Kata Pengantar
Artikel ini tidak terlalu mirip dengan yang diterbitkan sebelumnya tentang pemindaian Internet di negara-negara tertentu, karena saya tidak mengejar tujuan pemindaian massal segmen tertentu dari Internet untuk port terbuka dan keberadaan kerentanan paling populer karena melanggar hukum.
Saya agak memiliki minat yang sedikit berbeda - untuk mencoba mengidentifikasi semua situs yang relevan di zona BY domain menggunakan metode yang berbeda, untuk menentukan tumpukan teknologi yang digunakan, melalui layanan seperti Shodan, VirusTotal, dll. Untuk melakukan pengintaian pasif atas IP dan port terbuka dan, dalam lampiran, untuk mengumpulkan sedikit berguna lainnya informasi untuk pembentukan beberapa statistik umum pada tingkat keamanan mengenai situs dan pengguna.
Pendahuluan dan perangkat kami
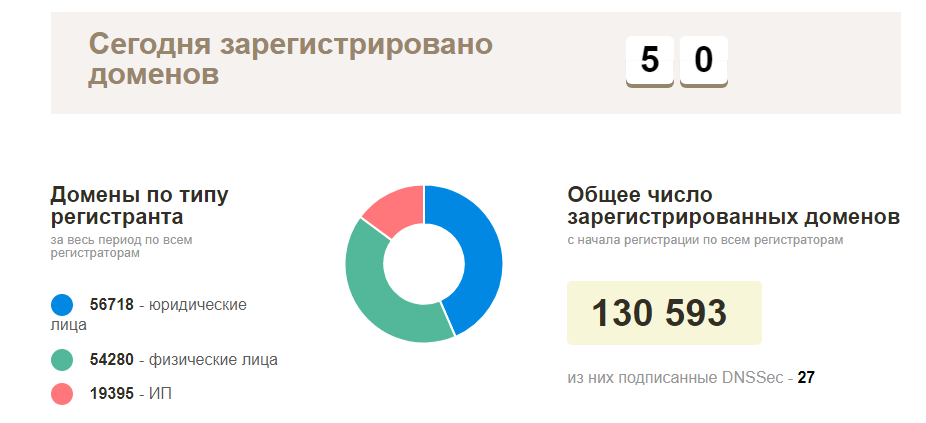
Rencana di awal sangat sederhana - hubungi registrar lokal Anda untuk daftar domain terdaftar saat ini, kemudian periksa semuanya untuk ketersediaan dan mulai menjelajahi situs yang berfungsi. Pada kenyataannya, semuanya ternyata jauh lebih rumit - informasi semacam ini alami, tidak ada yang mau memberikan, dengan pengecualian halaman statistik resmi dari nama domain terdaftar aktual di zona BY (sekitar 130 ribu domain). Jika tidak ada informasi seperti itu, maka Anda harus mengumpulkannya sendiri.
Dalam hal alat, pada kenyataannya, semuanya cukup sederhana - kami melihat ke arah open source, Anda selalu dapat menambahkan sesuatu, menyelesaikan beberapa kruk minimal. Yang paling populer, alat berikut digunakan:
Mulai dari Kegiatan: Titik Awal
Sebagai pengantar, seperti yang saya katakan sebelumnya, idealnya nama domain cocok, tetapi di mana saya bisa mendapatkannya? Kita perlu mulai dari sesuatu yang lebih sederhana, dalam hal ini alamat IP cocok untuk kita, tetapi sekali lagi - dengan pencarian terbalik tidak selalu mungkin untuk menangkap semua domain, dan ketika mengumpulkan nama host - itu tidak selalu merupakan domain yang benar. Pada tahap ini, saya mulai berpikir tentang kemungkinan skenario untuk mengumpulkan informasi semacam ini, lagi - fakta bahwa anggaran kami adalah $ 5 untuk sewa VPS diperhitungkan, semuanya harus gratis.
Sumber informasi potensial kami:
- Alamat IP (situs ip2lokasi )
- Pencarian domain berdasarkan bagian kedua dari alamat email (tetapi di mana mendapatkannya? Mari kita cari tahu sedikit di bawah)
- Beberapa penyedia pendaftar / hosting dapat memberi kami informasi tersebut dalam bentuk subdomain
- Subdomain dan kebalikannya berikutnya (Sublist3r dan Aquatone dapat membantu di sini)
- Masukan bruteforce dan manual (panjang, suram, tetapi mungkin, meskipun saya tidak menggunakan opsi ini)
Saya akan berlari sedikit ke depan dan mengatakan bahwa dengan pendekatan ini saya berhasil mengumpulkan sekitar 50 ribu domain dan situs unik, masing-masing (saya tidak berhasil memproses semuanya). Jika dia terus mengumpulkan informasi secara aktif, maka pastinya dalam waktu kurang dari sebulan kerja konveyor saya akan menguasai seluruh database, atau sebagian besar.
