Tidak, well, tentu saja, saya tidak serius. Harus ada batas sejauh mana dimungkinkan untuk menyederhanakan subjek. Tetapi untuk tahap pertama, pemahaman tentang konsep-konsep dasar dan "entri" cepat ke dalam topik, mungkin diizinkan. Dan bagaimana menyebutkan materi ini dengan benar (opsi: "Pembelajaran mesin untuk boneka", "Analisis data dari popok", "Algoritma untuk yang terkecil"), kita akan membahas di bagian akhir.
Untuk bisnis. Dia menulis beberapa program aplikasi pada MS Excel untuk visualisasi dan visualisasi proses yang terjadi dalam metode pembelajaran mesin yang berbeda ketika menganalisis data. Melihat adalah percaya, pada akhirnya, menurut media budaya yang mengembangkan sebagian besar metode ini (dengan cara, tidak berarti semua. "Metode vektor dukungan" yang paling kuat, atau SVM, mesin vektor dukungan adalah penemuan rekan senegaranya Vladimir Vapnik, Institut Manajemen Moskow. Omong-omong, 1963! Sekarang dia, bagaimanapun, mengajar dan bekerja di AS).
Tiga file untuk ditinjau
1. K-means clustering
Tugas semacam ini berhubungan dengan "belajar tanpa guru", ketika kita perlu memecah data awal menjadi sejumlah kategori yang diketahui sebelumnya, tetapi kita tidak memiliki sejumlah "jawaban yang benar", kita harus mengekstraknya dari data itu sendiri. Masalah klasik mendasar dalam menemukan subspesies bunga iris (Ronald Fisher, 1936!), Yang dianggap sebagai tanda pertama dari bidang pengetahuan ini - bersifat seperti itu.
Metodenya cukup sederhana. Kami memiliki satu set objek yang direpresentasikan sebagai vektor (set angka N). Untuk iris, ini adalah set 4 angka yang mencirikan bunga: panjang dan lebar lobus perianth luar dan dalam, masing-masing (
Iris Fisher - Wikipedia ). Sebagai jarak, atau ukuran kedekatan antara objek, metrik Cartesian biasa dipilih.
Selanjutnya, pusat-pusat cluster dipilih secara sewenang-wenang (atau tidak sewenang-wenang, lihat di bawah), dan jarak dari setiap objek ke pusat-pusat cluster dihitung. Setiap objek dalam langkah iterasi ini ditandai sebagai milik pusat terdekat. Kemudian pusat dari masing-masing klaster dipindahkan ke rata-rata aritmatika dari koordinat anggota-anggotanya (dengan analogi dengan fisika juga disebut "pusat massa"), dan prosedur ini diulangi.
Proses konvergen cukup cepat. Dalam gambar dalam dua dimensi, terlihat seperti ini:
1. Distribusi acak awal poin di pesawat dan jumlah cluster

2. Menentukan pusat-pusat cluster dan menetapkan poin ke cluster mereka
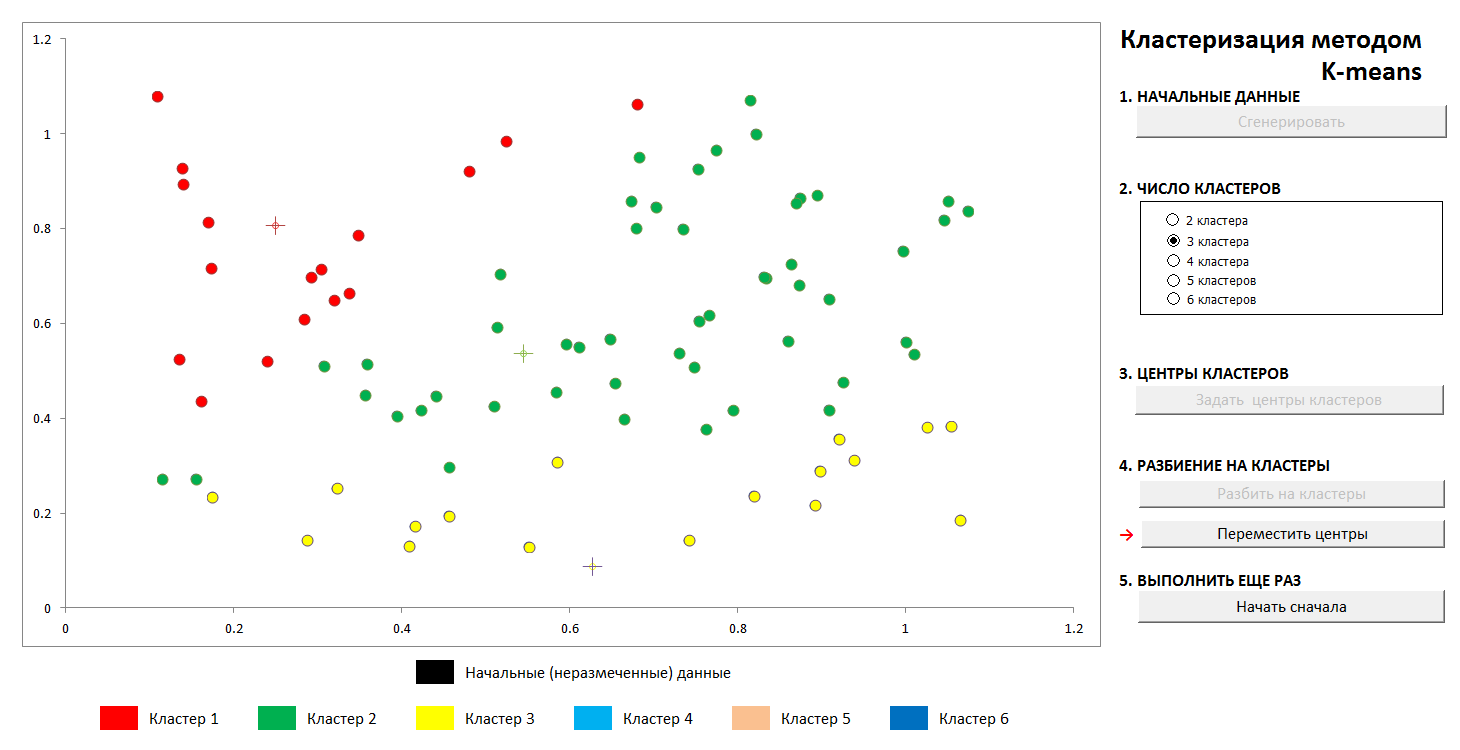
3. Transfer koordinat pusat cluster, perhitungan kembali poin, sampai pusat stabil. Lintasan pusat cluster ke posisi akhir terlihat.

