Halo teman-teman. Pada akhir April, kami meluncurkan kursus baru
"Keamanan Sistem Informasi" . Dan sekarang kami ingin membagikan terjemahan artikel kepada Anda, yang tentunya akan sangat berguna untuk kursus ini. Artikel asli dapat
ditemukan di sini .
Artikel ini menjelaskan fondasi kunci, mereka umum untuk semua mesin JavaScript, dan bukan hanya untuk
V8 , yang sedang dikerjakan oleh penulis mesin (
Benedict dan
Matias ). Sebagai pengembang JavaScript, saya dapat mengatakan bahwa pemahaman yang lebih dalam tentang cara kerja mesin JavaScript akan membantu Anda mengetahui cara menulis kode yang efisien.

Catatan : jika Anda lebih suka menonton presentasi daripada membaca artikel, maka tonton video ini. Jika tidak, lewatkan saja dan baca terus.
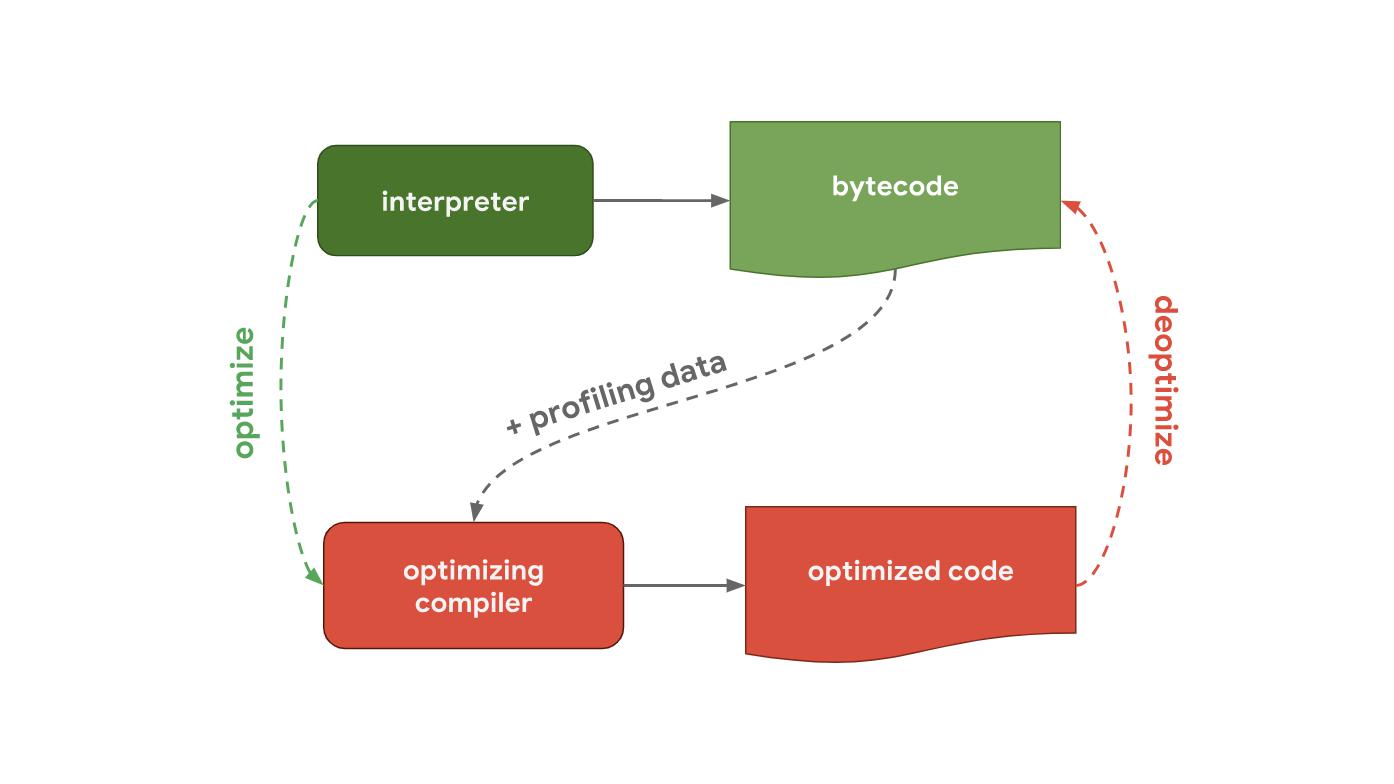
Mesin pipeline (pipa) JavaScriptSemuanya dimulai dengan fakta bahwa Anda menulis kode JavaScript. Setelah itu, mesin JavaScript memproses kode sumber dan menyajikannya sebagai pohon sintaksis abstrak (AST). Berdasarkan AST yang dibangun, juru bahasa akhirnya bisa mulai bekerja dan mulai membuat bytecode. Hebat! Ini adalah saat mesin mengeksekusi kode JavaScript.

Untuk membuatnya berjalan lebih cepat, Anda dapat mengirim bytecode ke kompiler yang mengoptimalkan bersama dengan profiling data. Kompilator pengoptimalisasi membuat asumsi tertentu berdasarkan pada profil data, kemudian menghasilkan kode mesin yang sangat optimal.
Jika pada beberapa titik asumsi ternyata salah, kompiler pengoptimalisasi akan menonaktifkan kode dan kembali ke tahap penerjemah.
Jalur pipa / kompiler juru bahasa dalam mesin JavaScriptSekarang mari kita melihat lebih dekat bagian-bagian dari pipa yang mengeksekusi kode JavaScript Anda, yaitu di mana kode ditafsirkan dan dioptimalkan, dan juga melihat beberapa perbedaan antara mesin JavaScript utama.
Inti dari semuanya adalah pipeline yang berisi interpreter dan kompiler yang mengoptimalkan. Interpreter dengan cepat menghasilkan bytecode yang tidak dioptimalkan, kompiler pengoptimal, pada gilirannya, bekerja lebih lama, tetapi hasilnya memiliki kode mesin yang sangat optimal.
Selanjutnya adalah saluran pipa yang menunjukkan cara kerja V8, mesin JavaScript yang digunakan oleh Chrome dan Node.js.

