Kami terus menerbitkan video dan transkrip laporan terbaik dari konferensi
PGConf.Russia 2019 . Sebuah laporan oleh Oleg Bartunov tentang topik "Postgres Profesional" membuka bagian pleno konferensi. Ini mengungkapkan sejarah Postgres DBMS, kontribusi Rusia untuk pengembangan, fitur arsitektur.
Materi sebelumnya dalam seri ini: "Kesalahan Umum Saat Bekerja dengan PostgreSQL" oleh Ivan Frolkov, bagian
1 dan
2 .

Saya akan berbicara tentang Postgres profesional. Tolong jangan bingung dengan perusahaan yang saya wakili sekarang - Postgres Professional.

Saya benar-benar akan berbicara tentang bagaimana Postgres, yang dimulai sebagai pengembangan akademis amatir, menjadi profesional - seperti yang kita lihat sekarang. Saya hanya akan mengungkapkan pendapat pribadi saya, itu tidak mencerminkan pendapat perusahaan kami atau kelompok mana pun.

Kebetulan saya menggunakan dan tidak membuat cuplikan Postgres, tetapi terus menerus dari 1995 hingga sekarang. Seluruh ceritanya terlintas di depan mataku, aku adalah peserta dalam acara utama.
Ceritanya
Pada slide ini, saya menjelaskan secara singkat proyek-proyek yang saya ikuti. Banyak dari mereka yang akrab bagi Anda. Dan saya akan segera memulai sejarah Postgres dengan gambar yang saya lukis bertahun-tahun yang lalu dan kemudian saya gambarkan - jumlah versi meningkat dan meningkat. Ini mencerminkan evolusi database relasional. Di sebelah kiri, jika ada yang tidak tahu, ini adalah
Michael Stonebreaker , yang disebut sebagai ayah dari Postgres. Di bawah ini adalah pengembang "nuklir" pertama kami. Orang yang duduk di sebelah kanan adalah Vadim Mikheev dari Krasnoyarsk, ia adalah salah satu pengembang inti pertama.
Saya akan memulai kisah model relasional dengan IBM, yang telah memberikan kontribusi besar bagi industri. IBMlah yang bekerja untuk
Edgar Codd , buku putih pertama tentang
IBM System R muncul dari perutnya - itu adalah basis data relasional pertama. Mike Stonebreaker bekerja pada waktu itu di Burkeley. Dia membaca artikel ini dan terbakar dengan teman-temannya: kita perlu membuat database.

Pada tahun-tahun itu - pada awal 70-an - seperti yang Anda duga, tidak ada banyak komputer. Ada satu PDP-11 untuk seluruh departemen ilmu Komputer di Berkeley, dan semua mahasiswa dan fakultas berjuang untuk waktu mesin. Mesin ini terutama digunakan untuk perhitungan. Saya sendiri bekerja seperti ini ketika saya masih muda: Anda memberi operator tugas, dia memulainya. Tetapi siswa dan pengembang menginginkan karya interaktif. Itu adalah impian kami - untuk duduk di remote control, masuk ke program, men-debug mereka. Dan ketika Mike Stonebreaker dan teman-temannya membuat basis pertama, mereka menyebutnya
Ingres - Sistem Pemulihan Grafis Interaktif. Orang tidak mengerti: mengapa interaktif? Dan itu hanya impian pengembangnya yang menjadi kenyataan. Mereka memiliki klien konsol yang dapat digunakan untuk bekerja dengan Ingres. Dia memberi banyak industri kami. Apakah Anda melihat ada berapa banyak panah dari Ingres? Ini adalah database yang dia pengaruhi, yang meraba-raba kodenya. Michael Stonebreaker memiliki banyak siswa pengembangan yang meninggalkan dan kemudian mengembangkan
Sybase dan
MS SQL ,
NonStop SQL ,
Illustra ,
Informix .
Ketika Ingres berkembang sedemikian rupa sehingga menjadi menarik secara komersial,
Illustra dibentuk (ini adalah tahun 1992), dan kode DBMS
Illustra dibeli oleh
Informix , yang kemudian dimakan oleh
IBM , dan dengan demikian kodenya pergi ke
DB2 . Tapi apa yang membuat
IBM tertarik dengan
Ingres ? Pertama-tama, ekstensibilitas - ide-ide revolusioner yang Michael Stonebreaker letakkan sejak awal, berpikir bahwa database harus siap untuk menyelesaikan masalah bisnis. Dan untuk ini, Anda perlu menambahkan tipe data, metode akses, dan fungsi ke database. Bagi kami postgresists, ini tampak alami. Pada tahun-tahun itu, itu adalah revolusi. Sejak zaman Ingres dan Postgres, fitur-fitur ini, fungsi ini telah menjadi standar de facto untuk semua basis data relasional. Sekarang semua database memiliki fungsi pengguna, dan ketika Stonebreaker menulis bahwa fungsi pengguna diperlukan,
Oracle , misalnya, berteriak bahwa itu berbahaya, dan bahwa ini tidak dapat dilakukan karena pengguna dapat membahayakan data. Sekarang kita melihat bahwa fungsi yang ditentukan pengguna ada di semua database, bahwa Anda dapat membuat agregat dan tipe data Anda sendiri.

Postgres dikembangkan sebagai pengembangan akademik, yang berarti: ada seorang profesor, ia memiliki hibah untuk pengembangan, mahasiswa dan mahasiswa pascasarjana yang bekerja dengannya. Basis yang serius, siap untuk diproduksi, tidak dapat dilakukan seperti itu. Namun, versi terbaru dari Berkeley -
Postgres95 - telah menambahkan
SQL . Pengembang siswa pada saat itu sudah mulai bekerja di Illustra, membuat Informix dan kehilangan minat pada proyek. Mereka berkata: kita memiliki Postgres95, bawa siapa pun yang membutuhkannya! Saya ingat semua ini dengan sangat baik karena saya sendiri adalah salah satu dari mereka yang menerima surat ini: ada milis, dan ada kurang dari 400 pelanggan di dalamnya. Komunitas
Postgres95 dimulai dengan 400 orang ini. Kita semua memberikan suara bersama untuk mengambil proyek ini. Kami menemukan penggemar yang mengambil server CVS, dan kami menyeret semuanya ke Panama, karena server ada di sana.
