Ketika bekerja dengan beberapa klien sekaligus, penting untuk dengan cepat menganalisis banyak informasi di berbagai akun dan laporan. Ketika ada lebih dari 10 pelanggan, pemasar tidak lagi punya waktu untuk terus memantau statistik. Tapi ada cara.
Di artikel ini, saya akan berbicara tentang cara memantau akun iklan menggunakan API dan Python.
Di pintu keluar, kami akan menerima permintaan ke Yandex.Direct API, yang dengannya kami akan menerima statistik kampanye iklan dan akan dapat memproses data ini.
Untuk ini kita perlu:
- Dapatkan Token API Yandex Direct
- Tulis permintaan server
- Impor data ke dalam DataFrame
Impor perpustakaan
Anda perlu mengimpor pustaka yang digunakan dalam kueri, serta panda dan DataFrame.
Semua impor akan terlihat seperti ini:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
Menerima token
Saat ini saya tidak bisa membedakan dari dokumentasi API Direct, jadi saya akan meninggalkan tautan.
(
Petunjuk untuk mendapatkan token )
Kami sedang menulis permintaan ke server API Yandex.Direct
Salin permintaan dari dokumentasi APIUbah permintaan.- Resepkan token Anda dan login
Token.
token = 'blaBlaBLAblaBLABLABLAblabla'
Login
clientLogin = 'e-66666666'
- Kami menyesuaikan badan permintaan untuk diri kami sendiri.
Dari sini
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
Lakukan itu
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
Dalam
SelectionCriteria kita menulis bagaimana kita akan memilih data. Secara default, 2 tanggal ditulis di sana, tetapi agar tidak harus terus mengubahnya, kami akan mengganti periode waktu dengan "5 hari terakhir".
Kami menetapkan filter untuk data . Ini terutama diperlukan agar tidak mendapatkan nilai kosong. Masalahnya adalah bahwa Direct menunjukkan data yang hilang sebagai dua minus, karena tipe data dari seluruh kolom berubah, setelah itu Anda tidak dapat melakukan operasi matematika tanpa gerakan yang tidak perlu.
FieldNames Kami menulis di sini data yang Anda butuhkan. Saya mendaftarkan bidang yang saya gunakan untuk analisis, daftar Anda mungkin berbeda.