Penerjemah dalam V8 disebut Ignition, yang bertanggung jawab untuk menghasilkan dan mengeksekusi bytecode. Itu mengumpulkan data profil yang dapat digunakan untuk mempercepat eksekusi pada langkah selanjutnya ketika bytecode sedang diproses. Ketika suatu fungsi menjadi
panas , misalnya, jika itu mulai sering, bytecode dan data profil yang dihasilkan ditransfer ke TurboFan, yaitu, ke kompiler yang mengoptimalkan untuk menghasilkan kode mesin yang sangat dioptimalkan berdasarkan pada data profil.

Misalnya, mesin JavaScript SpiderMonkey Mozilla, yang digunakan di Firefox dan
SpiderNode , bekerja sedikit berbeda. Ini bukan satu, tetapi dua kompiler yang mengoptimalkan. Interpreter dioptimalkan menjadi kompiler dasar (Kompilator dasar), yang menghasilkan beberapa kode yang dioptimalkan. Bersama dengan profiling data yang dikumpulkan selama eksekusi kode, kompiler IonMonkey dapat menghasilkan kode yang sangat dioptimalkan. Jika optimasi spekulatif gagal, IonMonkey kembali ke kode Baseline.

Chakra - mesin JavaScript milik Microsoft, digunakan pada Edge dan
Node-ChakraCore , memiliki struktur yang sangat mirip dan menggunakan dua kompiler yang mengoptimalkan. Interpreter dioptimalkan dalam SimpleJIT (di mana JIT adalah singkatan dari "Just-In-Time compiler", yang menghasilkan kode yang agak dioptimalkan. Bersama dengan data profil, FullJIT dapat membuat kode yang lebih dioptimalkan lebih tinggi.
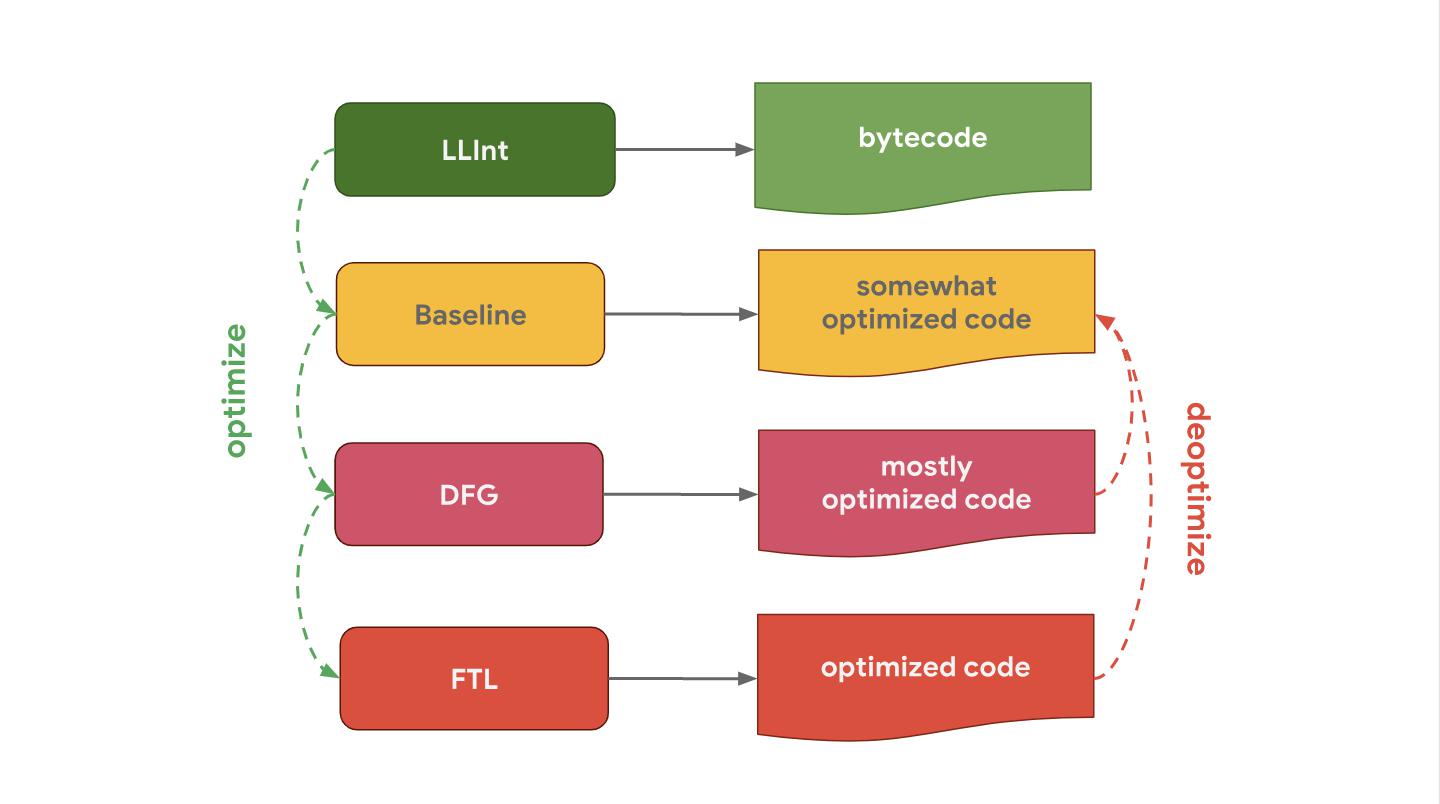
JavaScriptCore (disingkat JSC), mesin JavaScript Apple yang digunakan oleh Safari dan React Native, umumnya memiliki tiga kompiler pengoptimal yang berbeda. LLInt adalah juru bahasa level rendah yang dioptimalkan ke kompiler basis, yang pada gilirannya dioptimalkan ke kompiler DFG (Data Flow Graph), dan sudah dioptimalkan untuk kompiler FTL (Faster Than Light).
Mengapa beberapa engine memiliki kompiler yang lebih optimal daripada yang lain? Ini semua tentang kompromi. Interpreter dapat memproses bytecode dengan cepat, tetapi bytecode saja tidak terlalu efisien. Sebaliknya, kompiler pengoptimal bekerja sedikit lebih lama, tetapi menghasilkan kode mesin yang lebih efisien. Ini adalah kompromi antara cepat mendapatkan kode (juru bahasa) atau beberapa menunggu dan menjalankan kode dengan kinerja maksimum (mengoptimalkan kompiler). Beberapa engine memilih untuk menambahkan beberapa kompiler yang mengoptimalkan dengan karakteristik waktu dan efisiensi yang berbeda, yang memungkinkan Anda untuk memberikan kontrol terbaik atas solusi kompromi ini dan memahami biaya komplikasi tambahan dari perangkat internal. Pertukaran lainnya adalah penggunaan memori, lihat
artikel ini untuk pemahaman yang lebih baik.
