
Sumber Gambar: www.nikonsmallworld.com
Anti-plagiarisme adalah mesin pencari khusus, yang sudah ditulis sebelumnya . Dan setiap mesin pencari, apa pun yang dikatakan, untuk bekerja dengan cepat, memerlukan indeks sendiri, yang memperhitungkan semua fitur dari area pencarian. Dalam artikel pertama saya tentang Habr, saya akan berbicara tentang implementasi saat ini dari indeks pencarian kami, sejarah perkembangannya dan alasan untuk memilih satu atau solusi lain. Algoritme .NET yang efektif bukan mitos, tetapi kenyataan yang sulit dan produktif. Kami akan terjun ke dunia hashing, kompresi bitwise, dan cache prioritas multi-level. Bagaimana jika Anda membutuhkan pencarian lebih cepat daripada O (1) ?
Jika orang lain tidak tahu di mana sinanaga dalam gambar ini, selamat datang ...
Herpes zoster, indeks dan mengapa mencari mereka
Sirap adalah sepotong teks beberapa kata dalam ukuran. Herpes zoster saling tumpang tindih, maka nama (Inggris, herpes zoster - skala, ubin). Ukuran spesifik mereka adalah rahasia terbuka - 4 kata. Atau 5? Yah, itu tergantung. Namun, bahkan nilai ini memberikan sedikit dan tergantung pada komposisi kata berhenti, algoritma untuk menormalkan kata, dan detail lainnya yang tidak signifikan dalam kerangka kerja artikel ini. Pada akhirnya, kita menghitung hash 64-bit berdasarkan sirap ini, yang akan kita sebut sirap di masa depan.
Menurut teks dokumen, Anda dapat membuat banyak sirap, yang jumlahnya sebanding dengan jumlah kata dalam dokumen:
teks: string → sirap: uint64 []
Jika beberapa herpes zoster bertepatan dalam dua dokumen, kami menganggap bahwa dokumen saling bersilangan. Semakin banyak sinanaga cocok, semakin banyak teks identik dalam pasangan dokumen ini. Indeks mencari dokumen yang memiliki jumlah persimpangan terbesar dengan dokumen yang diperiksa.

Sumber Gambar: Wikipedia
Indeks herpes zoster memungkinkan Anda untuk melakukan dua operasi utama:
Buat indeks herpes zoster dokumen dengan pengidentifikasi mereka:
index.Add (docId, herpes zoster)
Cari dan tampilkan daftar pengidentifikasi peringkat untuk dokumen yang tumpang tindih:
index.Search (herpes zoster) → (docId, skor) []
Algoritme peringkat, saya yakin, layak untuk artikel yang terpisah secara umum, jadi kami tidak akan menulisnya di sini.
Indeks herpes zoster sangat berbeda dari rekan teks lengkap yang terkenal, seperti Sphinx, Elastic atau lebih besar: Google, Yandex, dll ... Di satu sisi, itu tidak memerlukan NLP dan kesenangan hidup lainnya. Semua pemrosesan teks dikeluarkan dan tidak memengaruhi proses, serta urutan sirap dalam teks. Di sisi lain, permintaan pencarian bukanlah kata atau frasa dari beberapa kata, tetapi hingga beberapa ratus ribu hash , yang semuanya penting dalam agregat, dan tidak secara terpisah.
Secara hipotesis, Anda dapat menggunakan indeks teks lengkap sebagai pengganti indeks herpes zoster, tetapi perbedaannya terlalu besar. Cara termudah untuk menggunakan beberapa penyimpanan kunci-nilai-terkenal, ini akan disebutkan di bawah ini. Kami melihat implementasi sepeda kami, yang disebut - ShingleIndex.
Kenapa kita repot-repot begitu? Tapi kenapa.
- Volume :
- Ada banyak dokumen. Sekarang kami memiliki sekitar 650 juta dari mereka, dan tahun ini jelas akan ada lebih banyak dari mereka;
- Jumlah herpes zoster unik tumbuh dengan pesat, dan sudah mencapai ratusan miliar. Kami menunggu satu triliun.
