 Diposting oleh Denis Tsyplakov , Solution Architect, DataArt
Diposting oleh Denis Tsyplakov , Solution Architect, DataArtPernyataan masalah
Salah satu masalah ketika membangun arsitektur layanan microser dan terutama ketika migrasi arsitektur monolitik ke layanan microser sering transaksi. Setiap layanan-mikro bertanggung jawab atas kelompok fungsinya sendiri, mungkin mengelola data yang terkait dengan grup ini, dan dapat melayani permintaan pengguna baik secara mandiri atau dengan mengirimkan permintaan ke layanan-layanan mikro lainnya. Semua ini berfungsi dengan baik sampai kita perlu memastikan konsistensi data yang dikendalikan oleh berbagai layanan microser.
Misalnya, aplikasi kita berfungsi di beberapa toko online besar. Di antara hal-hal lain, kami memiliki tiga area bisnis yang terpisah dan lemah yang saling terhubung:
- Gudang - apa, di mana, bagaimana, dan berapa lama disimpan, berapa banyak barang dari jenis tertentu saat ini dalam stok, dll.
- Mengirim barang - pengemasan, pengiriman, pelacakan pengiriman, analisis keluhan tentang keterlambatannya, dll.
- Mempertahankan bea cukai melaporkan pergerakan barang jika barang dikirim ke luar negeri (sebenarnya, saya tidak tahu jika dalam hal ini perlu untuk membuat sesuatu yang khusus, tetapi saya masih akan menghubungkan layanan negara dengan proses untuk menambahkan drama).
Masing-masing dari ketiga bidang ini mencakup banyak fungsi terpisah dan dapat direpresentasikan sebagai beberapa layanan mikro.
Ada satu masalah. Misalkan seseorang membeli suatu produk, mengemasnya dan mengirimkannya melalui kurir. Antara lain, kita perlu menunjukkan bahwa ada satu unit barang kurang di gudang, untuk mencatat bahwa proses pengiriman barang telah dimulai, dan jika barang dikirim, katakanlah, ke Cina, untuk mengurus surat-surat bea cukai. Jika aplikasi macet (misalnya, simpul macet) pada tahap kedua atau ketiga dari proses, data kami akan menjadi tidak konsisten, dan hanya beberapa kegagalan yang dapat menyebabkan masalah yang sangat tidak menyenangkan untuk bisnis (misalnya, kunjungan oleh petugas bea cukai).
Dalam arsitektur monolitik klasik jenis ini, masalahnya sederhana dan elegan diselesaikan dengan transaksi dalam database. Tetapi bagaimana jika kita menggunakan layanan microser? Sekalipun kami menggunakan satu basis data dari semua layanan (yang tidak terlalu elegan, tetapi dalam kasus kami dimungkinkan), bekerja dengan basis data ini berasal dari proses yang berbeda, dan kami tidak akan dapat memperluas transaksi antar proses.
Solusi
Masalahnya memiliki beberapa solusi:
- Anehnya, terkadang masalahnya bisa diabaikan. Jika kita tahu bahwa kegagalan tidak terjadi lebih dari sebulan sekali, dan penghapusan secara manual konsekuensi biaya uang yang dapat diterima untuk bisnis, Anda tidak dapat memperhatikan masalah, tidak peduli seberapa jeleknya kelihatannya. Saya tidak tahu apakah mungkin untuk mengabaikan klaim layanan pabean, tetapi dapat diasumsikan bahwa bahkan dalam keadaan tertentu hal ini dimungkinkan.
- Kompensasi (ini bukan tentang kompensasi moneter kepada bea cukai, misalnya, Anda membayar denda) adalah sekelompok berbagai jenis langkah yang memperumit urutan pemrosesan, tetapi memungkinkan Anda mendeteksi dan memproses proses yang gagal. Sebagai contoh, sebelum memulai operasi, kami menulis ke layanan khusus bahwa kami memulai operasi pengiriman, dan pada akhirnya kami menandai bahwa semuanya berakhir dengan baik. Kemudian kami memeriksa secara berkala untuk melihat apakah ada operasi yang tertunda, dan jika ada, melihat ketiga database, kami mencoba untuk membawa data ke kondisi yang konsisten. Ini adalah metode yang sepenuhnya berfungsi, tetapi secara signifikan mempersulit logika pemrosesan, dan melakukannya untuk setiap operasi cukup menyakitkan.
