
Logika mesin tidak tercela, mereka tidak membuat kesalahan jika algoritma mereka bekerja dengan benar dan parameter yang ditetapkan sesuai dengan standar yang diperlukan. Minta mobil untuk memilih rute dari titik A ke titik B, dan itu akan membangun yang paling optimal, dengan mempertimbangkan jarak, konsumsi bahan bakar, keberadaan pompa bensin, dll. Ini adalah perhitungan murni. Mobil itu tidak akan mengatakan: "Mari kita menyusuri jalan ini, saya merasa rute ini lebih baik." Mungkin mobil lebih baik daripada kita dalam kecepatan perhitungan, tetapi intuisi masih menjadi salah satu kartu truf kita. Umat manusia telah menghabiskan waktu puluhan tahun untuk menciptakan mesin yang mirip dengan otak manusia. Tetapi apakah ada begitu banyak kesamaan di antara mereka? Hari ini kita akan mempertimbangkan sebuah studi di mana para ilmuwan, meragukan mesin "visi" yang tak tertandingi berdasarkan jaringan saraf convolutional, melakukan percobaan untuk menipu sistem pengenalan objek menggunakan algoritma yang tugasnya adalah membuat gambar "palsu". Seberapa sukseskah aktivitas sabotase dari algoritma, apakah orang-orang mengatasi pengakuan lebih baik daripada mobil, dan apa yang akan dibawa studi ini ke masa depan teknologi ini? Kami akan menemukan jawaban dalam laporan para ilmuwan. Ayo pergi.
Dasar studi
Teknologi pengenalan objek menggunakan jaringan saraf convolutional (SNS) memungkinkan mesin, secara kasar, untuk membedakan angsa dari nomor 9 atau kucing dari sepeda. Teknologi ini berkembang cukup pesat dan saat ini sedang diterapkan di berbagai bidang, yang paling jelas di antaranya adalah produksi kendaraan tak berawak. Banyak yang berpendapat bahwa SNA dari sistem pengenalan objek dapat dianggap sebagai model penglihatan manusia. Namun, pernyataan ini terlalu keras, karena faktor manusia. Masalahnya, membodohi mobil ternyata lebih mudah daripada membodohi seseorang (setidaknya dalam hal pengenalan objek). Sistem SNA sangat rentan terhadap efek dari algoritma jahat (bermusuhan, jika Anda mau), yang dengan segala cara akan mencegah mereka melakukan tugasnya dengan benar, membuat gambar yang akan secara tidak tepat diklasifikasikan oleh sistem SNA.
Peneliti membagi gambar tersebut menjadi dua kategori: "bodoh" (benar-benar mengubah target) dan "memalukan" (sebagian mengubah target). Yang pertama adalah gambar tidak berarti yang diakui oleh sistem sebagai sesuatu yang akrab. Sebagai contoh, satu set garis dapat diklasifikasikan sebagai "baseball," dan noise digital multi-warna sebagai "armadillo." Kategori gambar kedua ("memalukan") adalah gambar yang, dalam kondisi normal, akan diklasifikasi dengan benar, tetapi algoritma jahat sedikit menyimpangkannya, kata berlebihan, di mata sistem SNA. Misalnya, tulisan tangan nomor 6 akan diklasifikasikan sebagai nomor 5 karena komplemen kecil beberapa piksel.
Bayangkan saja apa yang bisa dilakukan algoritma tersebut. Layak bertukar klasifikasi rambu-rambu jalan untuk transportasi otonom dan kecelakaan tidak akan terhindarkan.
Di bawah ini adalah gambar "palsu" yang menipu sistem SNA, dilatih untuk mengenali objek, dan bagaimana sistem serupa mengklasifikasikannya.
 Gambar No. 1
Gambar No. 1Penjelasan seri:
- dan - gambar "penipuan" yang secara tidak langsung dikodekan;
- b - gambar yang dikodekan secara langsung;
- c - "memalukan" gambar, memaksa sistem untuk mengklasifikasikan satu digit sebagai yang lain;
- d - serangan LaVAN (kebisingan permusuhan / malicious lokal dan terlihat) dapat menyebabkan klasifikasi yang salah, bahkan ketika "noise" terletak hanya pada satu titik (di sudut kanan bawah).