- Kecepatan :
- Pada siang hari, selama sesi musim panas, lebih dari 300 ribu dokumen diperiksa melalui sistem Anti-Plagiarisme . Ini sedikit menurut standar mesin pencari populer, tetapi tetap dalam nada;
- Untuk verifikasi dokumen yang berhasil karena keunikannya, jumlah dokumen yang diindeks harus lebih besar dari pada dokumen yang diperiksa. Versi indeks kami saat ini rata-rata dapat diisi dengan kecepatan lebih dari 4000 dokumen sedang per detik.
Dan itu semua dalam satu mesin! Ya, kami dapat mereplikasi , kami secara bertahap mendekati sharding dinamis pada sebuah cluster, tetapi dari 2005 hingga hari ini, indeks pada satu mesin dengan perawatan yang cermat telah mampu mengatasi semua kesulitan di atas.
Pengalaman aneh
Namun, sekarang kami sangat berpengalaman. Suka atau tidak, tetapi kita juga telah tumbuh dan telah mencoba berbagai hal dalam perjalanan pertumbuhan, yang menyenangkan untuk diingat sekarang.
Sumber Gambar: Wikipedia
Pertama-tama, pembaca yang tidak berpengalaman ingin menggunakan database SQL. Anda bukan satu-satunya yang berpikir begitu, implementasi SQL telah membantu kami dengan baik selama beberapa tahun untuk mengimplementasikan koleksi yang sangat kecil. Namun demikian, fokusnya langsung pada jutaan dokumen, jadi saya harus melangkah lebih jauh.
Seperti yang Anda tahu, tidak ada yang suka sepeda, dan LevelDB belum dibuka untuk umum, jadi pada 2010 mata kami tertuju pada BerkeleyDB. Semuanya keren - basis-nilai kunci bawaan yang persisten dengan metode akses btree dan hash yang cocok dan sejarah yang panjang. Semuanya dengan dia luar biasa, tetapi:
- Dalam kasus implementasi hash, ketika mencapai volume 2GB, itu hanya jatuh. Ya, kami masih bekerja dalam mode 32-bit;
- Implementasi B + tree bekerja dengan stabil, tetapi dengan volume lebih dari beberapa gigabytes, kecepatan pencarian mulai menurun secara signifikan.
Kita harus mengakui bahwa kita tidak pernah menemukan cara untuk menyesuaikannya dengan tugas kita. Mungkin masalahnya ada di .net-binding, yang masih harus diselesaikan. Implementasi BDB akhirnya digunakan sebagai pengganti SQL sebagai indeks perantara sebelum mengisi yang utama.
Waktu berlalu. Pada 2014, mereka mencoba LMDB dan LevelDB, tetapi tidak menerapkannya. Orang-orang dari Departemen Penelitian Anti-Plagiarisme kami menggunakan RocksDB sebagai indeks mereka. Pada pandangan pertama, itu adalah temuan. Tetapi pengisian ulang yang lambat dan kecepatan pencarian biasa-biasa saja bahkan pada volume kecil membawa segalanya sia-sia.
Kami melakukan semua hal di atas, sambil mengembangkan indeks kustom kami sendiri. Akibatnya, ia menjadi sangat pandai memecahkan masalah kami sehingga kami meninggalkan "sumbat" sebelumnya dan berfokus untuk memperbaikinya, yang sekarang kami gunakan dalam produksi di mana-mana.
Lapisan indeks
Pada akhirnya, apa yang kita miliki sekarang? Bahkan, indeks herpes zoster terdiri dari beberapa lapisan (array) dengan elemen dengan panjang konstan - dari 0 hingga 128 bit - yang tidak hanya bergantung pada lapisan dan tidak harus merupakan kelipatan dari delapan.
Setiap lapisan berperan. Beberapa membuat pencarian lebih cepat, beberapa menghemat ruang, dan beberapa tidak pernah digunakan, tetapi sangat dibutuhkan. Kami akan mencoba menggambarkannya untuk meningkatkan efisiensi total dalam pencarian.

