Pada bagian
pertama cerita, berdasarkan
presentasi oleh Dmitry Stogov dari Zend Technologies di HighLoad ++, kami memahami struktur internal PHP. Kami belajar secara terperinci dan langsung bagaimana perubahan dalam struktur data dasar memungkinkan PHP 7 untuk mempercepat lebih dari dua kali. Ini bisa dihentikan, tetapi sudah dalam versi 7.1, para pengembang melangkah lebih jauh, karena mereka masih punya banyak ide untuk optimasi.
Akumulasi pengalaman bekerja pada JIT sebelum ketujuh sekarang dapat ditafsirkan, melihat hasil dalam 7.0 tanpa JIT dan pada hasil HHVM dengan JIT. Dalam PHP 7.1, diputuskan untuk tidak bekerja dengan JIT, tetapi sekali lagi untuk beralih ke penerjemah. Jika sebelumnya optimasi menyangkut interpreter, maka dalam artikel ini kita akan melihat optimasi bytecode menggunakan inferensi tipe yang diterapkan untuk JIT kita.
Di bawah potongan, Dmitry Stogov akan menunjukkan bagaimana semua ini bekerja, menggunakan contoh sederhana.
Optimasi bytecode
Di bawah ini adalah bytecode di mana kompiler PHP standar mengkompilasi fungsi. Single-pass - cepat dan bodoh, tetapi dapat melakukan tugasnya pada setiap permintaan HTTP lagi (jika OPcache tidak terhubung).

Optimalisasi OPcache
Dengan munculnya OPcache, kami mulai mengoptimalkannya. Beberapa metode optimisasi
telah lama dimasukkan ke dalam OPcache , misalnya, metode optimasi celah - ketika kita melihat kode melalui lubang intip, mencari pola yang sudah dikenal, dan menggantinya dengan heuristik. Metode ini terus digunakan dalam 7.0. Misalnya, kami memiliki dua operasi: penambahan dan penugasan.

Mereka dapat digabungkan menjadi satu operasi penugasan majemuk, yang melakukan penambahan langsung pada hasilnya:
ASSIGN_ADD $sum, $i . Contoh lain adalah variabel post-increment yang secara teoritis dapat mengembalikan beberapa jenis hasil.

Ini mungkin bukan nilai skalar dan harus dihapus. Untuk melakukan ini, gunakan instruksi
FREE mengikutinya. Tetapi jika Anda mengubahnya menjadi pra-kenaikan, maka instruksi
FREE tidak diperlukan.

Pada akhirnya ada dua pernyataan
RETURN : yang pertama adalah refleksi langsung dari pernyataan RETURN dalam teks sumber, dan yang kedua ditambahkan oleh kompiler bodoh dengan braket penutup. Kode ini tidak akan pernah tercapai dan dapat dihapus.
Hanya ada empat instruksi yang tersisa di loop. Tampaknya tidak ada yang lebih lanjut untuk dioptimalkan, tetapi tidak untuk kita.
Lihatlah
$i++ dan instruksi yang sesuai - pra-kenaikan
PRE_INC . Setiap kali dieksekusi:
- perlu memeriksa jenis variabel apa yang datang;
- apakah itu
is_long ; - melakukan kenaikan;
- periksa overflow;
- pergi ke yang berikutnya;
- mungkin periksa pengecualian.
Tetapi seseorang, hanya dengan melihat kode PHP, akan melihat bahwa variabel
$i terletak pada rentang dari 0 hingga 100, dan tidak mungkin ada overflow, pemeriksaan jenis tidak diperlukan, dan tidak ada pengecualian juga.
Di PHP 7.1, kami mencoba mengajarkan kompiler untuk memahami hal ini .
Optimalisasi Grafik Aliran Kontrol

Untuk melakukan ini, Anda perlu menyimpulkan tipe, dan untuk memasukkan tipe, Anda harus terlebih dahulu membangun representasi formal dari aliran data yang dipahami komputer. Tapi kita akan mulai dengan membangun Grafik Aliran Kontrol, grafik ketergantungan kontrol. Awalnya, kami memecah kode menjadi blok-blok dasar - satu set instruksi dengan satu input dan satu output. Oleh karena itu, kami memotong kode di tempat-tempat di mana transisi terjadi, yaitu label L0, L1. Kami juga memotongnya setelah operator cabang bersyarat dan tanpa syarat, dan kemudian menghubungkannya dengan busur yang menunjukkan ketergantungan untuk kontrol.

