangkan kebutuhan untuk mengkonfigurasi cache secara terpisah, tetapi juga berarti bahwa Anda perlu meninggalkan ruang yang cukup untuk cache sistem operasi jika Anda ingin membuat permintaan untuk data yang lebih tua dari blok kepala.
Ini juga berarti bahwa konsumsi memori virtual Prometheus akan terlihat cukup tinggi, yang tidak perlu dikhawatirkan.

Poin desain menarik lainnya adalah penggunaan WAL (tulis log di depan). Seperti yang Anda lihat dari dokumentasi penyimpanan, Prometheus menggunakan WAL untuk menghindari kerugian karena jatuh. Sayangnya, mekanisme spesifik untuk memastikan ketahanan data tidak terdokumentasi dengan baik. Prometheus versi 2.3.2 menyiram WAL ke disk setiap 10 detik, dan parameter ini tidak dapat dikonfigurasi pengguna.
Stempel (Komposisi)
Prometheus TSDB dirancang dalam gambar repositori LSM (Log Structured merge - pohon log-terstruktur dengan penggabungan): blok kepala secara berkala disiram ke disk, sementara mekanisme kompresi menggabungkan beberapa blok bersama-sama untuk mencegah pemindaian terlalu banyak blok selama permintaan. Di sini Anda dapat melihat jumlah blok yang saya amati pada sistem pengujian setelah seharian bekerja.
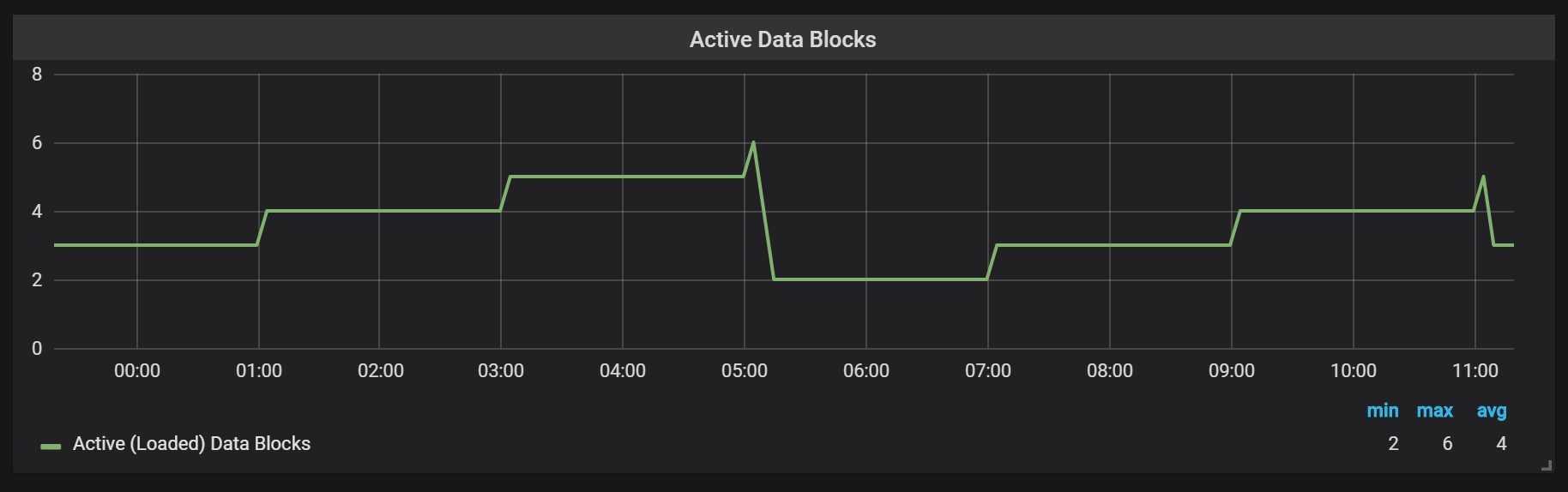
Jika Anda ingin tahu lebih banyak tentang repositori, Anda dapat mempelajari file meta.json, yang berisi informasi tentang blok yang tersedia dan bagaimana mereka muncul.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Stempel dalam Prometheus terikat pada waktu blok kepala dibilas ke disk. Pada titik ini, beberapa operasi seperti itu dapat dilakukan.