Sumber Gambar: Wikipedia
1. Array Indeks
Tanpa kehilangan sifat umum, kita sekarang akan mempertimbangkan bahwa sirap tunggal ditugaskan ke dokumen,
(docId → sirap)
Kami akan menukar elemen pasangan (terbalik, karena indeks sebenarnya "terbalik"!),
(sirap → docId)
Urutkan berdasarkan nilai-nilai herpes zoster dan bentuk sebuah layer. Karena ukuran sirap dan pengidentifikasi dokumen adalah konstan, sekarang siapa pun yang memahami pencarian biner dapat menemukan pasangan di luar pembacaan O (logn) file. Sebanyak itu, sangat banyak. Tapi ini lebih baik daripada hanya O (n) .
Jika dokumen memiliki beberapa herpes zoster, maka akan ada beberapa pasangan dari dokumen tersebut. Jika ada beberapa dokumen dengan sirap yang sama, maka ini juga tidak akan banyak berubah - akan ada beberapa pasangan berturut-turut dengan sirap yang sama. Dalam kedua kasus ini, pencarian akan berlangsung untuk waktu yang sebanding.
2. Array kelompok
Kami membagi elemen indeks dengan hati-hati dari langkah sebelumnya ke dalam grup dengan cara apa pun yang mudah. Sebagai contoh, sehingga mereka masuk ke dalam sektor cluster, blok unit alokasi (baca, 4096 bytes), dengan mempertimbangkan jumlah bit dan trik lainnya, akan membentuk kamus yang efektif. Kami mendapatkan sederetan posisi grup seperti itu:
group_map (hash (sirap)) -> group_position.
Saat mencari sirap, kami sekarang akan mencari posisi grup di kamus ini, dan kemudian membongkar grup dan mencari langsung di memori. Seluruh operasi membutuhkan dua bacaan.
Kamus posisi grup membutuhkan beberapa kali lipat lebih kecil dari indeks itu sendiri, seringkali dapat dengan mudah diturunkan ke memori. Dengan demikian, tidak akan ada dua bacaan, tetapi satu. Total, O (1) .
3. Filter Bloom
Pada wawancara, kandidat sering memecahkan masalah dengan mengeluarkan solusi unik dengan O (n ^ 2) atau bahkan O (2 ^ n) . Tetapi kita tidak melakukan hal-hal bodoh. Apakah ada O (0) di dunia, itu pertanyaannya? Mari kita coba tanpa banyak harapan untuk hasilnya ...
Mari kita beralih ke area subjek. Jika siswa selesai dengan baik dan menulis karya sendiri, atau hanya tidak ada teks, tetapi sampah, maka sebagian besar herpes zoster akan menjadi unik dan tidak akan ditemukan dalam indeks. Struktur data seperti filter Bloom dikenal di dunia. Sebelum mencari, periksa sirap di atasnya. Jika tidak ada sirap dalam indeks, maka Anda tidak dapat melihat lebih jauh, jika tidak melangkah lebih jauh.
Filter Bloom itu sendiri cukup sederhana, tetapi tidak masuk akal untuk menggunakan vektor hash dengan volume kami. Cukup menggunakan satu: +1 membaca dari filter Bloom. Ini memberikan pembacaan -1 atau -2 dari tahap berikutnya, jika sirapnya unik, dan tidak ada false positive dalam filter. Awasi tanganmu!
Probabilitas kesalahan filter Bloom ditetapkan selama konstruksi, probabilitas sirap yang tidak diketahui ditentukan oleh kejujuran siswa. Perhitungan sederhana bisa sampai pada ketergantungan berikut:
- Jika kami mempercayai kejujuran orang (mis., Sebenarnya dokumen itu asli), maka kecepatan pencarian akan berkurang;
- Jika dokumen dijahit dengan jelas, maka kecepatan pencarian akan meningkat, tetapi kita membutuhkan banyak memori.