- e - objek tiga dimensi yang secara keliru diklasifikasikan dari sudut yang berbeda.
Hal yang paling aneh tentang ini adalah bahwa seseorang mungkin tidak menyerah untuk menipu algoritma jahat dan mengklasifikasikan gambar dengan benar, berdasarkan pada intuisi. Sebelumnya, seperti yang dikatakan para ilmuwan, tidak ada yang membuat perbandingan praktis dari kemampuan sebuah mesin dan seseorang dalam percobaan untuk melawan algoritma berbahaya dari gambar palsu. Itulah yang para peneliti putuskan untuk lakukan.
Untuk ini, beberapa gambar yang dibuat oleh algoritma jahat disiapkan. Subjek diberitahu bahwa mesin mengklasifikasikan gambar (depan) ini sebagai objek yang dikenal, yaitu mesin tidak mengenalinya dengan benar. Tugas subyek adalah untuk menentukan dengan tepat bagaimana mesin mengklasifikasikan gambar-gambar ini, yaitu apa yang mereka pikir mesin lihat dalam gambar, apakah klasifikasi ini benar, dll.
Sebanyak 8 percobaan dilakukan, di mana 5 jenis gambar berbahaya dibuat tanpa memperhitungkan penglihatan manusia. Dengan kata lain, mereka diciptakan oleh mesin untuk mesin. Hasil percobaan ini ternyata sangat menghibur, tetapi kami tidak akan merusaknya dan mempertimbangkan semuanya secara berurutan.
Hasil Eksperimen
Eksperimen # 1: Membodohi Gambar dengan Tag Tidak Valid
Dalam percobaan pertama, 48 gambar bodoh digunakan, dibuat oleh algoritma untuk melawan sistem pengakuan berdasarkan SNA yang disebut AlexNet. Sistem ini mengklasifikasikan gambar-gambar ini sebagai "gigi" dan "donat" (
2a ).
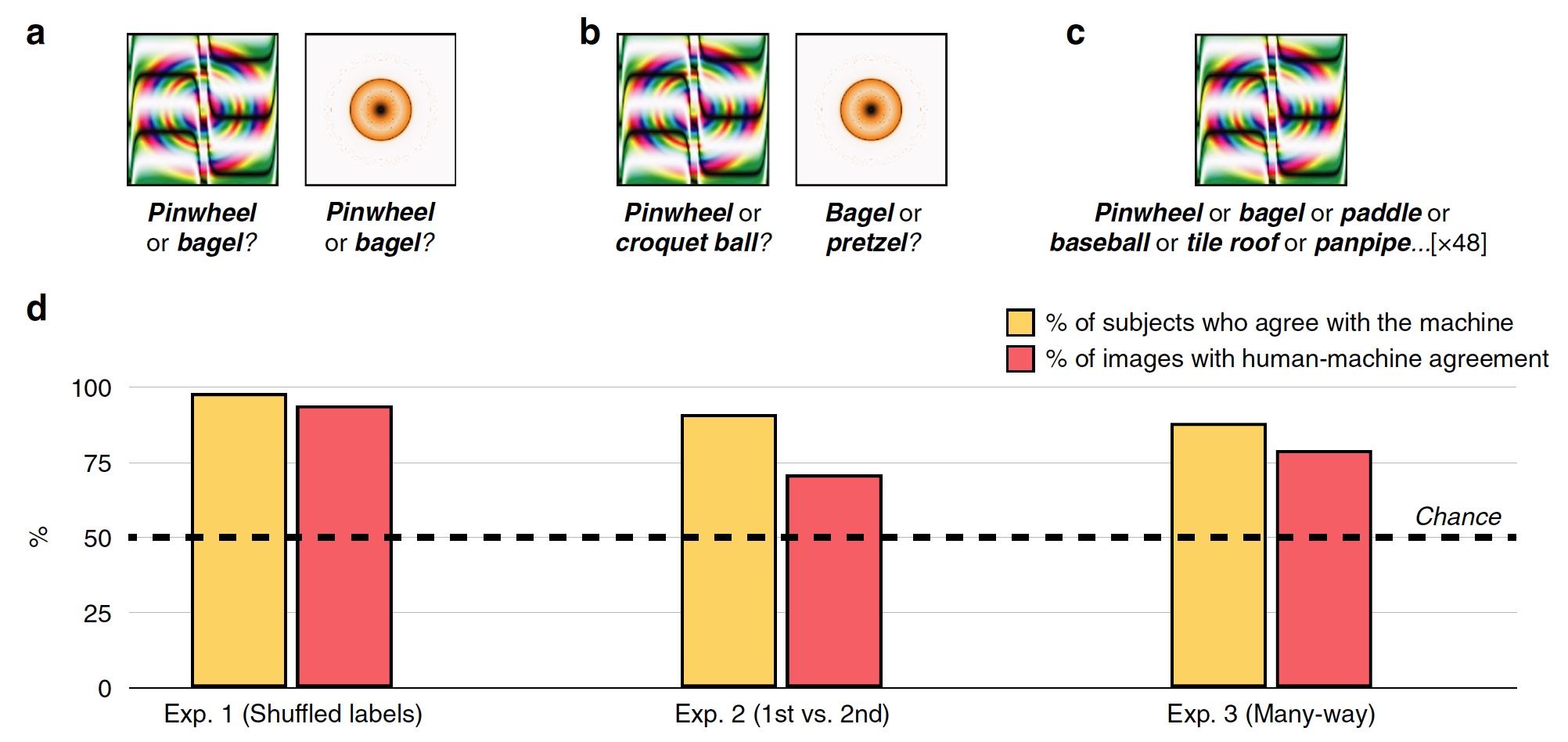 Gambar No. 2