Sejarah
PostgreSQL [hanya Postgres selanjutnya] dimulai dengan versi 6.0, karena versi 1, 4, 5 masih Postgres95. Pada 3 April 1997, logo kami muncul - seekor gajah. Sebelum itu, kami memiliki hewan yang berbeda. Di halaman saya, misalnya,
ada seekor cheetah untuk waktu yang lama , mengisyaratkan bahwa Postgres sangat cepat. Kemudian sebuah pertanyaan muncul di milis: basis data kami yang besar membutuhkan hewan yang serius. Dan seseorang menulis: biarlah itu gajah. Semua orang memberikan suara bersama, lalu orang-orang kami dari St. Petersburg menggambar logo ini. Awalnya, itu adalah gajah dalam berlian - jika Anda menggali lebih dalam ke mesin waktu, Anda akan melihatnya. Gajah dipilih karena gajah memiliki ingatan yang sangat baik. Bahkan Agatha Christie memiliki cerita "Gajah bisa mengingat": gajah itu sangat pendendam, dia ingat pelanggaran selama sekitar lima puluh tahun, dan kemudian menghancurkan pelaku. Berlian kemudian dipisah, pola vektor, dan hasilnya adalah gajah ini. Jadi ini adalah salah satu kontribusi Rusia pertama ke Postgres.

Cheetah menggantikan Gajah dalam berlian:

Tahapan Pengembangan Postgres
Tugas pertama adalah menstabilkan pekerjaannya. Komunitas telah mengadopsi kode sumber untuk pengembang akademik. Apa yang tidak ada di sana! Mereka mulai menyekop semua ini untuk dikompilasi dengan baik. Pada slide ini, saya menyoroti tahun 1997, versi 6.1 - internasionalisasi muncul di dalamnya. Saya menyorotnya bukan karena saya melakukannya sendiri (itu benar-benar tambalan pertama saya), tetapi karena itu adalah tahap yang penting. Anda sudah terbiasa dengan fakta bahwa Postgres bekerja dengan bahasa apa pun, di semua bahasa - di seluruh dunia. Dan kemudian dia mengerti hanya ASCII, yaitu, tidak ada 8 bit, tidak ada bahasa Eropa, tidak ada bahasa Rusia. Setelah menemukan ini, mengikuti prinsip-prinsip open-source, saya hanya mengambil dan membuat dukungan untuk lokal. Dan berkat pekerjaan ini, Postgres pergi ke dunia. Setelah saya,
Tatsuo Ishii Jepang membuat dukungan untuk pengkodean multibyte, dan Postgres benar-benar mendunia.
Pada 2005, dukungan
Windows diperkenalkan. Saya ingat perdebatan sengit ini ketika mereka membahas hal ini di milis. Semua pengembang adalah orang normal, mereka bekerja di bawah
Unix . Anda bertepuk tangan sekarang, dan dengan cara yang sama orang-orang bereaksi saat itu. Dan memilih menentang. Itu berlangsung selama bertahun-tahun. Selain itu,
SRA Computers merilis
Powergres mereka, port Windows asli, beberapa tahun sebelumnya. Tapi itu produk murni Jepang. Ketika pada tahun 2005 dalam versi ke 8 kami mendapat dukungan untuk Windows, ternyata ini adalah langkah yang kuat: komunitasnya bengkak. Ada banyak orang dan banyak pertanyaan bodoh, tetapi komunitas menjadi besar, kami meraih pengguna vinduzovye.
Pada 2010, kami memiliki replikasi bawaan. Ini menyakitkan. Saya ingat berapa tahun orang berjuang untuk replikasi berada di Postgres. Pada awalnya semua orang berkata: kita tidak perlu replikasi, ini bukan masalah basis data, ini masalah utilitas eksternal. Jika ada yang ingat,
Slony melakukan Jan Wieck. Ngomong-ngomong, "gajah" juga berasal dari bahasa Rusia: Jan bertanya kepada saya berapa "gajah" di Rusia, dan saya menjawab: "gajah". Jadi dia membuat Slony. Gajah-gajah ini bekerja seperti replikasi logis pada pemicu, mengonfigurasinya adalah mimpi buruk - para veteran ingat. Terlebih lagi, semua orang mendengarkan
Tom Lane dalam waktu lama, yang, saya ingat, berteriak dengan putus asa: mengapa kita harus mempersulit kode dengan replikasi jika dapat dilakukan di luar pangkalan? Tetapi sebagai hasilnya, replikasi inline masih muncul. Ini segera menghasilkan sejumlah besar pengguna perusahaan, karena sebelum itu, pengguna tersebut berkata: bagaimana kita bisa hidup tanpa replikasi? Ini tidak mungkin!
Pada 2014, jsonb muncul. Ini pekerjaan saya,
Fedor Sigaev dan
Alexander Korotkov . Dan juga orang-orang berteriak: mengapa kita membutuhkan ini? Secara umum, kami sudah memiliki hstore, yang kami buat pada tahun 2003, dan pada tahun 2006 ia memasuki Postgres. Orang-orang menggunakannya dengan indah di seluruh dunia, menyukainya, dan jika Anda mengetikkan
hstore di google, sejumlah besar dokumen muncul. Ekstensi yang sangat populer. Dan kami sangat mempromosikan ide data tidak terstruktur di Postgres. Dari awal pekerjaan saya, saya hanya tertarik dengan ini, dan ketika kami melakukannya
jsonb , saya menerima banyak surat terima kasih dan pertanyaan. Dan komunitas telah mendapat pengguna
NoSQL ! Sebelum jsonb, orang-orang yang di-zombi oleh hype pergi ke nilai kunci dari database. Pada saat yang sama, mereka dipaksa untuk mengorbankan integritas, identitas
ACID . Dan kami memberi mereka kesempatan, tanpa mengorbankan apa pun, untuk bekerja dengan json mereka yang cantik. Komunitas telah tumbuh dengan tajam lagi.