Dengan kepercayaan pada siswa, kami memiliki prinsip "kepercayaan, tetapi verifikasi", dan latihan menunjukkan bahwa masih ada keuntungan dari filter Bloom.
Mengingat bahwa struktur data ini juga lebih kecil dari indeks itu sendiri dan dapat di-cache, dalam kasus terbaik, ini memungkinkan Anda untuk menjatuhkan sirap tanpa akses disk sama sekali.
4. Ekor yang berat
Ada herpes zoster yang ditemukan hampir di mana-mana. Bagian mereka dalam jumlah total sangat sedikit, tetapi ketika membangun indeks pada langkah pertama, pada langkah kedua, kelompok puluhan dan ratusan MB dapat diperoleh. Kami akan mengingatnya secara terpisah dan kami akan segera membuangnya dari permintaan pencarian.
Ketika langkah sepele ini pertama kali digunakan pada tahun 2011, ukuran indeks dibelah dua, dan pencarian itu sendiri dipercepat.
5. Ekor lainnya
Meski begitu, sirap dapat memiliki banyak dokumen. Dan ini normal. Puluhan, ratusan, ribuan ... Menjaga mereka di dalam indeks utama menjadi tidak menguntungkan, mereka juga tidak dapat masuk ke dalam grup, dari mana volume kamus posisi grup meningkat. Tempatkan mereka dalam urutan terpisah dengan penyimpanan yang lebih efisien. Menurut statistik, keputusan seperti itu lebih dari dibenarkan. Selain itu, berbagai paket bitwise dapat mengurangi jumlah akses disk dan mengurangi volume indeks.
Akibatnya, untuk kemudahan perawatan, kami mencetak semua lapisan ini menjadi satu file besar - potongan. Ada sepuluh lapisan di dalamnya. Tetapi bagian tidak digunakan dalam pencarian, bagian sangat kecil dan selalu disimpan dalam memori, bagian secara aktif di-cache seperlunya / mungkin.
Dalam pertempuran, paling sering pencarian sirap turun ke satu atau dua bacaan file acak. Dalam kasus terburuk, Anda harus melakukan tiga. Semua lapisan secara efektif (kadang-kadang bitwise) dikemas dengan susunan elemen dengan panjang konstan. Begitulah normalisasi. Waktu untuk membongkar tidak signifikan dibandingkan dengan harga total volume selama penyimpanan dan kemampuan untuk menyimpan lebih baik.
Ketika membangun, ukuran lapisan terutama dihitung terlebih dahulu, ditulis berurutan, sehingga prosedur ini cukup cepat.
Bagaimana Anda sampai di sana, tidak tahu di mana
2010 , . , . , .

Sumber Gambar: Wikipedia
Awalnya, indeks kami terdiri dari dua bagian - konstanta, yang dijelaskan di atas, dan sementara, yang perannya adalah SQL, atau BDB, atau log pembaruannya sendiri. Kadang-kadang, misalnya, sebulan sekali (dan kadang-kadang setahun), yang sementara diurutkan, disaring dan digabung dengan yang utama. Hasilnya adalah yang bersatu, dan dua yang lama dihapus. Jika yang sementara tidak dapat masuk ke dalam RAM, maka prosedur dilakukan melalui penyortiran eksternal.
Prosedur ini agak merepotkan, itu dimulai dalam mode semi-manual dan diperlukan sebenarnya menulis ulang seluruh file indeks dari awal. Menulis ulang ratusan gigabyte untuk beberapa juta dokumen - yah, sangat-sangat menyenangkan, saya katakan ...
Kenangan dari masa lalu ...SSD. , 31 SSD wcf- . , . , .
Agar SSD tidak terlalu tegang, dan indeks diperbarui lebih sering, pada tahun 2012 kami melibatkan rantai beberapa bagian, potongan sesuai dengan skema berikut:

Di sini indeks terdiri dari rantai dengan tipe potongan yang sama, kecuali untuk yang pertama. Yang pertama, addon, adalah log append-only dengan indeks dalam RAM. Potongan berikutnya bertambah dalam ukuran (dan usia) hingga yang terakhir (nol, utama, root, ...).