Kami baru saja memeriksa perbedaan utama antara pipa penyalur interpreter dan optimizer untuk berbagai mesin JavaScript. Terlepas dari perbedaan tingkat tinggi ini, semua mesin JavaScript memiliki arsitektur yang sama: semuanya memiliki parser dan semacam pipa juru bahasa / penyusun.
Model objek JavaScriptMari kita lihat kesamaan apa yang dimiliki mesin JavaScript dan trik apa yang mereka gunakan untuk mempercepat akses ke properti objek JavaScript? Ternyata semua mesin utama melakukan ini dengan cara yang sama.
Spesifikasi ECMAScript mendefinisikan semua objek sebagai kamus dengan kunci string yang cocok dengan atribut
properti .

Selain
[[Value]] , spesifikasi mendefinisikan properti berikut:
[[Writable]] menentukan apakah suatu properti dapat dipindahkan;[[Enumerable]] menentukan apakah properti ditampilkan dalam for-in loop;[[Configurable]] menentukan apakah suatu properti dapat dihapus.
Notasi
[[ ]] terlihat aneh, tetapi begitulah spesifikasi menjelaskan properti di JavaScript. Anda masih bisa mendapatkan atribut properti ini untuk objek dan properti apa pun yang diberikan dalam JavaScript menggunakan API
Object.getOwnPropertyDescriptor :
const object = { foo: 42 }; Object.getOwnPropertyDescriptor(object, 'foo');
Oke, jadi JavaScript mendefinisikan objek. Bagaimana dengan array?
Anda dapat membayangkan array sebagai objek khusus. Satu-satunya perbedaan adalah array memiliki pemrosesan indeks khusus. Di sini, indeks array adalah istilah khusus dalam spesifikasi skrip ECMAS. JavaScript memiliki batasan jumlah elemen dalam array - hingga 2³² - 1. Indeks array adalah indeks apa pun yang tersedia dari rentang ini, yaitu nilai integer dari 0 hingga 2³² - 2.
Perbedaan lainnya adalah array memiliki properti ajaib yang
length .
const array = ['a', 'b']; array.length;
Dalam contoh ini, array memiliki panjang 2 pada saat pembuatan. Kemudian kami menetapkan elemen lain untuk mengindeks 2 dan panjangnya bertambah secara otomatis.
JavaScript mendefinisikan array serta objek. Sebagai contoh, semua kunci, termasuk indeks array, direpresentasikan secara eksplisit sebagai string. Elemen pertama array disimpan di bawah tombol '0'.

Properti
length hanyalah properti lain yang ternyata non-enumerable dan non-konfigurasi.
Segera setelah elemen ditambahkan ke array, JavaScript secara otomatis memperbarui atribut properti
[[Value]] properti
length .

Secara umum, kita dapat mengatakan bahwa array berperilaku mirip dengan objek.
Optimalisasi akses ke propertiSekarang kita tahu bagaimana objek didefinisikan dalam JavaScript, mari kita lihat bagaimana mesin JavaScript memungkinkan Anda untuk bekerja dengan objek secara efisien.
Dalam kehidupan sehari-hari, akses ke properti adalah operasi yang paling umum. Sangat penting bagi mesin untuk melakukan ini dengan cepat.
const object = { foo: 'bar', baz: 'qux', };
BentukDalam program JavaScript, cukup umum untuk menetapkan kunci properti yang sama ke banyak objek. Mereka mengatakan bahwa benda-benda tersebut memiliki
bentuk yang sama.
const object1 = { x: 1, y: 2 }; const object2 = { x: 3, y: 4 };
Juga mekanisme umum adalah akses ke properti benda dengan bentuk yang sama:
function logX(object) { console.log(object.x);
Mengetahui hal ini, mesin JavaScript dapat mengoptimalkan akses ke properti objek berdasarkan bentuknya. Lihat cara kerjanya.
Misalkan kita memiliki objek dengan properti x dan y, ia menggunakan struktur data kamus, yang telah kita bicarakan sebelumnya; itu berisi string kunci yang menunjuk ke atribut masing-masing.
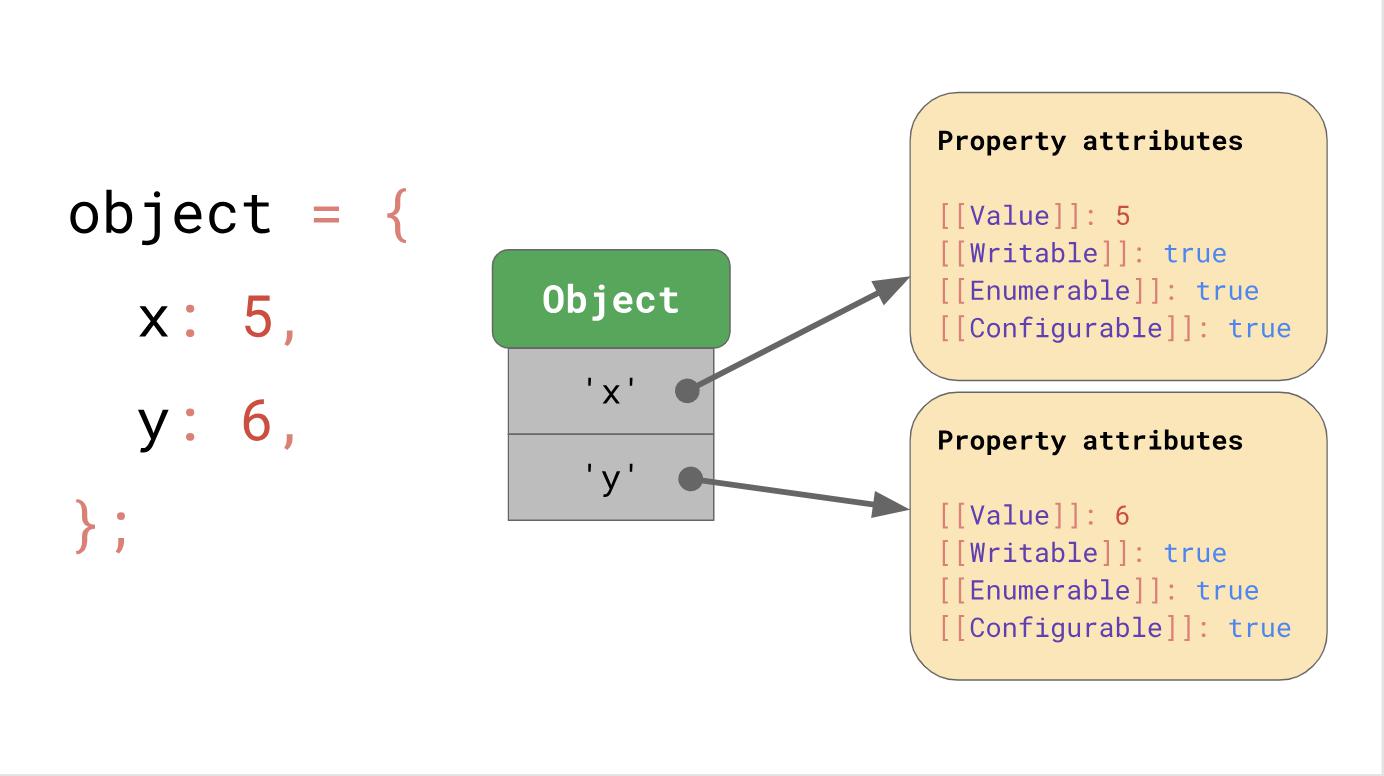
Jika Anda mengakses properti, seperti
object.y, mesin JavaScript mencari JSObject dengan kunci
'y' , kemudian memuat atribut properti yang cocok dengan kueri ini dan akhirnya mengembalikan
[[Value]] .
