Kami telah membahas
mesin pengindeksan PostgreSQL,
antarmuka metode akses , dan tiga metode:
indeks hash ,
B-tree , dan
GiST . Pada artikel ini, kami akan menjelaskan SP-GiST.
SP-GiST
Pertama, beberapa kata tentang nama ini. Bagian "GiST" menyinggung beberapa kesamaan dengan metode akses nama yang sama. Kesamaan memang ada: keduanya pohon pencarian umum yang menyediakan kerangka kerja untuk membangun berbagai metode akses.
"SP" adalah singkatan dari partisi ruang. Ruang di sini sering kali biasa kita sebut ruang, misalnya, bidang dua dimensi. Tetapi kita akan melihat bahwa ruang pencarian apa pun dimaksudkan, yaitu, sebenarnya domain nilai apa pun.
SP-GiST cocok untuk struktur di mana ruang dapat dibelah secara rekursif menjadi area yang
tidak berpotongan . Kelas ini terdiri dari quadtrees, pohon k-dimensional (pohon kD), dan pohon radix.
Struktur
Jadi, ide metode akses SP-GiST adalah untuk membagi domain nilai menjadi subdomain yang tidak
tumpang tindih yang masing-masing, pada gilirannya, juga dapat dibagi. Pemisahan seperti ini menyebabkan pohon tidak
seimbang (tidak seperti pohon B dan GiST biasa).
Sifat tidak berpotongan menyederhanakan pengambilan keputusan selama penyisipan dan pencarian. Di sisi lain, sebagai suatu peraturan, pohon yang diinduksi adalah bercabang rendah. Sebagai contoh, sebuah simpul quadtree biasanya memiliki empat node anak (tidak seperti B-tree, di mana jumlah node mencapai ratusan) dan kedalaman yang lebih besar. Pohon-pohon seperti ini cocok dengan pekerjaan dalam RAM, tetapi indeks disimpan pada disk dan oleh karena itu, untuk mengurangi jumlah operasi I / O, node harus dimasukkan ke dalam halaman, dan tidak mudah untuk melakukan ini secara efisien. Selain itu, waktu yang diperlukan untuk menemukan nilai yang berbeda dalam indeks, dapat bervariasi karena perbedaan kedalaman cabang.
Metode akses ini, sama seperti GiST, menangani tugas-tugas tingkat rendah (akses dan kunci simultan, logging, dan algoritma pencarian murni) dan menyediakan antarmuka yang disederhanakan khusus untuk memungkinkan menambahkan dukungan untuk tipe data baru dan untuk algoritma partisi baru.
Node internal pohon SP-GiST menyimpan referensi ke node anak;
label dapat didefinisikan untuk setiap referensi. Selain itu, simpul internal dapat menyimpan nilai yang disebut
awalan . Sebenarnya nilai ini bukan merupakan awalan wajib; itu dapat dianggap sebagai predikat sewenang-wenang yang dipenuhi untuk semua node anak.
Node daun SP-GiST berisi nilai dari tipe yang diindeks dan referensi ke baris tabel (TID). Data yang diindeks itu sendiri (kunci pencarian) dapat digunakan sebagai nilai, tetapi tidak wajib: nilai yang dipersingkat dapat disimpan.
Selain itu, node daun dapat dikelompokkan ke dalam daftar. Jadi, sebuah simpul internal dapat merujuk tidak hanya satu nilai, tetapi seluruh daftar.
Perhatikan bahwa awalan, label, dan nilai dalam node daun memiliki tipe datanya sendiri, tidak tergantung satu sama lain.
Sama seperti di GiST, fungsi utama untuk menentukan untuk pencarian adalah
fungsi konsistensi . Fungsi ini dipanggil untuk simpul pohon dan mengembalikan satu set simpul anak yang nilainya "konsisten" dengan predikat pencarian (seperti biasa, dalam bentuk "
ekspresi operator bidang-bidang "). Untuk simpul daun, fungsi konsistensi menentukan apakah nilai yang diindeks dalam simpul ini memenuhi predikat pencarian.