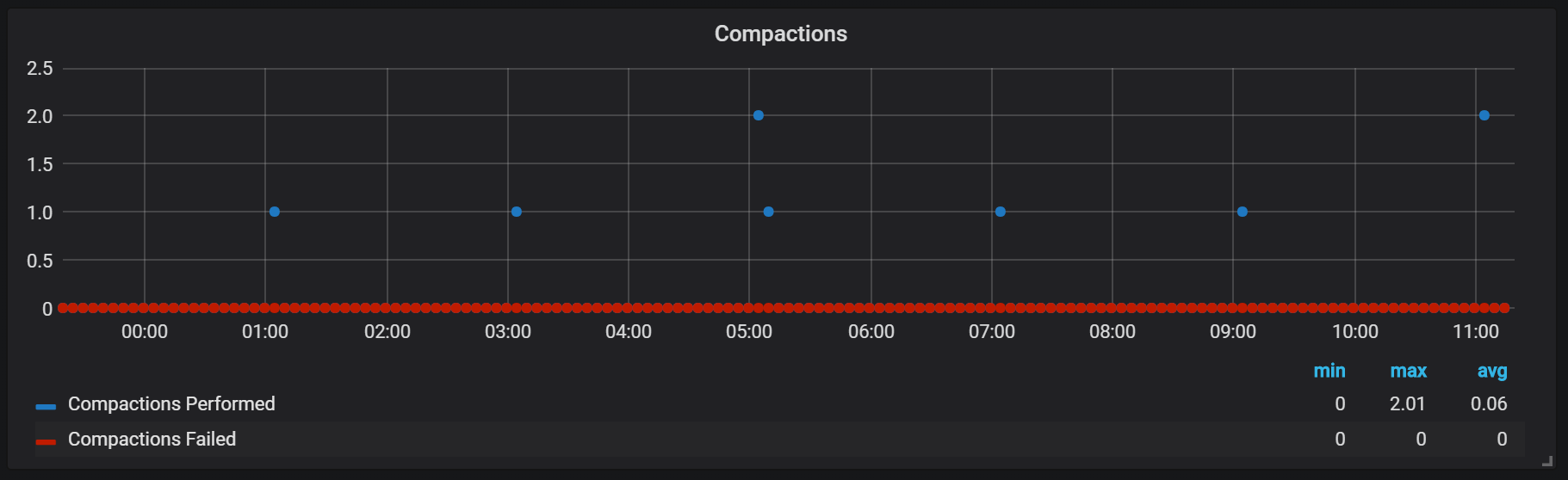
Rupanya, segel tidak terbatas dengan cara apa pun dan dapat menyebabkan disk I / O besar melompat saat runtime.

Paku unduhan CPU

Tentu saja, ini berdampak negatif pada kecepatan sistem, dan juga merupakan tantangan serius bagi LSM-storage: bagaimana membuat segel untuk mendukung kecepatan permintaan tinggi dan tidak menyebabkan terlalu banyak overhead?
Penggunaan memori dalam proses pemadatan juga terlihat cukup menarik.

Kita dapat melihat bagaimana, setelah pemadatan, sebagian besar memori berubah dari Cached ke Free: itu berarti informasi yang berpotensi berharga telah dihapus dari sana. Penasaran apakah
fadvice() atau teknik minimisasi lain digunakan di sini, atau apakah disebabkan oleh fakta bahwa cache dibebaskan dari blok yang dihancurkan selama pemadatan?
Pemulihan Kecelakaan
Pemulihan bencana membutuhkan waktu, dan itu dibenarkan. Untuk aliran masuk satu juta catatan per detik, saya harus menunggu sekitar 25 menit saat pemulihan dilakukan dengan mempertimbangkan drive SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
Masalah utama dari proses pemulihan adalah konsumsi memori yang tinggi. Terlepas dari kenyataan bahwa dalam situasi normal server dapat bekerja secara stabil dengan jumlah memori yang sama, ketika crash, itu mungkin tidak naik karena OOM. Satu-satunya solusi yang saya temukan adalah untuk menonaktifkan pengumpulan data, meningkatkan server, memungkinkannya untuk memulihkan dan reboot dengan koleksi sudah aktif.
Lakukan pemanasan
Perilaku lain yang harus diingat selama pemanasan adalah rasio produktivitas yang rendah dan konsumsi sumber daya yang tinggi setelah dimulainya. Selama beberapa, tetapi tidak semua dimulai, saya mengamati beban serius pada CPU dan memori.