Pada 2016, kami mendapat eksekusi permintaan paralel. Jika ada yang tidak tahu, ini, tentu saja, bukan untuk
OLTP. Jika Anda memiliki mesin yang dimuat, maka semua kernel sudah sibuk. Eksekusi query bersamaan bernilai bagi pengguna
OLAP . Dan mereka menghargainya, yaitu sejumlah pengguna
OLAP mulai berdatangan di komunitas.
Selanjutnya adalah proses kumulatif. Pada 2017, kami menerima replikasi logis dan partisi deklaratif - itu juga merupakan langkah besar dan serius karena replikasi logis memungkinkan untuk membuat sistem yang sangat, sangat menarik, orang mendapat kebebasan tanpa batas untuk imajinasi mereka dan mulai membuat cluster. Menggunakan partisi deklaratif, menjadi mungkin untuk tidak membuat partisi secara manual, tetapi menggunakan SQL.
Pada 2018, dalam versi 11, kami mendapat
JIT . Siapa yang tidak tahu, ini adalah kompiler Just In Time: Anda mengkompilasi permintaan, dan itu benar-benar dapat mempercepat eksekusi. Ini penting untuk mempercepat permintaan lambat karena permintaan cepat sudah cepat, dan overhead untuk kompilasi masih signifikan.
Pada tahun 2019, hal paling mendasar yang kami harapkan adalah
penyimpanan pluggable, sebuah API sehingga pengembang dapat membuat repositori mereka sendiri, salah satu contohnya adalah
zheap - repositori yang dikembangkan
EnterpriseDB .
Dan inilah perkembangan kami: SQL / JSON. Saya sangat berharap bahwa
Sasha Korotkov akan melakukannya sebelum konferensi, tetapi ada beberapa masalah di sana, dan sekarang kami berharap bahwa semua sama kita akan mendapatkan
SQL / JSON tahun ini. Orang-orang telah menunggunya selama dua tahun [bagian penting dari SQL / JSON: patch jsonpath telah dilakukan sekarang, ini dijelaskan secara rinci di
sini ].

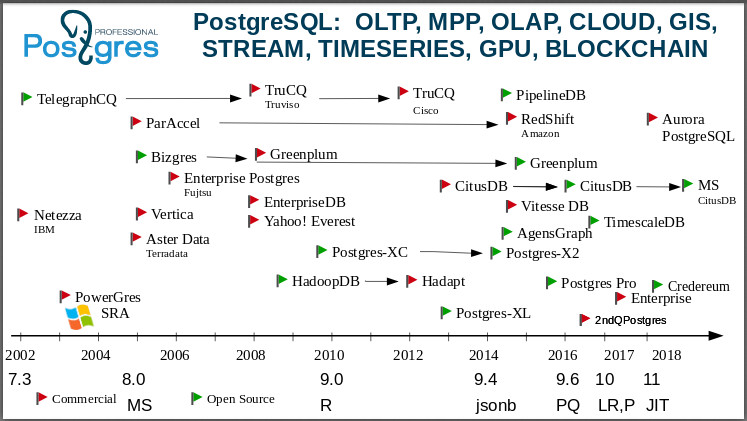
Selanjutnya, saya beralih ke slide yang menunjukkan: Postgres adalah database universal. Anda dapat mempelajari gambar ini selama berjam-jam, menceritakan banyak kisah tentang kemunculan perusahaan, pengambilalihan, dan kematian perusahaan. Saya akan mulai pada tahun 2000. Salah satu fork pertama Postgres adalah IBM
Netezza . Bayangkan saja: "Raksasa Biru" mengambil kode Postgres dan membangun basis untuk OLAP untuk mendukung BI-nya!
Ini adalah cabang dari
TelegraphCQ : sudah pada tahun 2000, orang-orang membuat basis data streaming berdasarkan Postgres di Berkeley. Jika ada yang tidak tahu, ini adalah database yang tidak tertarik pada data itu sendiri, tetapi tertarik pada agregat mereka. Sekarang ada banyak tugas di mana Anda tidak perlu mengetahui nilai masing-masing, misalnya, suhu di beberapa titik, tetapi Anda membutuhkan nilai rata-rata di wilayah ini. Dan di TelegraphCQ mereka mengambil ide ini (juga muncul di Berkeley), salah satu ide paling maju saat itu, dan mengembangkan basis berdasarkan Postgres. Lebih lanjut berevolusi, dan pada 2008, atas dasar, produk komersial dirilis - basis
TruCQ , sekarang pemiliknya adalah
Cisco .
Saya lupa mengatakan bahwa tidak semua garpu ada di halaman ini, ada dua kali lebih banyak. Saya memilih yang paling penting dan menarik, agar tidak mengacaukan gambar.
Halaman wiki postgresql mencantumkan semua garpu. Siapa yang tahu basis data sumber terbuka yang memiliki banyak garpu? Tidak ada pangkalan seperti itu.
Postgres berbeda dari database lain tidak hanya dalam fungsinya, tetapi juga dalam hal itu
komunitas yang sangat menarik, biasanya menerima garpu. Dalam dunia open source, ini diterima secara umum: Saya membuat garpu karena saya tersinggung - Anda tidak mendukung saya, jadi saya memutuskan untuk melakukan pengembangan sendiri. Di dunia pasca-Yunani, penampilan garpu berarti: beberapa orang atau perusahaan memutuskan untuk membuat beberapa prototipe dan menguji fungsi yang mereka ciptakan, untuk bereksperimen. Dan jika Anda beruntung, maka buatlah basis komersial yang dapat dijual kepada pelanggan, berikan mereka layanan, dan sebagainya. Pada saat yang sama, sebagai aturan, para pengembang dari semua garpu ini mengembalikan prestasi dan tambalan mereka ke komunitas. Produk perusahaan kami juga bercabang, dan jelas bahwa kami mengembalikan banyak tambalan ke komunitas. Dalam versi terbaru, ke-11, kami mengembalikan lebih dari 100 tambalan ke komunitas. Jika Anda melihat catatan rilisnya, maka akan ada 25 nama karyawan kami. Ini adalah perilaku normal masyarakat. Kami menggunakan versi komunitas dan membuat garpu kami untuk menguji ide-ide kami atau memberikan fungsionalitas pelanggan sebelum komunitas matang untuk penerapannya. Garpu di komunitas Postgres sangat disambut.