Tetapi di mana atribut properti ini disimpan dalam memori? Haruskah kita menyimpannya sebagai bagian dari JSObject? Jika kita melakukan ini, kita akan melihat lebih banyak objek dari formulir ini nanti, dalam hal ini, buang-buang ruang untuk menyimpan kamus lengkap yang berisi nama properti dan atribut di JSObject itu sendiri, karena nama properti diulang untuk semua objek dengan bentuk yang sama. Ini menyebabkan banyak duplikasi dan menyebabkan kesalahan alokasi memori. Untuk optimasi, mesin menyimpan bentuk objek secara terpisah.

Shape ini berisi semua nama dan atribut properti kecuali
[[Value]] . Sebagai gantinya, formulir berisi nilai offset di dalam JSObject, jadi mesin JavaScript tahu ke mana harus mencari nilai. Setiap JSObject dengan bentuk umum menunjukkan contoh spesifik dari formulir. Sekarang setiap JSObject harus menyimpan hanya nilai yang unik untuk objek.
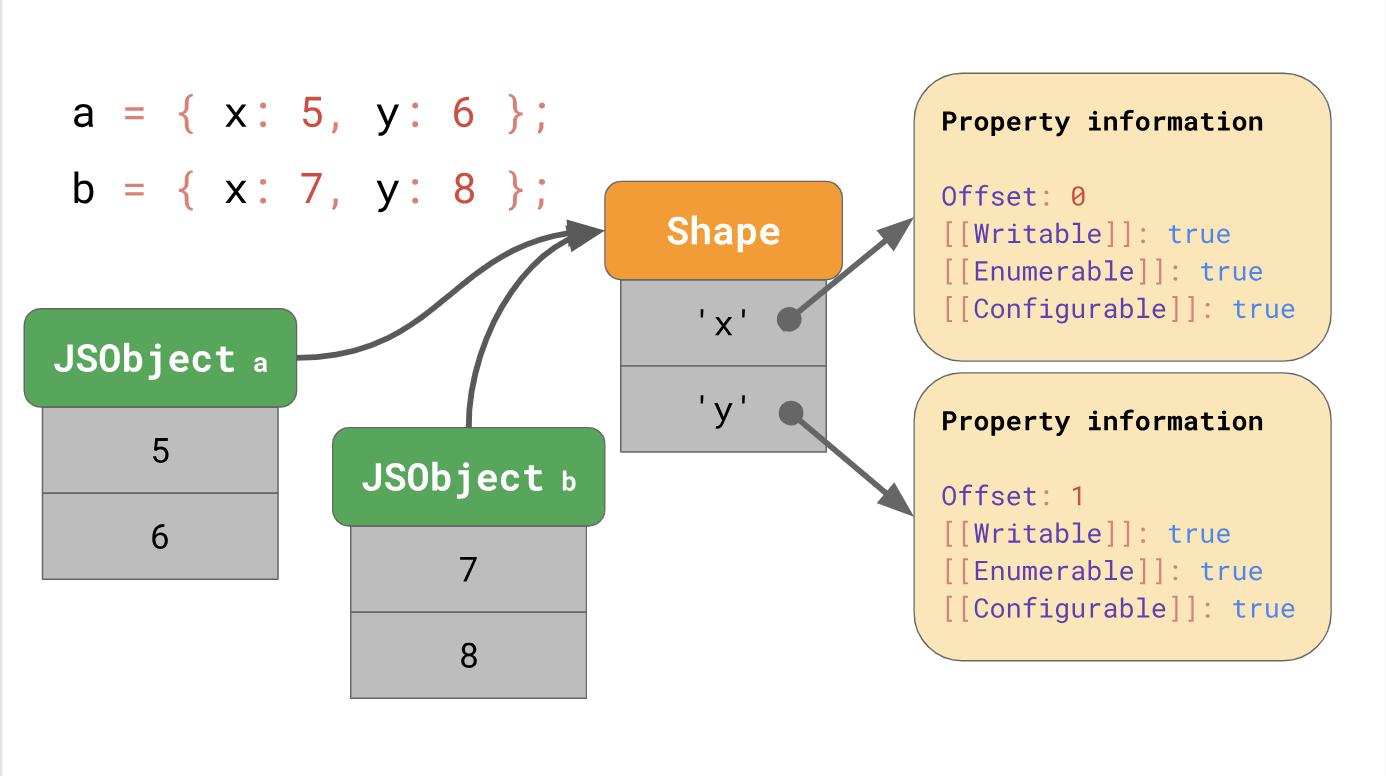
Keuntungan menjadi jelas segera setelah kami memiliki banyak objek. Jumlah mereka tidak masalah, karena jika mereka memiliki satu formulir, kami menyimpan informasi tentang formulir dan properti hanya sekali.