Gambar No. 2Selama setiap percobaan, orang yang diuji, yang jumlahnya 200, melihat satu gambar pembodohan dan dua tanda, yaitu label klasifikasi: label sistem SNS dan acak dari 47 gambar lainnya. Subjek harus memilih label yang dibuat oleh mesin.
Akibatnya, sebagian besar subjek memilih untuk memilih label yang dibuat oleh mesin, bukan label dari algoritma jahat. Akurasi klasifikasi, mis. tingkat persetujuan subjek dengan mesin adalah 74%. Secara statistik, 98% subjek memilih tag mesin pada tingkat yang lebih tinggi daripada keacakan statistik (
2d , "% subjek setuju dengan mesin"). 94% dari gambar menunjukkan penyelarasan manusia-mesin yang sangat tinggi, yaitu, dari 48, hanya 3 gambar yang diklasifikasikan oleh orang-orang berbeda dari mesin.
Dengan demikian, subjek menunjukkan bahwa seseorang dapat berbagi gambar nyata dan orang bodoh, yaitu, bertindak sesuai dengan program yang didasarkan pada SNA.
Eksperimen 2: pilihan pertama lawan yang kedua
Peneliti mengajukan pertanyaan - karena subjek apa yang mampu mengenali gambar dengan sangat baik dan memisahkannya dari tanda yang salah dan gambar yang menipu? Mungkin subyek mencatat cincin oranye-kuning sebagai "donat", karena dalam kenyataannya donat itu persis bentuk ini dan sekitar warna yang sama. Dalam pengakuan, asosiasi dan pilihan intuitif berdasarkan pengalaman dan pengetahuan dapat membantu seseorang.
Untuk memverifikasi ini, label acak diganti dengan yang dipilih oleh mesin sebagai opsi klasifikasi kedua yang mungkin. Sebagai contoh, AlexNet mengklasifikasikan cincin oranye-kuning sebagai "donat", dan opsi kedua untuk program ini adalah "pretzel".
Subjek dihadapkan dengan tugas untuk memilih tanda pertama dari mesin atau yang menempati tempat kedua untuk semua 48 gambar (
2s ).