Mari kita mulai bisnis
Pada artikel sebelumnya, informasi tentang alamat IP diambil dari situs IP2LOCATION, untuk alasan yang jelas, saya tidak menemukan artikel ini (karena semua tindakan terjadi lebih awal), tetapi juga datang ke sumber ini. Benar, dalam kasus saya, pendekatannya berbeda - saya memutuskan untuk tidak mengambil database secara lokal untuk diri saya sendiri dan tidak mengambil informasi dari CSV, tetapi memutuskan untuk memantau perubahan secara langsung di situs, secara berkelanjutan dan sebagai basis utama dari mana semua skrip berikutnya akan mengambil tujuan - membuat tabel dengan Alamat IP dalam berbagai format: CIDR, daftar "dari" dan "ke", tanda negara (untuk berjaga-jaga), Nomor AS, Deskripsi AS.
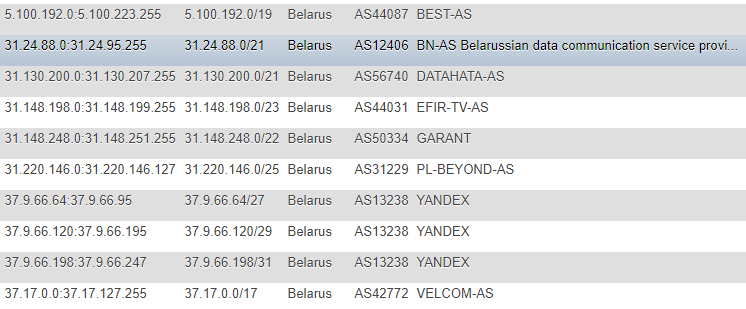
Formatnya bukan yang paling optimal, tetapi saya cukup senang dengan demo dan promosi satu kali, dan agar tidak terus mencari informasi tambahan seperti ASN, saya memutuskan untuk mencatatnya sendiri. Untuk mendapatkan informasi ini, saya beralih ke layanan
IpToASN , mereka memiliki API yang nyaman (dengan batasan), yang sebenarnya Anda hanya perlu mengintegrasikannya ke dalam diri Anda.
Kode parsing IPfunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
Setelah kami menemukan IP, kami perlu menjalankan seluruh database kami melalui layanan pencarian terbalik, sayangnya, tanpa batasan - ini tidak mungkin, kecuali untuk uang.
Dari layanan yang bagus untuk ini dan nyaman untuk digunakan, saya ingin menyebutkan dua:
- VirusTotal - membatasi frekuensi panggilan dari satu kunci API
- Hackertarget.com (API mereka) - membatasi jumlah klik dari satu IP
Melewati batas, opsi berikut diperoleh:
- Dalam kasus pertama, salah satu skenario adalah untuk menahan timeout 15 detik, secara total kita akan memiliki 4 panggilan per menit, yang dapat sangat mempengaruhi kecepatan kita dan dalam situasi ini akan berguna untuk menggunakan 2-3 kunci seperti itu, dan saya akan merekomendasikan menggunakan yang sama untuk proksi dan mengubah agen-pengguna.
- Dalam kasus kedua, saya menulis sebuah skrip untuk penguraian otomatis dari basis data proxy berdasarkan informasi yang tersedia untuk umum, validasi dan penggunaan selanjutnya (tetapi kemudian saya meninggalkan opsi ini karena VirusTotal juga cukup pada dasarnya)
Kami melangkah lebih jauh dan dengan lancar menuju ke alamat email. Mereka juga dapat menjadi sumber informasi yang berguna, tetapi di mana mengumpulkannya? Saya tidak perlu mencari solusi untuk waktu yang lama, karena pengguna memegang sedikit di segmen situs pribadi kami, dan kebanyakan dari mereka adalah organisasi - situs web profil seperti direktori toko online, forum, dan pasar bersyarat yang cocok untuk kami.
