Dengan munculnya banyak arsitektur jaringan saraf yang berbeda, banyak teknik Penglihatan Komputer klasik adalah sesuatu dari masa lalu. Semakin jarang orang menggunakan SIFT dan HOG untuk deteksi objek, dan MBH untuk pengenalan tindakan, dan jika mereka menggunakannya, itu lebih mirip tanda buatan tangan untuk kisi-kisi yang sesuai. Hari ini kita akan melihat salah satu masalah CV klasik di mana metode klasik masih memimpin, sementara arsitektur DL dengan tenang menghirupnya di belakang kepala.

Estimasi aliran optik
Tugas menghitung aliran optik antara dua gambar (biasanya antara frame video yang berdekatan) adalah untuk membangun bidang vektor
ukuran yang sama, apalagi
akan sesuai dengan vektor perpindahan piksel yang tampak
dari frame pertama ke yang kedua. Dengan membuat bidang vektor seperti itu di antara semua bingkai video yang berdekatan, kami mendapatkan gambaran lengkap tentang bagaimana objek tertentu bergerak di atasnya. Dengan kata lain, ini adalah tugas melacak semua piksel dalam video. Aliran optik digunakan sangat luas - dalam tugas-tugas pengenalan tindakan, misalnya, bidang vektor semacam itu memungkinkan Anda untuk berkonsentrasi pada gerakan yang terjadi pada video dan menjauh dari konteksnya [7]. Aplikasi yang bahkan lebih umum adalah odometri visual, kompresi video, pasca-pemrosesan (misalnya, menambahkan efek gerakan lambat) dan banyak lagi.

Ada ruang untuk beberapa ambiguitas - apa sebenarnya yang dianggap bias yang terlihat dari sudut pandang matematika? Biasanya, diasumsikan bahwa nilai piksel berpindah dari satu frame ke frame berikutnya tanpa perubahan, dengan kata lain:
dimana
- Intensitas piksel dalam koordinat
kemudian aliran optik
menunjukkan tempat piksel ini telah pindah ke titik waktu berikutnya (mis., pada frame berikutnya).
Dalam gambar itu terlihat seperti ini:


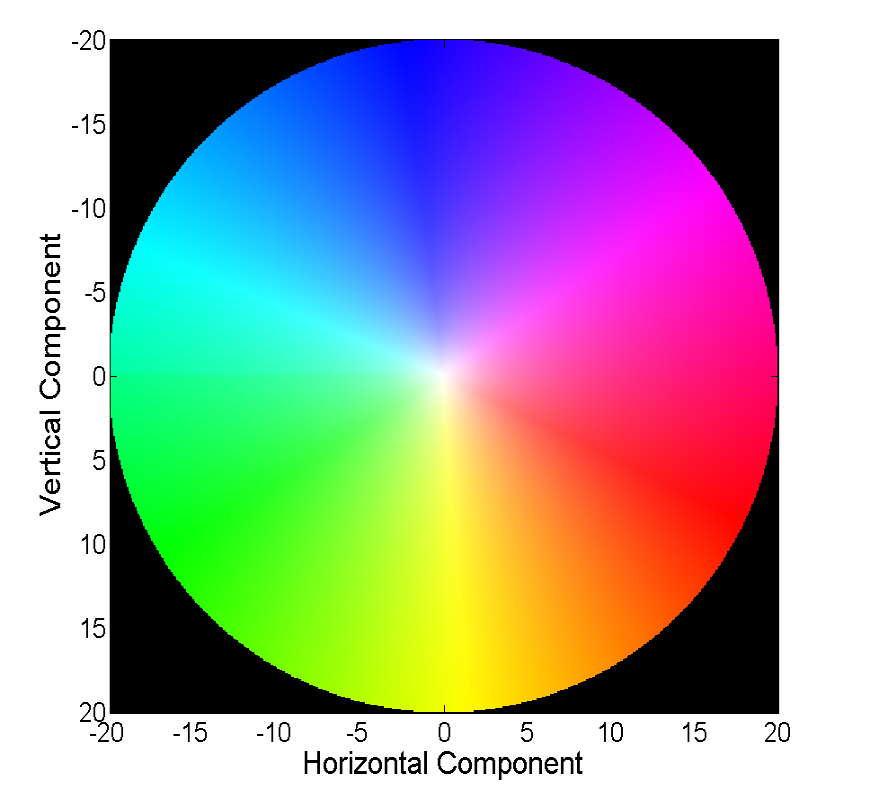
Memvisualisasikan bidang vektor langsung dengan vektor adalah visual, tetapi tidak selalu nyaman, oleh karena itu cara umum kedua adalah memvisualisasikan dengan warna:


Setiap warna dalam gambar ini mengkodekan vektor tertentu. Untuk kesederhanaan, vektor yang lebih dari 20 dipotong, dan vektor itu sendiri dapat dipulihkan dengan warna dari gambar berikut:
Lebih banyak aliran kucing! Metode klasik telah mencapai akurasi yang cukup baik, yang terkadang berbayar. Kami akan mempertimbangkan kemajuan yang dicapai jaringan saraf dalam menyelesaikan masalah ini selama 4 tahun terakhir.
Data dan Metrik
Dua kata tentang dataset mana yang tersedia dan populer di awal cerita kami (yaitu 2015), dan juga bagaimana mereka mengukur kualitas algoritma yang dihasilkan.
Middlebury
Dataset kecil yang terdiri dari 8 pasang gambar dengan offset kecil, yang, bagaimanapun, kadang-kadang digunakan dalam memvalidasi algoritma untuk menghitung fluks optik bahkan sekarang.

Kitty
Ini adalah kumpulan data yang ditandai untuk aplikasi untuk mobil yang dapat menyetir sendiri dan dirakit menggunakan teknologi LIDAR. Ini banyak digunakan untuk memvalidasi algoritma perhitungan aliran optik dan berisi banyak kasus yang agak rumit dengan transisi tajam antar frame.