Semua mesin JavaScript menggunakan formulir sebagai alat optimasi, tetapi mereka tidak menamainya secara langsung sebagai
shapes :
- Dokumentasi Akademik menyebutnya Kelas Tersembunyi (mirip dengan kelas JavaScript);
- V8 menyebutnya Peta;
- Chakra menyebut mereka Jenis;
- JavaScriptCore menyebutnya Struktur;
- SpiderMonkey memanggil mereka Shapes.
Dalam artikel ini, kami terus menyebutnya
shapes .
Rantai transisi dan pohonApa yang terjadi jika Anda memiliki objek dengan bentuk tertentu, tetapi Anda menambahkan properti baru ke dalamnya? Bagaimana cara mesin JavaScript mendefinisikan bentuk baru?
const object = {}; object.x = 5; object.y = 6;
Formulir membuat apa yang disebut rantai transisi di mesin JavaScript. Berikut ini sebuah contoh:
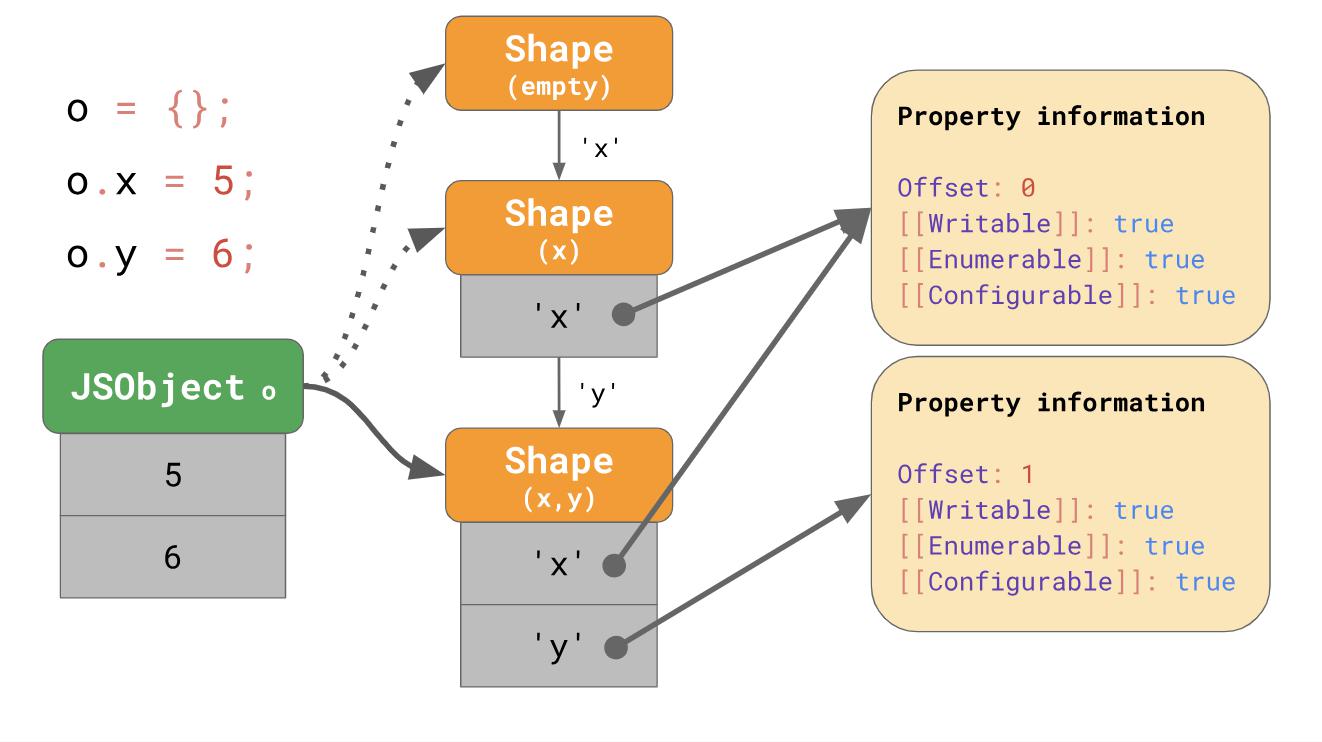
Objek pada awalnya tidak memiliki properti, itu sesuai dengan formulir kosong. Ekspresi berikut menambahkan properti
'x' dengan nilai 5 ke objek ini, kemudian mesin pergi ke bentuk yang berisi properti
'x' dan nilai 5 ditambahkan ke JSObject pada offset pertama 0. Baris berikutnya menambahkan properti
'y' , kemudian mesin menuju ke properti berikutnya formulir yang sudah berisi
'x' dan
'y' , dan juga menambahkan nilai 6 ke JSObject di offset 1.
Catatan : Urutan di mana properti ditambahkan mempengaruhi formulir. Misalnya, {x: 4, y: 5} akan menghasilkan bentuk yang berbeda dari {y: 5, x: 4}.
Kami bahkan tidak perlu menyimpan seluruh tabel properti untuk setiap formulir. Sebaliknya, setiap formulir hanya perlu mengetahui properti baru yang mereka coba sertakan di dalamnya. Misalnya, dalam hal ini, kita tidak perlu menyimpan informasi tentang 'x' dalam bentuk yang terakhir, karena dapat ditemukan sebelumnya dalam rantai. Agar ini berfungsi, formulir bergabung dengan bentuk sebelumnya.