Catatan untuk pengendara sepeda ...Terkadang Anda tidak harus bingung menulis kode dan bahkan tidak berpikir, tetapi cukup google saja. Sampai dengan notasi, diagram ini mirip dengan yang ini dari artikel 1996
"Pohon gabungan-log struktur" :
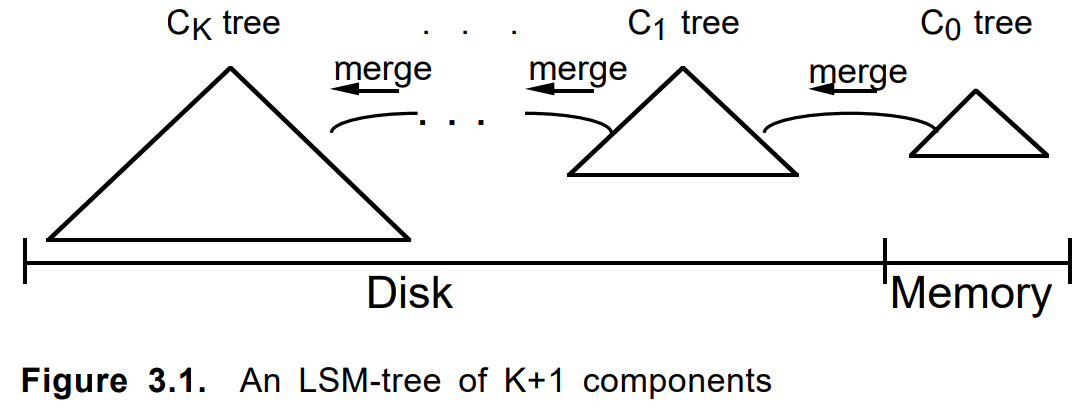
Saat menambahkan dokumen, pertama kali dilipat menjadi addon. Ketika penuh atau dengan kriteria lain, sepotong permanen dibangun di atasnya. Beberapa potongan tetangga, jika perlu, digabung menjadi yang baru, dan yang asli dihapus. Memperbarui dokumen atau menghapusnya berhasil dengan cara yang sama.
Gabungkan kriteria, panjang rantai, algoritma bypass, akuntansi untuk item yang dihapus dan pembaruan, parameter lainnya disetel. Pendekatan itu sendiri terlibat dalam beberapa tugas serupa dan mengambil bentuk sebagai kerangka kerja LSM internal yang terpisah pada .net bersih. Sekitar waktu yang sama, LevelDB menjadi populer.
Sedikit komentar tentang LSM-treeLSM-Tree adalah algoritma yang agak menarik, dengan justifikasi yang baik. Tapi, IMHO, ada beberapa kekaburan dari arti Pohon istilah. Dalam
artikel aslinya
, itu tentang rantai pohon dengan kemampuan untuk mentransfer cabang. Dalam implementasi modern, ini tidak selalu terjadi. Jadi kerangka kerja kami akhirnya dinamai sebagai LsmChain, yaitu rantai potongan lsm.
Algoritme LSM dalam kasus kami memiliki fitur yang sangat cocok:
- sisipkan / hapus / perbarui,
- mengurangi beban SSD saat memperbarui,
- format potongan disederhanakan,
- pencarian selektif hanya pada potongan lama / baru,
- cadangan sepele
- apa lagi yang diinginkan jiwa.
- ...
Secara umum, terkadang berguna untuk menciptakan sepeda untuk pengembangan diri.
Optimalisasi makro, mikro, nano
Dan akhirnya, kami akan berbagi kiat teknis tentang bagaimana kami di Antiplagiarisme melakukan hal-hal seperti itu di Net (dan tidak hanya di atasnya).
Perhatikan sebelumnya bahwa seringkali semuanya sangat tergantung pada perangkat keras khusus Anda, data atau mode penggunaan. Setelah memutar di satu tempat, kami terbang keluar dari cache CPU, di tempat lain - kami mengalami bandwidth antarmuka SATA, di tempat ketiga - kami mulai menggantung di GC. Dan di suatu tempat di inefisiensi pelaksanaan panggilan sistem tertentu.