Sintel
Patokan lain yang sangat umum dibuat atas dasar terbuka dan digambarnya Sintel dalam kartun Blender dalam dua versi, yang ditetapkan sebagai bersih dan final. Yang kedua jauh lebih rumit, karena mengandung banyak efek atmosfer, noise, blur dan masalah lain untuk algoritma untuk menghitung fluks optik.
EPE
Fungsi kesalahan standar untuk tugas perhitungan aliran optik adalah End Point Error atau EPE. Ini hanyalah jarak Euclidean antara algoritma yang dihitung dan fluks optik sejati, yang dirata-rata pada semua piksel.
Flownet (2015)
Ketika memulai pembangunan arsitektur jaringan saraf untuk tugas menghitung fluks optik kembali pada tahun 2015, penulis (dari Universitas Munich dan Freiburg) menghadapi dua masalah: tidak ada dataset bertanda besar untuk tugas ini, dan secara manual menandainya akan sulit (coba tandai di mana saya telah pindah) setiap piksel gambar pada bingkai berikutnya), pertama. Tugas ini sangat berbeda dari semua tugas yang diselesaikan dengan bantuan arsitektur CNN sebelum itu, yang kedua. Sebenarnya, ini adalah tugas regresi piksel-demi-piksel, yang membuatnya mirip dengan tugas segmentasi (klasifikasi piksel-per-piksel), tetapi alih-alih satu gambar, kami memiliki dua input, dan secara intuitif, tanda-tanda tersebut entah bagaimana harus menunjukkan perbedaan antara kedua gambar. Sebagai iterasi pertama, diputuskan untuk hanya menumpuk dua frame RGB sebagai input (setelah menerima, pada kenyataannya, gambar 6-channel), di antaranya kami ingin menghitung aliran optik, dan mengambil U-net sebagai arsitektur dengan sejumlah perubahan. Jaringan ini disebut FlowNetS (S singkatan dari Simple):
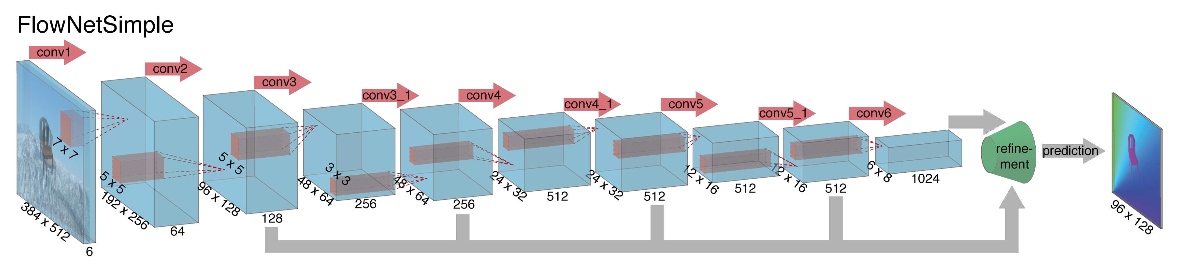
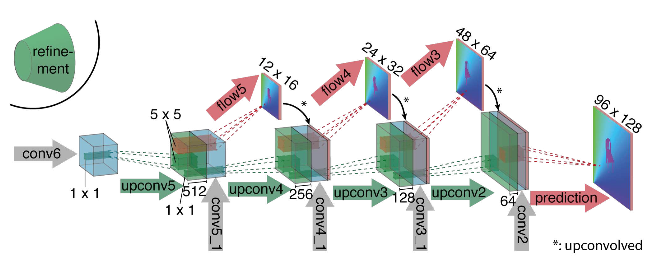
Seperti yang dapat dilihat dari diagram, encoder tidak terlihat dengan cara apa pun, decoder berbeda dari opsi klasik dalam beberapa cara:
- Prediksi aliran optik terjadi tidak hanya dari level terakhir, tetapi juga dari semua yang lain. Untuk mendapatkan Ground Truth untuk tingkat ke-10 dari decoder, target asli (yaitu aliran optik) dikurangi secara sederhana (hampir sama dengan gambar) ke resolusi yang diinginkan, dan predikat yang diperoleh pada tingkat ke-i melangkah lebih jauh, t yaitu, disatukan dengan peta fitur yang muncul dari level ini. Fungsi umum dari kehilangan