- Transaksi dua fase, secara jelas, spesifikasi XA +, yang memungkinkan Anda untuk membuat transaksi yang didistribusikan relatif terhadap aplikasi, adalah mekanisme yang sangat berat yang disukai beberapa orang dan, yang lebih penting, beberapa orang dapat mengonfigurasi. Selain itu, dengan layanan mikro yang ringan, secara ideologis lemah.
- Pada prinsipnya, transaksi adalah kasus khusus dari masalah konsensus, dan banyak sistem konsensus terdistribusi dapat digunakan untuk menyelesaikan masalah (secara kasar, segala sesuatu yang google dengan kata kunci paxos, rakit, zookeeper, dll, konsul). Tetapi dalam aplikasi praktis untuk data kegiatan gudang yang luas dan bercabang-cabang, semua ini tampak lebih rumit daripada transaksi dua fase.
- Antrian dan akhirnya konsistensi (konsistensi dalam jangka panjang) - kami membagi tugas menjadi tiga tugas asinkron, memproses data secara berurutan, meneruskannya di antara layanan dari antrian ke antrian, dan menggunakan mekanisme konfirmasi pengiriman. Dalam hal ini, kode ini tidak terlalu rumit, tetapi ada beberapa hal yang perlu diingat:
- Antrian menjamin pengiriman "satu kali atau lebih", yaitu, ketika mengirim kembali pesan yang sama, layanan harus menangani situasi ini dengan benar, dan tidak mengirimkan barang dua kali. Ini dapat dilakukan, misalnya, melalui UUID unik dari pesanan.
- Data pada waktu tertentu akan sedikit tidak konsisten. Artinya, barang pertama-tama akan menghilang dari gudang dan hanya kemudian, dengan sedikit penundaan, pesanan untuk pengirimannya akan dibuat. Nantinya, data bea cukai akan diproses. Dalam contoh kami, ini benar-benar normal dan tidak menimbulkan masalah bagi bisnis, tetapi ada kasus ketika perilaku data seperti itu bisa sangat tidak menyenangkan.
- Jika, sebagai hasilnya, layanan pertama harus mengembalikan beberapa data kepada pengguna, urutan panggilan yang pada akhirnya mengirimkan data ke browser pengguna bisa sangat tidak sepele. Masalah utama adalah bahwa browser mengirim permintaan secara sinkron dan biasanya mengharapkan respons sinkron. Jika Anda melakukan pemrosesan permintaan yang tidak sinkron, maka Anda perlu membangun pengiriman tanggapan yang tidak sinkron ke browser. Secara klasik, ini dilakukan baik melalui soket web, atau melalui permintaan berkala untuk acara baru dari browser ke server. Ada mekanisme, seperti SocksJS, misalnya, yang menyederhanakan beberapa aspek membangun tautan ini, tetapi masih akan ada kompleksitas tambahan.
Dalam kebanyakan kasus, opsi terakhir paling dapat diterima. Ini tidak terlalu menyulitkan permintaan pemrosesan, meskipun itu berfungsi beberapa kali lebih lama, tetapi, sebagai suatu peraturan, ini dapat diterima untuk operasi semacam ini. Ini juga memerlukan organisasi data yang sedikit lebih kompleks untuk memotong permintaan berulang, tetapi tidak ada yang super rumit tentang ini.
Secara skematis, salah satu opsi untuk memproses transaksi menggunakan antrian dan konsistensi akhirnya mungkin terlihat seperti ini:
- Pengguna melakukan pembelian, pesan tentang ini dikirim ke antrian (misalnya, cluster RabbitMQ atau, jika kami bekerja di Google Cloud Platform - Pub / Sub). Antriannya persisten, menjamin pengiriman satu kali atau lebih, dan bersifat transaksional, yaitu, jika layanan memproses pesan tiba-tiba turun, pesan tidak akan hilang, tetapi akan dikirim ke contoh layanan baru lagi.
- Pesan tiba ke layanan, yang menandai barang-barang di gudang sedang dipersiapkan untuk pengiriman dan pada gilirannya mengirimkan pesan "Barang-barang siap untuk pengiriman" ke antrian.
- Pada langkah berikutnya, layanan yang bertanggung jawab untuk pengiriman menerima pesan tentang kesiapan untuk pengiriman, membuat tugas pengiriman, dan kemudian mengirim pesan "pengiriman barang direncanakan".
