
Seperti yang disebutkan dalam artikel Teknologi Radar , Lamoda aktif bergerak menuju arsitektur layanan mikro. Sebagian besar layanan kami dikemas menggunakan Helm dan digunakan untuk Kubernetes. Pendekatan ini sepenuhnya memenuhi kebutuhan kita dalam 99% kasus. 1% tetap ketika fungsionalitas Kubernetes standar tidak cukup, misalnya, ketika Anda perlu mengkonfigurasi cadangan atau pembaruan layanan untuk acara tertentu. Untuk mengatasi masalah ini, kami menggunakan pola operator. Dalam seri artikel ini, I - Grigory Mikhalkin, pengembang tim R&D di Lamoda - akan berbicara tentang pelajaran yang saya pelajari dari pengalaman saya dalam mengembangkan operator K8 menggunakan Kerangka Operator .
Apa itu operator?
Salah satu cara untuk memperluas fungsionalitas Kubernetes adalah dengan membuat pengontrol Anda sendiri. Abstraksi utama dalam Kubernet adalah objek dan pengontrol. Objek menggambarkan keadaan cluster yang diinginkan. Misalnya, Pod menjelaskan wadah mana yang harus dimulai dan parameter startup, dan objek ReplicaSet memberitahu berapa banyak replika dari Pod yang diberikan perlu diluncurkan. Kontroler mengontrol keadaan gugus berdasarkan pada deskripsi objek, dalam kasus yang dijelaskan di atas, ReplicationController akan mendukung jumlah replika Pod yang ditentukan dalam ReplicaSet. Dengan bantuan pengontrol baru, Anda dapat menerapkan logika tambahan, seperti mengirim pemberitahuan acara, pulih dari kegagalan, atau mengelola sumber daya pihak ketiga .
Operator adalah aplikasi kubernet yang mencakup satu atau lebih pengontrol yang melayani sumber daya pihak ketiga. Konsep ini diciptakan oleh tim CoreOS pada tahun 2016, dan baru-baru ini, popularitas operator telah berkembang pesat. Anda dapat mencoba menemukan operator yang diinginkan dalam daftar di kubedex , (lebih dari 100 operator yang tersedia untuk publik terdaftar di sini), serta di OperatorHub . Ada 3 alat populer untuk pengembangan operator: Kubebuilder , Operator SDK dan Metacontroller . Di Lamoda kami menggunakan Operator SDK, jadi kami akan membicarakannya nanti.
Operator SDK
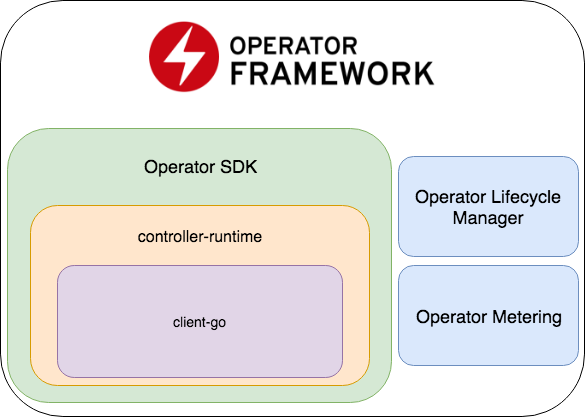
Operator SDK adalah bagian dari Kerangka Operator, yang mencakup dua bagian penting: Manajer Siklus Hidup Operator dan Pengukuran Operator.
- Operator SDK adalah pembungkus untuk runtime pengontrol , perpustakaan populer untuk mengembangkan pengontrol (yang, pada gilirannya, adalah pembungkus untuk client-go ), kerangka pembuat kode + untuk menulis tes E2E.
- Operator Siklus Hidup Operator - kerangka kerja untuk mengelola operator yang ada; menyelesaikan situasi ketika operator memasuki mode zombie atau versi baru diluncurkan.
- Pengukuran Operator - sesuai dengan namanya, ia mengumpulkan data pada pekerjaan operator, dan juga dapat menghasilkan laporan berdasarkan pada itu.
