TL; DR: Empat tahun lalu, saya meninggalkan Google dengan ide alat baru untuk memonitor server. Idenya adalah untuk menggabungkan fungsi-fungsi yang biasanya terisolasi
mengumpulkan dan menganalisis log, mengumpulkan metrik,
peringatan, dan dashboard menjadi satu layanan. Salah satu prinsip - layanannya harus sangat
cepat , menyediakan pekerjaan yang mudah, interaktif, dan menyenangkan bagi para devs. Ini membutuhkan pemrosesan set data beberapa gigabyte dalam sepersekian detik, tanpa melampaui anggaran. Alat yang ada untuk bekerja dengan log seringkali lambat dan ceroboh, jadi kami menghadapi tugas yang baik: mengembangkan alat dengan benar untuk memberi pengguna sensasi baru dari pekerjaan.
Artikel ini menjelaskan bagaimana kami di Scalyr memecahkan masalah ini dengan menerapkan metode old-school, brute force, menghilangkan lapisan redundan dan menghindari struktur data yang kompleks. Anda dapat menerapkan pelajaran ini untuk tugas teknik Anda sendiri.
Kekuatan sekolah tua
Analisis log biasanya dimulai dengan pencarian: temukan semua pesan yang cocok dengan templat tertentu. Dalam Scalyr, ini adalah puluhan atau ratusan gigabyte log dari banyak server. Pendekatan modern, sebagai suatu peraturan, melibatkan pembangunan beberapa struktur data kompleks yang dioptimalkan untuk pencarian. Tentu saja, saya melihat ini di Google, di mana mereka cukup pandai dalam hal-hal seperti itu. Tapi kami sepakat dengan pendekatan yang lebih kasar: pemindaian log secara linier. Dan itu berhasil - kami menyediakan antarmuka dengan pencarian urutan besarnya lebih cepat dari pesaing (lihat animasi di akhir).
Wawasan utama adalah bahwa prosesor modern sangat cepat dalam operasi yang sederhana dan langsung. Ini mudah diabaikan dalam sistem yang kompleks dan berlapis-lapis yang bergantung pada kecepatan I / O dan operasi jaringan, dan sistem seperti itu sangat umum saat ini. Oleh karena itu, kami telah mengembangkan desain yang meminimalkan jumlah lapisan dan kelebihan sampah. Dengan beberapa prosesor dan server secara paralel, kecepatan pencarian mencapai 1 TB per detik.
Temuan kunci dari artikel ini:
- Pencarian kasar adalah pendekatan yang layak untuk memecahkan masalah skala besar yang nyata.
- Brute force adalah teknik desain, bukan pembebasan dari pekerjaan. Seperti teknik lainnya, teknik ini lebih cocok untuk beberapa masalah daripada yang lain, dan dapat diimplementasikan dengan buruk atau baik.
- Brute force sangat baik untuk kinerja yang stabil .
- Penggunaan brute force yang efektif membutuhkan optimalisasi kode dan penggunaan sumber daya yang memadai secara tepat waktu. Sangat cocok jika server Anda di bawah beban berat, tidak terkait dengan pengguna, dan operasi pengguna tetap menjadi prioritas.
- Kinerja tergantung pada desain seluruh sistem, dan bukan hanya pada algoritma loop internal.
(Artikel ini menjelaskan cara mencari data dalam memori. Dalam kebanyakan kasus, ketika pengguna mencari log, server Scalyr telah men-cache-nya. Pada artikel berikutnya kita akan membahas pencarian log yang tidak di-cache. Prinsip yang sama berlaku: kode efisien, metode brute force dengan komputasi besar sumber daya).
Metode kekerasan
Secara tradisional, pencarian dalam dataset besar dilakukan menggunakan indeks kata kunci. Sebagaimana diterapkan pada log server, ini berarti mencari setiap kata unik dalam log. Untuk setiap kata, Anda perlu membuat daftar semua inklusi. Ini membuatnya mudah untuk menemukan semua pesan dengan kata ini, misalnya, 'error', 'firefox' atau "transaction_16851951" - lihat saja di indeks.
Saya menggunakan pendekatan ini di Google dan itu berhasil dengan baik. Tetapi dalam Scalyr, kita melihat log untuk byte demi byte.
Mengapa Dari sudut pandang algoritmik abstrak, indeks kata kunci jauh lebih efektif daripada pencarian kasar. Namun, kami tidak menjual algoritma, kami menjual kinerja. Dan kinerjanya tidak hanya algoritma, tetapi juga rekayasa sistem. Kita harus mempertimbangkan segalanya: jumlah data, jenis pencarian, perangkat keras yang tersedia dan konteks perangkat lunak. Kami memutuskan bahwa untuk masalah khusus kami, opsi seperti 'grep' lebih baik daripada indeks.