Misalnya, pemeriksaan cepat terhadap salah satu situs ini menunjukkan bahwa banyak pengguna menambahkan email mereka langsung ke profil publik mereka dan, dengan demikian, bisnis ini dapat diurai dengan hati-hati untuk penggunaan di masa mendatang.
Saya tidak akan membahas detail penguraian setiap situs, di tempat yang lebih nyaman untuk menebak ID pengguna dengan kekerasan, di suatu tempat lebih mudah untuk menguraikan peta situs, mendapatkan informasi tentang halaman perusahaan dari itu dan kemudian mengumpulkan alamat dari mereka. Setelah mengumpulkan alamat, tetap bagi kami untuk melakukan beberapa operasi sederhana segera menyortirnya berdasarkan zona domain, melestarikan "ekor" dan menjalankannya untuk mengecualikan duplikat dari database yang ada.
Pada tahap ini, saya percaya bahwa dengan pembentukan ruang lingkup, kita dapat mengakhiri dan beralih ke kecerdasan. Kecerdasan, seperti yang telah kita ketahui, dapat terdiri dari dua jenis - aktif dan pasif, dalam kasus kami - pendekatan pasif akan paling relevan. Tetapi sekali lagi, hanya mengakses situs pada port 80 atau 443 tanpa beban berbahaya dan mengeksploitasi kerentanan adalah tindakan yang sah. Minat kami adalah respons server terhadap satu permintaan, dalam beberapa kasus mungkin ada dua permintaan (redirect dari http ke https), dalam kasus yang lebih jarang, sebanyak tiga (ketika www digunakan).
Kecerdasan
Dengan menggunakan informasi seperti domain, kami dapat mengumpulkan data berikut:
- Catatan DNS (NS, MX, TXT)
- Header Jawab
- Identifikasi tumpukan teknologi yang digunakan
- Pahami protokol apa yang digunakan situs ini.
- Cobalah untuk mengidentifikasi port terbuka (berdasarkan database Shodan / Censys) tanpa pemindaian langsung
- Cobalah untuk mengidentifikasi kerentanan berdasarkan korelasi informasi dari Shodan / Censys dengan database Vulners
- Apakah itu ada di basis data malware Google Safe Browsing
- Kumpulkan alamat email berdasarkan domain, serta kecocokan yang sudah ditemukan dan periksa oleh Have I Been Pwned, selain itu - menautkan ke jejaring sosial
- Domain dalam beberapa kasus tidak hanya wajah perusahaan, tetapi juga produk dari aktivitasnya, alamat email untuk pendaftaran layanan, dll., Masing-masing - Anda dapat mencari informasi yang terkait dengan mereka pada sumber daya seperti GitHub, Pastebin, Google Dorks (Google CSE )
Anda selalu dapat melanjutkan dan menggunakan masscan atau nmap, zmap sebagai opsi, mengaturnya terlebih dahulu melalui Tor dengan meluncurkan secara acak atau bahkan dari beberapa kejadian, tetapi kami memiliki tujuan lain dan namanya menyiratkan bahwa saya tidak melakukan pemindaian langsung.
Kami mengumpulkan catatan DNS, memeriksa kemungkinan amplifikasi permintaan dan kesalahan konfigurasi seperti AXFR:
Contoh mengumpulkan catatan server NS dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
Contoh pengumpulan catatan MX (lihat NS, ganti saja 'ns' dengan 'mx'
Periksa AXFR (ada banyak solusi di sini, ini ada kruk lain, tetapi bukan keamanan, yang digunakan untuk melihat output) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
Periksa Amplifikasi DNS dig +short test.openresolver.com TXT @$dns
Dalam kasus saya, server NS diambil dari database, jadi pada akhir variabel, di sana Anda dapat mengganti sembarang server. Mengenai kebenaran hasil dari layanan ini, saya tidak dapat memastikan bahwa semuanya bekerja dengan lancar di sana dan hasilnya selalu valid, tetapi saya berharap bahwa sebagian besar hasilnya nyata.
Jika untuk tujuan apa pun kita perlu menyimpan URL final lengkap ke situs, untuk ini saya menggunakan cURL:
curl -I -L $target | awk '/Location/{print $2}'
Dia sendiri akan melalui seluruh pengalihan dan menampilkan yang terakhir, yaitu URL situs saat ini. Dalam kasus saya, itu sangat berguna untuk penggunaan alat selanjutnya seperti WhatWeb.