pelatihan adalah jumlah kerugian dari semua level decoder, sementara bobot itu sendiri akan semakin besar, semakin dekat level ke output jaringan. Para penulis tidak memberikan penjelasan mengapa ini dilakukan, tetapi kemungkinan besar alasannya adalah fakta bahwa gerakan tajam lebih baik untuk dideteksi pada tingkat awal, maka vektor dalam aliran optik resolusi rendah tidak akan begitu besar.
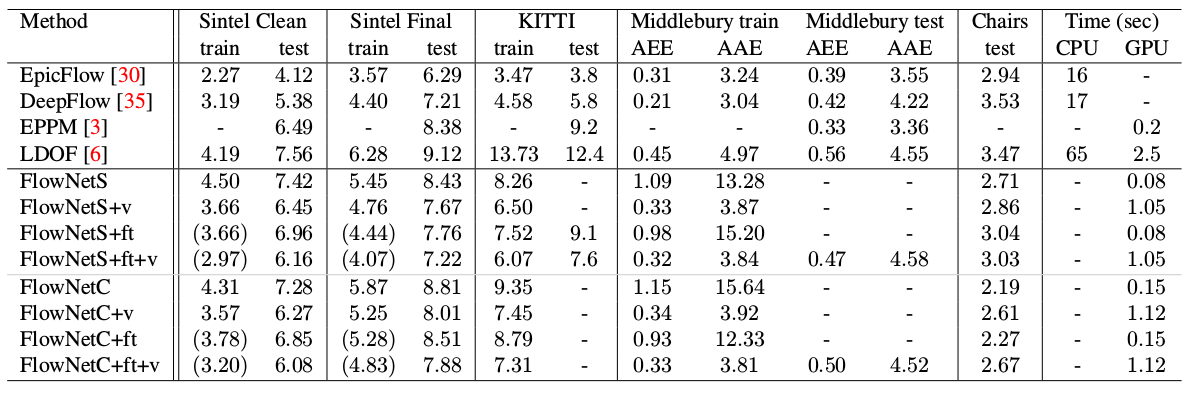
- Diagram menunjukkan bahwa resolusi input gambar adalah 384x512, dan outputnya empat kali lebih kecil. Para penulis memperhatikan bahwa jika Anda meningkatkan output ini menjadi 384x512 dengan interpolasi bilinear sederhana, itu akan memberikan kualitas yang sama seperti jika Anda memasang dua level lagi dari decoder. Anda juga dapat menggunakan pendekatan variasional [2], yang membuktikan kualitas (+ v dalam tabel dengan kualitas).
- Seperti di U-net, kartu atribut dari encoder dikirim ke decoder dan digabungkan seperti yang ditunjukkan pada diagram.

Untuk memahami bagaimana penulis mencoba meningkatkan garis dasar mereka, Anda perlu tahu apa korelasi antara gambar dan mengapa hal itu dapat berguna dalam menghitung fluks optik. Jadi, memiliki dua gambar dan mengetahui bahwa yang kedua adalah frame berikutnya dalam video relatif terhadap yang pertama, kita dapat mencoba membandingkan area di sekitar titik pada frame pertama (yang kita ingin menemukan pergeseran ke frame kedua) dengan area dengan ukuran yang sama di gambar kedua. Selain itu, dengan anggapan bahwa shift tidak boleh terlalu besar per unit waktu, perbandingan hanya dapat dipertimbangkan di lingkungan tertentu dari titik awal. Untuk ini, korelasi silang digunakan. Mari kita ilustrasikan dengan sebuah contoh.
Ambil dua frame video yang berdekatan, kami ingin menentukan di mana titik tertentu telah bergeser dari frame pertama ke yang kedua. Misalkan beberapa area di sekitar titik ini telah bergeser dengan cara yang sama. Memang, piksel tetangga dalam video biasanya diimbangi bersama, seperti kemungkinan besar, secara visual, adalah bagian dari satu objek. Asumsi ini digunakan secara aktif, misalnya, dalam pendekatan diferensial, yang dapat dibaca secara lebih rinci dalam [5], [6].
fig, ax = plt.subplots(1, 2, figsize=(20, 10)) ax[0].imshow(frame1) ax[1].imshow(frame2);