Grafik di tengah gambar
2d menunjukkan hasil tes ini: 91% subjek memilih versi pertama label, dan tingkat pencocokan mesin manusia adalah 71%.
Percobaan No. 3: klasifikasi multi-utas
Eksperimen yang dijelaskan di atas cukup sederhana mengingat fakta bahwa subjek memiliki pilihan antara dua jawaban yang mungkin (tag mesin dan tag acak). Bahkan, mesin dalam proses pengenalan gambar iterates melalui ratusan bahkan ribuan pilihan untuk label sebelum memilih yang paling cocok.
Dalam tes ini, semua tanda untuk 48 gambar langsung di depan subjek. Mereka harus memilih dari set ini yang paling cocok untuk setiap gambar.
Akibatnya, 88% subjek memilih label yang persis sama dengan mesin, dan tingkat koordinasi adalah 79%. Fakta menarik adalah bahwa bahkan ketika memilih label yang salah yang dipilih mesin, subjek dalam 63% dari kasus tersebut memilih salah satu dari 5 label teratas. Yaitu, semua tanda pada mobil dipesan dalam daftar dari yang paling cocok hingga yang paling tidak pantas (contoh berlebihan: "bagel", "pretzel", "cincin karet", "ban", dll. Hingga "elang di langit malam") )
Eksperimen No. 3b: "apa itu?"
Dalam tes ini, para ilmuwan telah sedikit mengubah aturan. Alih-alih meminta mereka untuk "menebak" label apa yang akan dipilih mesin untuk gambar tertentu, subjek hanya ditanya apa yang mereka lihat di depan mereka.
Sistem pengenalan yang didasarkan pada jaringan saraf convolutional pilih label yang sesuai untuk gambar tertentu. Ini adalah proses yang cukup jelas dan logis. Dalam tes ini, subjek menunjukkan pemikiran intuitif.
Akibatnya, 90% subjek memilih label, yang juga dipilih oleh mesin. Penjajaran manusia-mesin di antara gambar adalah 81%.
Eksperimen 4: Kebisingan Statis Televisi
Para ilmuwan mencatat bahwa dalam percobaan sebelumnya, gambar tidak biasa, tetapi mereka memiliki fitur yang dapat dibedakan yang dapat mendorong subjek untuk membuat pilihan label yang benar (atau salah). Sebagai contoh, gambar "baseball" bukanlah bola, tetapi ada garis dan warna di atasnya yang hadir pada bola baseball nyata. Ini adalah fitur pembeda yang mencolok. Tetapi jika gambar tidak memiliki fitur seperti itu, tetapi pada dasarnya adalah noise statis, dapatkah seseorang mengenali setidaknya sesuatu di dalamnya? Itu yang diputuskan untuk diperiksa.
 Gambar No. 3a
Gambar No. 3aDalam tes ini, ada 8 gambar dengan statika di depan mata pelajaran, yang sistem SNS mengenali sebagai objek tertentu (misalnya, burung-zaryanka). Juga, di depan subjek ada label dan gambar normal yang terkait dengannya (8 gambar statis, 1 label "zaryanka" dan 5 foto burung ini). Subjek uji harus memilih 1 dari 8 gambar statis yang paling sesuai dengan satu atau label lainnya.
Anda bisa menguji diri sendiri. Di atas Anda melihat contoh tes semacam itu. Manakah dari tiga gambar yang paling cocok untuk tag "zaryanka" dan mengapa?
81% subjek memilih label yang dipilih mesin. Pada saat yang sama, 75% gambar diberi label oleh subjek dengan label yang paling cocok menurut pendapat mesin (dari sejumlah opsi, seperti yang kami sebutkan sebelumnya).
Untuk tes khusus ini, Anda mungkin memiliki pertanyaan, seperti pertanyaan saya. Faktanya adalah bahwa dalam statika yang diusulkan (di atas), saya pribadi melihat tiga fitur diucapkan yang membedakan mereka satu sama lain. Dan hanya dalam satu gambar, fitur ini sangat mirip dengan zaryanka yang sama (saya pikir Anda mengerti gambar ketiganya). Karena itu, pendapat pribadi saya dan sangat subyektif adalah bahwa tes seperti itu tidak terlalu indikatif. Meskipun mungkin di antara opsi-opsi lain untuk gambar statis benar-benar tidak dapat dibedakan dan tidak dapat dikenali.