Indeks memang bagus, tetapi mereka memiliki keterbatasan. Satu kata mudah ditemukan. Tetapi menemukan pesan dengan beberapa kata, seperti 'googlebot' dan '404', sudah jauh lebih rumit. Mencari frasa seperti 'pengecualian tanpa tertangkap' memerlukan indeks yang lebih rumit yang tidak hanya merekam semua pesan dengan kata itu, tetapi juga lokasi spesifik kata tersebut.
Kesulitan sebenarnya datang ketika Anda tidak mencari kata-kata. Misalkan Anda ingin melihat berapa banyak lalu lintas yang berasal dari bot. Pikiran pertama adalah mencari log untuk kata 'bot'. Jadi, Anda akan menemukan beberapa bot: Googlebot, Bingbot dan banyak lainnya. Tapi di sini 'bot' bukan sebuah kata, tetapi bagian dari itu. Jika kami mencari 'bot' di indeks, kami tidak akan menemukan pesan dengan kata 'Googlebot'. Jika Anda memeriksa setiap kata dalam indeks dan kemudian memindai indeks untuk kata kunci yang ditemukan, pencarian akan sangat melambat. Akibatnya, beberapa program untuk bekerja dengan log tidak memungkinkan pencarian di bagian kata atau (paling-paling) mengizinkan penggunaan sintaksis khusus dengan kinerja lebih rendah. Kami ingin menghindari ini.
Masalah lainnya adalah tanda baca. Ingin menemukan semua permintaan dari
50.168.29.7 ? Bagaimana dengan debugging log yang berisi
[error] ? Indeks biasanya melewati tanda baca.
Akhirnya, insinyur menyukai alat yang kuat, dan kadang-kadang masalah hanya dapat diselesaikan dengan ekspresi reguler. Indeks kata kunci tidak cocok untuk ini.
Selain itu, indeksnya
kompleks . Setiap pesan harus ditambahkan ke beberapa daftar kata kunci. Daftar ini harus selalu disimpan dalam format yang ramah-pencarian. Kueri dengan frasa, fragmen kata, atau ekspresi reguler harus diterjemahkan ke dalam operasi dengan beberapa daftar, dan hasilnya dipindai dan digabungkan untuk mendapatkan kumpulan hasil. Dalam konteks layanan multi-pengguna skala besar, kompleksitas ini menciptakan masalah kinerja yang tidak terlihat saat menganalisis algoritma.
Indeks kata kunci juga memakan banyak ruang, dan penyimpanan adalah item biaya utama dalam sistem manajemen log.
Di sisi lain, banyak daya komputasi dapat dihabiskan untuk setiap pencarian. Pengguna kami menghargai pencarian berkecepatan tinggi untuk kueri unik, tetapi kueri semacam itu relatif jarang. Untuk kueri penelusuran khas, misalnya, untuk dasbor, kami menggunakan teknik khusus (kami akan menjelaskannya di artikel berikutnya). Pertanyaan lain sangat jarang, jadi Anda jarang perlu memproses lebih dari satu pada satu waktu. Tetapi ini tidak berarti bahwa server kami tidak sibuk: mereka sibuk dengan pekerjaan menerima, menganalisis dan mengompresi pesan baru, mengevaluasi peringatan, mengompresi data lama dan sebagainya. Dengan demikian, kami memiliki persediaan prosesor yang cukup besar yang dapat digunakan untuk memenuhi permintaan.
Brute force berfungsi jika Anda memiliki masalah brute force (dan banyak kekuatan)
Brute force bekerja paling baik pada tugas-tugas sederhana dengan loop internal kecil. Seringkali Anda dapat mengoptimalkan loop dalam untuk bekerja pada kecepatan yang sangat tinggi. Jika kodenya rumit, akan lebih sulit untuk mengoptimalkannya.
Awalnya, kode pencarian kami memiliki loop dalam yang agak besar. Kami menyimpan pesan di halaman 4K; setiap halaman berisi beberapa pesan (dalam UTF-8) dan metadata untuk setiap pesan. Metadata adalah struktur di mana panjang nilai, ID pesan internal, dan bidang lainnya dikodekan. Loop pencarian tampak seperti ini:

Ini adalah opsi yang disederhanakan dibandingkan dengan kode aktual. Tetapi bahkan di sini Anda dapat melihat beberapa penempatan objek, salinan data, dan panggilan fungsi. JVM cukup baik mengoptimalkan pemanggilan fungsi dan mengalokasikan objek fana, sehingga kode ini bekerja lebih baik daripada yang kita layak. Selama pengujian, klien menggunakannya dengan cukup sukses. Tetapi pada akhirnya kami pindah ke tingkat yang baru.