Vertica yang terkenal berasal dari
C-Store - juga tumbuh dari Postgres. Beberapa orang mengklaim bahwa Vertica sama sekali tidak memiliki kode sumber Postgres, tetapi hanya mendukung protokol postgres. Meskipun demikian, sudah lazim untuk mengklasifikasikannya sebagai garpu pos-Yunani.
Greenplum . Sekarang Anda dapat mengunduhnya dan menggunakannya sebagai cluster. Itu berasal dari
Bizgres , basis data paralel-masif. Kemudian dibeli oleh Greenplum, menjadi dan untuk waktu yang lama tetap komersial. Tetapi Anda melihat bahwa sekitar tahun 2015, mereka menyadari bahwa dunia telah berubah: dunia bergerak menuju protokol terbuka, komunitas terbuka, basis data terbuka. Dan mereka membuka kode Greenplum. Sekarang mereka secara aktif mengejar ketinggalan dengan Postgres karena mereka telah ketinggalan, tentu saja, sangat banyak. Mereka beranjak di angka 8.2, dan sekarang mereka mengatakan bahwa mereka berhasil mengejar angka 9.6.
Kita semua suka dan tidak suka
Amazon . Anda tahu bagaimana itu terjadi. Itu terjadi di depan mataku. Ada perusahaan, ada
ParAccel dengan pemrosesan vektor, juga di Postgres - produk komunitas, terbuka. Pada tahun 2012, Amazon yang licik membeli kode sumber dan secara harfiah enam bulan kemudian mengumumkan bahwa kami sekarang memiliki
RDS di Amazon. Kami kemudian bertanya kepada mereka, mereka ragu-ragu untuk waktu yang lama, tetapi ternyata Postgres. RDS masih hidup, dan ini adalah salah satu layanan paling populer Amazon, mereka memiliki sekitar 7.000 pangkalan berputar di sana. Tetapi mereka tidak tenang dalam hal ini, dan pada 2010 Amazon Aurora muncul - Postgres 10 dengan cerita yang ditulis ulang yang dijahit langsung ke infrastruktur Amazon, dalam penyimpanan terdistribusi mereka.
Lihatlah
Teradata sekarang. Perusahaan analitik besar dan bagus,
OLAP . Setelah G8 [PostgreSQL 8.0],
Aster Data muncul.
Hadoop : kami memiliki Postgres di Hadoop -
HadoopDB . Setelah beberapa saat, itu menjadi pangkalan
Hadapt tertutup yang dimiliki oleh
Teradata . Jika Anda melihat Hadapt, tahu apa yang ada di dalam Postgres.
Nasib yang sangat menarik bersama
Citus . Semua orang tahu bahwa ini adalah Postgres yang didistribusikan untuk analitik online. Itu tidak mendukung transaksi.
Citus Data adalah startup, dan Citus adalah sumber tertutup, basis data terpisah. Setelah beberapa waktu, orang-orang menyadari bahwa lebih baik hidup dengan komunitas, untuk terbuka. Dan mereka melakukan banyak hal untuk menjadi hanya perpanjangan dari Postgres. Ditambah lagi, mereka mulai berbisnis dengan penyediaan layanan cloud mereka. Anda semua sudah tahu:
MS Citus ditulis di sini karena
Microsoft membelinya, secara harfiah dua minggu lalu. Mungkin, untuk mendukung Postgres pada
Azure -nya, yaitu, Microsoft juga memainkan game-game ini. Mereka memiliki Postgres yang berjalan di Azure, dan tim pengembangan Citus telah bergabung dengan pengembang MS.
Secara umum, baru-baru ini proses pembelian perusahaan pasca-gres telah berjalan secara intensif. Tepat setelah Microsoft membeli Citus, perusahaan postgres lain,
credativ , membeli
OmniTI untuk memperkuat kehadiran pasarnya. Ini adalah dua perusahaan terkenal dan solid. Dan Amazon membeli
OpenSCG . Dunia postgres berubah sekarang, dan saya akan tunjukkan mengapa ada begitu banyak minat pada Postgres.
TimescaleDB yang diakui juga merupakan basis data yang terpisah, tetapi sekarang merupakan ekstensi: Anda menggunakan Postgres dan menginstal timescaledb sebagai ekstensi dan mendapatkan basis data yang memecah semua jenis basis data khusus.
Ada juga Postgres XL, ada cluster yang berkembang.
Di sini pada tahun 2015, saya mengatur garpu kami:
Postgres Pro . Kami memiliki
Postgres Pro Enterprise , ada versi bersertifikat, kami mendukung
1C di luar kotak dan kami diakui oleh
1C . Jika ada yang ingin mencoba Postgres Pro Enterprise, maka Anda dapat mengambil kit distribusi secara gratis, dan jika Anda membutuhkannya untuk bekerja, Anda dapat membelinya.
Kami membuat
Credereum , basis data prototipe dengan dukungan blockchain. Sekarang kami sedang menunggu orang dewasa untuk mulai menggunakannya.
Lihat seberapa besar dan menarik gambarnya. Saya bahkan tidak berbicara tentang
Yahoo! Everest dengan penyimpanan kolom, dengan petabyte data di Yahoo! - itu tahun 2008. Mereka bahkan mensponsori konferensi kami di Kanada, datang ke sana, di suatu tempat saya bahkan punya kemeja dari sana :)
Ada juga
PipelineDB . Itu juga dimulai sebagai database sumber tertutup, tetapi sekarang ini juga hanya sebuah ekstensi. Kita melihat bahwa Citus, TimescaleDB dan PipelineDB seperti database terpisah, tetapi pada saat yang sama mereka ada sebagai ekstensi, yaitu, Anda mengambil Postgres standar dan mengkompilasi ekstensi. PipelineDB adalah kelanjutan dari gagasan stream databases.