Pencarian dimulai dengan root node. Fungsi konsistensi memungkinkan untuk mengetahui simpul anak mana yang masuk akal untuk dikunjungi. Algoritme berulang untuk setiap node yang ditemukan. Pencarian adalah kedalaman-pertama.
Pada tingkat fisik, indeks node dikemas ke dalam halaman untuk membuat pekerjaan dengan node efisien dari sudut pandang operasi I / O. Perhatikan bahwa satu halaman dapat berisi node internal atau daun, tetapi tidak keduanya.
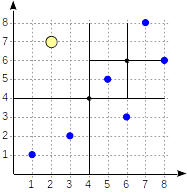
Contoh: quadtree
Quadtree digunakan untuk mengindeks poin dalam sebuah pesawat. Gagasannya adalah membagi daerah secara rekursif menjadi empat bagian (kuadran) sehubungan dengan
titik pusat . Kedalaman cabang di pohon seperti itu dapat bervariasi dan tergantung pada kepadatan titik di kuadran yang sesuai.
Ini terlihat seperti dalam gambar, dengan contoh dari
database demo ditambah oleh bandara dari situs
openflights.org . Ngomong-ngomong, baru-baru ini kami merilis versi baru dari database di mana, di antara yang lain, kami mengganti bujur dan lintang dengan satu bidang tipe "titik".
 Pertama, kami membagi pesawat menjadi empat kuadran ...
Pertama, kami membagi pesawat menjadi empat kuadran ... Lalu kami membagi masing-masing kuadran ...
Lalu kami membagi masing-masing kuadran ... Dan seterusnya sampai kita mendapatkan partisi terakhir.
Dan seterusnya sampai kita mendapatkan partisi terakhir.Mari kita berikan lebih banyak detail dari contoh sederhana yang telah kita
bahas dalam artikel terkait GiST . Lihat seperti apa tampilan partisi dalam kasus ini:
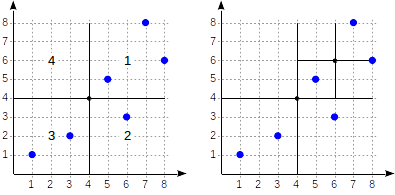
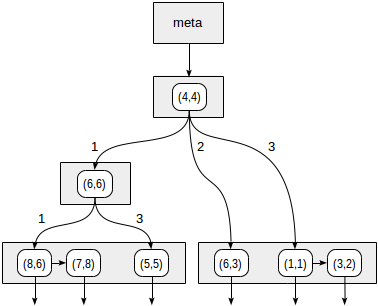
Kuadran diberi nomor seperti yang ditunjukkan pada gambar pertama. Demi kepastian, mari kita tempatkan node anak dari kiri ke kanan tepat dalam urutan yang sama. Struktur indeks yang mungkin dalam hal ini ditunjukkan pada gambar di bawah ini. Setiap simpul internal merujuk maksimal empat simpul anak. Setiap referensi dapat diberi label dengan nomor kuadran, seperti pada gambar. Tetapi tidak ada label dalam implementasi karena lebih mudah untuk menyimpan array tetap dari empat referensi yang beberapa di antaranya bisa kosong.
Poin yang terletak pada batas berkaitan dengan kuadran dengan jumlah yang lebih kecil.
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index points_quad_idx on points using spgist(p);
Dalam hal ini, kelas operator "quad_point_ops" digunakan secara default, yang berisi operator berikut:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'quad_point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- <<(point,point) | 1 strictly left >>(point,point) | 5 strictly right ~=(point,point) | 6 coincides <^(point,point) | 10 strictly below >^(point,point) | 11 strictly above <@(point,box) | 8 contained in rectangle (6 rows)
Misalnya, mari kita lihat bagaimana kueri
select * from points where p >^ point '(2,7)' akan dilakukan (temukan semua titik yang terletak di atas yang diberikan).
Kita mulai dengan simpul root dan menggunakan fungsi konsistensi untuk memilih ke mana simpul anak diturunkan. Untuk operator
>^ , fungsi ini membandingkan titik (2,7) dengan titik pusat simpul (4,4) dan memilih kuadran yang mungkin mengandung titik yang dicari, dalam hal ini, kuadran pertama dan keempat.