Buat proyek baru
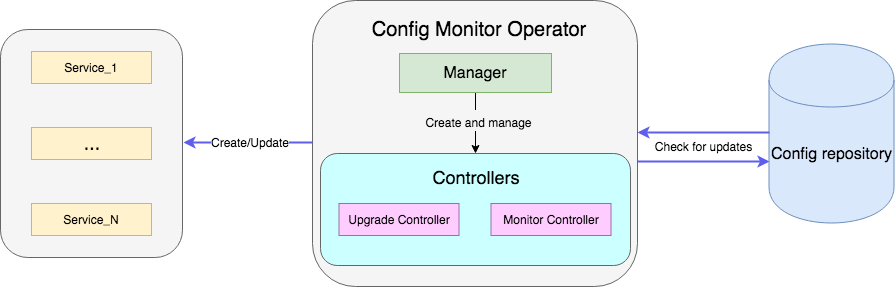
Contohnya adalah operator yang memantau file dengan konfigurasi di repositori dan, ketika diperbarui, memulai kembali penyebaran layanan dengan konfigurasi baru. Kode sampel lengkap tersedia di sini .
Buat proyek dengan operator baru:
operator-sdk new config-monitor
Pembuat kode akan membuat kode untuk operator yang bekerja di namespace yang dialokasikan. Pendekatan ini lebih disukai untuk memberikan akses ke seluruh cluster, karena jika terjadi kesalahan, masalah akan diisolasi dalam namespace yang sama. Operator cluster-wide dapat dihasilkan dengan menambahkan --cluster-scoped . Direktori berikut akan berlokasi di dalam proyek yang dibuat:
- cmd - berisi
main package , di mana Manager diinisialisasi dan diluncurkan; - deploy - berisi pernyataan operator, CRD dan objek yang diperlukan untuk mengatur operator RBAC
- pkg - ini akan menjadi kode utama kita untuk objek dan pengendali baru.
Hanya ada satu cmd/manager/main.go file dalam cmd/manager/main.go .
Cuplikan kode // Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
Di baris pertama: err = leader.Become(ctx, "config-monitor-lock") - seorang pemimpin dipilih. Dalam sebagian besar skenario, hanya satu instance aktif pernyataan di namespace / cluster yang diperlukan. Secara default, Operator SDK menggunakan strategi Leader for life - instance yang diluncurkan pertama dari operator akan tetap menjadi pemimpin sampai dihapus dari cluster.
Setelah instance operator ini ditunjuk sebagai pemimpin, Manager baru diinisialisasi - mgr, err := manager.New(...) . Tanggung jawabnya meliputi:
err := apis.AddToScheme(mgr.GetScheme()) - pendaftaran skema sumber daya baru;err := controller.AddToManager(mgr) - pendaftaran pengendali;err := mgr.Start(signals.SetupSignalHandler()) - luncurkan dan kendalikan pengontrol.
Saat ini, kami tidak memiliki sumber daya baru, atau pengontrol untuk pendaftaran. Anda dapat menambahkan sumber daya baru menggunakan perintah:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
Perintah ini akan menambahkan definisi skema sumber daya MonitoredService ke direktori pkg/apis , serta yaml dengan definisi CRD di deploy/crds . Dari semua file yang dihasilkan, Anda hanya perlu mengubah definisi skema secara manual di monitoredservice_types.go . Tipe MonitoredServiceSpec mendefinisikan status sumber daya yang diinginkan: apa yang ditentukan pengguna dalam yaml dengan definisi sumber daya. Dalam konteks operator kami, bidang Size menentukan jumlah replika yang diinginkan, ConfigRepo menunjukkan dari mana konfigurasi saat ini dapat ditarik. MonitoredServiceStatus menentukan keadaan sumber daya yang diamati, misalnya, ia menyimpan nama-nama Pods yang dimiliki sumber daya ini dan Pods spec saat ini.
Setelah mengedit skema, Anda perlu menjalankan perintah:
operator-sdk generate k8s
Ini akan memperbarui definisi CRD di deploy/crds .