Mari kita coba mengambil titik di tengah cakar kucing dan menemukannya di bingkai kedua. Ambil beberapa area di sekitarnya.
patch1 = frame1[90:190, 140:250] plt.imshow(patch1);

Kami menghitung korelasi antara area ini (dalam literatur bahasa Inggris sering menulis template atau patch dari gambar pertama) dan gambar kedua. Template hanya akan "berjalan" melalui gambar kedua dan menghitung nilai berikut antara dirinya dan potongan-potongan dengan ukuran yang sama pada gambar kedua:
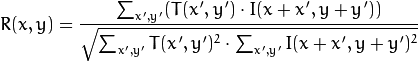
Semakin besar nilai dari nilai ini, semakin banyak template yang terlihat seperti bagian yang sesuai pada gambar kedua. Dengan OpenCV, ini dapat dilakukan seperti ini:
corr = cv2.matchTemplate(frame2, patch1, cv2.TM_CCORR_NORMED) plt.imshow(corr, cmap='gray');
Rincian lebih lanjut dapat ditemukan di [7].
Hasilnya adalah sebagai berikut:
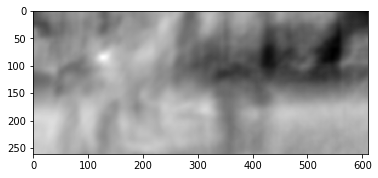
Kami melihat puncak yang jelas, ditunjukkan dengan warna putih. Temukan di bingkai kedua:
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(corr) h, w, _ = patch1.shape top_left = max_loc bottom_right = (top_left[0] + w, top_left[1] + h) frame2_copy = frame2.copy() cv2.rectangle(frame2_copy, top_left, bottom_right, 255, 2) plt.imshow(frame2_copy);

Kita melihat bahwa kaki ditemukan dengan benar, menurut data ini kita dapat memahami ke arah mana ia bergerak dari frame pertama ke frame kedua dan menghitung fluks optik yang sesuai. Selain itu, ternyata operasi ini cukup tahan terhadap distorsi fotometrik, mis. jika kecerahan pada frame kedua meningkat tajam, puncak korelasi silang antara gambar akan tetap ada.
Mempertimbangkan semua hal di atas, penulis memutuskan untuk memperkenalkan apa yang disebut layer korelasi ke dalam arsitektur mereka, tetapi diputuskan untuk tidak mempertimbangkan korelasi sesuai dengan gambar input, tetapi menurut atribut peta setelah beberapa lapisan encoder. Lapisan seperti itu, untuk alasan yang jelas, tidak memiliki parameter pembelajaran, meskipun esensinya mirip dengan konvolusi, tetapi alih-alih filter, di sini kami tidak menggunakan bobot, tetapi beberapa area pada gambar kedua:
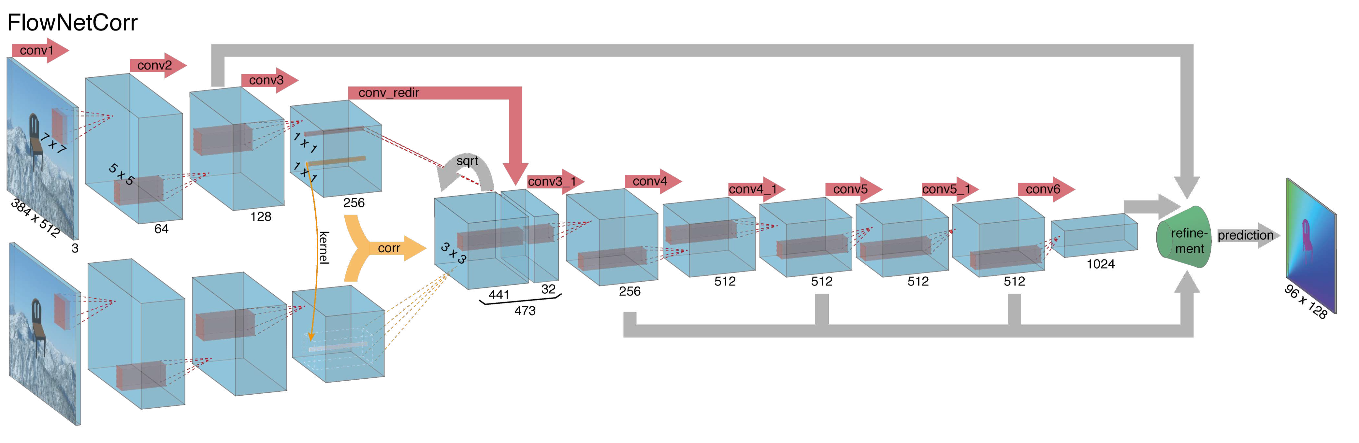
Anehnya, trik ini tidak memberikan peningkatan yang signifikan dalam kualitas penulis artikel ini, namun, itu lebih berhasil diterapkan dalam pekerjaan lebih lanjut, dan pada [9] penulis dapat menunjukkan bahwa dengan sedikit mengubah parameter pelatihan, FlowNetC dapat dibuat bekerja lebih baik.
Para penulis memecahkan masalah dengan kurangnya dataset dengan cara yang agak elegan: mereka menggores 964 gambar dari Flickr pada tema: "kota", "lanskap", "gunung" dalam resolusi 1024 × 768 dan menggunakan tanaman mereka 512x384 sebagai latar belakang, yang kemudian melemparkan beberapa gambar. kursi dari set terbuka model 3D yang diberikan. Kemudian, berbagai transformasi affine diterapkan secara independen pada kursi dan latar belakang, yang digunakan untuk menghasilkan gambar kedua dalam pasangan dan aliran optik di antara mereka. Hasilnya adalah sebagai berikut:

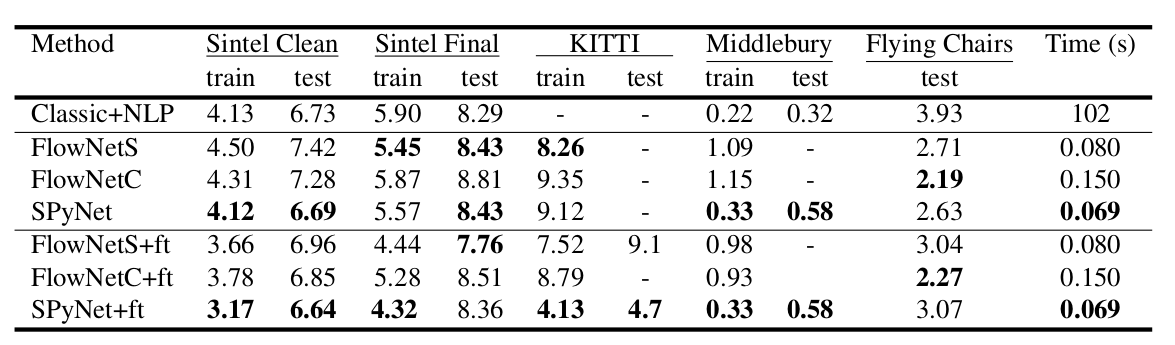
Hasil yang menarik adalah bahwa penggunaan set data sintetis memungkinkan untuk mencapai kualitas yang relatif baik untuk data dari domain lain. Penyesuaian yang baik pada data yang sesuai, tentu saja, membuktikan lebih banyak kualitas (+ ft dalam tabel di bawah):
Hasil pada video nyata dapat dilihat di sini:
SpyNet (2016)
Dalam banyak artikel berikutnya, penulis mencoba meningkatkan kualitas dengan memecahkan masalah buruknya pengenalan gerakan tiba-tiba. Secara intuitif, gerakan tidak akan ditangkap oleh jaringan jika vektornya secara signifikan melampaui bidang aktivasi reseptif. Diusulkan untuk menyelesaikan masalah ini karena tiga hal: konvolusi yang lebih besar, piramida dan "melengkungkan" satu gambar dari sepasang ke dalam aliran optik. Semuanya beres.
Jadi, jika kita memiliki beberapa gambar yang objeknya telah bergeser dengan tajam (10+ piksel), maka kita cukup mengurangi gambar (sebanyak 6 kali atau lebih). Nilai absolut dari offset akan berkurang secara signifikan, dan jaringan lebih mungkin untuk “menangkapnya”, terutama jika konvolusinya lebih besar daripada offset itu sendiri (dalam hal ini, konvolusi 7x7 digunakan).
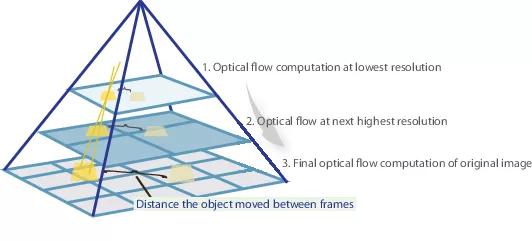
Namun, ketika mengurangi gambar, kami kehilangan banyak detail penting, jadi kami harus pergi ke tingkat piramida berikutnya, di mana ukuran gambar sudah lebih besar, sementara entah bagaimana memperhitungkan informasi yang kami terima sebelumnya ketika kami menghitung fluks optik pada ukuran yang lebih kecil. Ini dilakukan dengan menggunakan operator warping, yang menghitung ulang gambar pertama sesuai dengan perkiraan fluks optik yang tersedia (diperoleh pada tingkat sebelumnya). Peningkatan dalam hal ini adalah bahwa gambar pertama yang "didorong" sesuai dengan perkiraan fluks optik akan lebih dekat dengan yang kedua daripada yang asli, yaitu, kita kembali mengurangi nilai absolut fluks optik, yang perlu kita prediksi (ingat, nilainya kecil) gerakan terdeteksi jauh lebih baik, karena mereka benar-benar termasuk dalam satu konvolusi). Dari sudut pandang matematika, memiliki gambar bitmap I dan perkiraan fluks optik V, operator warping dapat digambarkan sebagai berikut:
dimana
, yaitu titik tertentu pada gambar
- gambar itu sendiri
- aliran optik
- gambar yang dihasilkan, "dibungkus" dalam aliran optik.
Bagaimana cara menerapkan semua ini dalam arsitektur CNN? Kami memperbaiki jumlah level piramida
dan faktor di mana setiap gambar berikutnya dikurangi pada level mulai dari yang terakhir
. Ditunjukkan oleh
dan
fungsi downsampling dan upsampling dari gambar atau fluks optik oleh faktor ini.
Kami juga akan mendapatkan satu set CNN-ok {
}, satu untuk setiap tingkat piramida. Lalu
jaringan -th akan menerima beberapa gambar dengan
tingkat piramida dan fluks optik dihitung pada
level (
hanya akan menerima tensor nol saja). Dalam hal ini, kami akan mengirim salah satu gambar ke lapisan warping untuk mengurangi perbedaan di antara mereka, dan kami tidak akan memprediksi fluks optik pada level ini, tetapi nilai yang perlu ditambahkan ke fluks optik meningkat (di-upample) dari level sebelumnya untuk mendapatkan fluks optik. di level ini. Dalam rumus, itu terlihat seperti ini:
Untuk mendapatkan stream optik itu sendiri, kami cukup menambahkan predikat jaringan dan peningkatan stream dari level sebelumnya:
Untuk mendapatkan Ground Truth untuk jaringan pada level ini, kita perlu melakukan operasi yang berlawanan - kurangi predikat dari target (dikurangi ke level yang diinginkan) dari level piramida sebelumnya. Secara skematis, tampilannya seperti ini:

Keuntungan dari pendekatan ini adalah kita dapat mengajar setiap level secara mandiri. Para penulis mulai pelatihan dari level 0, setiap jaringan berikutnya diinisialisasi dengan parameter yang sebelumnya. Karena setiap jaringan
Memecahkan masalah lebih sederhana daripada perhitungan penuh fluks optik dalam gambar besar, maka parameter dapat dibuat lebih sedikit. Sedemikian rupa sehingga sekarang seluruh ansambel dapat ditampung di perangkat seluler:

Ensembel itu sendiri adalah sebagai berikut (contoh piramida 3 tingkat):
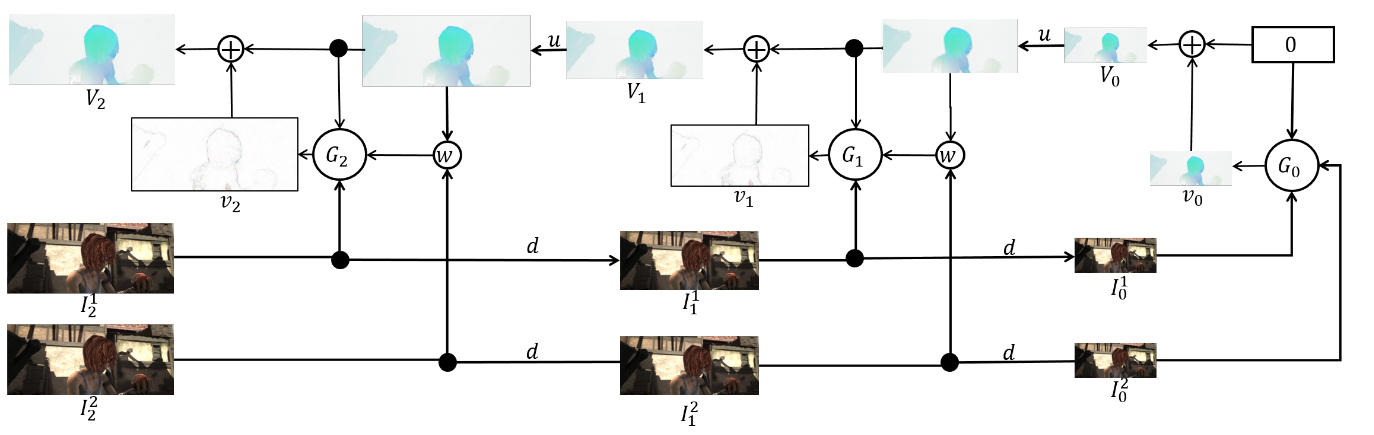
Masih berbicara langsung tentang arsitektur
jaringan dan mengambil stok. Setiap jaringan
terdiri dari 5 lapisan konvolusional, yang masing-masing berakhir dengan aktivasi ReLU, kecuali yang terakhir (yang memprediksi aliran optik). Jumlah filter pada setiap lapisan adalah masing-masing {
}. Input dari jaringan saraf (gambar, gambar kedua "dibungkus" dalam aliran optik dan aliran optik itu sendiri) hanya digabungkan sesuai dengan dimensi saluran, sehingga tensor input mereka memiliki 8. Hasilnya mengesankan:
PWC-Net (2018)
Terinspirasi oleh keberhasilan rekan-rekan Jerman mereka, orang-orang dari NVIDIA memutuskan untuk menerapkan pengalaman mereka (dan kartu video) untuk lebih meningkatkan hasilnya. Pekerjaan mereka sebagian besar didasarkan pada ide-ide dari model sebelumnya (SpyNet), sehingga PWC-Net juga akan menangani piramida, tetapi dengan piramida konvolusi, bukan gambar asli, namun, lagi-lagi - secara berurutan.
Menggunakan intensitas piksel mentah untuk menghitung fluks optik tidak selalu masuk akal, karena Perubahan tajam dalam kecerahan / kontras akan mematahkan asumsi kami bahwa piksel bergerak dari satu frame ke frame berikutnya tanpa perubahan dan algoritma tidak akan tahan terhadap perubahan tersebut. Dalam algoritma klasik untuk menghitung fluks optik, berbagai transformasi digunakan untuk mengurangi situasi ini, dalam hal ini, penulis memutuskan untuk memberikan kesempatan kepada model untuk mempelajari transformasi tersebut. Oleh karena itu, alih-alih piramida gambar di PWC-Net, piramida konvolusi digunakan (maka huruf pertama dalam Pwc-Net), yaitu. cukup fitur peta dari berbagai lapisan CNN, yang disebut ekstraktor fitur piramida di sini.
Maka semuanya hampir seperti di SpyNet, tepat sebelum Anda mengirim ke CNN, yang disebut pengukur aliran optik, semua yang Anda butuhkan, yaitu:
- gambar (dalam hal ini, peta fitur dari ekstraktor piramida fitur),
- fluks optik up-sampel yang dihitung pada tingkat sebelumnya,
- gambar kedua, "dibungkus" (ingat lapisan melengkung, maka huruf kedua di pWc-Net) ke dalam aliran optik ini,
antara frame kedua "terbungkus" dan yang biasa pertama (sekali lagi saya ingatkan Anda bahwa alih-alih gambar mentah, kartu fitur dengan ekstraktor piramida digunakan di sini) mempertimbangkan apa yang disebut volume biaya (maka huruf ketiga di pwC-Net) dan yang pada dasarnya sudah sebelumnya dianggap korelasi antara dua gambar.
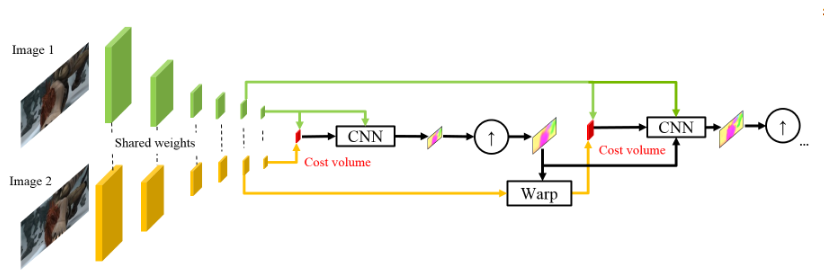
Sentuhan terakhir adalah jaringan konteks, yang ditambahkan segera setelah estimator aliran optik dan memainkan peran pasca-pemrosesan terlatih untuk aliran optik yang dihitung. Detail arsitektur dapat dilihat di bawah spoiler atau di artikel asli.
Detail intimJadi, fitur piramid extractor memiliki bobot yang sama untuk kedua gambar, ReLU bocor digunakan sebagai non-linearitas untuk setiap konvolusi. Untuk mengurangi resolusi peta fitur pada setiap tingkat berikutnya, konvolusi dengan langkah 2 digunakan, dan
berarti peta fitur gambar
di tingkat
.