Sumber Gambar: Wikipedia
Bekerja dengan file
Masalah dengan akses ke file tidak unik dengan kami. Ada file besar exabyte terabyte , volume yang berkali-kali lebih besar dari jumlah RAM. Tugasnya adalah membaca jutaan yang tersebar di sekitarnya dari beberapa nilai acak kecil. Dan untuk melakukannya dengan cepat, efisien dan murah. Kami harus memeras, membandingkan, dan banyak berpikir.
Mari kita mulai dengan yang sederhana. Untuk membaca byte berharga Anda perlu:
- Buka file (FileStream baru);
- Pindah ke posisi yang diinginkan (Posisi atau Carilah, tidak ada perbedaan);
- Baca array byte yang diinginkan (Baca);
- Tutup file (Buang).
Dan ini buruk, karena panjang dan suram. Melalui uji coba, kesalahan, dan berulang kali menginjak menyapu, kami mengidentifikasi algoritma tindakan berikut:
Terbuka tunggal, banyak baca
Jika urutan ini dilakukan di dahi, untuk setiap permintaan ke disk, maka kami akan segera menekuk. Masing-masing item masuk ke permintaan ke kernel OS, yang mahal.
Jelas, Anda harus membuka file satu kali dan membaca secara berurutan dari semua jutaan nilai kami, yang kami lakukan
Tidak ada yang ekstra
Mendapatkan ukuran file, posisi saat ini di dalamnya juga cukup sulit dioperasikan. Bahkan jika file tidak berubah.
Setiap pertanyaan seperti mendapatkan ukuran file atau posisi saat ini di dalamnya harus dihindari.
Filestreampool
Selanjutnya Sayangnya, FileStream pada dasarnya single-threaded. Jika Anda ingin membaca file secara paralel, Anda harus membuat / menutup aliran file baru.
Sampai Anda membuat sesuatu seperti aiosync, Anda harus menciptakan sepeda sendiri.
Saran saya adalah membuat kumpulan aliran file per file. Ini akan menghindari membuang-buang waktu membuka / menutup file. Dan jika Anda menggabungkannya dengan ThreadPool dan memperhitungkan bahwa SSD mengeluarkan megaIOPS-nya dengan multithreading yang kuat ... Anda mengerti saya.
Unit alokasi
Selanjutnya Perangkat penyimpanan (HDD, SSD, Optane) dan sistem file beroperasi dengan file pada level blok (cluster, sektor, unit alokasi). Mereka mungkin tidak cocok, tetapi sekarang hampir selalu 4096 byte. Membaca satu atau dua byte di perbatasan dua blok seperti itu di SSD sekitar satu setengah kali lebih lambat daripada di dalam blok itu sendiri.
Anda harus mengatur data Anda sehingga elemen yang dikurangkan berada dalam batas-batas blok sektor cluster .
Tanpa buffer.
Selanjutnya FileStream secara default menggunakan buffer 4096 byte. Dan berita buruknya adalah Anda tidak bisa mematikannya. Namun, jika Anda membaca lebih banyak data daripada ukuran buffer, maka yang terakhir akan diabaikan.
Untuk pembacaan acak, Anda harus mengatur buffer ke 1 byte (tidak akan bekerja kurang) dan kemudian mempertimbangkan bahwa itu tidak digunakan.
Gunakan penyangga.
Selain bacaan acak, ada juga yang berurutan. Di sini buffer sudah bisa menjadi berguna jika Anda tidak ingin membaca semuanya sekaligus. Saya menyarankan Anda untuk mulai dengan artikel ini. Ukuran buffer yang akan diatur tergantung pada apakah file tersebut ada pada HDD atau pada SSD. Dalam kasus pertama, 1MB akan optimal, yang kedua, 4kB standar akan cukup. Jika ukuran area data yang akan dibaca sebanding dengan nilai-nilai ini, maka lebih baik untuk mengurangkannya sekaligus, melompati buffer, seperti dalam kasus pembacaan acak. Buffer besar tidak akan menghasilkan keuntungan dalam kecepatan, tetapi akan mulai menekan GC.
