Artikel ini diterbitkan atas nama John Akhaltsev , Jiga
Tinkoff.ru hari ini bukan hanya bank, ini adalah perusahaan IT. Ini tidak hanya menyediakan layanan perbankan, tetapi juga membangun ekosistem di sekitarnya.
Kami di Tinkoff.ru menjalin kemitraan dengan berbagai layanan untuk meningkatkan kualitas layanan pelanggan, dan membantu menjadi layanan yang lebih baik. Sebagai contoh, kami melakukan pengujian beban dan analisis kinerja salah satu layanan yang membantu menemukan kemacetan dalam sistem - termasuk Transparent Huge Pages di konfigurasi OS.
Jika Anda ingin tahu bagaimana melakukan analisis kinerja sistem dan apa yang terjadi dengan kami, selamat datang di cat.
Deskripsi masalah
Saat ini, arsitektur layanan adalah:
- Server web Nginx untuk menangani koneksi http
- Php-fpm untuk kontrol proses php
- Redis untuk caching
- PostgreSQL untuk penyimpanan data
- Solusi belanja lengkap
Masalah utama yang kami temukan selama penjualan berikutnya di bawah beban tinggi adalah pemanfaatan cpu yang tinggi, sementara waktu prosesor dalam mode kernel (waktu sistem) meningkat dan lebih lama daripada waktu dalam mode pengguna (waktu pengguna).
- Waktu Pengguna - waktu yang dihabiskan prosesor untuk tugas-tugas pengguna. Ini adalah hal utama yang Anda bayar saat membeli prosesor.
- Waktu sistem - jumlah waktu yang dihabiskan sistem pada paging, mengubah konteks, meluncurkan tugas terjadwal, dan tugas sistem lainnya.
Menentukan karakteristik utama sistem
Untuk mulai dengan, kami mengumpulkan sirkuit beban dengan sumber daya yang dekat dengan produktif, dan menyusun profil beban yang sesuai dengan beban normal pada hari-hari biasa.
Gatling versi 3 dipilih sebagai alat penembakan, dan penembakan itu sendiri dilakukan di dalam jaringan lokal melalui gitlab-runner. Lokasi agen dan target dalam jaringan lokal yang sama adalah karena berkurangnya biaya jaringan, jadi kami fokus untuk memeriksa pelaksanaan kode itu sendiri, dan bukan pada kinerja infrastruktur tempat sistem dikerahkan.
Saat menentukan karakteristik utama sistem, skenario dengan beban yang meningkat secara linear dengan konfigurasi http cocok:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
Pada tahap ini, kami menerapkan skrip untuk membuka halaman utama dan mengunduh semua sumber

Hasil tes ini menunjukkan kinerja maksimum 1500 rps, peningkatan lebih lanjut dalam intensitas beban menyebabkan degradasi sistem yang terkait dengan peningkatan waktu softirq.


Softirq adalah mekanisme interupsi tertunda dan dijelaskan dalam file kernel / softirq.s. Pada saat yang sama, mereka memalu antrian instruksi ke prosesor, mencegah mereka membuat perhitungan yang berguna dalam mode pengguna. Penanganan interupsi juga dapat menunda pekerjaan tambahan dengan paket jaringan di utas OS (waktu sistem). Secara singkat tentang pekerjaan tumpukan jaringan dan optimisasi dapat ditemukan di artikel terpisah .
Kecurigaan masalah utama tidak dikonfirmasi, karena ada waktu sistem yang lebih lama pada produk dengan aktivitas jaringan yang lebih sedikit.
Skrip pengguna
Langkah selanjutnya adalah mengembangkan skrip khusus dan menambahkan sesuatu lebih dari sekadar membuka halaman dengan gambar. Profil ini mencakup operasi berat, yang sepenuhnya melibatkan kode situs dan database, dan bukan server web yang memberikan sumber daya statis.