Ingin bekerja dengan stream? Ambil Postgres, ambil PipelineDB dan Anda bisa bekerja.Selain itu, ada ekstensi yang memungkinkan Anda untuk bekerja dengan GPU . Lihat tajuk utama? Saya telah menunjukkan bahwa ada ekosistem yang mencakup sejumlah besar berbagai jenis data dan beban. Karena itu, kami mengatakan bahwa Postgres adalah database universal.Pangkalan orang favorit
 Slide berikutnya memiliki nama besar. Semua awan paling terkenal di dunia mendukung Postgres. Di Rusia, Postgres didukung oleh perusahaan besar milik negara. Mereka menggunakannya, dan kami melayani mereka sebagai pelanggan kami.
Slide berikutnya memiliki nama besar. Semua awan paling terkenal di dunia mendukung Postgres. Di Rusia, Postgres didukung oleh perusahaan besar milik negara. Mereka menggunakannya, dan kami melayani mereka sebagai pelanggan kami. Sudah ada banyak ekstensi dan banyak aplikasi, jadi Postgres bagus sebagai basis data dari mana proyek dimulai. Saya selalu mengatakan kepada para startup: Anda tidak perlu mengambil basis data NoSQL . Saya mengerti bahwa Anda benar-benar menginginkannya, tetapi mulailah dengan Postgres. Jika Anda tidak memiliki cukup, Anda selalu dapat melepaskan layanan dan memberikannya ke basis data khusus. Selain universalitas, Postgres memiliki satu keuntungan lagi: lisensi BSD yang sangat liberal, yang memungkinkan Anda untuk melakukan apa saja dengan database Anda.Segala sesuatu yang Anda lihat pada slide ini dapat diakses karena fakta bahwa Postgres adalah database yang dapat diperluas, dan ekstensibilitas ini tertanam langsung, tepat di arsitektur basis data. Ketika Michael Stonebreaker menulis tentang Postgres di artikel pertamanya tentang dia (ditulis olehnya pada tahun 1984, di sini saya mengutip sebuah artikel dari tahun 1987), dia sudah berbicara tentang ekstensibilitas sebagai komponen terpenting dari fungsi basis data. Dan ini, seperti kata mereka, sudah diuji oleh waktu. Anda dapat menambahkan fungsi Anda sendiri, tipe data Anda, operator, akses indeks (yaitu, metode akses yang dioptimalkan), Anda dapat menulis prosedur Anda dalam sejumlah besar bahasa. Kami memiliki Foreign Data Wrapper ( FDW ), yaitu antarmuka untuk bekerja dengan berbagai repositori, file, yang dapat Anda sambungkan ke Oracle , MySQLdan pangkalan lainnya.Saya ingin memberi contoh dari pengalaman pribadi saya. Saya bekerja dengan Postgres dan ketika ada sesuatu yang hilang di Postgres, kolega saya dan saya hanya menambahkan fungsi ini. Kami perlu bekerja, misalnya, dengan bahasa Rusia, dan kami membuat lokal 8-bit. Itu adalah proyek Rambler . Ngomong-ngomong, dia berada di 5 besar. Rambleradalah proyek global besar pertama yang diluncurkan di Postgres. Array dalam Postgres sudah dari awal, tetapi mereka sedemikian rupa sehingga tidak ada yang bisa dilakukan dengan mereka, itu hanya sebuah baris teks di mana array disimpan. Kami menambahkan operator, membuat indeks, dan sekarang array adalah bagian integral dari fungsi Postgres, dan banyak dari Anda menggunakannya tanpa khawatir tentang seberapa cepat mereka bekerja - dan itu bagus. Mereka biasa mengatakan bahwa array bukan lagi model relasional tradisional, itu tidak memenuhi bentuk normal klasik. Sekarang orang sudah terbiasa menggunakan array.
Sudah ada banyak ekstensi dan banyak aplikasi, jadi Postgres bagus sebagai basis data dari mana proyek dimulai. Saya selalu mengatakan kepada para startup: Anda tidak perlu mengambil basis data NoSQL . Saya mengerti bahwa Anda benar-benar menginginkannya, tetapi mulailah dengan Postgres. Jika Anda tidak memiliki cukup, Anda selalu dapat melepaskan layanan dan memberikannya ke basis data khusus. Selain universalitas, Postgres memiliki satu keuntungan lagi: lisensi BSD yang sangat liberal, yang memungkinkan Anda untuk melakukan apa saja dengan database Anda.Segala sesuatu yang Anda lihat pada slide ini dapat diakses karena fakta bahwa Postgres adalah database yang dapat diperluas, dan ekstensibilitas ini tertanam langsung, tepat di arsitektur basis data. Ketika Michael Stonebreaker menulis tentang Postgres di artikel pertamanya tentang dia (ditulis olehnya pada tahun 1984, di sini saya mengutip sebuah artikel dari tahun 1987), dia sudah berbicara tentang ekstensibilitas sebagai komponen terpenting dari fungsi basis data. Dan ini, seperti kata mereka, sudah diuji oleh waktu. Anda dapat menambahkan fungsi Anda sendiri, tipe data Anda, operator, akses indeks (yaitu, metode akses yang dioptimalkan), Anda dapat menulis prosedur Anda dalam sejumlah besar bahasa. Kami memiliki Foreign Data Wrapper ( FDW ), yaitu antarmuka untuk bekerja dengan berbagai repositori, file, yang dapat Anda sambungkan ke Oracle , MySQLdan pangkalan lainnya.Saya ingin memberi contoh dari pengalaman pribadi saya. Saya bekerja dengan Postgres dan ketika ada sesuatu yang hilang di Postgres, kolega saya dan saya hanya menambahkan fungsi ini. Kami perlu bekerja, misalnya, dengan bahasa Rusia, dan kami membuat lokal 8-bit. Itu adalah proyek Rambler . Ngomong-ngomong, dia berada di 5 besar. Rambleradalah proyek global besar pertama yang diluncurkan di Postgres. Array dalam Postgres sudah dari awal, tetapi mereka sedemikian rupa sehingga tidak ada yang bisa dilakukan dengan mereka, itu hanya sebuah baris teks di mana array disimpan. Kami menambahkan operator, membuat indeks, dan sekarang array adalah bagian integral dari fungsi Postgres, dan banyak dari Anda menggunakannya tanpa khawatir tentang seberapa cepat mereka bekerja - dan itu bagus. Mereka biasa mengatakan bahwa array bukan lagi model relasional tradisional, itu tidak memenuhi bentuk normal klasik. Sekarang orang sudah terbiasa menggunakan array. Ketika kami membutuhkan pencarian teks lengkap, kami berhasil. Ketika kami perlu menyimpan data yang berbeda sifatnya, kami membuat ekstensi hstore, dan banyak orang mulai menggunakannya: itu memungkinkan untuk membangun skema basis data yang fleksibel sehingga bisa lebih cepat dan lebih cepat. Kami membuat indeks GIN untuk mempercepat pencarian teks lengkap. Kami membuat trigram ( pg_trgm ). Dibuat NoSQL Dan semua ini ada dalam ingatan saya, semua kebutuhan saya sendiri.