(Anda mungkin bertanya mengapa kami menyimpan pesan dalam format ini dengan halaman 4K, teks dan metadata, daripada bekerja secara langsung dengan log. Ada banyak alasan mengapa mesin Scalyr internal lebih mirip database terdistribusi daripada sistem file Pencarian teks sering dikombinasikan dengan filter gaya DBMS di bidang setelah penguraian log. Kita dapat mencari ribuan log pada saat yang bersamaan, dan file teks sederhana tidak cocok untuk kontrol transaksional, direplikasi, dan didistribusikan data).
Awalnya, sepertinya kode seperti itu tidak terlalu cocok untuk optimisasi dengan metode brute force. "Pekerjaan nyata" di
String.indexOf() bahkan tidak mendominasi profil CPU. Artinya, optimalisasi hanya metode ini tidak akan membawa efek signifikan.
Kebetulan kami menyimpan metadata di awal setiap halaman, dan teks semua pesan di UTF-8 dikemas di ujung lainnya. Mengambil keuntungan dari ini, kami menulis ulang loop pencarian di seluruh halaman sekaligus:
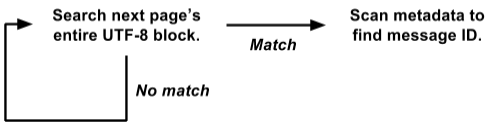
Versi ini bekerja langsung pada tampilan
raw byte[] dan mencari semua pesan sekaligus di seluruh halaman 4K.
Ini jauh lebih mudah untuk dioptimalkan untuk brute force. Siklus pencarian internal dipanggil secara bersamaan untuk seluruh halaman 4K, dan tidak terpisah untuk setiap pesan. Tidak ada penyalinan data, tidak ada pemilihan objek. Dan operasi yang lebih kompleks dengan metadata dipanggil hanya dengan hasil positif, dan bukan untuk setiap pesan. Dengan demikian, kami menghilangkan satu ton overhead, dan sisa beban terkonsentrasi dalam siklus pencarian internal kecil, yang cocok untuk optimasi lebih lanjut.
Algoritme pencarian kami yang sebenarnya didasarkan pada
ide hebat dari Leonid Volnitsky . Ini mirip dengan algoritma Boyer-Moore dengan melewatkan panjang string pencarian di setiap langkah. Perbedaan utama adalah bahwa ia memeriksa dua byte sekaligus untuk meminimalkan kecocokan yang salah.
Implementasi kami memerlukan pembuatan tabel pencarian 64K untuk setiap pencarian, tetapi ini tidak masuk akal dibandingkan dengan gigabyte data yang kami cari. Loop dalam memproses beberapa gigabytes per detik pada satu inti. Dalam praktiknya, kinerja yang stabil adalah sekitar 1,25 GB per detik pada setiap inti, dan ada potensi untuk peningkatan. Anda dapat menghilangkan beberapa overhead di luar loop dalam, dan kami berencana untuk bereksperimen dengan loop dalam di C sebagai ganti Java.
Terapkan kekuatan
Kami membahas bahwa pencarian log dapat diimplementasikan "secara kasar", tetapi berapa banyak "kekuatan" yang kita miliki? Banyak.
1 inti : bila digunakan dengan benar, satu inti dari prosesor modern itu sendiri cukup kuat.
8 core : saat ini kami sedang bekerja di server SSD Amazon hi1.4xlarge dan i2.4xlarge, yang masing-masing memiliki 8 core (16 utas). Seperti disebutkan di atas, biasanya kernel ini sibuk dengan operasi latar belakang. Ketika pengguna melakukan pencarian, operasi latar belakang dijeda, membebaskan semua 8 core untuk pencarian. Pencarian biasanya selesai dalam sepersekian detik, setelah itu pekerjaan latar belakang dilanjutkan (program pengontrol memastikan bahwa rentetan permintaan pencarian tidak akan mengganggu pekerjaan latar belakang yang penting).
16 core : untuk keandalan, kami mengatur server menjadi grup master / slave. Setiap master memiliki satu server SSD dan satu bawahan EBS. Jika server utama macet, server pada SSD segera menggantikannya. Hampir sepanjang waktu, master dan slave berfungsi dengan baik, sehingga setiap blok data dapat dicari di dua server yang berbeda (server slave EBS memiliki prosesor yang lemah, jadi kami tidak mempertimbangkannya). Kami membagi tugas di antara mereka, sehingga kami memiliki total 16 core yang tersedia.