Eksperimen No. 5: angka "diragukan"
Tes yang dijelaskan di atas didasarkan pada gambar yang tidak dapat langsung sepenuhnya dan tanpa setetes keraguan diklasifikasikan sebagai satu atau objek lain. Selalu ada sedikit keraguan. Gambar-gambar yang bodoh cukup mudah dalam pekerjaan mereka - untuk merusak gambar tanpa bisa dikenali. Tetapi ada jenis kedua dari algoritma jahat yang menambahkan (atau menghapus) hanya detail kecil dalam gambar, yang dapat sepenuhnya melanggar sistem pengenalan oleh sistem SNA. Tambahkan beberapa piksel, dan angka 6 secara ajaib berubah menjadi angka 5 (
1s ).
Para ilmuwan menganggap algoritma seperti itu menjadi salah satu yang paling berbahaya. Anda dapat sedikit mengubah tag gambar, dan kendaraan tak berawak secara tidak benar mempertimbangkan tanda batas kecepatan (misalnya, 75 bukannya 45), yang dapat menyebabkan konsekuensi yang menyedihkan.
 Gambar # 3b
Gambar # 3bDalam tes ini, para ilmuwan menyarankan agar subjek memilih jawaban yang salah, tetapi yang salah. Dalam pengujian, 100 gambar digital yang diubah oleh algoritma jahat digunakan (LeNet SNA mengubah klasifikasi mereka, yaitu, algoritma jahat bekerja dengan sukses). Subjek harus mengatakan angka apa yang menurut mesin dilihat. Seperti yang diharapkan, 89% dari subyek berhasil menyelesaikan tes ini.
Eksperimen 6: foto dan "distorsi" lokal
Para ilmuwan mencatat bahwa tidak hanya sistem pengenalan objek yang dikembangkan, tetapi juga algoritma jahat yang mencegah mereka melakukan hal ini. Sebelumnya, agar gambar tidak diklasifikasikan dengan benar, perlu untuk mendistorsi (mengubah, menghapus, merusak, dll.) 14% dari semua piksel dalam gambar target. Sekarang angka ini menjadi jauh lebih kecil. Cukup menambahkan gambar kecil di dalam target dan klasifikasi akan dilanggar.
 Gambar No. 4
Gambar No. 4Dalam tes ini, algoritma LaVAN berbahaya yang cukup baru digunakan, yang menempatkan gambar kecil terlokalisasi pada satu titik pada foto target. Akibatnya, sistem pengenalan objek dapat mengenali kereta metro sebagai kaleng susu (
4a ). Fitur yang paling signifikan dari algoritma ini adalah proporsi kecil dari piksel yang rusak (hanya 2%) dari gambar target dan tidak adanya kebutuhan untuk mengubah keseluruhan atau bagian utama (paling signifikan) dari gambar tersebut.
Dalam pengujian, 22 gambar yang rusak oleh LaVAN digunakan (sistem pengenalan SNA Inception V3 berhasil diretas oleh algoritma ini). Subjek seharusnya mengklasifikasikan sisipan berbahaya dalam foto. 87% dari subyek berhasil melakukan ini.
Eksperimen 7: objek tiga dimensi
Gambar yang kami lihat sebelumnya adalah dua dimensi, seperti foto, gambar atau kliping koran. Sebagian besar algoritma jahat berhasil memanipulasi gambar seperti itu. Namun, hama ini hanya dapat bekerja di bawah kondisi tertentu, yaitu mereka memiliki sejumlah keterbatasan:
- kompleksitas: hanya gambar dua dimensi;
- aplikasi praktis: perubahan berbahaya hanya dimungkinkan pada sistem yang membaca gambar digital yang diterima, dan bukan gambar dari sensor dan sensor;
- stabilitas: serangan jahat kehilangan kekuatannya jika Anda memutar gambar dua dimensi (mengubah ukuran, memotong, mempertajam, dll.);
- orang: kita melihat dunia dan benda-benda di sekitar kita dalam 3D pada sudut yang berbeda, pencahayaan, dan bukan dalam bentuk gambar digital dua dimensi yang diambil dari satu sudut.