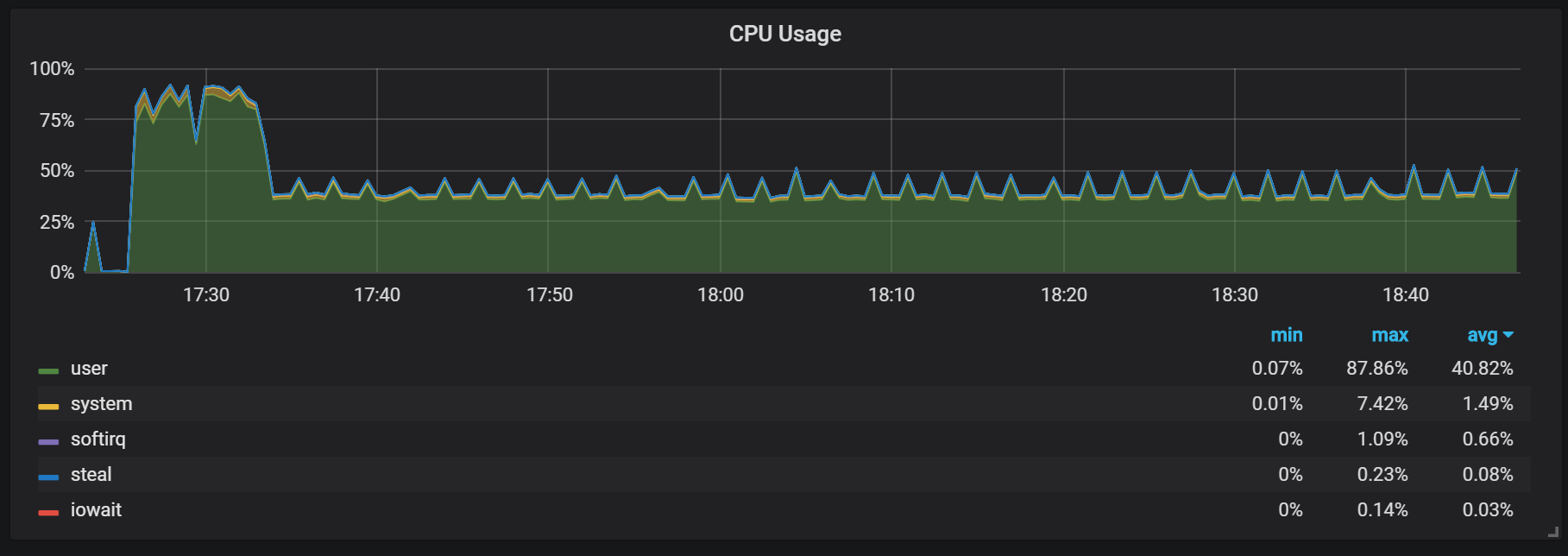

Memori yang hilang menunjukkan bahwa Prometheus tidak dapat mengkonfigurasi semua biaya dari awal, dan beberapa informasi hilang.
Saya tidak menemukan alasan pasti tingginya beban pada prosesor dan memori. Saya menduga bahwa ini disebabkan oleh penciptaan seri waktu baru di blok kepala dengan frekuensi tinggi.
Paku beban CPU
Selain segel, yang menciptakan beban I / O yang agak tinggi, saya perhatikan lompatan yang serius pada prosesor setiap dua menit. Semburan bertahan lebih lama dengan aliran masuk yang tinggi dan sepertinya disebabkan oleh pengumpul sampah Go, setidaknya beberapa kernel terisi penuh.