Kenapa kita harus menggunakannya? Untuk menentukan OS, server web, situs CMS yang digunakan, beberapa tajuk, modul tambahan seperti pustaka / kerangka kerja JS / HTML, serta judul situs yang nantinya dapat Anda coba saring berdasarkan bidang aktivitas yang sama.
Pilihan yang sangat nyaman dalam hal ini adalah untuk mengekspor hasil pengoperasian alat dalam format XML untuk analisis selanjutnya dan impor ke dalam basis data jika ada tujuan untuk memproses semuanya nanti.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
Untuk saya sendiri, saya membuat JSON sebagai hasil dari output dan sudah memasukkannya ke dalam database.
Berbicara tentang tajuk, Anda dapat melakukan hal yang hampir sama dengan CURL biasa dengan mengeksekusi kueri formulir:
curl -I https://www.mywebsite.com
Di tajuk, tangkap informasi tentang CMS dan server web menggunakan ekspresi reguler, misalnya.
Selain yang berguna, kami juga dapat menyoroti kemungkinan mengumpulkan informasi tentang port terbuka menggunakan Shodan dan kemudian menggunakan data yang telah diperoleh, melakukan pemeriksaan pada database Vulners menggunakan API mereka (tautan ke layanan diberikan di header). Tentu saja, mungkin ada masalah dengan keakuratan dalam skenario ini, tetapi ini bukan pemindaian langsung dengan validasi manual, tetapi "juggling" data dari sumber pihak ketiga, tapi setidaknya itu lebih baik daripada tidak sama sekali.
Fungsi PHP untuk Shodan function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
Contoh dari analisis perbandingan # 1 Ya, karena mereka mulai berbicara tentang API, maka Vulners memiliki batasan dan solusi yang paling optimal adalah dengan menggunakan skrip Python mereka, semuanya akan berfungsi dengan baik tanpa puntiran-puntiran, dalam kasus PHP, saya menemui beberapa kesulitan kecil (sekali lagi, tambahkan. timeout menyelamatkan situasi).
Salah satu tes terbaru - kami akan mempelajari informasi tentang firewall yang digunakan dengan skrip seperti "wafw00f". Saat menguji alat yang luar biasa ini, saya perhatikan satu hal yang menarik: tidak selalu pertama kali menentukan jenis firewall yang digunakan.
Untuk melihat jenis firewall apa yang berpotensi dapat dideteksi wafw00f, Anda dapat memasukkan perintah berikut:
wafw00f -l
Untuk menentukan jenis firewall, wafw00f menganalisis header respons server setelah mengirim permintaan standar ke situs, jika upaya ini tidak cukup, menghasilkan permintaan tes sederhana tambahan dengan baik, dan jika ini tidak cukup lagi, metode ketiga beroperasi pada data setelah dua upaya pertama .
Karena untuk statistik, pada kenyataannya, kami tidak memerlukan seluruh jawaban, kami memotong semua kelebihan dengan ekspresi reguler dan hanya meninggalkan nama firewall:
/is\sbehind\sa\s(.+?)\n/
Yah, seperti yang saya tulis sebelumnya - selain informasi tentang domain dan situs, informasi tentang alamat email dan jejaring sosial juga diperbarui dalam mode pasif:
Statistik berdasarkan email ditentukan berdasarkan domain Contoh penentuan ikatan jejaring sosial ke alamat email Cara termudah adalah berurusan dengan validasi alamat di Twitter (2 cara), dengan Facebook (1 cara) dalam hal ini ternyata menjadi sedikit lebih rumit karena sistem yang sedikit lebih rumit untuk menghasilkan sesi pengguna nyata.
Mari kita beralih ke statistik kering.