Banyak core : dalam waktu dekat kami akan mendistribusikan data di antara server sehingga mereka semua berpartisipasi dalam pemrosesan setiap permintaan non-sepele. Setiap inti akan bekerja. [Catatan:
kami mengimplementasikan rencana dan meningkatkan kecepatan pencarian menjadi 1 TB / s, lihat catatan di akhir artikel ].
Kesederhanaan Memberikan Keandalan
Keuntungan lain dari brute force adalah kinerjanya yang relatif stabil. Biasanya, pencarian tidak terlalu peka terhadap detail tugas dan kumpulan data (saya pikir itulah sebabnya disebut "kasar").
Indeks kata kunci terkadang menghasilkan hasil yang sangat cepat, tetapi dalam kasus lain tidak. Misalkan Anda memiliki 50 GB log di mana istilah 'customer_5987235982' muncul tepat tiga kali. Pencarian dengan istilah ini menghitung tiga lokasi langsung dari indeks dan berakhir secara instan. Tetapi pencarian wildcard yang kompleks dapat memindai ribuan kata kunci dan membutuhkan banyak waktu.
Di sisi lain, pencarian brute force untuk setiap kueri dilakukan dengan kecepatan yang kurang lebih sama. Pencarian kata-kata panjang lebih baik, tetapi bahkan pencarian satu karakter pun cukup cepat.
Kesederhanaan metode brute force berarti produktivitasnya mendekati maksimum teoretis. Ada lebih sedikit opsi untuk overload disk yang tidak terduga, konflik kunci, pengejaran pointer, dan ribuan alasan lain untuk kegagalan. Saya baru saja melihat permintaan yang dibuat oleh pengguna Scalyr minggu lalu di server tersibuk kami. Ada 14.000 permintaan. Tepatnya delapan dari mereka membutuhkan lebih dari satu detik; 99% dilakukan dalam 111 milidetik (jika Anda belum menggunakan alat analisis log, percayalah:
ini cepat ).
Kinerja yang stabil dan andal adalah penting untuk kenyamanan menggunakan layanan ini. Jika secara berkala melambat, pengguna akan menganggapnya tidak dapat diandalkan dan enggan menggunakannya.
Log Search in Action
Inilah sedikit animasi yang menunjukkan pencarian Scalyr beraksi. Kami memiliki akun demo tempat kami mengimpor setiap acara di setiap repositori Github publik. Dalam demo ini, saya mempelajari data untuk minggu ini: sekitar 600 MB log mentah.
Video direkam langsung, tanpa persiapan khusus, di desktop saya (sekitar 5.000 kilometer dari server). Kinerja yang akan Anda lihat sebagian besar disebabkan oleh
optimalisasi klien web , serta backend yang cepat dan andal. Setiap kali ada jeda tanpa indikator 'memuat', saya jeda sehingga Anda dapat membaca apa yang akan saya klik.

Kesimpulannya
Saat memproses data dalam jumlah besar, penting untuk memilih algoritma yang baik, tetapi "baik" tidak berarti "mewah". Pikirkan tentang bagaimana kode Anda akan bekerja dalam praktiknya. Beberapa faktor yang dapat menjadi sangat penting di dunia nyata jatuh dari analisis teoritis algoritma. Algoritma yang lebih sederhana lebih mudah untuk dioptimalkan dan lebih stabil dalam situasi batas.
Pikirkan juga konteks di mana kode akan dieksekusi. Dalam kasus kami, kami membutuhkan server yang cukup kuat untuk mengelola tugas latar belakang. Pengguna relatif jarang melakukan pencarian, sehingga kami dapat meminjam seluruh kelompok server untuk waktu singkat yang diperlukan untuk menyelesaikan setiap pencarian.
Menggunakan brute force, kami menerapkan pencarian cepat, andal, fleksibel pada satu set log. Kami berharap ide-ide ini akan berguna untuk proyek Anda.
Sunting:
Judul dan teks berubah dari “Pencarian pada 20 GB per detik” menjadi “Pencarian pada 1 TB per detik” untuk mencerminkan peningkatan kinerja selama beberapa tahun terakhir. Peningkatan kecepatan ini terutama disebabkan oleh perubahan jenis dan jumlah server EC2 yang kami tingkatkan hari ini untuk melayani basis klien yang meningkat. Dalam waktu dekat, perubahan diharapkan akan memberikan peningkatan tajam dalam efisiensi kerja, dan kami menantikan kesempatan untuk mengetahuinya.