Pengumuman
Kolega, di tengah musim panas saya berencana untuk merilis seri artikel lain tentang desain sistem antrian: "Percobaan VTrade" - upaya untuk menulis kerangka kerja untuk sistem perdagangan. Siklus akan menganalisis teori dan praktik membangun pertukaran, pelelangan, dan penyimpanan. Di akhir artikel, saya mengusulkan memilih topik yang paling menarik bagi Anda.

Ini adalah artikel terakhir dalam siklus aplikasi reaktif terdistribusi Erlang / Elixir. Pada artikel pertama, Anda dapat menemukan fondasi teoritis arsitektur reaktif. Artikel kedua menggambarkan pola dan mekanisme dasar untuk membangun sistem seperti itu.
Hari ini kita akan mengangkat masalah pengembangan basis kode dan proyek secara umum.
Organisasi Layanan
Dalam kehidupan nyata, ketika mengembangkan layanan, Anda sering harus menggabungkan beberapa pola interaksi dalam satu pengontrol. Misalnya, layanan pengguna, yang menyelesaikan tugas-tugas mengelola profil pengguna untuk suatu proyek, harus menanggapi permintaan permintaan dan melaporkan pembaruan profil melalui pub-sub. Kasus ini cukup sederhana: di belakang pesan ada satu pengontrol yang mengimplementasikan logika layanan dan menerbitkan pembaruan.
Situasi menjadi rumit ketika kita perlu mengimplementasikan layanan terdistribusi yang toleran terhadap kesalahan. Misalkan persyaratan pengguna telah berubah:
- sekarang layanan harus memproses permintaan pada 5 node cluster,
- dapat melakukan tugas pemrosesan latar belakang,
- dan dapat secara dinamis mengelola daftar berlangganan pembaruan profil Anda.
Catatan: Kami tidak mempertimbangkan masalah penyimpanan yang konsisten dan replikasi data. Misalkan masalah ini telah diselesaikan sebelumnya dan sistem sudah memiliki lapisan penyimpanan yang andal dan dapat diskalakan, dan penangan memiliki mekanisme untuk berinteraksi dengannya.
Deskripsi formal layanan pengguna menjadi lebih rumit. Dari sudut pandang programmer, menggunakan perubahan pesan sangat minim. Untuk memenuhi persyaratan pertama, kita perlu menyesuaikan keseimbangan pada titik pertukaran req-resp.
Persyaratan untuk menangani tugas latar belakang sering muncul. Dalam pengguna, ini dapat memeriksa dokumen pengguna, memproses multimedia yang diunduh, atau menyinkronkan data dengan layanan sosial. jaringan. Tugas-tugas ini perlu didistribusikan entah bagaimana di dalam cluster dan mengendalikan kemajuan. Oleh karena itu, kami memiliki dua solusi: baik menggunakan templat distribusi tugas dari artikel sebelumnya, atau, jika tidak cocok, tulis penjadwal tugas khusus yang akan diperlukan bagi kami untuk mengelola kumpulan penangan.
Butir 3 membutuhkan ekstensi untuk templat pub-sub. Dan untuk implementasi, setelah membuat titik pertukaran pub-sub, kita perlu meluncurkan pengendali titik ini sebagai bagian dari layanan kami. Jadi, kami tampaknya mengambil logika pemrosesan berlangganan dan berhenti berlangganan dari lapisan pesan ke dalam implementasi pengguna.
Akibatnya, dekomposisi tugas menunjukkan bahwa untuk memenuhi persyaratan, kita perlu menjalankan 5 instance layanan pada node yang berbeda dan membuat entitas tambahan - pengendali pub-sub yang bertanggung jawab untuk berlangganan.
Untuk menjalankan 5 penangan, Anda tidak perlu mengubah kode layanan. Satu-satunya tindakan tambahan adalah mengatur aturan keseimbangan di titik pertukaran, yang akan kita bicarakan sedikit kemudian.
Ada juga kompleksitas tambahan: pengendali pub-sub dan penjadwal tugas khusus harus berfungsi dalam satu salinan. Sekali lagi, layanan pesan, sebagai hal mendasar, harus menyediakan mekanisme untuk memilih pemimpin.
Pilihan Pemimpin
Dalam sistem terdistribusi, pilihan pemimpin adalah prosedur untuk menunjuk satu-satunya proses yang bertanggung jawab untuk merencanakan pemrosesan terdistribusi dari suatu beban.
Dalam sistem yang tidak rentan terhadap sentralisasi, algoritma konsensus universal, seperti paxos atau rakit, digunakan.