Jadi kami mendapat CFG.
Optimalisasi Formulir Penugasan Tunggal Statis
Nah, sekarang kita membutuhkan ketergantungan data. Untuk melakukan ini, kami menggunakan Formulir Penugasan Tunggal Statis - representasi populer di dunia pengoptimal penyusun. Ini menyiratkan bahwa nilai setiap variabel hanya dapat ditetapkan satu kali.

Untuk setiap variabel, kami menambahkan indeks, atau nomor reinkarnasi. Di setiap tempat di mana tugas berlangsung, kami menempatkan indeks baru, dan di mana kami menggunakannya - sampai tanda tanya, karena tidak selalu dikenal di mana-mana. Misalnya, dalam instruksi
IS_SMALLER $ saya dapat berasal dari blok L0 dengan nomor 4, dan dari blok pertama dengan nomor 2.
Untuk mengatasi masalah ini, SSA memperkenalkan
fungsi pseudo-Phi , yang, jika perlu, dimasukkan pada awal blok dasar->, mengambil semua jenis indeks dari satu variabel yang datang ke blok-dasar dari tempat yang berbeda, dan menciptakan reinkarnasi baru dari variabel. Ini adalah variabel yang kemudian digunakan untuk menghilangkan ambiguitas.

Mengganti semua tanda tanya dengan cara ini, kami akan membangun SSA.
Ketik optimasi
Sekarang kami menyimpulkan tipe - seolah-olah mencoba mengeksekusi kode ini langsung pada manajemen.

Di blok pertama, variabel diberi nilai konstan - nol, dan kami tahu pasti bahwa variabel-variabel ini akan bertipe panjang. Selanjutnya adalah fungsi Phi. Lama tiba di input, dan kami tidak tahu nilai-nilai variabel lain yang berasal dari cabang lain.

Kami percaya bahwa output phi () kami akan memiliki panjang.

Kami mendistribusikan lebih lanjut. Kami sampai pada fungsi tertentu, misalnya,
ASSIGN_ADD dan
PRE_INC . Jumlahkan dua panjang. Hasilnya bisa panjang atau ganda jika overflow terjadi.

Nilai-nilai ini lagi jatuh ke dalam fungsi Phi, penyatuan set jenis yang mungkin tiba di cabang yang berbeda terjadi. Baik dan seterusnya, kami terus menyebar hingga mencapai titik yang pasti dan semuanya beres.

Kami mendapat satu set nilai tipe yang mungkin di setiap titik dalam program. Ini sudah bagus. Komputer sudah tahu bahwa
$i hanya bisa panjang atau ganda, dan dapat mengecualikan beberapa cek yang tidak perlu. Tapi kita tahu dobel
$i tidak bisa. Bagaimana kita tahu Dan kami melihat kondisi yang membatasi pertumbuhan
$i dalam siklus hingga kemungkinan overflow. Kami akan mengajarkan komputer untuk melihat ini.
Optimalisasi Propagasi Rentang
Dalam instruksi
PRE_INC kami tidak pernah menemukan bahwa saya hanya dapat berupa bilangan bulat - biayanya panjang atau dua kali lipat. Ini terjadi karena kami tidak mencoba menyimpulkan rentang yang mungkin. Lalu kita bisa menjawab pertanyaan apakah overflow akan terjadi atau tidak.
Output rentang ini dibuat dengan cara yang serupa, tetapi sedikit lebih kompleks. Sebagai hasilnya, kita mendapatkan rentang variabel tetap
$i dengan indeks 2, 4, 6 7, dan sekarang kita dapat dengan yakin mengatakan bahwa kenaikan
$i tidak akan menyebabkan overflow.

Dengan menggabungkan kedua hasil ini, kita dapat mengatakan dengan pasti bahwa variabel ganda
$i tidak pernah
$i menjadi.

Yang kami dapatkan belum optimal, ini informasi untuk optimisasi! Pertimbangkan
ASSIGN_ADD . Secara umum, nilai lama dari jumlah yang datang ke instruksi ini bisa, misalnya, sebuah objek. Kemudian, setelah penambahan, nilai lama seharusnya dihapus. Tetapi dalam kasus kami, kami tahu pasti bahwa ada panjang atau ganda, yaitu nilai skalar. Tidak ada kerusakan yang diperlukan, kami dapat mengganti
ASSIGN_ADD dengan
ADD - instruksi yang lebih mudah.
ADD menggunakan variabel
sum sebagai argumen dan nilai.