Dalam node yang sesuai dengan kuadran pertama, kami kembali menentukan node anak menggunakan fungsi konsistensi. Titik pusatnya adalah (6,6), dan kita kembali perlu melihat kuadran pertama dan keempat.
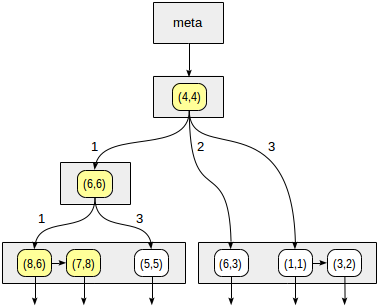
Daftar node daun (8.6) dan (7.8) sesuai dengan kuadran pertama, yang hanya titik (7,8) yang memenuhi kondisi kueri. Referensi ke kuadran keempat kosong.
Di simpul internal (4.4), referensi ke kuadran keempat juga kosong, yang melengkapi pencarian.
postgres=# set enable_seqscan = off; postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN ------------------------------------------------ Index Only Scan using points_quad_idx on points Index Cond: (p >^ '(2,7)'::point) (2 rows)
Internal
Kita dapat menjelajahi struktur internal indeks SP-GiST menggunakan ekstensi "
gevel ", yang disebutkan sebelumnya. Berita buruknya adalah karena bug, ekstensi ini berfungsi secara salah dengan versi modern PostgreSQL. Berita baiknya adalah kami berencana menambah "pageinspect" dengan fungsionalitas "gevel" (
diskusi ). Dan bug sudah diperbaiki di "pageinspect".
Sekali lagi, berita buruknya adalah tambalan itu macet tanpa kemajuan.
Sebagai contoh, mari kita ambil basis data demo yang diperluas, yang digunakan untuk menggambar dengan peta dunia.
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
Pertama, kita bisa mendapatkan beberapa statistik untuk indeks:
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats ---------------------------------- totalPages: 33 + deletedPages: 0 + innerPages: 3 + leafPages: 30 + emptyPages: 2 + usedSpace: 201.53 kbytes+ usedInnerSpace: 2.17 kbytes + usedLeafSpace: 199.36 kbytes+ freeSpace: 61.44 kbytes + fillRatio: 76.64% + leafTuples: 5993 + innerTuples: 37 + innerAllTheSame: 0 + leafPlaceholders: 725 + innerPlaceholders: 0 + leafRedirects: 0 + innerRedirects: 0 (1 row)
Dan kedua, kita dapat menampilkan pohon indeks itu sendiri:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_quad_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix point,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------------+------------------ (1,1) | 0 | 1 | (5,3) | (-10.220,53.588) | (1,1) | 1 | 1 | (5,2) | (-10.220,53.588) | (1,1) | 2 | 1 | (5,1) | (-10.220,53.588) | (1,1) | 3 | 1 | (5,14) | (-10.220,53.588) | (3,68) | | 3 | | | (86.107,55.270) (3,70) | | 3 | | | (129.771,62.093) (3,85) | | 4 | | | (57.684,-20.430) (3,122) | | 4 | | | (107.438,51.808) (3,154) | | 3 | | | (-51.678,64.191) (5,1) | 0 | 2 | (24,27) | (-88.680,48.638) | (5,1) | 1 | 2 | (5,7) | (-88.680,48.638) | ...
Tetapi perlu diingat bahwa "spgist_print" menampilkan tidak semua nilai daun, tetapi hanya yang pertama dari daftar, dan karena itu menunjukkan struktur indeks daripada konten lengkapnya.
Contoh: pohon k-dimensional
Untuk titik-titik yang sama di pesawat, kami juga dapat menyarankan cara lain untuk mempartisi ruang.
Mari menggambar
garis horizontal melalui titik pertama yang diindeks. Membagi pesawat menjadi dua bagian: atas dan bawah. Titik kedua yang akan diindeks jatuh ke dalam salah satu bagian ini. Melalui titik ini, mari kita menggambar
garis vertikal , yang membagi bagian ini menjadi dua yang: kanan dan kiri. Kita lagi menggambar garis horizontal melalui titik berikutnya dan garis vertikal melalui titik berikutnya, dan seterusnya.