Saat secara berurutan membaca potongan besar file, Anda harus mengatur buffer ke 1MB untuk HDD dan 4kB untuk SSD. Yah, itu tergantung.
MMF vs FileStream
Pada 2011, tip datang ke MemoryMappedFile, karena mekanisme ini telah diterapkan sejak .Net Framework v4.0. Pertama, mereka menggunakannya ketika caching filter Bloom, yang sudah tidak nyaman dalam mode 32-bit karena keterbatasan 4GB. Tetapi ketika pindah ke dunia 64 bit, saya menginginkan lebih. Tes pertama sangat mengesankan. Caching gratis, kecepatan aneh, antarmuka pembacaan struktur yang nyaman. Tapi ada masalah:
- Pertama, anehnya, kecepatan. Jika data sudah di-cache, maka semuanya baik-baik saja. Tetapi jika tidak, membaca satu byte dari file disertai dengan "mengangkat" jumlah data yang jauh lebih besar daripada dengan pembacaan reguler.
- Kedua, cukup aneh, daya ingat. Ketika dipanaskan, memori bersama tumbuh, workingset - tidak, yang logis. Tetapi kemudian proses tetangga mulai berperilaku tidak terlalu baik. Mereka dapat melakukan swap, atau secara tidak sengaja jatuh dari OoM. Volume yang ditempati oleh MMF dalam RAM, sayangnya, tidak dapat dikontrol. Dan keuntungan dari cache dalam kasus ketika file yang dapat dibaca adalah beberapa pesanan lebih besar dari memori menjadi tidak berarti.
Masalah kedua masih bisa diperjuangkan. Hilang jika indeks bekerja di buruh pelabuhan atau pada mesin virtual khusus. Tapi masalah kecepatannya fatal.
Akibatnya, MMF ditinggalkan sedikit lebih dari sepenuhnya. Caching dalam Anti-Plagiarisme mulai dilakukan dalam bentuk eksplisit, jika mungkin mengingat-ingat lapisan yang paling sering digunakan pada prioritas dan batas yang diberikan.

Sumber Gambar: Wikipedia
Bits / byte
Bukan byte dunia adalah satu. Terkadang Anda harus turun ke level bit.
Sebagai contoh: misalkan Anda memiliki triliun angka yang dipesan sebagian, berhasrat untuk menyimpan dan membaca sering. Bagaimana cara mengatasi semua ini?
- Penulisan Biner Sederhana. - cepat tapi lambat. Ukuran itu penting. Pembacaan dingin terutama tergantung pada ukuran file.
- Variasi lain dari VarInt? - cepat tapi lambat. Masalah konsistensi. Volume mulai tergantung pada data, yang membutuhkan memori tambahan untuk penentuan posisi.
- Packing sedikit? - cepat tapi lambat. Anda harus lebih hati-hati mengendalikan tangan Anda.
Tidak ada solusi yang ideal, tetapi dalam kasus khusus, cukup menekan kisaran dari 32 bit ke yang diperlukan untuk menyimpan ekor yang disimpan 12% lebih banyak (puluhan GB!) Daripada VarInt (tentu saja hanya menyimpan perbedaan yang bertetangga), dan itu beberapa kali opsi dasar.
Contoh lain. Anda memiliki tautan dalam file ke sejumlah array angka. Tautan 64-bit, file per terabyte. Segalanya tampak baik-baik saja. Terkadang ada banyak angka dalam array, terkadang sedikit. Seringkali sedikit. Sangat sering. Kemudian ambil dan simpan seluruh array dalam tautan itu sendiri. Untung Kemas dengan hati-hati tapi jangan lupa.
Struct, unsafe, batching, micro-opts
Nah dan optimalisasi mikro lainnya. Saya tidak akan menulis di sini tentang dangkal "apakah layak menyimpan Panjang array dalam satu lingkaran" atau "yang lebih cepat, untuk atau foreach".