Ketika kami membutuhkan pencarian teks lengkap, kami berhasil. Ketika kami perlu menyimpan data yang berbeda sifatnya, kami membuat ekstensi hstore, dan banyak orang mulai menggunakannya: itu memungkinkan untuk membangun skema basis data yang fleksibel sehingga bisa lebih cepat dan lebih cepat. Kami membuat indeks GIN untuk mempercepat pencarian teks lengkap. Kami membuat trigram ( pg_trgm ). Dibuat NoSQL Dan semua ini ada dalam ingatan saya, semua kebutuhan saya sendiri. Extensibility menjadikan Postgres basis data unik, basis data universal yang dengannya Anda dapat mulai bekerja dan tidak takut bahwa Anda akan dibiarkan tanpa dukungan. Lihat berapa banyak orang di sini yang kita miliki - ini sudah menjadi pasar! Terlepas dari kenyataan bahwa sekarang database hype - grafik, database dokumen, seri waktu dan sebagainya - lihat: sebagian besar masih menggunakan database relasional. Mereka mendominasi, ini adalah 75% dari pasar basis data, dan sisanya adalah basis data eksotis, sedikit dibandingkan dengan yang relasional.
Extensibility menjadikan Postgres basis data unik, basis data universal yang dengannya Anda dapat mulai bekerja dan tidak takut bahwa Anda akan dibiarkan tanpa dukungan. Lihat berapa banyak orang di sini yang kita miliki - ini sudah menjadi pasar! Terlepas dari kenyataan bahwa sekarang database hype - grafik, database dokumen, seri waktu dan sebagainya - lihat: sebagian besar masih menggunakan database relasional. Mereka mendominasi, ini adalah 75% dari pasar basis data, dan sisanya adalah basis data eksotis, sedikit dibandingkan dengan yang relasional. Jika Anda melihat rasio basis data open source untuk komersial, maka,menurut DB-Engine, kita akan melihat bahwa jumlah database open source hampir sama dengan jumlah database komersial. Dan kita melihat bahwa basis data sumber terbuka (garis biru) tumbuh, dan komersial (merah) turun. Ini adalah arah pengembangan seluruh komunitas TI, arah keterbukaan. Sekarang, tentu saja, tidak pantas untuk merujuk ke Gartner , tetapi saya tetap akan mengatakannya: mereka memperkirakan bahwa pada tahun 2022 70% akan menggunakan basis data terbuka dan hingga 50% dari sistem yang ada akan bermigrasi ke open source.Lihatlah pomosomer ini: kita melihat bahwa Postgres disebut database tahun 2018. Tahun lalu, ia juga merupakan estimasi ahli independen pertama dari DB-Engine. Pemeringkatan menunjukkan bahwa Postgres benar-benar di depan yang lain. Ini dalam istilah absolut di tempat ke-4, tetapi lihat bagaimana ia tumbuh. Tentu baik Pada slide, ini adalah garis biru. Sisanya - MySQL, Oracle, MS SQL - baik saldo pada levelnya, atau mulai menekuk.
Jika Anda melihat rasio basis data open source untuk komersial, maka,menurut DB-Engine, kita akan melihat bahwa jumlah database open source hampir sama dengan jumlah database komersial. Dan kita melihat bahwa basis data sumber terbuka (garis biru) tumbuh, dan komersial (merah) turun. Ini adalah arah pengembangan seluruh komunitas TI, arah keterbukaan. Sekarang, tentu saja, tidak pantas untuk merujuk ke Gartner , tetapi saya tetap akan mengatakannya: mereka memperkirakan bahwa pada tahun 2022 70% akan menggunakan basis data terbuka dan hingga 50% dari sistem yang ada akan bermigrasi ke open source.Lihatlah pomosomer ini: kita melihat bahwa Postgres disebut database tahun 2018. Tahun lalu, ia juga merupakan estimasi ahli independen pertama dari DB-Engine. Pemeringkatan menunjukkan bahwa Postgres benar-benar di depan yang lain. Ini dalam istilah absolut di tempat ke-4, tetapi lihat bagaimana ia tumbuh. Tentu baik Pada slide, ini adalah garis biru. Sisanya - MySQL, Oracle, MS SQL - baik saldo pada levelnya, atau mulai menekuk. Berita peretas - Anda semua mungkin membacanya atau Y Combinator- jajak pendapat dilakukan secara berkala di sana, perusahaan menerbitkan lowongan mereka di sana, dan untuk beberapa waktu mereka telah melakukan statistik. Anda lihat bahwa mulai sekitar tahun 2014, Postgres berada di depan semua orang. Itu adalah MySQL pertama, tetapi Postgres perlahan-lahan tumbuh, dan sekarang di antara seluruh komunitas peretas (dalam arti kata yang baik), ia juga menang dan tumbuh lebih jauh.