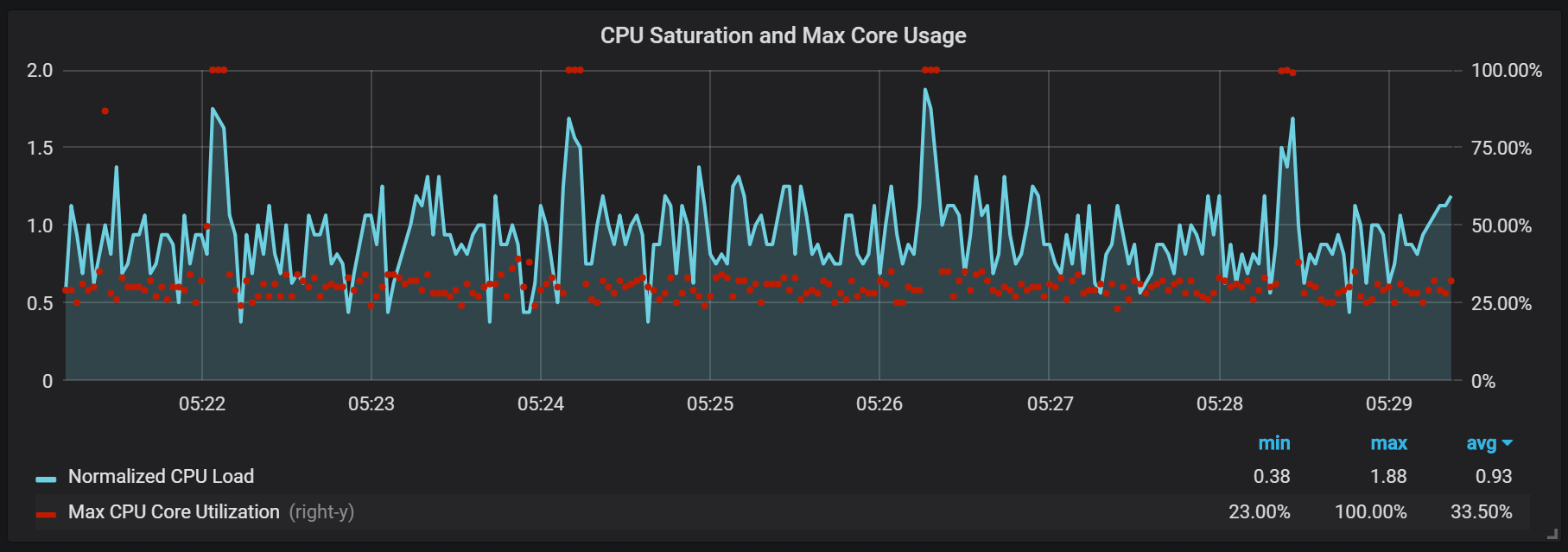
Lompatan ini tidak begitu signifikan. Tampaknya ketika itu terjadi, titik entri internal dan metrik Prometheus menjadi tidak dapat diakses, yang menyebabkan kesenjangan data pada interval waktu yang sama.
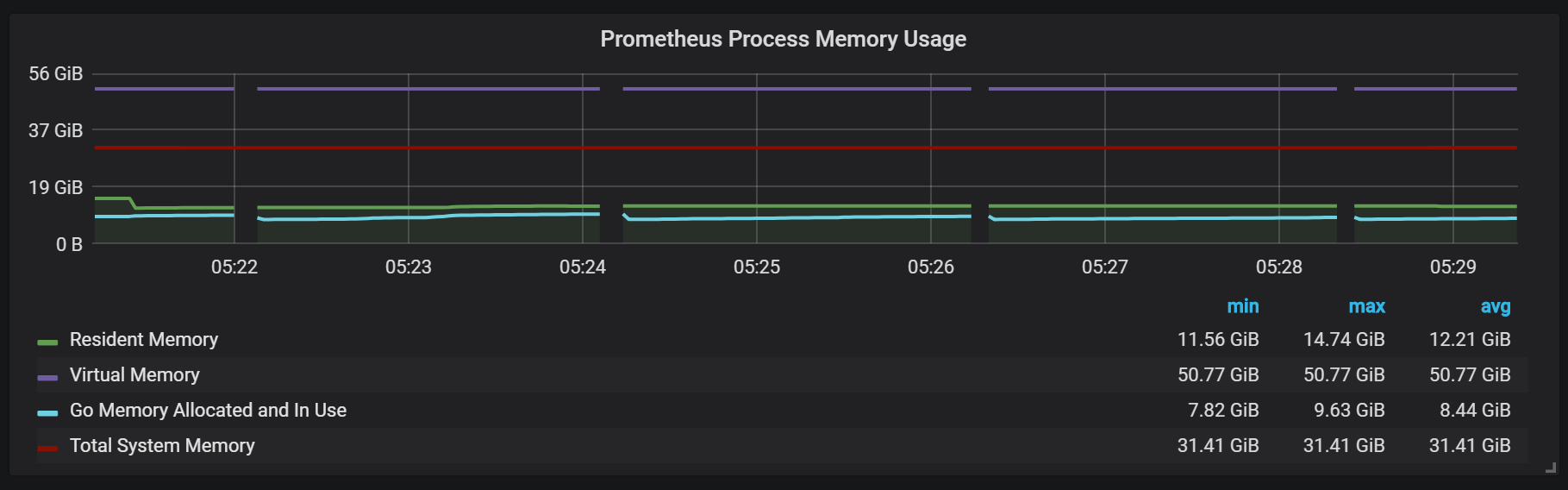
Anda juga dapat memperhatikan bahwa eksportir Prometheus tutup mulut selama satu detik.