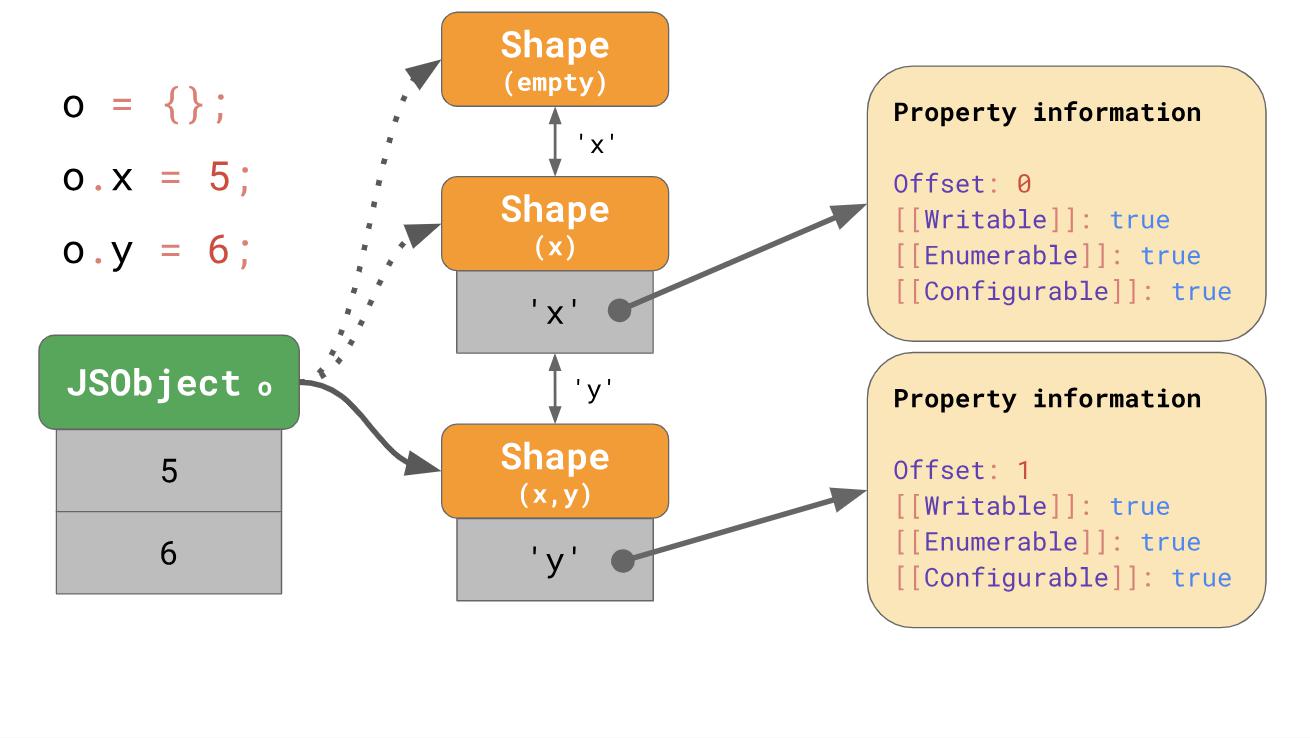
Jika Anda menulis
ox dalam kode JavaScript Anda, JavaScript akan mencari properti
'x' sepanjang rantai transisi hingga mendeteksi bentuk yang sudah memiliki properti
'x' di dalamnya.
Tetapi apa yang terjadi jika tidak mungkin membuat rantai transisi? Misalnya, apa yang terjadi jika Anda memiliki dua objek kosong dan Anda menambahkan properti yang berbeda padanya?
const object1 = {}; object1.x = 5; const object2 = {}; object2.y = 6;
Dalam kasus ini, cabang muncul, dan alih-alih rantai transisi kita mendapatkan pohon transisi:
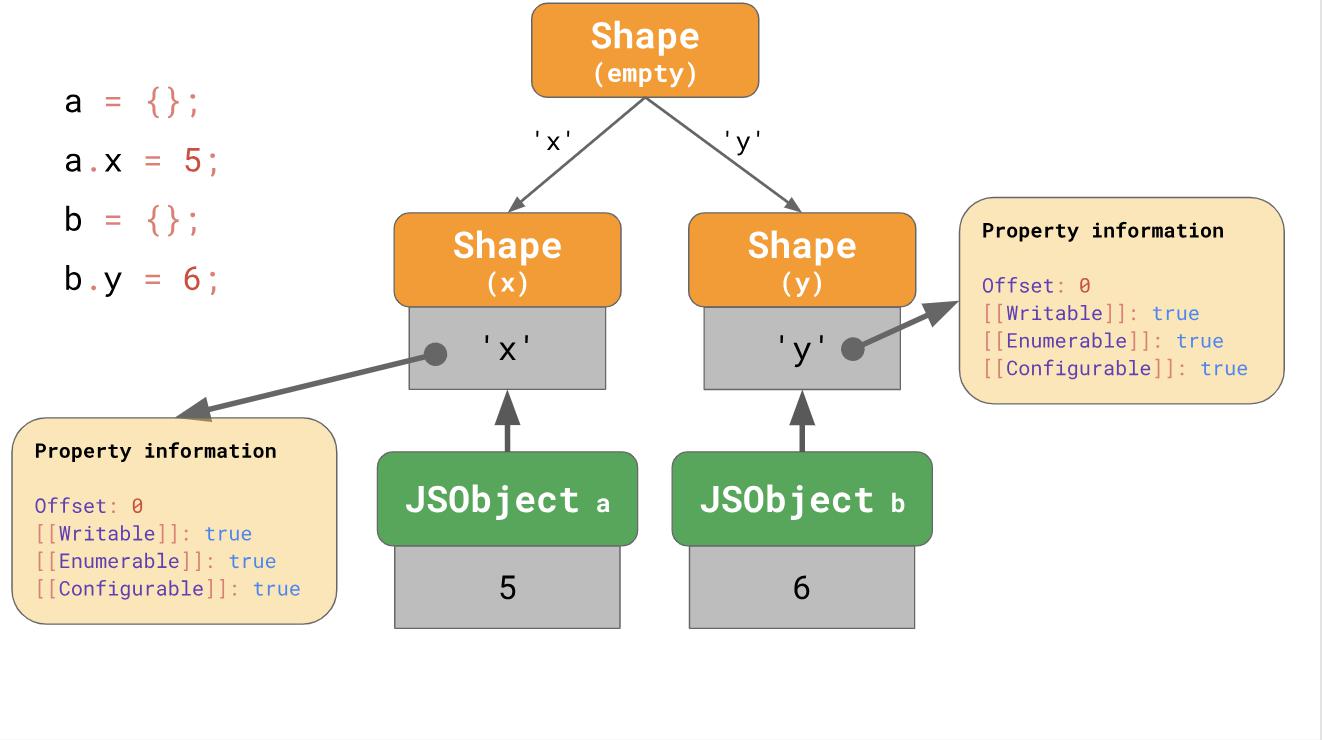
Kami membuat objek kosong
a dan menambahkan properti
'x' . Akibatnya, kami memiliki
JSObject berisi nilai tunggal dan dua formulir: kosong dan formulir dengan properti
'x' tunggal.
Contoh kedua dimulai dengan fakta bahwa kita memiliki objek kosong
b , tetapi kemudian kita menambahkan properti lain
'y' . Hasilnya, di sini kita mendapatkan dua rantai bentuk, tetapi pada akhirnya kita mendapatkan tiga rantai.