Kapan saja, Anda dapat mengatur pusat cluster baru (tanpa menghasilkan distribusi poin baru!) Dan melihat bahwa proses partisi tidak selalu unik. Secara matematis, ini berarti bahwa untuk fungsi yang dioptimalkan (jumlah kuadrat jarak dari titik ke pusat klusternya) kami menemukan bukan global, tetapi minimum lokal. Masalah ini dapat dikalahkan baik dengan pilihan non-acak dari pusat-pusat awal cluster, atau dengan memilah-milah pusat-pusat yang mungkin (kadang-kadang menguntungkan untuk menempatkan mereka tepat di beberapa titik, maka setidaknya ada jaminan bahwa kami tidak akan mendapatkan cluster kosong). Bagaimanapun, himpunan terbatas selalu memiliki batas bawah yang tepat.
Anda dapat bermain dengan file ini di tautan ini (jangan lupa untuk mengaktifkan dukungan makro. File diperiksa untuk virus)
Deskripsi metode Wikipedia - metode
k-means2. Perkiraan oleh polinomial dan penguraian data. Pelatihan ulang
Seorang ilmuwan yang luar biasa dan popularizer ilmu data K.V. Vorontsov secara singkat berbicara tentang metode pembelajaran mesin sebagai "ilmu menggambar kurva melalui poin." Dalam contoh ini, kita akan menemukan pola dalam data dengan metode kuadrat terkecil.
Teknik membagi data sumber menjadi "pelatihan" dan "kontrol", serta fenomena seperti pelatihan ulang, atau "pelatihan ulang" untuk data ditampilkan. Dengan perkiraan yang benar, kami akan memiliki kesalahan tertentu pada data pelatihan dan kesalahan yang sedikit lebih besar pada data kontrol. Jika itu salah, itu adalah penyesuaian yang tepat untuk data pelatihan dan kesalahan besar pada kontrol.
(Ini adalah fakta yang diketahui bahwa melalui titik N dimungkinkan untuk menggambar kurva tunggal tingkat N-1, dan metode ini umumnya tidak memberikan hasil yang diinginkan.
Polinomial interpolasi Lagrange di Wikipedia )
1. Kami mengatur distribusi awal

2. Bagilah poin menjadi “pelatihan” dan “kontrol” dengan rasio 70 hingga 30.

3. Kami menggambar kurva perkiraan untuk poin pelatihan, kami melihat kesalahan yang diberikan pada data kontrol

4. Kami menggambar kurva yang tepat melalui titik-titik pelatihan, dan kami melihat kesalahan mengerikan pada data kontrol (dan nol pada pelatihan, tetapi apa gunanya?).