Pengukur aliran optis pada tingkat kedua piramida (misalnya). Tidak ada yang aneh di sini, setiap belitan masih berakhir dengan ReLU yang bocor, kecuali yang terakhir, yang memprediksi aliran optik.

Jaringan konteks masih pada tingkat piramida yang sama, jaringan ini menggunakan konvolusi melebar dengan aktivasi ReLU bocor yang sama, kecuali untuk lapisan terakhir. Ini menerima aliran optik yang dihitung oleh pengukur aliran optik dan atribut dari lapisan kedua dari ujung lapisan dengan pengukur aliran optik yang sama. Digit terakhir di setiap blok berarti pelebaran konstan.

Hasilnya bahkan lebih mengesankan:
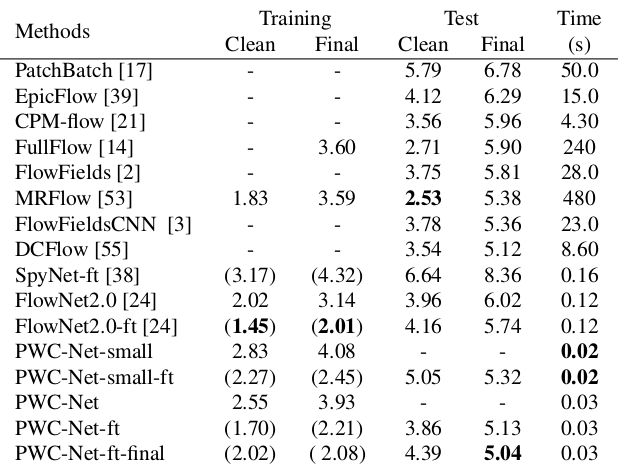
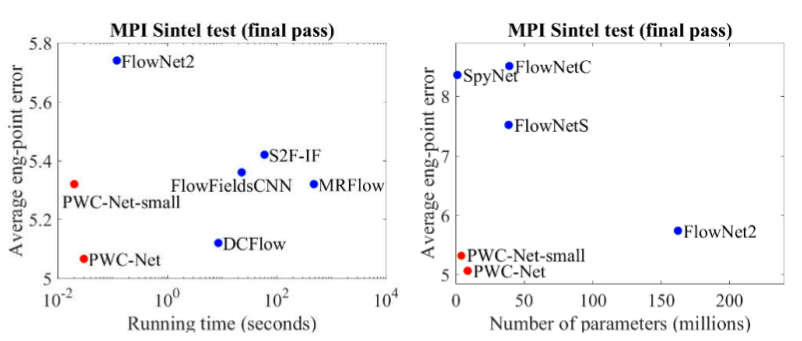
Dibandingkan dengan metode CNN lain untuk menghitung aliran optik, PWC-Net mencapai keseimbangan antara kualitas dan jumlah parameter:
Ada juga presentasi yang sangat baik oleh penulis sendiri, di mana mereka berbicara tentang model itu sendiri dan eksperimen mereka:
Kesimpulan
Evolusi arsitektur yang memecahkan masalah penghitungan fluks optik adalah contoh yang bagus tentang bagaimana kemajuan dalam arsitektur CNN dan menggabungkannya dengan metode klasik memberikan hasil terbaik dan terbaik. Dan sementara metode CV klasik masih menang dalam kualitas, hasil terbaru memberi harapan bahwa ini dapat diperbaiki ...
Sumber dan tautan
1. FlowNet: Belajar Aliran Optik dengan Jaringan Konvolusional:
artikel ,
kode .
2. Aliran optik perpindahan besar: pencocokan deskriptor dalam estimasi gerakan variasional:
artikel .
3. Estimasi Aliran Optik menggunakan Jaringan Spasial Piramida:
artikel ,
kode .
4. PWC-Net: CNN untuk Aliran Optik Menggunakan Piramida, Warping, dan Volume Biaya:
artikel ,
kode .
5. Apa yang ingin Anda ketahui tentang aliran optik, tetapi malu untuk bertanya:
artikel .
6. Perhitungan fluks optik dengan metode Lucas-Kanada. Teori:
artikel .
7. Pencocokan template dengan OpenCVP:
dock .
8. Quo Vadis, Pengakuan Aksi? Model Baru dan Kumpulan Data Kinetika:
artikel .
9. FlowNet 2.0: Evolusi Estimasi Aliran Optik dengan Deep Networks:
artikel ,
kode .