Berita peretas - Anda semua mungkin membacanya atau Y Combinator- jajak pendapat dilakukan secara berkala di sana, perusahaan menerbitkan lowongan mereka di sana, dan untuk beberapa waktu mereka telah melakukan statistik. Anda lihat bahwa mulai sekitar tahun 2014, Postgres berada di depan semua orang. Itu adalah MySQL pertama, tetapi Postgres perlahan-lahan tumbuh, dan sekarang di antara seluruh komunitas peretas (dalam arti kata yang baik), ia juga menang dan tumbuh lebih jauh. The Stack Overflow , juga, setiap tahun melakukan survei. Yang paling sering digunakan, Postgres kami berada di posisi ketiga. Oleh paling dicintai - pada detik. Ini adalah basis data favorit. Redis bukan database relasional, tetapi Postgres relasional adalah favorit. Di sini saya tidak memberikan gambar yang paling ditakuti- Basis data yang paling mengerikan, tetapi Anda mungkin menebak siapa yang lebih dulu. "Basis X," begitu mereka menyebutnya di Rusia.
The Stack Overflow , juga, setiap tahun melakukan survei. Yang paling sering digunakan, Postgres kami berada di posisi ketiga. Oleh paling dicintai - pada detik. Ini adalah basis data favorit. Redis bukan database relasional, tetapi Postgres relasional adalah favorit. Di sini saya tidak memberikan gambar yang paling ditakuti- Basis data yang paling mengerikan, tetapi Anda mungkin menebak siapa yang lebih dulu. "Basis X," begitu mereka menyebutnya di Rusia. Ada ulasan di Rusia, survei pada kita semua di konferensi HighLoad ++ yang disegani . Itu tidak dilakukan oleh kami, itu dibuat oleh Oleg Bunin . Ternyata: dalam database Rusia Postgres No. 1.
Ada ulasan di Rusia, survei pada kita semua di konferensi HighLoad ++ yang disegani . Itu tidak dilakukan oleh kami, itu dibuat oleh Oleg Bunin . Ternyata: dalam database Rusia Postgres No. 1. Kami meminta HH.ru untuk kedua kalinya berbagi statistik pekerjaan Postgres dengan kami. 9 tahun yang lalu Postgres 10 kali di belakang Oracle, semua orang berteriak: beri kami oracleists. Dan kita melihat bahwa tahun lalu kita berhasil, dan kemudian pada tahun 2018 ada pertumbuhan. Dan jika Anda khawatir tentang di mana mencari pekerjaan, maka lihat: 2 ribu lowongan di HH.ru adalah Postgres. Jangan khawatir, cukup kerja.
Kami meminta HH.ru untuk kedua kalinya berbagi statistik pekerjaan Postgres dengan kami. 9 tahun yang lalu Postgres 10 kali di belakang Oracle, semua orang berteriak: beri kami oracleists. Dan kita melihat bahwa tahun lalu kita berhasil, dan kemudian pada tahun 2018 ada pertumbuhan. Dan jika Anda khawatir tentang di mana mencari pekerjaan, maka lihat: 2 ribu lowongan di HH.ru adalah Postgres. Jangan khawatir, cukup kerja. Untuk membuatnya lebih mudah dilihat, saya mengambil gambar di mana saya menunjukkan lowongan Postgres tentang lowongan Oracle. Ada yang lebih sedikit, mulai dari 2018 mereka sudah setara, dan sekarang Postgres sudah menjadi sedikit lebih. Sejauh ini agak menyedihkan bahwa jumlah absolut lowongan Oracle juga bertambah, yang pada prinsipnya tidak seharusnya. Tapi, seperti kata mereka, kita duduk di dekat tepi sungai dan mengawasi: kapan mayat musuh akan melintas. Kami hanya melakukan pekerjaan kami.
Untuk membuatnya lebih mudah dilihat, saya mengambil gambar di mana saya menunjukkan lowongan Postgres tentang lowongan Oracle. Ada yang lebih sedikit, mulai dari 2018 mereka sudah setara, dan sekarang Postgres sudah menjadi sedikit lebih. Sejauh ini agak menyedihkan bahwa jumlah absolut lowongan Oracle juga bertambah, yang pada prinsipnya tidak seharusnya. Tapi, seperti kata mereka, kita duduk di dekat tepi sungai dan mengawasi: kapan mayat musuh akan melintas. Kami hanya melakukan pekerjaan kami.
Komunitas Postgres Rusia
Ini adalah komunitas paling terorganisir di Rusia, saya belum pernah bertemu orang seperti itu. Banyak sumber daya, obrolan, tempat kita semua berkomunikasi dalam bisnis. Kami mengadakan konferensi - dua konferensi besar: di St. Petersburg dan Moskow, rumah-rumah apartemen, kami berpartisipasi dalam semua konferensi internasional utama, menyelenggarakan kursus. Sebenarnya, ini adalah kursus komunitas. Mereka disiapkan oleh perusahaan kami, tetapi mereka tersedia secara bebas untuk Anda, lihat di youtube saluran kami atau buka situs web kami di bagian "Pendidikan", ada kursus DBA1 , DBA2 , DBA3 , kursus pengembangan untuk unduhan gratis .Dan sekarang kami meluncurkan sertifikasi - inilah yang diminta perusahaan, mereka ingin memiliki spesialis bersertifikat. Dan majikan akan tahu: Anda adalah spesialis bersertifikat.