Tentu saja, varian paling sederhana dengan satu partisi ke dalam subset “training” dan “control” ditunjukkan, dalam kasus umum ini dilakukan berulang kali untuk penyesuaian koefisien yang terbaik.
File tersedia di sini, anti-virus diperiksa. Nyalakan makro untuk bekerja dengan benar
3. Dinamika keturunan dan kesalahan gradien
Akan ada kasus 4 dimensi dan regresi linier. Koefisien regresi linier akan ditentukan dalam langkah-langkah dengan metode gradient descent, awalnya semua koefisien adalah nol. Grafik terpisah menunjukkan dinamika reduksi kesalahan karena koefisien semakin lama semakin tersetel. Dimungkinkan untuk melihat keempat proyeksi 2 dimensi.
Jika Anda menetapkan langkah gradient descent terlalu besar, maka jelas bahwa setiap kali kami akan melewati minimum dan kami akan sampai pada hasil dalam jumlah langkah yang lebih besar, meskipun pada akhirnya kami akan tetap datang (kecuali jika kami terlalu banyak menyentuh langkah penurunan, maka algoritma akan berjalan “ dalam jarak "). Dan grafik ketergantungan kesalahan pada langkah iterasi tidak akan mulus, tetapi "tersentak".
1. Hasilkan data, atur langkah gradient descent
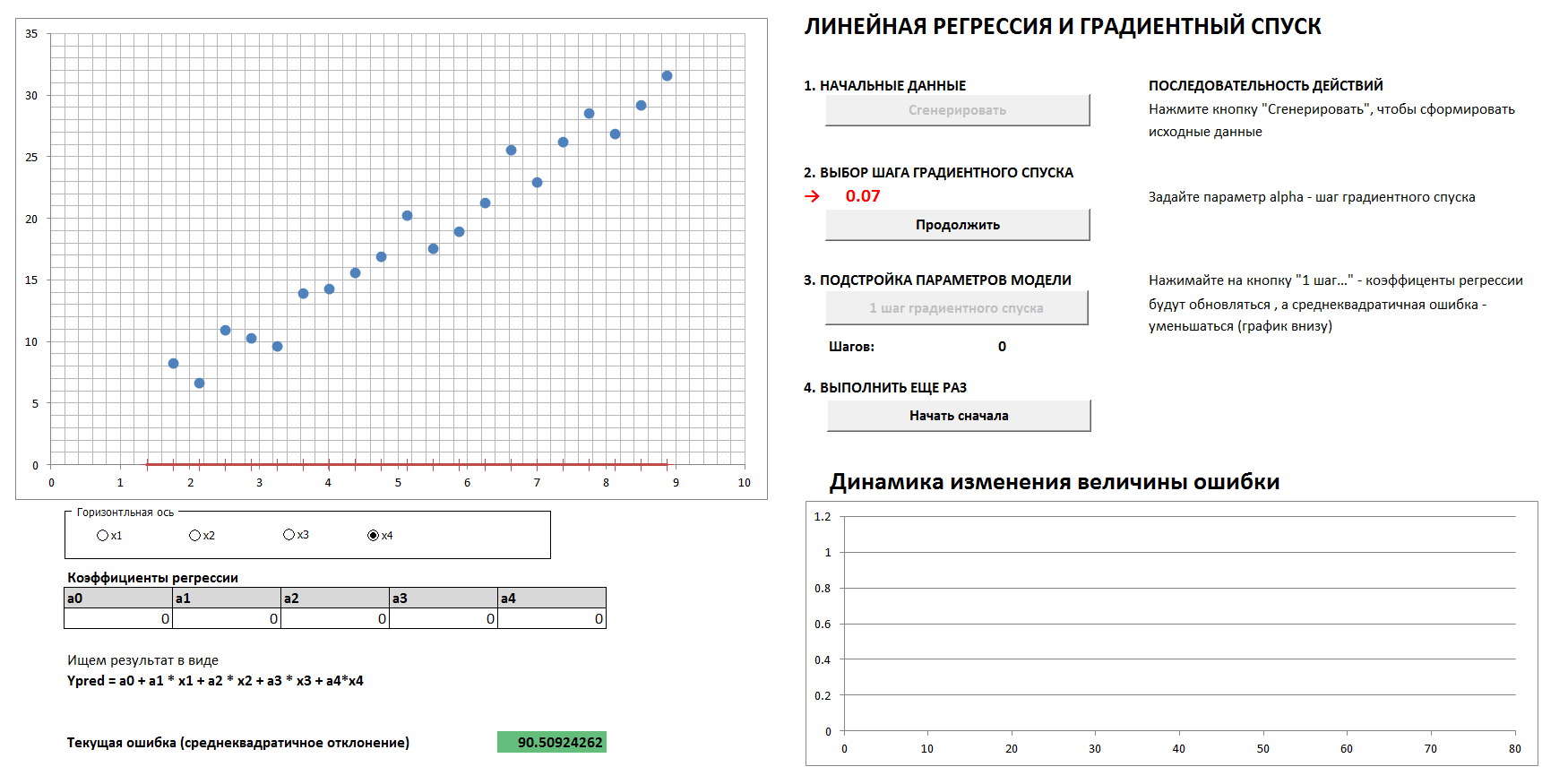
2. Dengan pilihan langkah gradient descent yang tepat, kami cukup lancar dan cepat

3. Jika langkah gradient descent tidak dipilih dengan benar, kami lewati maksimum, grafik kesalahannya adalah "jerky," konvergensi membutuhkan lebih banyak langkah

dan

4. Dengan pemilihan langkah gradient descent yang benar-benar salah, kami menjauh dari minimum

(Untuk mereproduksi proses dengan nilai-nilai langkah gradient descent yang ditunjukkan dalam gambar, centang kotak "data referensi").
File - dengan tautan ini, Anda harus mengaktifkan makro, tidak ada virus.Menurut komunitas yang disegani, apakah penyederhanaan dan metode presentasi seperti itu dapat diterima? Haruskah saya menerjemahkan artikel ke dalam bahasa Inggris?