Tapi, seperti yang kita tahu, kemajuan tidak terhindar dari algoritma jahat. Di antara mereka muncul satu yang mampu tidak hanya mendistorsi gambar dua dimensi, tetapi juga yang tiga dimensi, yang mengarah pada klasifikasi yang salah oleh sistem pengenalan objek. Ketika menggunakan perangkat lunak untuk grafik tiga dimensi, algoritma seperti itu menyesatkan pengklasifikasi berdasarkan SNA (dalam hal ini, program Inception V3) dari jarak yang berbeda dan sudut pandang. Hal yang paling mengejutkan adalah gambar 3D yang bodoh seperti itu dapat dicetak pada printer yang sesuai, mis. buat objek fisik nyata, dan sistem pengenalan objek masih akan salah mengklasifikasikannya (misalnya, oranye sebagai bor listrik). Dan semua berkat perubahan kecil pada tekstur pada gambar target (
4b ).
Untuk sistem pengenalan objek, algoritma berbahaya seperti itu adalah musuh yang serius. Tetapi manusia bukanlah mesin, ia melihat dan berpikir secara berbeda. Dalam tes ini, sebelum subjek ada gambar objek tiga dimensi di mana ada perubahan tekstur yang dijelaskan di atas dari tiga sudut. Subjek juga diberi tanda yang benar dan salah. Mereka harus menentukan label mana yang benar, mana yang tidak, dan mengapa, mis. apakah subjek uji melihat perubahan tekstur pada gambar.
Hasilnya, 83% subjek berhasil menyelesaikan tugas.
Untuk seorang kenalan yang lebih mendetail dengan nuansa penelitian, saya sangat menyarankan agar Anda melihat
laporan para ilmuwan .
Dan pada
tautan ini Anda akan menemukan file gambar, data, dan kode yang digunakan dalam penelitian.
Epilog
Pekerjaan yang dilakukan memberi para ilmuwan kesempatan untuk menarik kesimpulan yang sederhana dan cukup jelas - intuisi manusia dapat menjadi sumber data yang sangat penting dan alat dalam membuat keputusan yang tepat dan / atau persepsi informasi. Seseorang dapat secara intuitif memahami bagaimana sistem pengenalan objek akan berperilaku, label apa yang akan dipilihnya, dan mengapa.
Alasan mengapa seseorang lebih mudah untuk melihat gambar asli dan mengenalinya dengan benar. Yang paling jelas adalah metode untuk memperoleh informasi: mesin menerima gambar dalam bentuk digital, dan seseorang melihatnya dengan matanya sendiri. Untuk mesin, gambar adalah kumpulan data, membuat perubahan yang, Anda dapat mengubah klasifikasi. Bagi kami, citra kereta metro akan selalu menjadi kereta metro, bukan sekaleng susu, karena kami melihatnya.
Para ilmuwan juga menekankan bahwa tes semacam itu sulit untuk dievaluasi, karena seseorang bukan mesin, dan mesin bukan manusia. Sebagai contoh, peneliti berbicara tentang tes dengan "donat" dan "roda". Gambar-gambar ini mirip dengan "donat" dan "roda", karena sistem pengenalan mengklasifikasikan mereka seperti itu. Seseorang melihat bahwa mereka terlihat seperti "donat" dan "roda", tetapi ternyata tidak. Ini adalah perbedaan mendasar dalam persepsi informasi visual antara seseorang dan program.
Terima kasih atas perhatian Anda, tetap ingin tahu dan selamat bekerja, kawan.
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps hingga musim panas gratis ketika membayar untuk jangka waktu enam bulan, Anda dapat memesan di
sini .
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?