Sekarang mari kita buat bagian utama dari operator kami, controller:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
File monitor_controller.go akan muncul di monitor_controller.go pkg/controller , di mana kita menambahkan logika yang kita butuhkan.
Pengembangan Kontroler
Pengontrol adalah unit kerja utama operator. Dalam kasus kami, ada dua pengontrol:
- Kontroler monitor memantau perubahan konfigurasi layanan;
- Pengontrol pemutakhiran memperbarui layanan dan mempertahankannya dalam kondisi yang diinginkan.
Pada intinya, controller adalah loop kontrol, memonitor antrian dengan peristiwa berlangganannya dan memprosesnya:
Kontroler baru dibuat dan didaftarkan oleh manajer dalam metode add :
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
Menggunakan metode Watch , kami berlangganan ke acara terkait penciptaan sumber daya baru atau pembaruan Spec dari sumber daya MonitoredService ada:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
Jenis acara dapat dikonfigurasi menggunakan parameter src dan predicates . src menerima objek bertipe Source .
Informer - secara berkala polling apiserver untuk peristiwa yang cocok dengan filter, jika ada peristiwa seperti itu, masukkan ke dalam antrian pengontrol. Di controller-runtime ini adalah pembungkus atas SharedIndexInformer dari client-go .Kind juga merupakan pembungkus lebih dari SharedIndexInformer , tetapi, tidak seperti Informer , itu secara independen membuat contoh informan berdasarkan parameter yang dikirimkan (skema sumber daya yang dipantau).Channel - menerima acara chan event.GenericEvent sebagai parameter, peristiwa yang datang melaluinya ditempatkan dalam antrian pengontrol.
redicates mengharapkan objek yang memenuhi antarmuka Predicate . Bahkan, ini adalah filter tambahan untuk acara, misalnya, saat memfilter UpdateEvent Anda bisa melihat perubahan apa yang dibuat dalam spec sumber daya.
Ketika suatu peristiwa tiba, seorang EventHandler menerimanya - argumen kedua dari metode Watch - yang membungkus peristiwa tersebut dalam format permintaan yang diharapkan oleh Reconciler :
EnqueueRequestForObject - membuat permintaan dengan nama dan namespace objek yang menyebabkan peristiwa;EnqueueRequestForOwner - membuat permintaan dengan data induk objek. Ini diperlukan, misalnya, jika Pod dikontrol sumber daya telah dihapus, dan Anda perlu memulai penggantinya;EnqueueRequestsFromMapFunc - sebagai parameter fungsi map yang menerima acara (dibungkus dengan MapObject ) dan mengembalikan daftar permintaan. Contoh ketika pawang ini diperlukan - ada timer, untuk setiap centang yang Anda butuhkan untuk mengeluarkan konfigurasi baru untuk semua layanan yang tersedia.
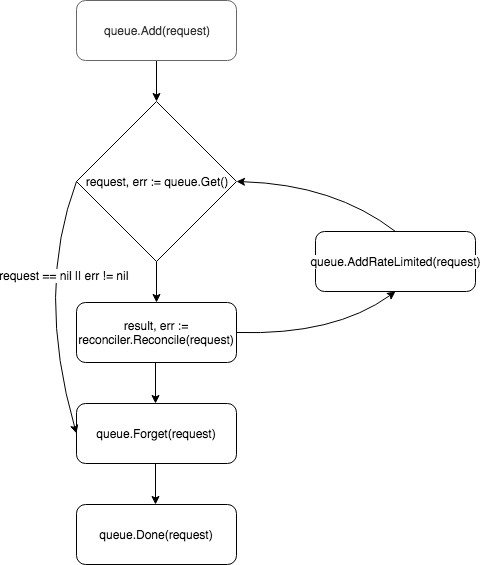
Permintaan ditempatkan di antrian pengontrol, dan salah satu pekerja (secara default pengontrol memiliki satu) menarik peristiwa keluar dari antrian dan meneruskannya ke Reconciler .