Apakah ini berarti kita selalu mulai dengan formulir kosong? Belum tentu. Mesin menggunakan beberapa optimasi objek literal, yang sudah mengandung properti. Katakanlah kita menambahkan x, dimulai dengan objek kosong literal, atau kita memiliki objek literal yang sudah berisi
x :
const object1 = {}; object1.x = 5; const object2 = { x: 6 };
Pada contoh pertama, kita mulai dengan formulir kosong dan pergi ke rantai yang juga berisi
x , seperti yang kita lihat sebelumnya.
Dalam kasus
object2 masuk akal untuk secara langsung membuat objek yang sudah memiliki x dari awal, daripada memulai dengan objek kosong dan transisi.
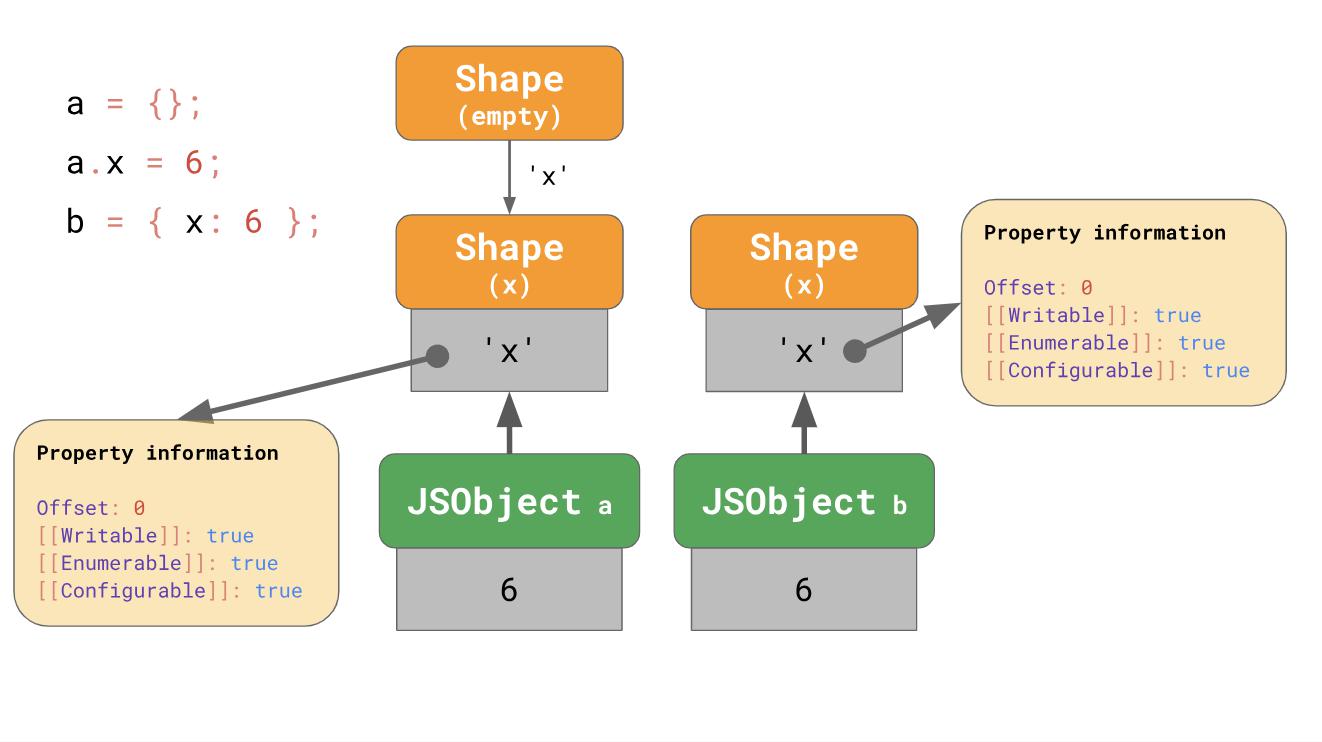
Literal dari objek yang berisi properti
'x' dimulai dengan bentuk yang mengandung
'x' sejak awal, dan bentuk kosong dilewati secara efektif. Inilah (setidaknya) yang dilakukan V8 dan SpiderMonkey. Optimalisasi memperpendek rantai transisi dan membuatnya lebih mudah untuk mengumpulkan objek dari literal.
Posting blog Benedict tentang polimorfisme aplikasi yang menakjubkan tentang
React berbicara tentang bagaimana seluk-beluk seperti itu dapat memengaruhi kinerja.
Selanjutnya Anda akan melihat contoh titik-titik objek tiga dimensi dengan properti
'x' ,
'y' ,
'z' .
const point = {}; point.x = 4; point.y = 5; point.z = 6;
Seperti yang Anda pahami sebelumnya, kami membuat objek dengan tiga bentuk dalam memori (tidak termasuk bentuk kosong). Untuk mengakses properti
'x' dari objek ini, misalnya, jika Anda menulis
point.x di program Anda, mesin JavaScript harus mengikuti daftar tertaut: mulai dari formulir di bagian paling bawah, dan kemudian secara bertahap bergerak ke atas ke bentuk yang memiliki
'x' di bagian paling atas.