Karena olahpesan adalah broker dan elemen utama, dia tahu tentang semua pengontrol layanan - kandidat untuk kepemimpinan. Pesan dapat menunjuk seorang pemimpin tanpa suara.
Setelah memulai dan menghubungkan ke titik pertukaran, semua layanan menerima pesan sistem #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . Jika LeaderPid cocok dengan pid proses saat ini, ditetapkan sebagai pemimpin, dan daftar Servers mencakup semua node dan parameternya.
Ketika node cluster baru muncul dan terputus, semua pengontrol layanan menerima #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} dan #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} masing-masing.
Dengan demikian, semua komponen menyadari semua perubahan, dan dalam cluster pada waktu tertentu satu pemimpin dijamin.
Perantara
Untuk implementasi proses pemrosesan terdistribusi yang kompleks, serta dalam optimalisasi arsitektur yang ada, akan lebih mudah untuk menggunakan perantara.
Agar tidak mengubah kode layanan dan menyelesaikan, misalnya, tugas pemrosesan tambahan, perutean, atau pendataan pesan, Anda dapat mengaktifkan prosesor proksi sebelum layanan, yang akan melakukan semua pekerjaan tambahan.
Contoh klasik optimasi pub-sub adalah aplikasi terdistribusi dengan kernel bisnis yang menghasilkan peristiwa pembaruan, misalnya, perubahan harga pasar, dan lapisan akses - N server yang menyediakan API liontin web untuk klien web.
Jika Anda memutuskan "dahi", maka layanan pelanggan adalah sebagai berikut:
- klien membangun koneksi dengan platform. Di sisi server, mengakhiri lalu lintas, proses melayani koneksi ini dimulai.
- Dalam konteks proses layanan, otorisasi dan berlangganan pembaruan terjadi. Proses memanggil metode berlangganan untuk topik.
- setelah event dihasilkan dalam kernel, ia dikirim ke proses yang melayani koneksi.
Bayangkan kita memiliki 50.000 pelanggan untuk topik "berita". Pelanggan didistribusikan secara merata di 5 server. Akibatnya, setiap pembaruan, yang tiba di titik pertukaran, akan direplikasi 50.000 kali: 10.000 kali untuk setiap server, sesuai dengan jumlah pelanggan di dalamnya. Skema yang tidak efektif, bukan?
Untuk memperbaiki situasi, kami memperkenalkan proxy yang memiliki nama yang sama dengan titik pertukaran. Pencatat nama global harus dapat mengembalikan proses terdekat dengan nama, ini penting.
Jalankan proxy ini di server lapisan akses, dan semua proses kami yang melayani api websocket akan berlangganan, dan bukan ke titik pertukaran pub-sub asli di kernel. Proxy hanya berlangganan kernel jika ada langganan unik dan mereplikasi pesan yang masuk ke semua pelanggannya.
Akibatnya, 5 pesan akan dikirim antara kernel dan server akses, bukan 50.000.
Routing dan balancing
Req-resp
Dalam implementasi perpesanan saat ini, ada 7 strategi distribusi permintaan:
default . Permintaan diteruskan ke semua pengontrol.round-robin . Iterate melalui dan mendistribusikan permintaan antara pengontrol secara siklus.consensus . Kontroler yang melayani layanan dibagi menjadi pemimpin dan pengikut. Permintaan hanya diteruskan ke pemimpin.consensus & round-robin . Ada pemimpin dalam grup, tetapi permintaan didistribusikan di antara semua anggota.sticky . Fungsi hash dihitung dan ditugaskan ke penangan tertentu. Permintaan selanjutnya dengan tanda tangan ini pergi ke penangan yang sama.sticky-fun . Ketika titik pertukaran diinisialisasi, fungsi perhitungan hash untuk sticky balancing juga ditransfer.fun . Ini mirip dengan sticky-fun, hanya di samping itu Anda dapat mengarahkan, menolak atau memprosesnya.
Strategi distribusi ditetapkan ketika titik pertukaran diinisialisasi.
Selain menyeimbangkan pesan, Anda dapat menandai entitas. Pertimbangkan jenis-jenis tag dalam sistem:
- Tag koneksi. Memungkinkan Anda untuk memahami melalui koneksi mana peristiwa itu terjadi. Digunakan saat proses pengontrol terhubung ke titik pertukaran yang sama, tetapi dengan kunci perutean yang berbeda.
- Tag layanan. Mengizinkan layanan tunggal untuk mengelompokkan prosesor dan memperluas kemampuan perutean dan penyeimbangan. Untuk pola req-resp, routing bersifat linier. Kami mengirim permintaan ke titik pertukaran, lalu mengirimkannya ke layanan. Tetapi jika kita perlu membagi penangan menjadi kelompok logis, maka pemisahan dilakukan menggunakan tag. Saat menentukan tag, permintaan akan diarahkan ke grup pengontrol tertentu.