Pengujian dengan beban stabil diluncurkan pada intensitas yang lebih rendah dari maksimum, transisi pengalihan ditambahkan ke konfigurasi:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
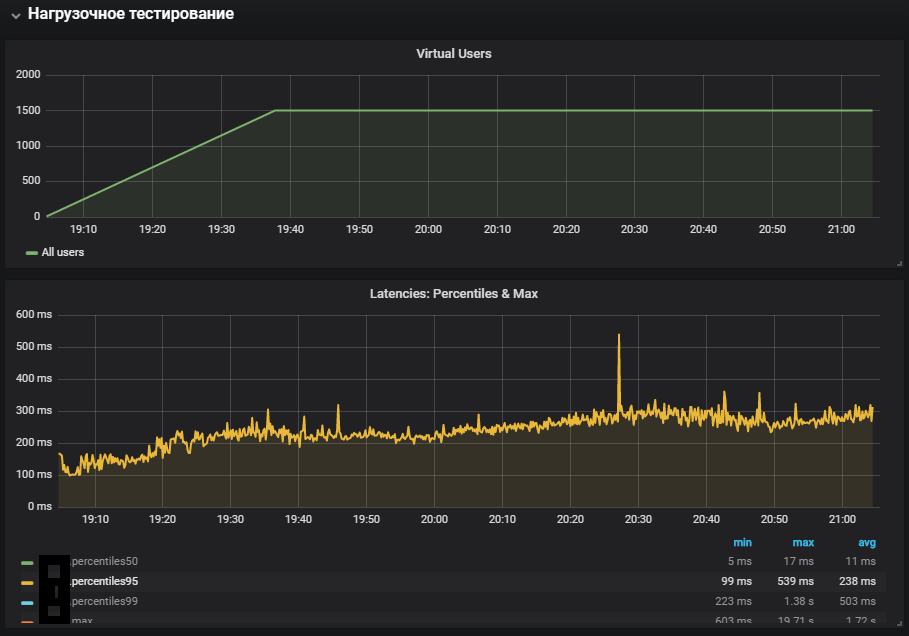

Penggunaan sistem yang paling lengkap menunjukkan peningkatan dalam metrik waktu sistem, serta pertumbuhannya selama uji stabilitas. Masalah dengan lingkungan produksi direproduksi.
Jaringan dengan Redis
Ketika menganalisis masalah, sangat penting untuk memiliki pemantauan semua komponen sistem untuk memahami cara kerjanya dan apa dampak dari beban yang diberikan terhadapnya.
Dengan dimulainya pemantauan Redis, menjadi mungkin untuk melihat bukan pada metrik umum sistem, tetapi pada komponen spesifiknya. Skenario untuk pengujian stres juga diubah, yang, bersama dengan pemantauan tambahan, membantu mendekati lokalisasi masalah.

Dalam pemantauan, Redis melihat gambar yang mirip dengan pemanfaatan cpu, atau lebih tepatnya, waktu sistem secara signifikan lebih lama dari waktu pengguna, sedangkan pemanfaatan utama cpu adalah dalam operasi SET, yaitu alokasi RAM untuk menyimpan nilai.

Untuk menghilangkan efek interaksi jaringan dengan Redis, diputuskan untuk menguji hipotesis dan beralih Redis ke soket UNIX bukan soket tcp. Ini dilakukan tepat dalam kerangka kerja melalui mana php-fpm terhubung ke database. Dalam file /yiisoft/yii/framework/caching/CRedisCache.php, kami mengganti baris dari host: port dengan hardis redis.sock. Baca lebih lanjut tentang kinerja soket di artikel .
protected function connect() { $this->_socket=@stream_socket_client(
Sayangnya, ini tidak berpengaruh banyak. Pemanfaatan CPU sedikit stabil, tetapi tidak memecahkan masalah kami - sebagian besar pemanfaatan CPU adalah dalam mode kernel.