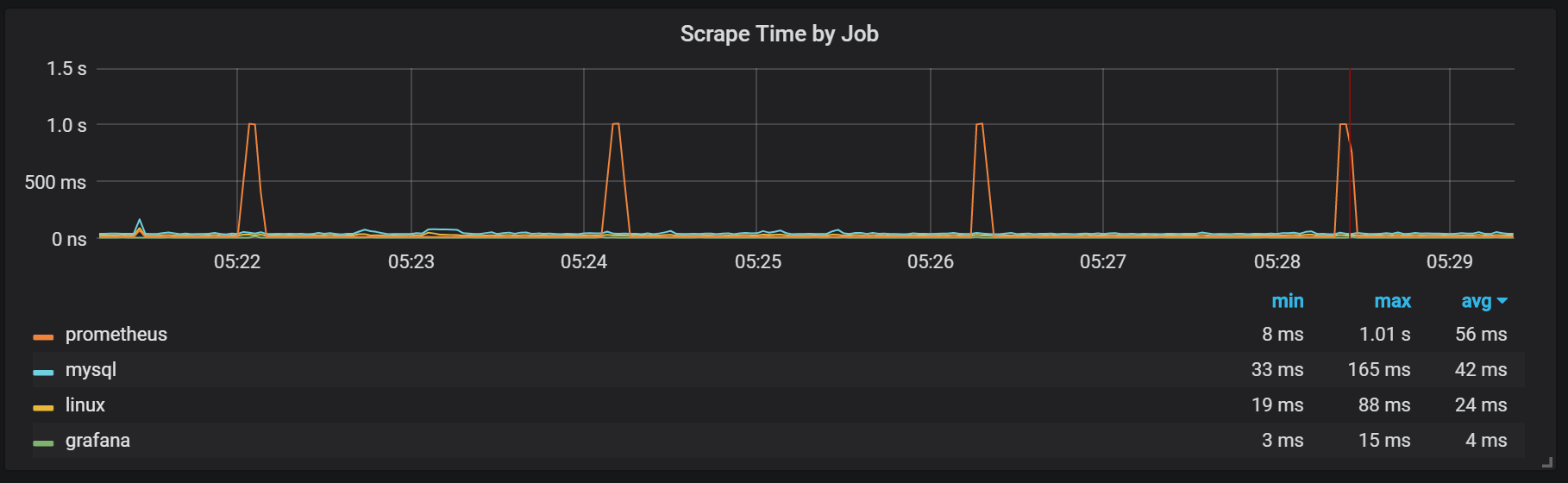
Kita bisa melihat korelasi dengan pengumpulan sampah (GC).

Kesimpulan
TSDB di Prometheus 2 cepat, mampu menangani jutaan seri waktu dan pada saat yang sama dengan ribuan rekaman per detik menggunakan perangkat keras yang cukup sederhana. Penggunaan CPU dan disk I / O juga mengesankan. Contoh saya menunjukkan hingga 200.000 metrik per detik per inti yang digunakan.
Untuk merencanakan ekstensi, Anda perlu mengingat tentang volume memori yang cukup, dan ini haruslah memori nyata. Jumlah memori yang digunakan yang saya amati sekitar 5 GB per 100.000 entri per detik dari aliran masuk, yang dikombinasikan dengan cache sistem operasi sekitar 8 GB memori yang digunakan.
Tentu saja, masih ada banyak pekerjaan untuk menjinakkan ledakan CPU dan disk I / O, dan ini tidak mengherankan mengingat betapa mudanya TSDB Prometheus 2 dibandingkan dengan InnoDB, TokuDB, RocksDB, WiredTiger, tetapi mereka semua memiliki masalah yang sama pada awal siklus hidup.