Sebenarnya, ini adalah kursus komunitas. Mereka disiapkan oleh perusahaan kami, tetapi mereka tersedia secara bebas untuk Anda, lihat di youtube saluran kami atau buka situs web kami di bagian "Pendidikan", ada kursus DBA1 , DBA2 , DBA3 , kursus pengembangan untuk unduhan gratis .Dan sekarang kami meluncurkan sertifikasi - inilah yang diminta perusahaan, mereka ingin memiliki spesialis bersertifikat. Dan majikan akan tahu: Anda adalah spesialis bersertifikat. Mereka sering bertanya: berapa banyak Postgres Rusia? Pertanyaannya sedikit salah tempat: Postgres adalah internasional. Tapi saya akan mengatakan sedikit tentang bendera Rusia. Anda lihat di slide apa yang dilakukan Vadim Mikheev . Mereka yang tahu Postgres mengerti bahwa MVCC , WAL , VACUUM dan sebagainya berarti untuk basis ini . Ini semua kontribusi Rusia. Sekarang ada tiga pengembang terkemuka Postgres, di mana dua di antaranya adalah committer. Pada slide Anda melihat bahwa banyak yang telah dilakukan. Jika Anda melihat fitur utama dari catatan rilis, maka Anda akan melihat kontribusi kami. Kontribusi Rusia cukup besar. Kami bekerja sejak awal dan terus bekerja dengan masyarakat - sudah di tingkat kampanye.
Mereka sering bertanya: berapa banyak Postgres Rusia? Pertanyaannya sedikit salah tempat: Postgres adalah internasional. Tapi saya akan mengatakan sedikit tentang bendera Rusia. Anda lihat di slide apa yang dilakukan Vadim Mikheev . Mereka yang tahu Postgres mengerti bahwa MVCC , WAL , VACUUM dan sebagainya berarti untuk basis ini . Ini semua kontribusi Rusia. Sekarang ada tiga pengembang terkemuka Postgres, di mana dua di antaranya adalah committer. Pada slide Anda melihat bahwa banyak yang telah dilakukan. Jika Anda melihat fitur utama dari catatan rilis, maka Anda akan melihat kontribusi kami. Kontribusi Rusia cukup besar. Kami bekerja sejak awal dan terus bekerja dengan masyarakat - sudah di tingkat kampanye. Dan kontribusi perusahaan adalah buku. Kami memiliki 2 program universitas Postgres. Anda dapat pergi ke toko dan membeli buku-buku ini, Anda dapat mengajar di kursus-kursus ini, mengikuti ujian dan sebagainya. Kami memiliki buku untuk pemula yang didistribusikan, termasuk di sini. Buku bagus yang sangat berguna. Kami bahkan menerjemahkannya ke dalam bahasa Inggris.
Dan kontribusi perusahaan adalah buku. Kami memiliki 2 program universitas Postgres. Anda dapat pergi ke toko dan membeli buku-buku ini, Anda dapat mengajar di kursus-kursus ini, mengikuti ujian dan sebagainya. Kami memiliki buku untuk pemula yang didistribusikan, termasuk di sini. Buku bagus yang sangat berguna. Kami bahkan menerjemahkannya ke dalam bahasa Inggris.Postgres Profesional
Mari kita beralih ke yang utama. Academic Postgres, ketika dimulai, dirancang untuk beberapa lusin pengguna. Komunitas Postgres95 memiliki kurang dari 400 orang. Komunitas ini terutama terdiri dari pengembang dan lebih sedikit pengguna. Pada saat yang sama - detail yang menarik - para pengembang terutama pelanggan dan kontraktor. Sebagai contoh, ketika saya membutuhkannya, saya mengembangkan untuk diri saya sendiri dan, pada saat yang sama, berbagi dengan semua orang. Artinya, komunitas itu berkembang untuk komunitas tersebut.
Mulai dari tahun 2000, sedikit lebih awal, perusahaan pasca Grace pertama mulai muncul:
GreatBridge ,
2ndQuadrant ,
EDB . Mereka sudah mempekerjakan pengembang penuh waktu yang bekerja untuk komunitas. Garpu perusahaan pertama dan penyesuai perusahaan pertama kali muncul. Ini mengarah pada fakta bahwa pada tahun 2015 jumlah utama - dan hampir semua pengembang terkemuka - sudah terorganisir di beberapa perusahaan. Pada 2015, perusahaan kami dibentuk: kami adalah pengembang freelance gratis terakhir. Sekarang praktis tidak ada orang seperti itu. Komunitas postgres telah berubah, telah menjadi sebuah perusahaan, dan sekarang perusahaan-perusahaan ini mendorong pengembangan. Ini bagus karena perusahaan-perusahaan ini melakukan apa yang dibutuhkan perusahaan. Komunitas adalah rem dengan cara yang baik: ia menguji fitur, mengecam, atau menerima fitur baru, menyatukan kita semua. Dan Postgres telah menjadi
perusahaan siap , perusahaan besar senang menggunakannya, telah menjadi profesional.

Slide ini tentang masa depan, seperti yang saya lihat. Dengan munculnya
penyimpanan pluggable , repositori baru akan muncul:
penyimpanan kolom append-only ,
read-only , - apa pun yang Anda inginkan (misalnya, saya bermimpi tentang parket). Akan ada dukungan untuk operasi vektor. Hari ini, omong-omong, akan ada laporan tentang mereka. Blockchain akan didukung. Tidak ada jalan keluar dari ini, karena kita pindah ke ekonomi digital, ke teknologi tanpa kertas. Anda harus menggunakan tanda tangan elektronik dan Anda harus dapat mengotentikasi database Anda, pastikan tidak ada yang mengubah apa pun, dan blockchain sangat cocok untuk ini.


Berikutnya:
Postgres adaptif . Ini adalah topik yang agak menyedihkan bagi Anda, tetapi masih cukup jauh dari Anda. Faktanya adalah bahwa DBA, secara umum, adalah sumber daya yang mahal, dan segera database tidak akan membutuhkannya. Basis akan cukup pintar dan akan mengkonfigurasi dan menyesuaikan diri. Tapi mungkin sepuluh tahun lagi, mungkin. Kami masih punya banyak waktu.

Dan jelas bahwa di Postgres akan ada dukungan asli untuk cloud, penyimpanan cloud - tanpa ini, kita tidak bisa bertahan hidup. Dan, tentu saja, ini dia, slide terakhir:
SEMUA YANG ANDA BUTUHKAN ADALAH POSTGRES!

Terima kasih atas perhatian anda