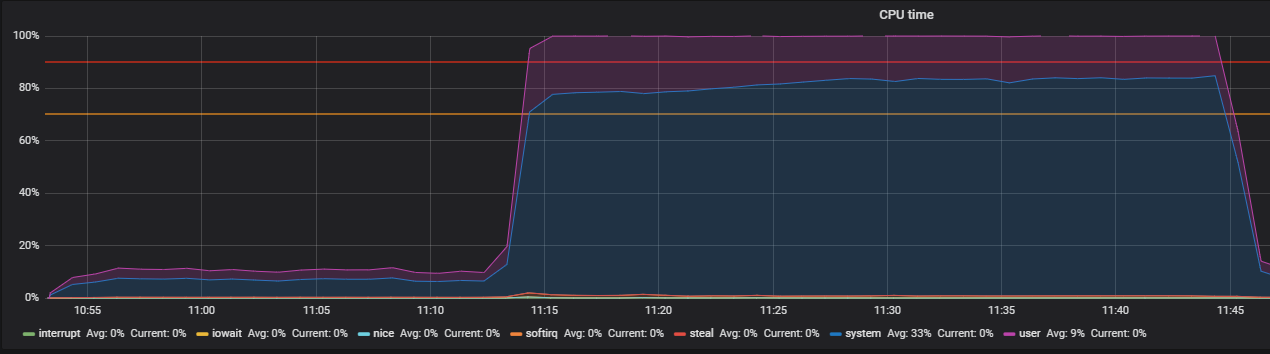
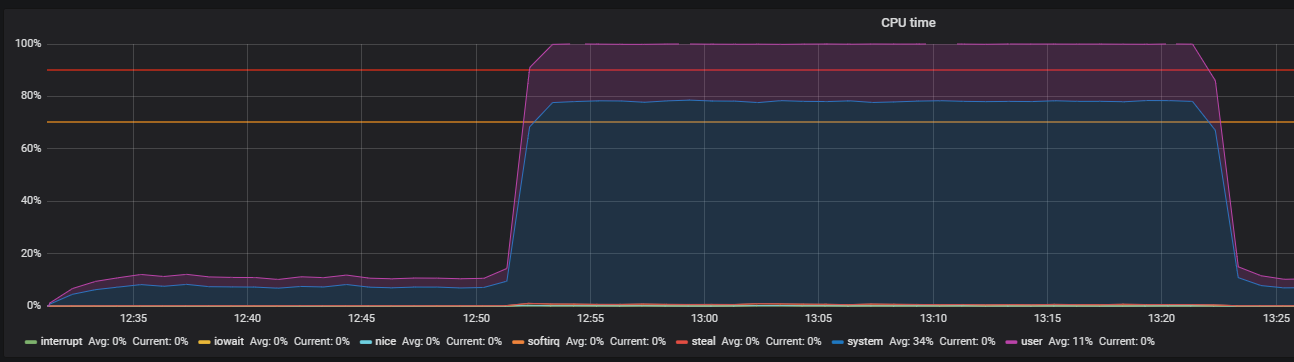
Benchmark menggunakan stres dan mengidentifikasi masalah THP
Utilitas stres membantu melokalisasi masalah - generator beban kerja sederhana untuk sistem POSIX, yang dapat memuat komponen sistem individual, misalnya, CPU, Memori, IO.