Semua simpul internal pohon yang dibangun dengan cara ini hanya akan memiliki dua simpul anak. Masing-masing dari dua referensi dapat mengarah ke node internal yang berikutnya dalam hierarki atau ke daftar node daun.
Metode ini dapat dengan mudah digeneralisasikan untuk ruang dimensi k, dan oleh karena itu, pohon juga disebut dimensi k (pohon kD) dalam literatur.
Menjelaskan metode dengan contoh bandara:
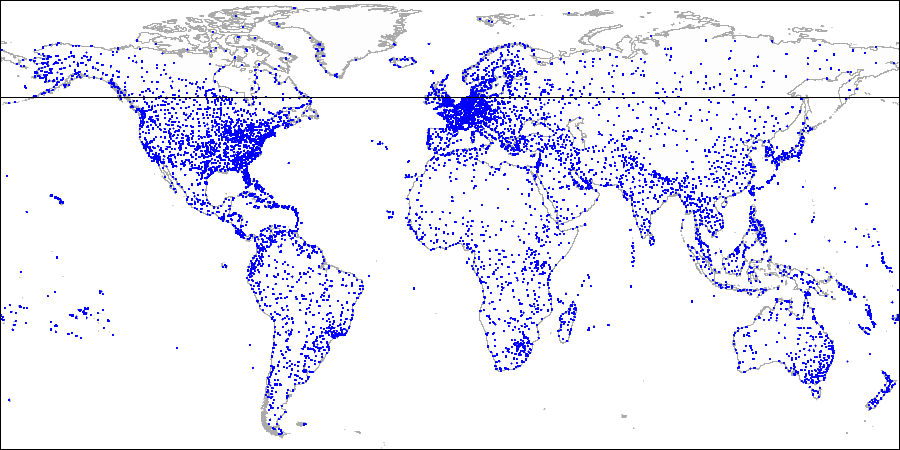 Pertama kami membagi pesawat menjadi bagian atas dan bawah ...
Pertama kami membagi pesawat menjadi bagian atas dan bawah ...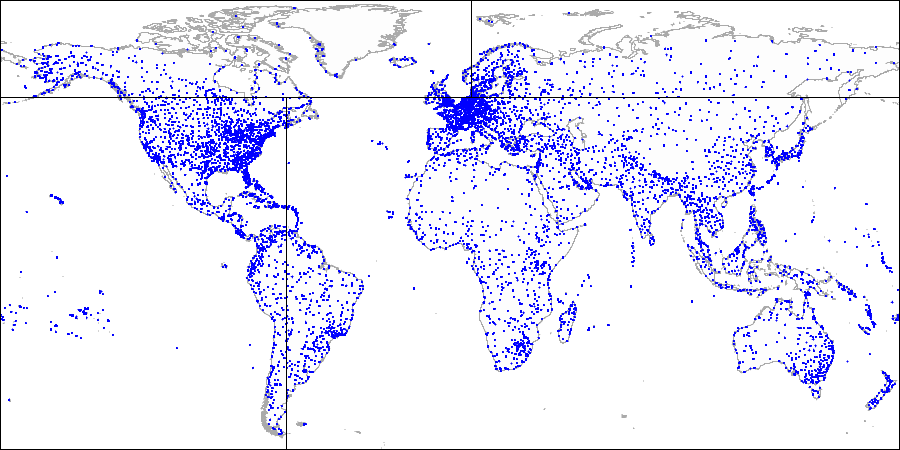 Lalu kami membagi setiap bagian menjadi bagian kiri dan kanan ...
Lalu kami membagi setiap bagian menjadi bagian kiri dan kanan ... Dan seterusnya sampai kita mendapatkan partisi terakhir.
Dan seterusnya sampai kita mendapatkan partisi terakhir.Untuk menggunakan partisi seperti ini, kita perlu secara eksplisit menentukan kelas operator
"kd_point_ops" saat membuat indeks.
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
Kelas ini mencakup operator yang sama persis dengan kelas "default" "quad_point_ops".