Untuk operasi pra-kenaikan, kami tahu pasti bahwa operan selalu panjang, dan bahwa luapan tidak dapat terjadi. Kami menggunakan penangan yang sangat khusus untuk instruksi ini, yang hanya akan melakukan tindakan yang diperlukan tanpa pemeriksaan.

Sekarang bandingkan variabel di akhir loop. Kita tahu bahwa nilai variabel hanya akan panjang - Anda dapat segera memeriksa nilai ini dengan membandingkannya dengan seratus. Jika sebelumnya kita mencatat hasil verifikasi dalam variabel sementara, dan sekali lagi memeriksa variabel sementara untuk benar / salah, sekarang ini dapat dilakukan dengan satu instruksi, yaitu disederhanakan.

Hasil bytecode dibandingkan dengan yang asli.

Hanya ada 3 instruksi yang tersisa dalam siklus, dan dua di antaranya sangat terspesialisasi. Akibatnya, kode di sebelah kanan
3 kali lebih cepat dari aslinya.
Penangan yang sangat terspesialisasi
Setiap
PHP crawl handler hanyalah fungsi C. Di sebelah kiri adalah penangan standar, dan di kanan atas adalah yang sangat terspesialisasi. Yang kiri memeriksa: jenis operan, jika overflow telah terjadi, jika pengecualian telah terjadi. Yang benar hanya menambahkan satu dan hanya itu. Diterjemahkan ke dalam 4 instruksi mesin. Jika kita melangkah lebih jauh dan melakukan JIT, maka kita hanya perlu satu kali instruksi
incl .