Pengujian seharusnya dilakukan pada versi perangkat keras dan OS:
Ubuntu 18.04.1 LTS
12 Intel® Xeon® CPU
Utilitas diinstal menggunakan perintah:
sudo apt-get install stress
Kami melihat bagaimana CPU digunakan di bawah beban, menjalankan tes yang menciptakan pekerja untuk menghitung akar kuadrat dengan durasi 300 detik:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
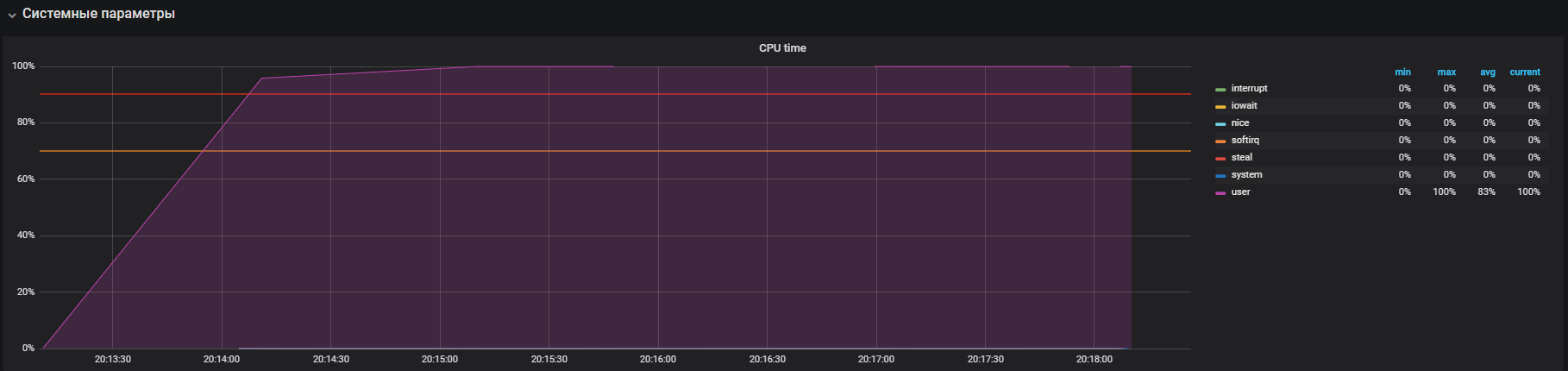
Grafik menunjukkan pemanfaatan lengkap dalam mode pengguna - ini berarti bahwa semua inti prosesor dimuat dan perhitungan yang bermanfaat dilakukan, bukan panggilan layanan sistem.
Langkah selanjutnya adalah menggunakan sumber daya saat bekerja secara intensif dengan io. Jalankan tes selama 300 detik dengan penciptaan 12 pekerja yang menjalankan sinkronisasi (). Perintah sinkronisasi menulis data yang disangga dalam memori ke disk. Kernel menyimpan data dalam memori untuk menghindari operasi baca dan tulis disk yang sering (biasanya lambat). Perintah sync () memastikan bahwa semua yang tersimpan dalam memori ditulis ke disk.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

Kami melihat bahwa prosesor ini terutama terlibat dalam pemrosesan panggilan dalam mode kernel dan sedikit di iowait, Anda juga dapat melihat> 35k ops menulis ke disk. Perilaku ini mirip dengan masalah dengan waktu sistem tinggi, penyebab yang kami analisis. Tapi di sini ada beberapa perbedaan: ini adalah iowait dan iops lebih besar dari pada sirkuit produktif, masing-masing, ini tidak sesuai dengan kasus kami.
Saatnya memeriksa memori Anda. Kami meluncurkan 20 pekerja yang akan mengalokasikan dan membebaskan memori selama 300 detik menggunakan perintah:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