- Layanan berikutnya, setelah menerima pesan bahwa pengiriman direncanakan, memulai proses administrasi untuk bea cukai.
Selain itu, setiap pesan yang diterima oleh layanan diperiksa keunikannya, dan jika pesan dengan UUID tersebut telah diproses, maka diabaikan.
Di sini, basis data pada setiap saat waktu dalam keadaan yang sedikit tidak konsisten, yaitu, barang-barang di gudang sudah ditandai sebagai sedang dalam proses pengiriman, tetapi tugas pengiriman itu sendiri belum ada di sana, itu akan muncul dalam satu atau dua detik. Tetapi pada saat yang sama, kami memiliki 99,999% (pada kenyataannya, jumlah ini sama dengan tingkat keandalan layanan antrian) menjamin bahwa tugas pengiriman akan muncul. Bagi sebagian besar bisnis, ini dapat diterima.
Tentang apakah artikel itu?
Dalam artikel ini saya ingin berbicara tentang cara lain untuk menyelesaikan masalah transaksionalitas dalam aplikasi layanan mikro. Terlepas dari kenyataan bahwa layanan microser bekerja paling baik ketika setiap layanan memiliki database sendiri, untuk sistem kecil dan menengah, semua data, sebagai suatu peraturan, mudah masuk ke dalam basis data relasional modern. Ini berlaku untuk hampir semua sistem perusahaan internal. Artinya, kita sering tidak memiliki kebutuhan ketat untuk berbagi data antara mesin fisik yang berbeda. Kami dapat menyimpan data dari layanan microser yang berbeda dalam kelompok tabel yang tidak terkait dari database yang sama. Ini sangat nyaman jika Anda membagi aplikasi lama, monolitik ke dalam layanan dan sudah membagi kodenya, tetapi datanya masih hidup dalam database yang sama. Namun, masalah pemisahan transaksi masih tetap ada - transaksi tersebut secara kaku terkait dengan koneksi jaringan dan, oleh karena itu, proses yang membuka koneksi ini, dan kami memiliki proses terpisah. Bagaimana menjadi
Di atas, saya menjelaskan beberapa cara umum untuk menyelesaikan masalah, tetapi lebih lanjut saya ingin menawarkan cara lain untuk kasus khusus, ketika semua data berada dalam database yang sama. Saya
tidak merekomendasikan mencoba menerapkan metode ini
dalam proyek ini , tetapi cukup menarik bagi saya
untuk mempresentasikannya dalam artikel. Nah, tiba-tiba itu akan berguna dalam beberapa kasus khusus.
Esensinya sangat sederhana. Transaksi dikaitkan dengan koneksi jaringan, dan database tidak benar-benar tahu siapa yang duduk di ujung koneksi jaringan terbuka itu. Dia tidak peduli, yang utama adalah bahwa perintah yang benar dikirim ke soket. Jelas bahwa biasanya sebuah soket secara eksklusif milik satu proses di sisi klien, tetapi saya melihat setidaknya tiga cara untuk mengatasi ini.
1. Ubah kode basis data
Pada level kode basis data untuk basis data, kode yang dapat kita ubah, membuat rakitan basis data kita sendiri, kita menerapkan mekanisme untuk mentransfer transaksi antar koneksi. Bagaimana cara kerjanya dari sudut pandang klien:
- Kami memulai transaksi, melakukan beberapa perubahan, sekarang saatnya untuk mentransfer transaksi ke layanan berikutnya.
- Kami memberi tahu DB untuk memberi kami UUID transaksi dan menunggu N detik. Jika selama waktu ini koneksi lain dengan UUID ini tidak datang, gulung balik transaksi, jika ya, transfer semua struktur data yang terkait dengan transaksi ke koneksi baru dan terus bekerja dengannya.
- Kami meneruskan UUID ke layanan berikutnya (mis., Ke proses lain, mungkin ke VM lain).
- Di dalamnya, buka koneksi dan berikan perintah DB - lanjutkan transaksi dengan UUID yang ditentukan.
- Kami terus bekerja dengan database sebagai bagian dari transaksi yang dimulai oleh proses lain.