- Tag permintaan. Memungkinkan untuk membedakan jawaban. Karena sistem kami tidak sinkron, untuk memproses respons layanan, Anda harus dapat menentukan RequestTag saat mengirim permintaan. Dari situ kita bisa memahami jawaban yang datang kepada kita.
Sub pub
Untuk pub-sub, segalanya sedikit lebih mudah. Kami memiliki titik pertukaran pesan yang diterbitkan. Titik pertukaran mendistribusikan pesan antara pelanggan yang berlangganan kunci perutean yang mereka butuhkan (kita dapat mengatakan bahwa ini analog dengan yang ada)
Skalabilitas dan ketahanan
Skalabilitas sistem secara keseluruhan tergantung pada tingkat skalabilitas lapisan dan komponen sistem:
- Layanan diskalakan dengan menambahkan node tambahan ke cluster dengan penangan untuk layanan ini. Selama operasi uji coba, Anda dapat memilih kebijakan keseimbangan optimal.
- Layanan olahpesan itu sendiri, dalam satu kluster, umumnya ditingkatkan baik dengan memindahkan titik pertukaran yang dimuat secara khusus ke masing-masing node klaster, atau dengan menambahkan proses proxy ke zona kluster yang dimuat secara khusus.
- Skalabilitas seluruh sistem sebagai karakteristik tergantung pada fleksibilitas arsitektur dan kemungkinan menggabungkan masing-masing kelompok ke dalam entitas logis umum.
Kesederhanaan dan kecepatan penskalaan sering menentukan keberhasilan suatu proyek. Perpesanan dalam kinerjanya saat ini tumbuh bersama aplikasi. Bahkan jika kita kekurangan sekelompok 50-60 mobil, kita dapat menggunakan federasi. Sayangnya, topik federasi berada di luar cakupan artikel ini.
Reservasi
Dalam analisis penyeimbangan beban, kami telah membahas reservasi pengontrol layanan. Namun, pesan juga harus disediakan. Jika terjadi kerusakan pada simpul atau mesin, pengiriman pesan akan otomatis pulih, dan sesegera mungkin.
Dalam proyek saya, saya menggunakan node tambahan yang mengambil beban jika jatuh. Erlang memiliki implementasi mode terdistribusi standar untuk aplikasi OTP. Mode terdistribusi, pada kenyataannya, melakukan pemulihan jika terjadi kegagalan dengan meluncurkan aplikasi yang macet pada node lain yang sebelumnya diluncurkan. Prosesnya transparan, setelah kegagalan, aplikasi bergerak secara otomatis ke node failover. Anda dapat membaca lebih lanjut tentang fungsi ini di sini .
Performa
Mari kita coba setidaknya untuk membandingkan kinerja rabbitmq dan pesan khusus kami.
Saya menemukan hasil tes rabbitmq resmi dari tim openstack.
Dalam klausa 6.14.1.2.1.2.2. Dokumen asli menyajikan hasil RPC CAST:
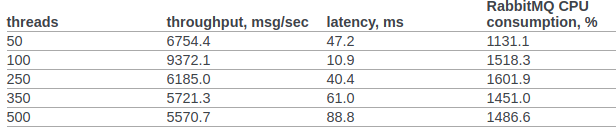
Sebelumnya, kami tidak akan membuat pengaturan tambahan untuk kernel OS atau VM erlang. Kondisi pengujian:
- erl opts: + A1 + sbtu.
- Tes dalam satu node erlang berjalan pada laptop dengan i7 lama dalam kinerja seluler.
- Tes cluster dilakukan pada server dengan jaringan 10G.
- Kode ini berfungsi dalam wadah buruh pelabuhan. Jaringan dalam mode NAT.
Kode Tes:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
Skenario 1: Tes dijalankan pada laptop dengan eksekusi ponsel i7 lama. Tes, olahpesan dan layanan dijalankan pada satu simpul dalam satu wadah buruh pelabuhan:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
Skenario 2 : 3 node berjalan pada mesin yang berbeda di bawah docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
Dalam semua kasus, pemanfaatan CPU tidak melebihi 250%
Ringkasan
Saya berharap siklus ini tidak terlihat seperti tumpukan kesadaran dan pengalaman saya akan membawa manfaat nyata bagi para peneliti sistem terdistribusi dan bagi para praktisi yang berada di awal jalur membangun arsitektur terdistribusi untuk sistem bisnis mereka dan yang memandang Erlang / Elixir dengan penuh minat, tetapi ragu apakah itu layak ...
Foto oleh @chuttersnap