Apa selanjutnya
Kami terus meningkatkan kecepatan cabang PHP 7 tanpa JIT.
PHP 7.1 lagi akan menjadi 60% lebih cepat pada tes sintetik khas, tetapi pada aplikasi nyata ini hampir tidak memberikan kemenangan - hanya 1-2% di WordPress. Ini tidak terlalu menarik. Sejak Agustus 2016, ketika cabang 7.1 dibekukan untuk perubahan besar, kami kembali mulai bekerja pada JIT untuk PHP 7.2 atau lebih tepatnya PHP 8.
Dalam upaya baru, kami menggunakan
DynAsm untuk menghasilkan kode, yang dikembangkan oleh Mike Paul
untuk LuaJIT-2 . Itu bagus karena
menghasilkan kode dengan sangat cepat : fakta bahwa notulen dikompilasi dalam versi JIT pada LLVM sekarang terjadi dalam 0,1-0,2 dtk. Sudah hari ini,
akselerasi di bench.php di JIT adalah 75 kali lebih cepat dari PHP 5.
Tidak ada akselerasi pada aplikasi nyata, dan ini adalah tantangan berikutnya bagi kami. Sebagian, kami mendapatkan kode optimal, tetapi setelah mengkompilasi terlalu banyak skrip PHP, kami menyumbat cache prosesor, sehingga tidak bekerja lebih cepat. Dan bukan kecepatan kode adalah hambatan dalam aplikasi nyata ...
Mungkin DynAsm dapat digunakan untuk mengkompilasi hanya fungsi-fungsi tertentu yang akan dipilih oleh programmer atau heuristik berbasis penghitung - berapa kali suatu fungsi dipanggil, berapa kali siklus diulang di dalamnya, dll.
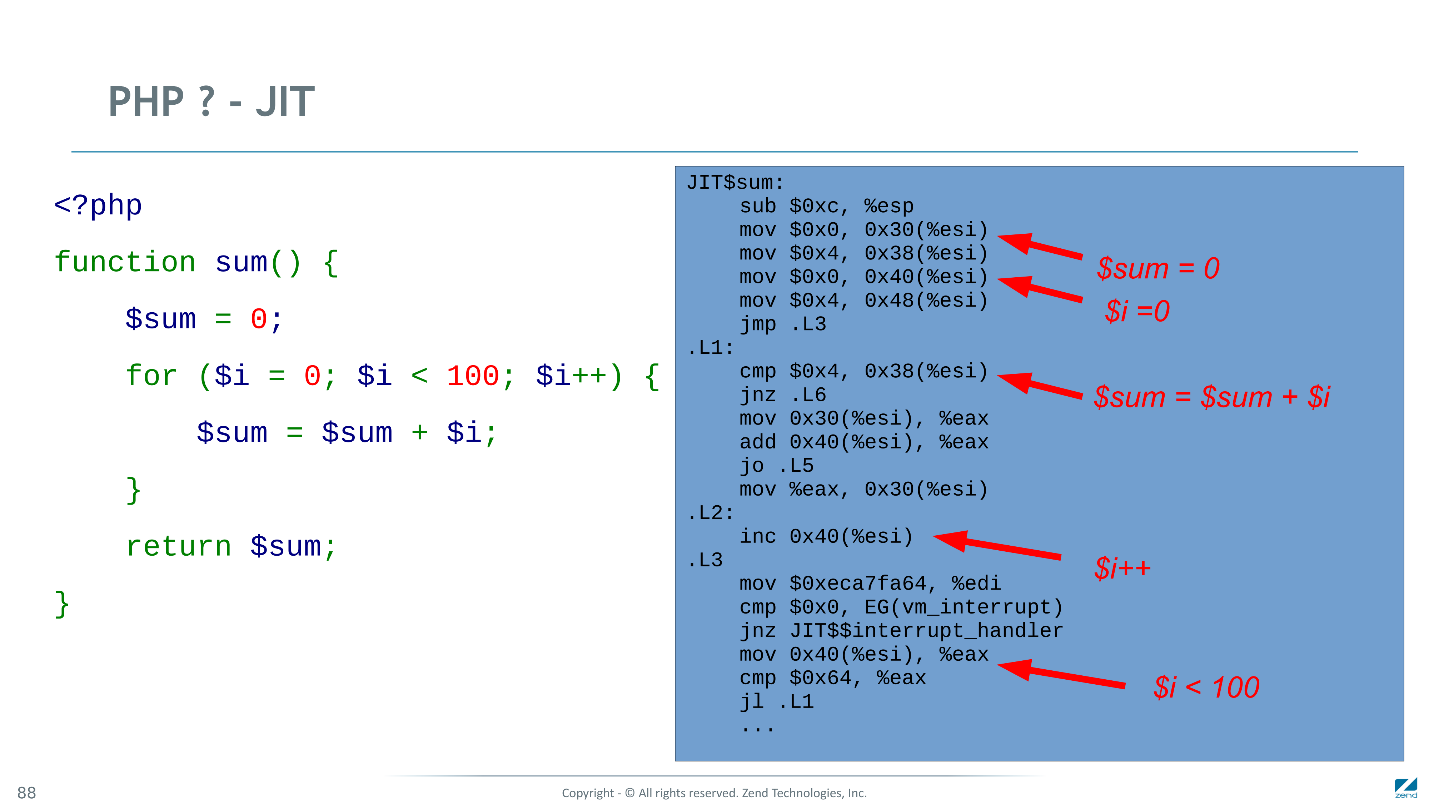