Metode ini adalah yang paling ringan untuk digunakan, tetapi membutuhkan modifikasi dari kode database, pemrogram aplikasi biasanya tidak melakukan ini, itu memerlukan banyak keterampilan khusus. Kemungkinan besar, akan diperlukan untuk mentransfer data antara proses basis data, dan basis data, yang kodenya dapat kita ubah dengan aman pada umumnya, satu - PostgreSQL. Selain itu, ini hanya akan berfungsi untuk server yang tidak dikelola, Anda tidak akan menggunakannya di RDS atau Cloud SQL.
Secara skematis, tampilannya seperti ini:

2. Manipulasi soket
Hal kedua yang terlintas dalam pikiran adalah manipulasi koneksi database oleh soket. Kita dapat membuat "Reverse socket proxy", yang mengarahkan perintah yang datang dari beberapa klien ke port tertentu dalam satu aliran perintah ke database.
Pada kenyataannya, aplikasi ini sangat mirip dengan pgBuncer, hanya saja, selain fungsionalitas standarnya, melakukan beberapa manipulasi dengan aliran byte dari klien dan dapat menggantikan satu klien dengan yang lain pada perintah.
Saya sangat tidak menyukai metode ini, untuk implementasinya perlu untuk membersihkan paket-paket biner yang beredar antara server dan klien. Dan itu masih membutuhkan banyak pemrograman sistem. Saya membawanya hanya untuk kelengkapan.
3. Gateway JDBC
Kita dapat membuat driver gateway JDBC - kita mengambil driver JDBC standar untuk database tertentu, biarlah itu PostgreSQL. Kami membungkus kelas dan membuat antarmuka HTTP ke semua metode eksternal (bukan HTTP, tetapi perbedaannya kecil). Selanjutnya, kami membuat driver JDBC lain - fasad, yang mengalihkan semua panggilan metode ke gateway JDBC. Faktanya, kita menggergaji driver yang ada menjadi dua bagian dan menghubungkan bagian-bagian ini melalui jaringan. Kami mendapatkan diagram komponen berikut:
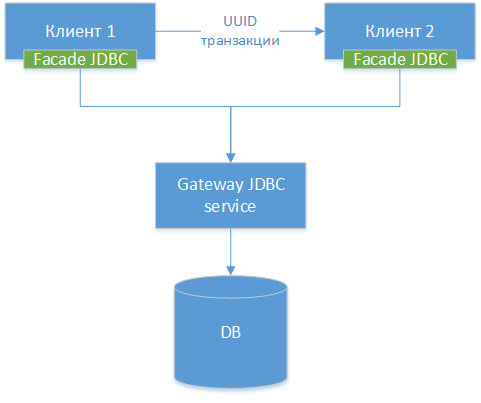 NB!: Seperti yang bisa kita lihat, ketiga opsi itu serupa, satu-satunya perbedaan adalah pada level apa kita mentransfer koneksi dan alat apa yang kita gunakan untuk ini.
NB!: Seperti yang bisa kita lihat, ketiga opsi itu serupa, satu-satunya perbedaan adalah pada level apa kita mentransfer koneksi dan alat apa yang kita gunakan untuk ini.
Setelah itu, kami mengajari pengemudi kami untuk melakukan trik yang pada dasarnya sama dengan transaksi UUID yang dijelaskan dalam metode 1.
Dalam kode aplikasi Java, menggunakan metode ini mungkin terlihat seperti ini.
Layanan A - mulai transaksi
Di bawah ini adalah kode untuk beberapa layanan yang memulai transaksi, membuat perubahan pada database dan meneruskannya ke layanan lain untuk menyelesaikannya. Dalam kode, kami menggunakan kerja langsung dengan kelas JDBC. Tentu saja, tidak ada yang melakukan ini pada 2019, tetapi demi kesederhanaan, kodenya disederhanakan.
Layanan B - penyelesaian transaksi
Interaksi dengan komponen dan kerangka kerja lainnya
Pertimbangkan kemungkinan efek samping dari solusi arsitektur semacam itu.
Kolam koneksi
Karena pada kenyataannya kita akan memiliki kumpulan koneksi nyata di dalam gerbang JDBC - lebih baik untuk mematikan kumpulan koneksi dalam layanan, karena mereka akan menangkap dan menahan koneksi di dalam layanan yang dapat digunakan oleh layanan lain.