Jenis Laporan Jenis laporan ditulis dalam bidang ini, untuk kampanye dibutuhkan laporan ini.
Anda harus mendapatkan sesuatu seperti ini.
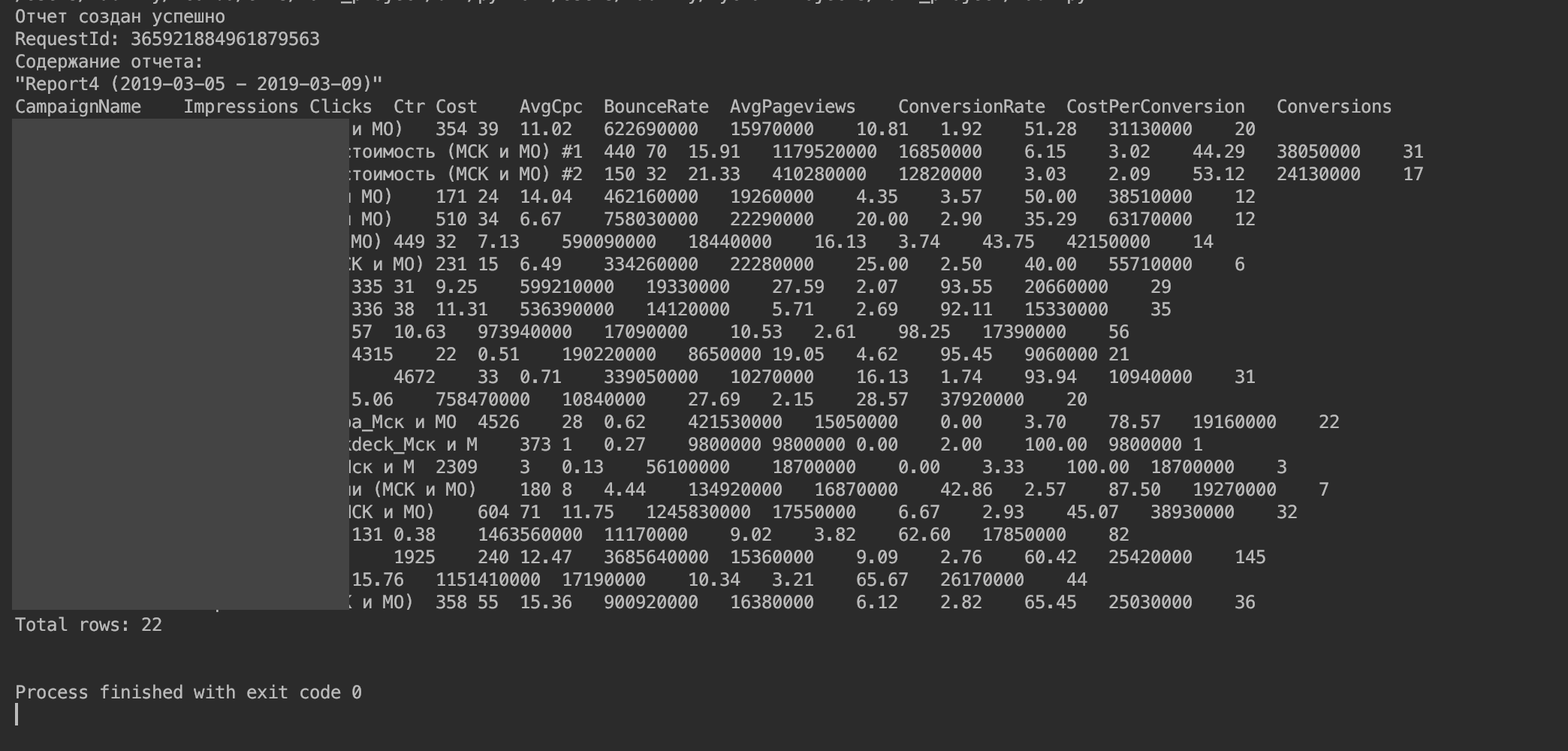
5. Impor data ke dalam DataFrame.
(DataFrame mungkin merupakan cara yang paling tepat untuk bekerja dengan data ini.)
Saya dapat mengimplementasikan fungsi ini dengan menulis dan membaca file csv.
Kami menemukan di bagian yang bertanggung jawab untuk output statistik - ini adalah "req.text".
Kami menghapus output standar dari program untuk menulis ke file. Untuk melakukan ini, ubah semua kesimpulan dalam kode 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
Pada:
format(u(req.text))
Sekarang impor respons server ke dalam DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
Langkah demi langkah:
- Buka (dan secara otomatis buat) file cashe.csv untuk ditulis
- Kami menulis respons server ke dalamnya
- Tutup file
- Buka file sebagai DataFrame (tentukan nama file, di mana baris adalah header tabel, apa pembagi antara data, di mana kolom adalah indeks)