Reconciler mengimplementasikan hanya satu metode - Reconcile , yang berisi logika dasar pemrosesan peristiwa:
metode rekonsiliasi func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
Metode menerima objek Request dengan bidang NamespacedName , di mana sumber daya dapat ditarik dari cache: r.client.Get(context.TODO(), request.NamespacedName, instance) . Dalam contoh ini, permintaan dibuat ke file dengan konfigurasi layanan yang dirujuk oleh bidang ConfigRepo dalam spec sumber daya. Jika konfigurasi diperbarui, acara baru dari tipe GenericEvent dan dikirim ke saluran yang didengarkan pengontrol pemutakhiran.
Setelah memproses permintaan, Reconcile mengembalikan objek bertipe Result dan error . Jika bidang Result adalah Requeue: true atau error != nil , controller akan mengembalikan permintaan kembali ke antrian menggunakan metode queue.AddRateLimited . Permintaan akan dikembalikan ke antrian dengan penundaan, yang ditentukan oleh RateLimiter . Secara default, ItemExponentialFailureRateLimiter digunakan, yang meningkatkan waktu tunda secara eksponensial dengan peningkatan jumlah permintaan "pengembalian". Jika bidang Requeue tidak disetel, dan tidak ada kesalahan terjadi selama pemrosesan permintaan, controller akan memanggil metode Queue.Forget , yang akan menghapus permintaan dari cache RateLimiter (dengan demikian mengatur ulang jumlah pengembalian). Pada akhir pemrosesan permintaan, pengontrol menghapusnya dari antrian menggunakan metode Queue.Done .
Peluncuran operator
Komponen operator dijelaskan di atas, dan satu pertanyaan tetap: bagaimana memulainya. Pertama, Anda perlu memastikan bahwa semua sumber daya yang diperlukan sudah diinstal (untuk pengujian lokal, saya sarankan menyiapkan minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
Setelah prasyarat dipenuhi, ada dua cara mudah untuk menjalankan pernyataan untuk pengujian. Cara termudah adalah memulainya di luar cluster menggunakan perintah:
operator-sdk up local --namespace=default
Cara kedua adalah menggunakan operator di cluster. Pertama, Anda perlu membuat gambar Docker dengan operator:
operator-sdk build config-monitor-operator:latest
Dalam file deploy/operator.yaml , ganti REPLACE_IMAGE dengan config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
Buat Penempatan dengan pernyataan:
kubectl create -f deploy/operator.yaml
Sekarang dalam daftar Pod pada cluster akan muncul Pod dengan layanan tes, dan dalam kasus kedua - yang lain dengan operator.
Alih-alih kesimpulan atau praktik terbaik
Masalah utama pengembangan operator saat ini adalah dokumentasi alat yang lemah dan kurangnya praktik terbaik yang ada. Ketika pengembang baru mulai mengembangkan operator, ia tidak punya tempat untuk melihat contoh penerapan persyaratan tertentu, sehingga kesalahan tidak dapat dihindari. Berikut adalah beberapa pelajaran yang kami pelajari dari kesalahan kami:
- Jika ada dua aplikasi terkait, Anda harus menghindari keinginan untuk menggabungkannya dengan satu operator. Jika tidak, prinsip layanan kopling longgar dilanggar.
- Anda harus ingat tentang pemisahan masalah: Anda tidak harus mencoba menerapkan semua logika dalam satu pengontrol. Sebagai contoh, ada baiknya menyebarkan fungsi pemantauan konfigurasi dan membuat / memperbarui sumber daya.
- Memblokir panggilan harus dihindari dalam metode
Reconcile . Misalnya, Anda dapat menarik konfigurasi dari sumber eksternal, tetapi jika operasinya lebih lama, buat goroutine untuk ini, dan kirim permintaan kembali ke antrian, yang menunjukkan dalam respons Requeue: true .
Dalam komentar, akan menarik untuk mendengar tentang pengalaman Anda dalam mengembangkan operator. Dan di bagian selanjutnya kita akan berbicara tentang pengujian operator.