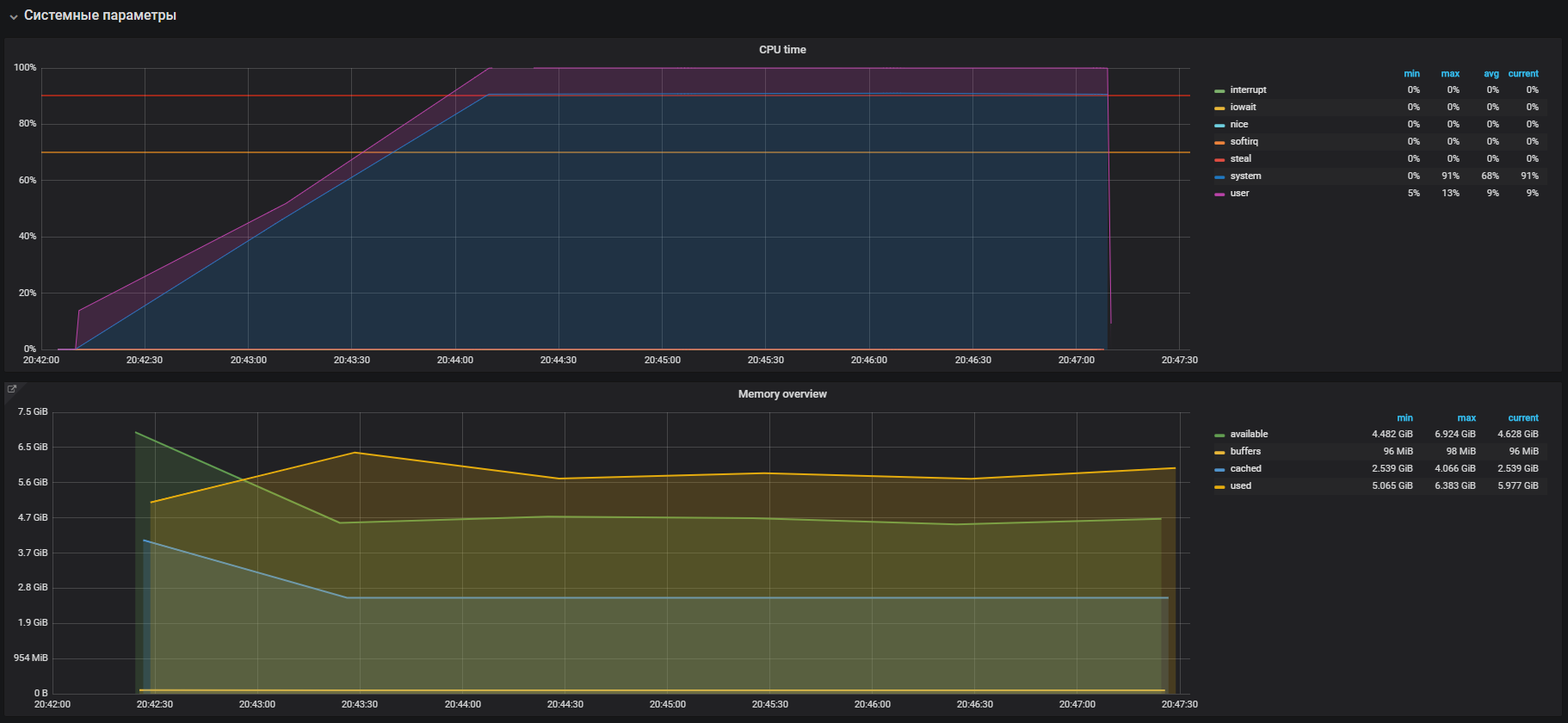
Segera kita melihat pemanfaatan CPU yang tinggi dalam mode sistem dan sedikit dalam mode pengguna, serta penggunaan RAM lebih dari 2 GB.
Kasing ini sangat mirip dengan masalah dengan prod, yang dikonfirmasi oleh penggunaan besar memori pada tes beban. Karena itu, masalah harus dicari dalam operasi memori. Alokasi dan pembebasan memori masing-masing terjadi dengan bantuan malloc dan panggilan gratis, yang pada akhirnya akan diproses oleh panggilan sistem kernel, yang berarti bahwa mereka akan ditampilkan dalam pemanfaatan CPU sebagai waktu sistem.
Di sebagian besar sistem operasi modern, memori virtual diatur menggunakan paging, dengan pendekatan ini, seluruh area memori dibagi menjadi beberapa halaman dengan panjang tetap, misalnya 4096 byte (default untuk banyak platform), dan ketika mengalokasikan, misalnya memori 2 GB, manajer memori harus beroperasi lebih dari 500.000 halaman. Dalam pendekatan ini, ada overhead manajemen besar dan halaman Huge dan teknologi Transparent Huge Pages diciptakan untuk menguranginya, dengan bantuan mereka Anda dapat meningkatkan ukuran halaman, misalnya menjadi 2MB, yang secara signifikan akan mengurangi jumlah halaman dalam tumpukan memori. Perbedaan teknologi hanya untuk halaman Huge kita harus secara eksplisit mengatur lingkungan dan mengajarkan program cara bekerja dengannya, sementara Transparent Huge Pages bekerja "secara transparan" untuk program.
THP dan pemecahan masalah
Jika Anda mencari informasi tentang Halaman Besar Transparan, Anda dapat melihat banyak hasil di halaman pencarian dengan pertanyaan "Cara mematikan THP".