Internal
Ketika melihat melalui struktur pohon, kita perlu memperhitungkan bahwa awalan dalam kasus ini hanya satu koordinat daripada satu titik:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_kd_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix float,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------+------------------ (1,1) | 0 | 1 | (5,1) | 53.740 | (1,1) | 1 | 1 | (5,4) | 53.740 | (3,113) | | 6 | | | (-7.277,62.064) (3,114) | | 6 | | | (-85.033,73.006) (5,1) | 0 | 2 | (5,12) | -65.449 | (5,1) | 1 | 2 | (5,2) | -65.449 | (5,2) | 0 | 3 | (5,6) | 35.624 | (5,2) | 1 | 3 | (5,3) | 35.624 | ...
Contoh: pohon radix
Kita juga bisa menggunakan SP-GiST untuk mengimplementasikan pohon radix untuk string. Gagasan pohon radix adalah bahwa string yang akan diindeks tidak sepenuhnya disimpan dalam simpul daun, tetapi diperoleh dengan menggabungkan nilai-nilai yang disimpan dalam node di atas yang satu ini sampai ke root.
Asumsikan, kita perlu mengindeks URL situs: "postgrespro.ru", "postgrespro.com", "postgresql.org", dan "planet.postgresql.org".
postgres=# create table sites(url text); postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org'); postgres=# create index on sites using spgist(url);
Pohon itu akan terlihat sebagai berikut:
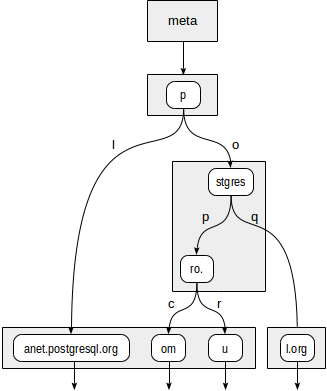
Node internal prefix store tree umum untuk semua node anak. Misalnya, dalam simpul anak "stgres", nilai dimulai dengan "p" + "o" + "stgres".
Tidak seperti di quadtrees, setiap pointer ke simpul anak juga diberi label dengan satu karakter (lebih tepatnya, dengan dua byte, tetapi ini tidak begitu penting).
"Text_ops" kelas operator mendukung operator mirip-Pohon: "sama", "lebih besar", dan "kurang":
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'text_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- ~<~(text,text) | 1 ~<=~(text,text) | 2 =(text,text) | 3 ~>=~(text,text) | 4 ~>~(text,text) | 5 <(text,text) | 11 <=(text,text) | 12 >=(text,text) | 14 >(text,text) | 15 (9 rows)
Perbedaan operator dengan tilde adalah mereka memanipulasi
byte daripada
karakter .
Kadang-kadang, representasi dalam bentuk pohon radix dapat berubah menjadi jauh lebih kompak daripada B-pohon karena nilai-nilai tidak sepenuhnya disimpan, tetapi direkonstruksi karena kebutuhan muncul saat turun melalui pohon.
Pertimbangkan kueri:
select * from sites where url like 'postgresp%ru' . Itu dapat dilakukan dengan menggunakan indeks:
postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN ------------------------------------------------------------------------------ Index Only Scan using sites_url_idx on sites Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text)) Filter: (url ~~ 'postgresp%ru'::text) (3 rows)
Sebenarnya, indeks digunakan untuk menemukan nilai yang lebih besar atau sama dengan "postgresp", tetapi kurang dari "postgresq" (Indeks Cond), dan kemudian nilai yang cocok dipilih dari hasil (Filter).
Pertama, fungsi konsistensi harus memutuskan ke simpul anak mana dari akar "p" yang perlu kita turunkan. Tersedia dua opsi: "p" + "l" (tidak perlu turun, yang jelas bahkan tanpa menyelam lebih dalam) dan "p" + "o" + "stgres" (lanjutkan penurunan).
Untuk simpul "stgres", panggilan ke fungsi konsistensi diperlukan lagi untuk memeriksa "postgres" + "p" + "ro." (lanjutkan penurunan) dan "postgres" + "q" (tidak perlu turun).