Statistik DNS
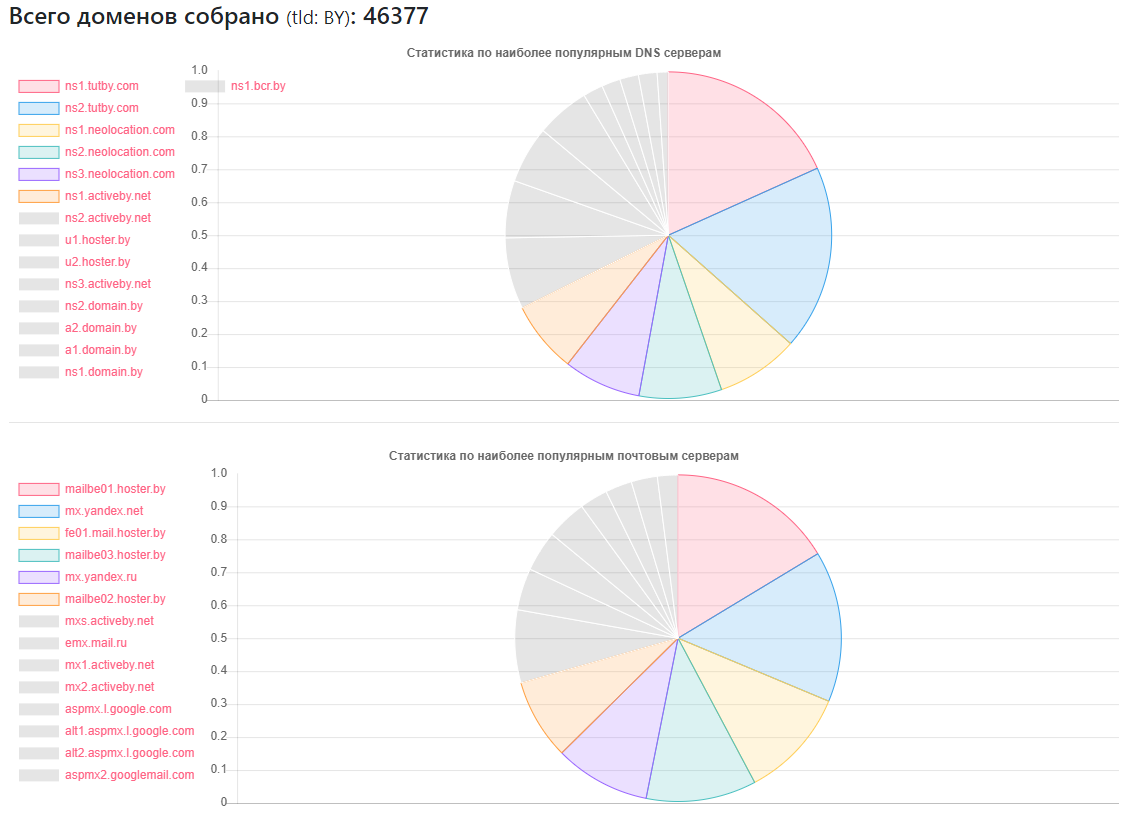 Penyedia - berapa banyak situs
Penyedia - berapa banyak situsns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
DNS unik ditemukan: 2462
Server MX (surat) unik: 9175 (selain layanan populer, ada cukup banyak administrator yang menggunakan layanan surat mereka sendiri)
Dipengaruhi oleh Transfer Zona DNS: 1011
Dipengaruhi oleh Penguatan DNS: 531
Beberapa penggemar CloudFlare: 375 (berdasarkan catatan NS yang digunakan)
Statistik CMS
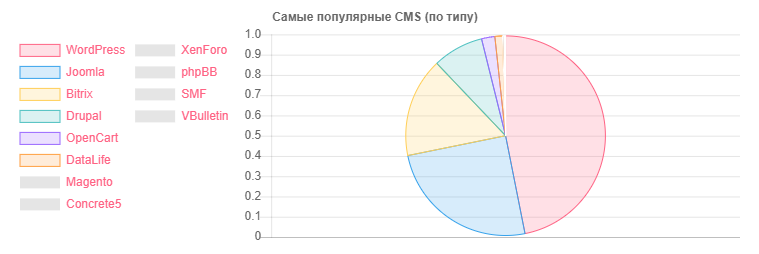 CMS - Kuantitas
CMS - KuantitasWordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Instalasi WordPress yang berpotensi rentan: 2977
- Instalasi yang berpotensi rentan terhadap Joomla: 212
- Dengan menggunakan layanan Google SafeBrowsing, dimungkinkan untuk mengidentifikasi situs yang berpotensi berbahaya atau terinfeksi: sekitar 10.000 (pada waktu yang berbeda, seseorang diperbaiki, seseorang tampaknya bangkrut, statistik tidak sepenuhnya objektif)
- Tentang HTTP dan HTTPS - kurang dari setengah situs volume yang ditemukan menggunakan yang terakhir, tetapi dengan mempertimbangkan fakta bahwa basis data saya tidak lengkap, tetapi hanya 40% dari jumlah total, sangat mungkin bahwa sebagian besar situs dari babak kedua dapat dan berkomunikasi melalui HTTPS .