Ternyata, fitur "keren" ini diperkenalkan oleh perusahaan Red Hat ke dalam kernel Linux, inti dari fitur ini adalah aplikasi dapat bekerja secara transparan dengan memori, seolah-olah mereka bekerja dengan Huge Page nyata. Menurut tolok ukur, THP mempercepat aplikasi abstrak sebesar 10%, Anda dapat melihat lebih banyak detail dalam presentasi, tetapi pada kenyataannya semuanya berbeda. Dalam beberapa kasus, THP menyebabkan peningkatan konsumsi CPU yang tidak masuk akal dalam sistem. Untuk informasi lebih lanjut, lihat rekomendasi Oracle.
Kami pergi dan memeriksa parameter kami. Ternyata, THP dihidupkan secara default, kami mematikannya dengan perintah:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Kami mengonfirmasi dengan tes sebelum mematikan THP dan setelahnya, pada profil beban:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

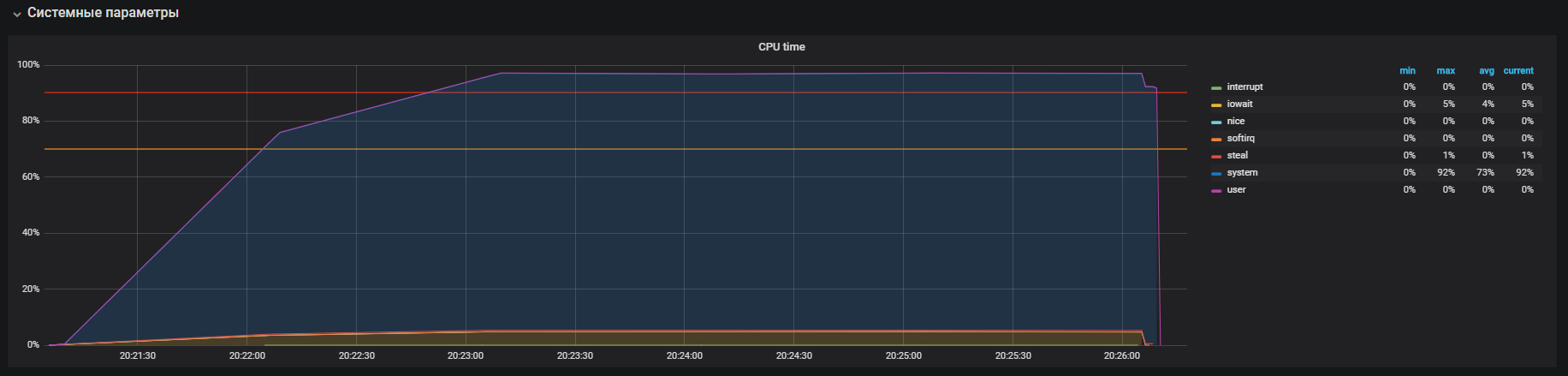
Kami menyaksikan gambar ini sebelum mematikan THP

Setelah mematikan THP, kita dapat mengamati pemanfaatan sumber daya yang sudah berkurang.
Masalah utama terlokalisasi. Alasannya diaktifkan secara default di OS
mekanisme halaman besar transparan. Setelah menonaktifkan opsi THP, pemanfaatan cpu dalam mode sistem berkurang setidaknya 2 kali, yang membebaskan sumber daya untuk mode pengguna. Selama analisis masalah utama, "kemacetan" interaksi dengan tumpukan jaringan OS dan Redis juga ditemukan, yang merupakan alasan untuk penelitian yang lebih dalam. Tetapi ini adalah kisah yang sangat berbeda.
Kesimpulan
Sebagai kesimpulan, saya ingin memberikan beberapa kiat agar berhasil mencari masalah kinerja:
- Sebelum meneliti kinerja sistem, pahami arsitekturnya dan interaksi komponennya dengan cermat.
- Konfigurasikan pemantauan untuk semua komponen sistem dan lacak, jika tidak ada cukup metrik standar, masuk lebih dalam dan perluas.
- Baca manual tentang sistem yang digunakan.
- Periksa pengaturan default di file konfigurasi OS dan komponen sistem.