Untuk "ro." simpul dan semua simpul daun anaknya, fungsi konsistensi akan merespons "ya", sehingga metode indeks akan mengembalikan dua nilai: "postgrespro.com" dan "postgrespro.ru". Satu nilai yang cocok akan dipilih dari mereka pada tahap penyaringan.
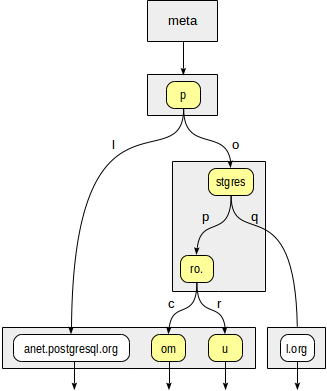
Internal
Saat melihat melalui struktur pohon, kita perlu mempertimbangkan tipe data:
postgres=# select * from spgist_print('sites_url_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix text,
Properti
Mari kita lihat properti dari metode akses SP-GiST (pertanyaan
disediakan sebelumnya ):
amname | name | pg_indexam_has_property --------+---------------+------------------------- spgist | can_order | f spgist | can_unique | f spgist | can_multi_col | f spgist | can_exclude | t
Indeks SP-GiST tidak dapat digunakan untuk menyortir dan untuk mendukung kendala unik. Selain itu, indeks seperti ini tidak dapat dibuat di beberapa kolom (tidak seperti GiST). Tetapi diizinkan untuk menggunakan indeks tersebut untuk mendukung batasan pengecualian.
Properti lapisan indeks berikut tersedia:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | f
Perbedaan dari GiST di sini adalah bahwa pengelompokan tidak mungkin.
Dan akhirnya yang berikut adalah properti kolom-layer:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | t search_array | f search_nulls | t
Penyortiran tidak didukung, yang dapat diprediksi. Operator jarak untuk mencari tetangga terdekat tidak tersedia di SP-GiST sejauh ini. Kemungkinan besar, fitur ini akan didukung di masa depan.
Ini didukung di PostgreSQL 12 mendatang, tambalan oleh Nikita Glukhov.
SP-GiST dapat digunakan untuk pemindaian hanya indeks, setidaknya untuk kelas operator yang dibahas. Seperti yang telah kita lihat, dalam beberapa kasus, nilai-nilai yang diindeks secara eksplisit disimpan dalam simpul daun, sementara di yang lain, nilai-nilai tersebut direkonstruksi bagian demi bagian selama penurunan pohon.
Nulls
Tidak menyulitkan gambar, kami belum menyebutkan NULL sejauh ini. Jelas dari properti indeks bahwa NULL didukung. Sungguh:
postgres=# explain (costs off) select * from sites where url is null;
QUERY PLAN ---------------------------------------------- Index Only Scan using sites_url_idx on sites Index Cond: (url IS NULL) (2 rows)
Namun, NULL adalah sesuatu yang asing bagi SP-GiST. Semua operator dari kelas operator "spgist" harus ketat: operator harus mengembalikan NULL setiap kali salah satu parameternya adalah NULL. Metode itu sendiri memastikan ini: NULL tidak diteruskan ke operator.
Tetapi untuk menggunakan metode akses untuk pemindaian hanya indeks, NULL harus tetap disimpan dalam indeks. Dan mereka disimpan, tetapi di pohon yang terpisah dengan akarnya sendiri.
Tipe data lainnya
Selain poin dan pohon radix untuk string, metode lain berdasarkan SP-GiST juga diterapkan PostgreSQL:
- Kelas operator Box_ops menyediakan quadtree untuk persegi panjang.
Setiap persegi panjang diwakili oleh sebuah titik dalam ruang empat dimensi , sehingga jumlah kuadran sama dengan 16. Indeks seperti ini dapat mengalahkan GiST dalam kinerja ketika ada banyak persimpangan dari persegi panjang: di GiST tidak mungkin untuk menggambar batas sehingga untuk memisahkan objek berpotongan satu sama lain, sementara tidak ada masalah dengan poin (bahkan empat dimensi).
- "Range_ops" kelas operator menyediakan quadtree untuk interval.
Interval diwakili oleh titik dua dimensi : batas bawah menjadi absis, dan batas atas menjadi ordinat.
Baca terus .