Ternyata yang berikut ini:
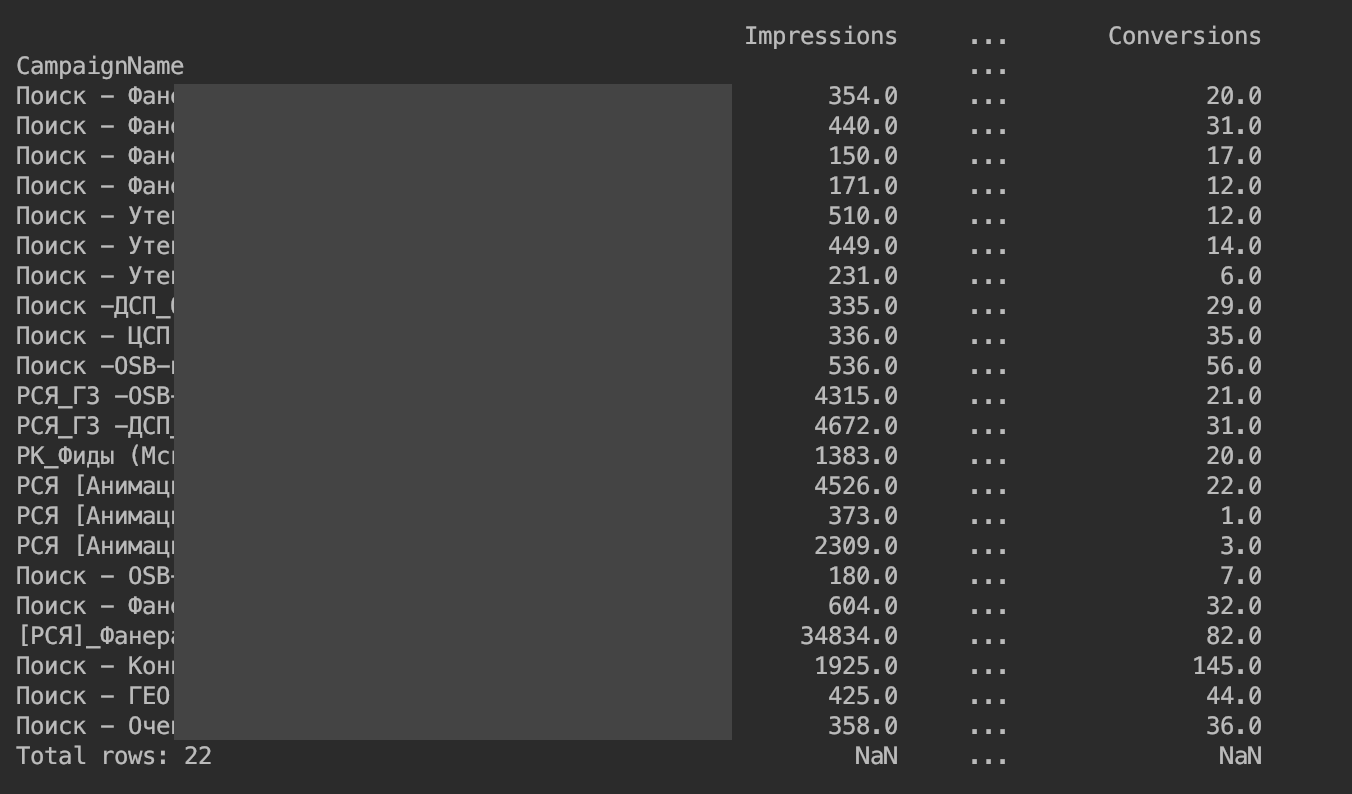
Kami menghapus batasan pada output kolom:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
Sekarang semuanya ditampilkan:
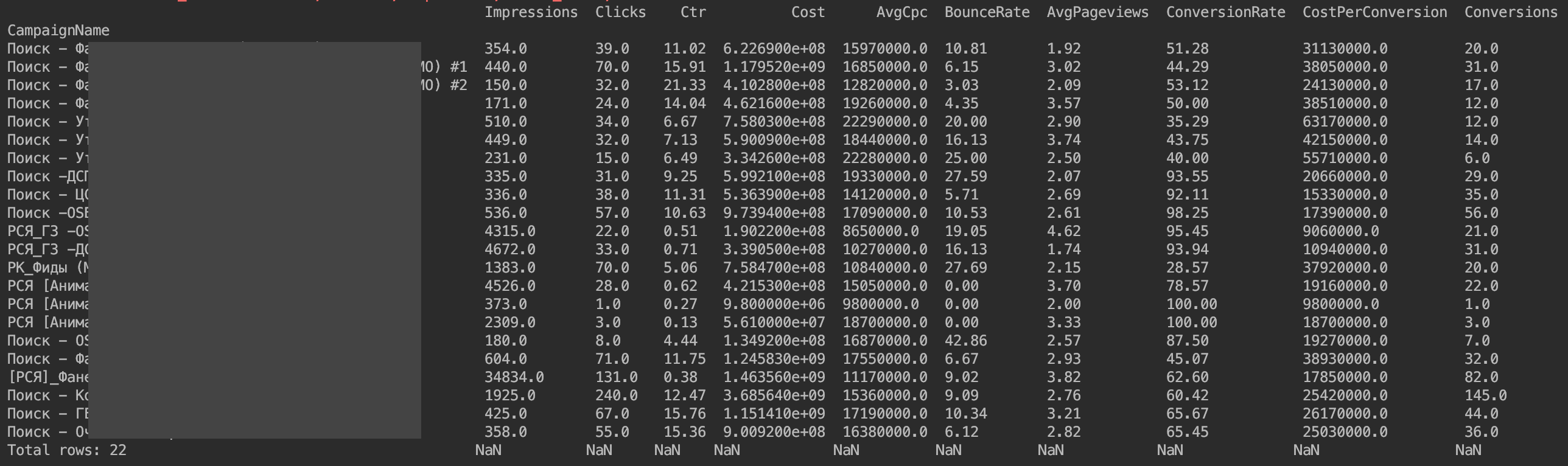
Satu-satunya masalah adalah bahwa nilai moneter tidak ditampilkan seperti yang diinginkan. Ini adalah fitur implementasi API Yandex.Direct. Kita hanya perlu membagi nilai moneter dengan 1.000.000.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
Saya juga menyarankan segera mengurutkan berdasarkan jumlah klik
f=f.sort_values(by=['Clicks'], ascending=False)
Jadi kami menyiapkan DataFrame untuk dianalisis
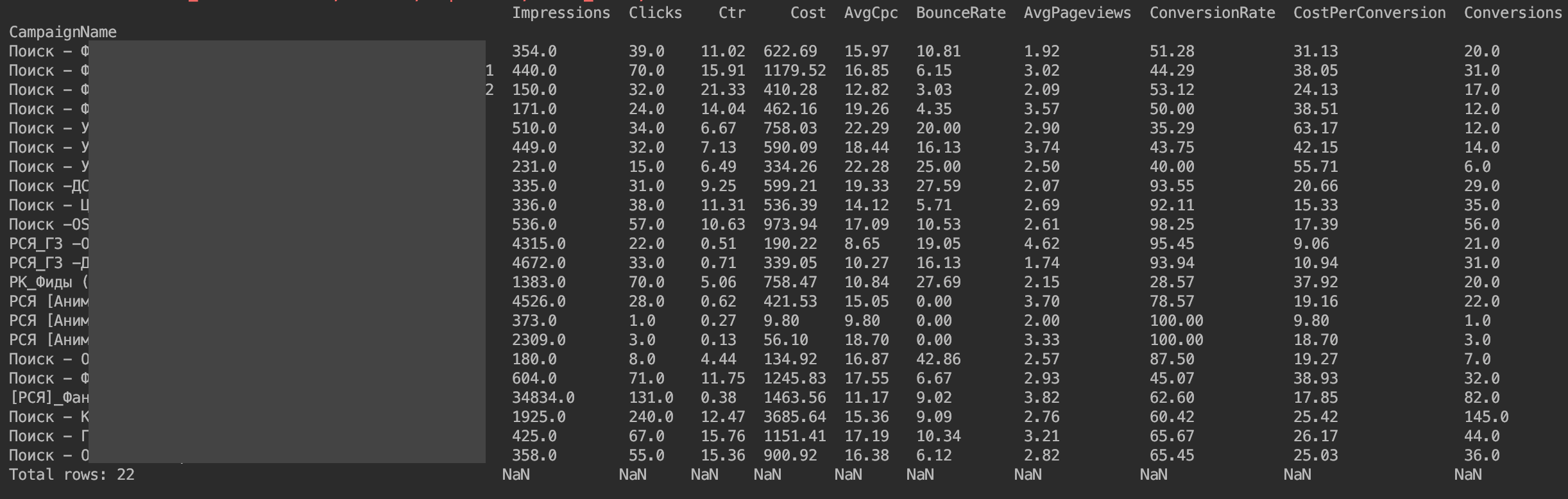
Bagi saya sendiri, saya menulis permintaan statistik yang mirip hari demi hari dan berdasarkan kampanye, agar selalu waspada terhadap penyimpangan lalu lintas dan memahami di mana penyimpangan kira-kira terjadi.
Terima kasih atas perhatian anda
Kode Akhir: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)