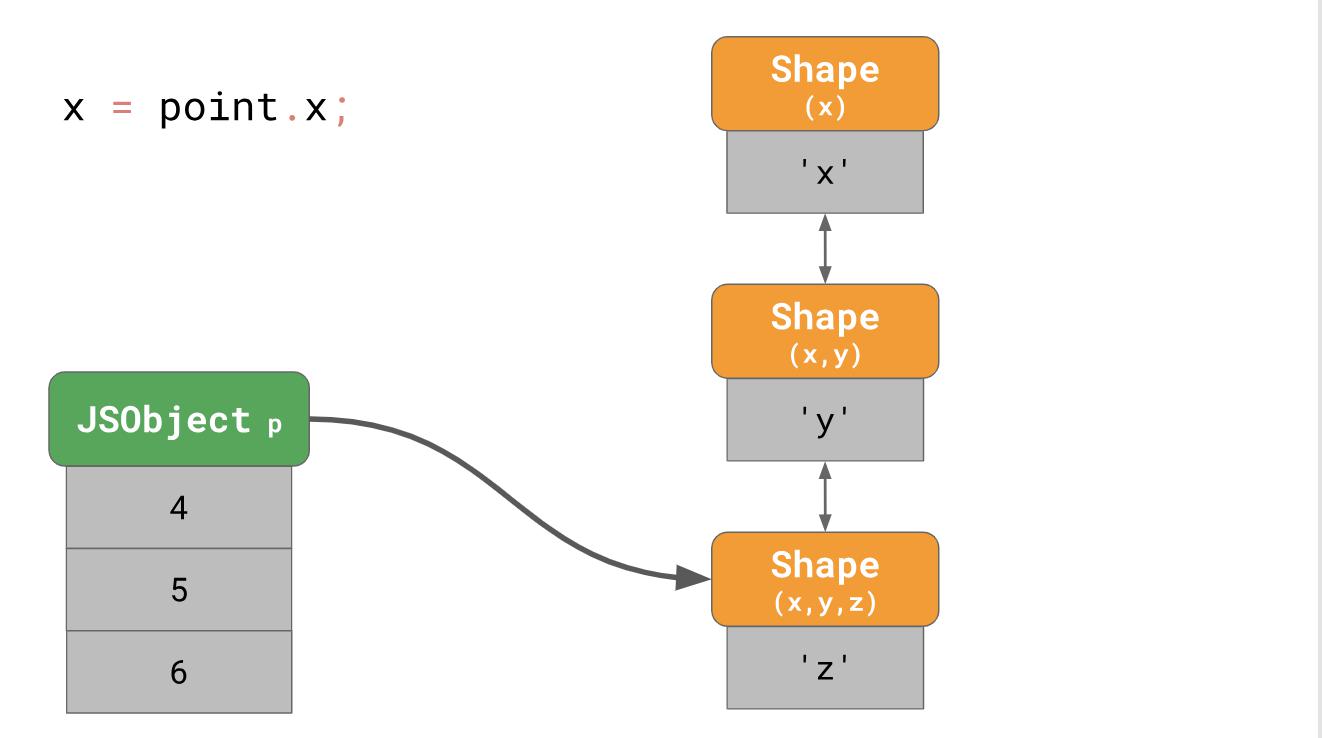
Ternyata sangat lambat, terutama jika Anda sering melakukannya dan dengan banyak properti objek. Waktu tinggal properti adalah
O(n) , yaitu, itu adalah fungsi linier yang berkorelasi dengan jumlah properti objek. Untuk mempercepat pencarian properti, mesin JavaScript menambahkan struktur data ShapeTable. ShapeTable adalah kamus tempat kunci dipetakan dengan cara tertentu dengan formulir dan menghasilkan properti yang diinginkan.
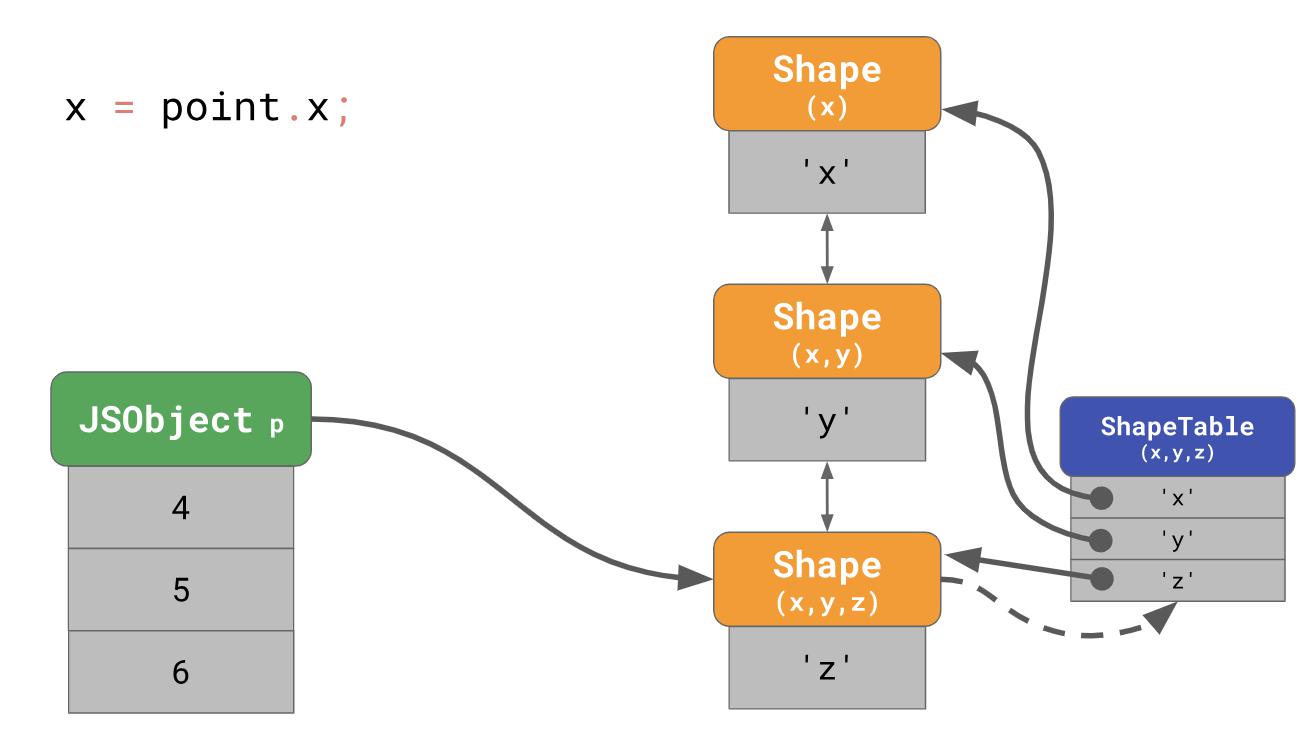
Tunggu sebentar, sekarang kita kembali ke pencarian kamus ... Ini adalah apa yang kita mulai dengan ketika kita meletakkan formulir di tempat pertama! Jadi mengapa kita peduli dengan formulir?
Faktanya adalah bahwa formulir berkontribusi pada pengoptimalan lain yang disebut
Cache Inline.Kami akan berbicara tentang konsep cache inline atau IC di bagian
kedua artikel, dan sekarang kami ingin mengundang Anda ke
webinar terbuka gratis , yang akan dipegang oleh analis virus terkenal dan guru paruh waktu,
Alexander Kolesnikov , pada 9 April.