Di bawah ini adalah kode mesin yang dihasilkan JIT kami untuk contoh yang sama. Banyak instruksi dikompilasi secara optimal: kenaikan menjadi satu instruksi CPU, inisialisasi variabel menjadi konstanta menjadi dua. Di mana jenis tidak menetas, Anda harus repot-repot lagi.
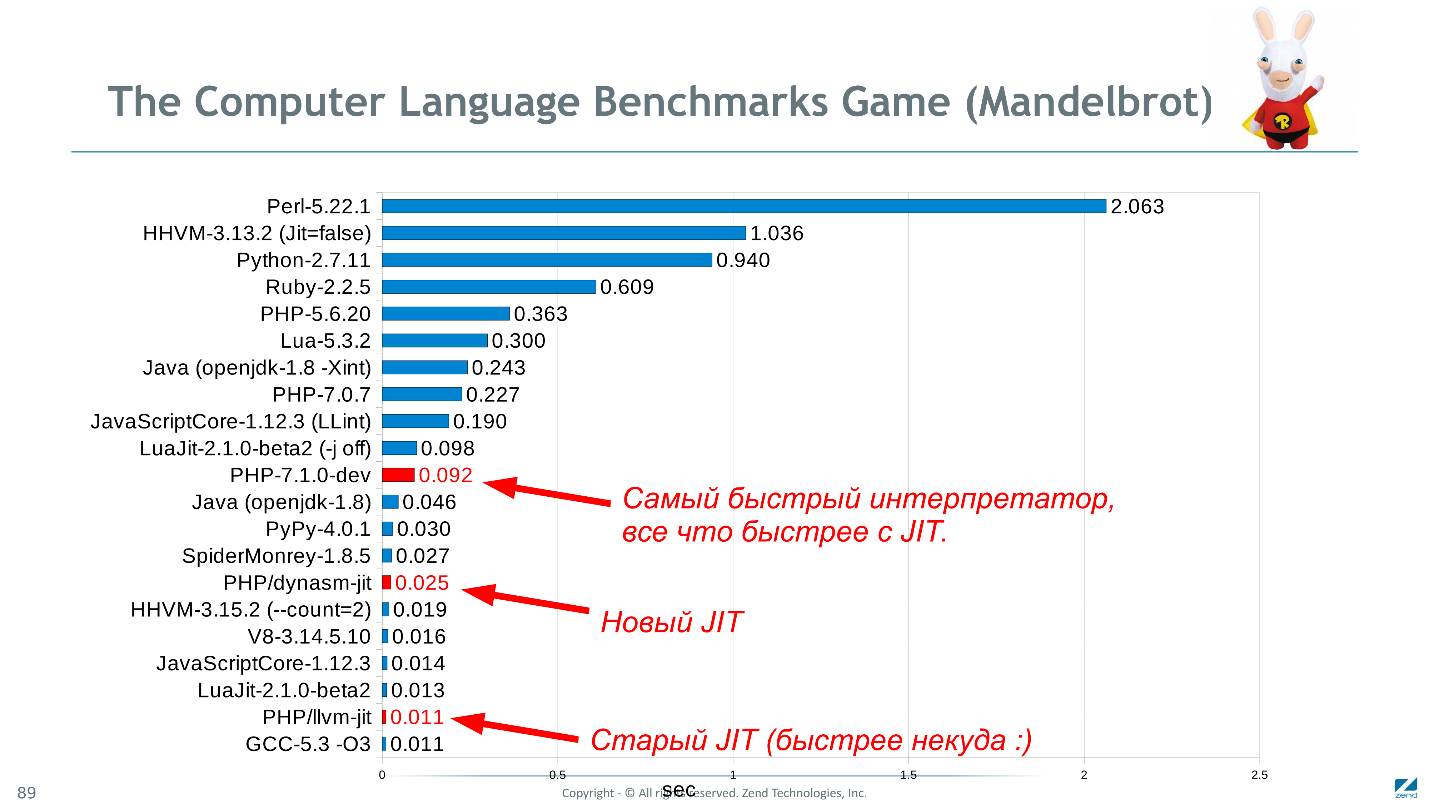
Kembali ke gambar judul, PHP, dibandingkan dengan bahasa serupa di tes Mandelbrot, menunjukkan hasil yang sangat baik (meskipun data relevan pada akhir 2016).
Diagram menunjukkan waktu eksekusi dalam detik, lebih sedikit lebih baik.Mungkin
Mandelbrot bukan tes terbaik. Ini adalah komputasi, tetapi sederhana dan diimplementasikan secara merata dalam semua bahasa. Akan menyenangkan untuk mengetahui seberapa cepat Wordpress akan bekerja di C ++, tetapi hampir tidak ada keanehan siap untuk menulis ulang hanya untuk memeriksa, dan bahkan mengulangi semua penyimpangan dari kode PHP. Jika Anda memiliki ide untuk serangkaian tolok ukur yang lebih memadai - sarankan.
Kami akan bertemu di PHP Rusia pada 17 Mei , kami akan membahas prospek dan pengembangan ekosistem dan pengalaman menggunakan PHP untuk proyek yang benar-benar kompleks dan keren. Sudah bersama kami:
Tentu saja, ini jauh dari semua. Dan Call for Papers masih ditutup, hingga 1 April, kami menunggu aplikasi dari mereka yang dapat menerapkan pendekatan modern dan praktik terbaik untuk mengimplementasikan layanan PHP keren. Jangan takut bersaing dengan pembicara terkemuka - kami mencari pengalaman dalam menggunakan apa yang mereka lakukan dalam proyek nyata dan akan membantu menunjukkan manfaat dari kasus Anda.