Ada dua aturan sederhana, dan kami akan mematuhinya: 1. "benchmark semuanya", 2. "benchmark lebih banyak."
Struct . Digunakan di mana-mana. Jangan kirim GC. Dan, seperti yang sedang modis saat ini, kami juga memiliki ValueList mega-cepat kami sendiri.
Tidak aman . Mengizinkan struktur mapit (dan tidak dipetakan) ke array byte saat digunakan. Dengan demikian, kita tidak perlu alat serialisasi terpisah. Benar, ada pertanyaan untuk menyematkan dan mendefragmentasi tumpukan, tetapi sejauh ini belum ditampilkan. Yah, itu tergantung.
Batching . Pekerjaan dengan banyak elemen harus melalui paket / grup / blok. Baca / tulis file, transfer antar fungsi. Masalah terpisah adalah ukuran paket ini. Biasanya ada yang optimal, dan ukurannya sering berkisar antara 1kB hingga 8MB (ukuran cache CPU, ukuran cluster, ukuran halaman, ukuran hal lain). Cobalah memompa melalui fungsi <nte> IEnumerable atau IEnumerable <byte [1024]> dan rasakan perbedaannya.
Pooling . Setiap kali Anda menulis "baru," anak kucing mati di suatu tempat. Sekali byte baru [ 85000 ] - dan traktor mengendarai satu ton angsa. Jika tidak mungkin menggunakan stackalloc, maka buat kumpulan objek apa pun dan gunakan kembali.
Sebaris . Bagaimana cara membuat dua fungsi alih-alih satu dapat mempercepat semuanya sepuluh kali? Sederhana Semakin kecil ukuran tubuh dari fungsi (metode), semakin besar kemungkinan akan sejajar. Sayangnya, di dunia dotnet masih tidak ada cara untuk melakukan inlining parsial, jadi jika Anda memiliki fungsi panas yang dalam 99% kasus keluar setelah memproses beberapa baris pertama, dan sisa seratus baris untuk memproses sisa 1%, maka dengan aman membaginya menjadi dua (atau tiga), membawa ekor yang berat ke fungsi yang terpisah.
Apa lagi
Rentang <T> , Memori <T> - menjanjikan. Kode akan lebih sederhana dan mungkin sedikit lebih cepat. Kami menunggu rilis .Net Core v3.0 dan Std v2.1 untuk beralih ke mereka, karena kernel kami di .Net Std v2.0, yang biasanya tidak mendukung span.
Async / menunggu - sejauh ini kontroversial. Benchmark baca acak yang paling sederhana menunjukkan bahwa konsumsi CPU sebenarnya turun, tetapi kecepatan baca juga menurun. Harus menonton. Kami belum menggunakannya di dalam indeks.
Kesimpulan
Saya berharap bahwa keterpencilan saya akan memberi Anda kesenangan dari memahami keindahan dari beberapa keputusan. Kami sangat menyukai indeks kami. Ini efisien, kode yang indah, bekerja dengan sangat baik. Solusi yang sangat terspesialisasi dalam inti sistem, tempat kerja yang kritis, lebih baik daripada solusi umum. Sistem kontrol versi kami mengingat insert assembler dalam kode C ++. Sekarang ada empat plus - hanya C # murni, hanya. Net. Di dalamnya kami menulis bahkan algoritma pencarian yang paling rumit dan tidak menyesal sama sekali. Dengan munculnya .Net Core, transisi ke Docker, jalan menuju masa depan DevOps yang cerah telah menjadi lebih mudah dan lebih jelas. Depan adalah solusi dari masalah shardisasi dan replikasi dinamis tanpa mengurangi efektivitas dan keindahan solusi.
Terima kasih kepada semua orang yang membaca sampai akhir. Untuk semua perbedaan dan ketidakkonsistenan lainnya, silakan tulis komentar. Saya akan senang dengan saran dan bantahan yang masuk akal dalam komentar.