Statistik firewall:
 Firewall - Nomor
Firewall - NomorModSecurity: 4354
Keamanan Aplikasi Web IBM: 126
Keamanan WP yang lebih baik: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Statistik Server Web
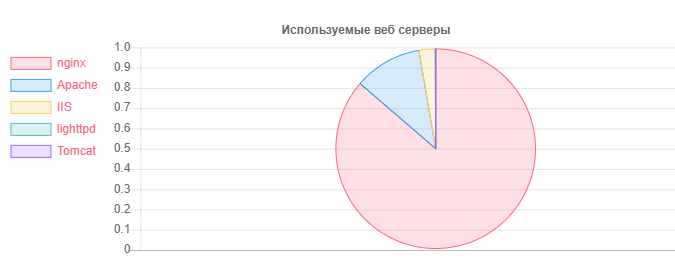 Server Web - Nomor
Server Web - NomorNginx: 31752
Apache: 4042
IIS: 959
Instalasi Nginx yang ketinggalan zaman dan berpotensi rentan: 20966
Instalasi Apache yang sudah usang dan berpotensi rentan: 995
Terlepas dari kenyataan bahwa hoster.by adalah pemimpin dalam domain dan hosting, misalnya, secara umum, Kontak Terbuka juga dibedakan, tetapi kebenarannya ada pada sejumlah situs pada satu IP:
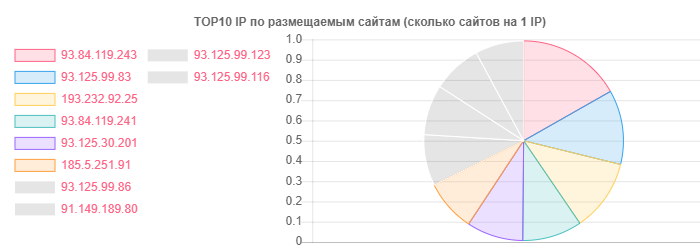 IP - Situs
IP - Situs93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
Melalui email, statistik terperinci benar-benar memutuskan untuk tidak ditarik, tidak disortir berdasarkan zona domain, melainkan, menarik untuk melihat lokasi pengguna ke vendor tertentu:
- Pada layanan TUT.BY: 38282
- Pada layanan Yandex (oleh | ru): 28127
- Pada layanan Gmail: 33452
- Terikat ke Facebook: 866
- Terikat ke Twitter: 652
- Ditampilkan dalam kebocoran menurut HIBP: 7844
- Kecerdasan pasif membantu mengidentifikasi lebih dari 13 ribu alamat email
Seperti yang Anda lihat, gambaran keseluruhan cukup positif, terutama penggunaan aktif nginx dari bagian penyedia hosting. Mungkin ini sebagian besar karena populer di kalangan pengguna biasa - tipe hosting bersama.
Dari kenyataan bahwa saya tidak benar-benar menyukainya - ada cukup banyak penyedia hosting dari tangan tengah yang telah melihat kesalahan seperti AXFR, menggunakan versi lama SSH dan Apache dan beberapa masalah kecil lainnya. Di sini, tentu saja, lebih banyak cahaya pada situasi dapat ditumpahkan oleh fase aktif, tetapi pada saat ini, berdasarkan undang-undang kami, tampaknya bagi saya itu tidak mungkin, dan saya tidak ingin mendaftar dalam barisan hama untuk hal-hal semacam itu.
Gambar email umumnya sangat cerah, jika Anda bisa menyebutnya begitu. Oh ya, di mana penyedia TUT.BY ditunjukkan - ini berarti menggunakan domain, karena Layanan ini bekerja atas dasar Yandex.
Kesimpulan
Sebagai kesimpulan, saya dapat mengatakan satu hal - bahkan dengan hasil yang tersedia, Anda dapat dengan cepat memahami bahwa ada banyak pekerjaan untuk spesialis yang terlibat dalam pembersihan situs dari virus, pengaturan WAF, dan mengkonfigurasi / menambahkan CMS yang berbeda.
Nah, serius, seperti pada dua artikel sebelumnya, kita melihat bahwa masalah ada pada tingkat yang sangat berbeda di semua segmen Internet dan negara, dan beberapa dari mereka bahkan datang dengan studi jarak jauh masalah ini, tanpa menggunakan metode ofensif, dll. e. menggunakan informasi yang tersedia untuk umum untuk mengumpulkan keterampilan khusus mana yang tidak diperlukan.