Plus, setelah menerima UUID dan menunggu transfer ke proses lain, koneksi pada dasarnya menjadi tidak beroperasi, dan dari sudut pandang JDBC frontend, ia menutup secara otomatis, dan dari sudut pandang gateway JDBC, itu harus diadakan tanpa memberikan kepada siapa pun selain siapa akan datang dengan UUID yang diinginkan.
Dengan kata lain, manajemen ganda kumpulan koneksi di Gateway JDBC dan di dalam masing-masing layanan dapat menghasilkan kesalahan yang halus dan tidak menyenangkan.
Jpa
Dengan JPA, saya melihat dua kemungkinan masalah:
- Manajemen transaksi. Ketika melakukan JPA, mesin mungkin berpikir bahwa ia telah menyimpan semua data, sementara itu belum disimpan. Kemungkinan besar, manajemen transaksi manual dan flush () sebelum mentransfer transaksi harus menyelesaikan masalah.
- Cache tingkat kedua cenderung bekerja secara salah, tetapi dalam sistem terdistribusi penggunaannya terbatas dalam hal apa pun.
Transaksi musim semi
Mekanisme manajemen transaksi Spring, mungkin, tidak dapat diaktifkan, dan Anda harus mengelolanya secara manual. Saya hampir yakin bahwa itu dapat diperluas - misalnya, untuk menulis ruang lingkup kustom - tetapi untuk mengatakan dengan pasti, kita perlu mempelajari bagaimana ekstensi Transaksi Musim Semi diatur di sana, tetapi saya belum melihat ke sana.
Pro dan kontra
Pro
- Praktis tidak memerlukan modifikasi kode monolitik yang ada saat menggergaji.
- Anda dapat menulis transaksi lintas-server yang rumit tanpa kerumitan kode.
- Memungkinkan Anda melakukan penelusuran lintas-layanan dari transaksi.
- Solusinya cukup fleksibel, Anda dapat menggunakan transaksi klasik di mana distribusi tidak diperlukan dan berbagi transaksi hanya untuk operasi-operasi tersebut di mana interaksi lintas-layanan diperlukan.
- Tim proyek tidak diharuskan menguasai teknologi baru secara paksa. Teknologi baru, tentu saja, baik, tetapi tugas - sangat penting dan mendesak (hingga kemarin!) Untuk mengajarkan 20 pengembang konsep membangun sistem reaktif - bisa sangat tidak penting. Namun, tidak ada jaminan bahwa semua 20 orang akan menyelesaikan pelatihan tepat waktu.
Cons
- Tidak dapat dihemat dan, pada kenyataannya, non-modular pada tingkat basis data, berbeda dengan solusi yang antri. Anda masih memiliki satu basis data di mana semua kueri dan seluruh beban bertemu. Dalam hal ini, solusinya adalah jalan buntu: jika nanti Anda ingin menambah beban atau menjadikan solusi modular sesuai dengan data, Anda harus mengulang semuanya.
- Anda harus sangat berhati-hati dalam mentransfer transaksi antar proses, terutama proses yang ditulis dalam kerangka kerja. Sesi memiliki pengaturan sendiri, dan untuk berbagai kerangka kerja, perubahan tiba-tiba sehubungan dengan database dapat menyebabkan operasi yang salah. Lihat, misalnya, pengaturan sesi dan transaksi untuk PostgreSQL.
- Ketika saya memberi tahu gagasan itu dalam obrolan arsitek lokal kami di DataArt, hal pertama yang ditanyakan oleh rekan saya adalah apakah saya minum (tidak, tidak minum!) Tetapi saya akui bahwa idenya, katakanlah, bukan yang paling luas, dan jika Anda menerapkannya dalam proyek Anda, itu akan terlihat sangat tidak biasa bagi para peserta lainnya.
- Membutuhkan driver JDBC khusus. Menulis itu membutuhkan waktu, Anda harus men-debug-nya, mencari kesalahan di dalamnya, termasuk yang disebabkan oleh kesalahan komunikasi jaringan, dll.
Peringatan
Saya memperingatkan Anda sekali lagi:
jangan mencoba mengulangi trik ini di rumah dalam proyek ini, kecuali jika Anda memiliki penjelasan yang sangat jelas tentang mengapa Anda membutuhkannya, dan bukti meyakinkan bahwa tidak ada cara lain sama sekali.
Semua dari awal April!