Pemrosesan bahasa alami sekarang tidak digunakan kecuali di sektor yang sangat konservatif. Dalam sebagian besar solusi teknologi, pengenalan dan pemrosesan bahasa "manusia" telah lama diperkenalkan: itulah sebabnya IVR biasa dengan opsi respons yang dikodekan secara bertahap menjadi sesuatu di masa lalu, obrolan mulai berkomunikasi secara lebih memadai tanpa partisipasi dari operator langsung, filter surat bekerja dengan keras, dll. Bagaimana pengakuan ucapan yang direkam, yaitu, teks? Atau lebih tepatnya, apa yang akan menjadi dasar pengakuan modern dan teknik pemrosesan? Terjemahan kami yang disesuaikan hari ini merespon dengan baik terhadap hal ini - di bawah potongan Anda akan menemukan longride yang akan menutup celah pada dasar-dasar NLP. Selamat membaca!
Apa itu pemrosesan bahasa alami?
Natural Language Processing (selanjutnya disebut - NLP) - pemrosesan bahasa alami adalah subbagian dari ilmu komputer dan AI yang ditujukan untuk bagaimana komputer menganalisis bahasa alami (manusia). NLP memungkinkan penggunaan algoritma pembelajaran mesin untuk teks dan ucapan.
Misalnya, kita dapat menggunakan NLP untuk membuat sistem seperti pengenalan ucapan, generalisasi dokumen, terjemahan mesin, deteksi spam, pengakuan entitas yang disebutkan, jawaban atas pertanyaan, lengkapi-otomatis, input teks prediktif, dll.
Saat ini, banyak dari kita memiliki smartphone pengenal ucapan - mereka menggunakan NLP untuk memahami pembicaraan kita. Juga, banyak orang menggunakan laptop dengan pengenalan suara bawaan di OS.
Contohnya
Cortana
Windows memiliki asisten virtual Cortana yang mengenali ucapan. Dengan Cortana, Anda dapat membuat pengingat, membuka aplikasi, mengirim surat, bermain game, mencari tahu cuaca, dll.
Siri
Siri adalah asisten untuk OS Apple: iOS, watchOS, macOS, HomePod, dan tvOS. Banyak fungsi juga bekerja melalui kontrol suara: memanggil / menulis seseorang, mengirim email, mengatur timer, mengambil foto, dll.
Gmail
Layanan email terkenal tahu cara mendeteksi spam sehingga tidak masuk ke kotak masuk kotak masuk Anda.
Dialogflow
Platform dari Google yang memungkinkan Anda membuat bot NLP. Misalnya, Anda dapat membuat bot pemesanan pizza
yang tidak memerlukan IVR kuno untuk menerima pesanan Anda .
Perpustakaan Python NLTK
NLTK (Natural Language Toolkit) adalah platform terkemuka untuk membuat program NLP dengan Python. Ini memiliki antarmuka yang mudah digunakan untuk banyak
korps bahasa , serta perpustakaan untuk pengolah kata untuk klasifikasi, tokenization,
stemming ,
markup , filtering dan
penalaran semantik . Nah, dan ini adalah proyek open source gratis yang sedang dikembangkan dengan bantuan masyarakat.
Kami akan menggunakan alat ini untuk menunjukkan dasar-dasar NLP. Untuk semua contoh berikutnya, saya berasumsi bahwa NLTK sudah diimpor; ini dapat dilakukan dengan perintah
import nltkDasar-Dasar NLP untuk Teks
Pada artikel ini kita akan membahas topik:
- Tokenisasi dengan penawaran.
- Tokenisasi dengan kata-kata.
- Lekatkan dan cap teks.
- Hentikan kata-kata.
- Ekspresi reguler.
- Tas kata-kata .
- TF-IDF .
1. Tokenisasi dengan penawaran
Tokenisasi (terkadang segmentasi) kalimat adalah proses membagi bahasa tertulis menjadi kalimat komponen. Idenya terlihat sangat sederhana. Dalam bahasa Inggris dan beberapa bahasa lain, kita dapat mengisolasi sebuah kalimat setiap kali kita menemukan tanda baca tertentu - suatu periode.
Tetapi bahkan dalam bahasa Inggris tugas ini tidak sepele, karena intinya juga digunakan dalam singkatan. Tabel singkatan dapat sangat membantu selama pemrosesan kata untuk menghindari kesalahan penempatan batas kalimat. Dalam kebanyakan kasus, perpustakaan digunakan untuk ini, jadi Anda tidak perlu khawatir tentang detail implementasi.
Contoh:Ambil teks singkat tentang permainan papan backgammon:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Untuk membuat tokenization penawaran menggunakan NLTK, Anda dapat menggunakan metode
nltk.sent_tokenize | text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
Di pintu keluar, kami mendapatkan 3 kalimat terpisah:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. Tokenisasi menurut kata-kata
Tokenisasi (terkadang segmentasi) menurut kata-kata adalah proses membagi kalimat menjadi kata-kata komponen. Dalam bahasa Inggris dan banyak bahasa lain yang menggunakan satu atau beberapa versi lain dari alfabet Latin, spasi adalah pemisah kata yang baik.
Namun, masalah dapat muncul jika kita hanya menggunakan spasi - dalam bahasa Inggris, kata benda majemuk ditulis secara berbeda dan terkadang dipisahkan oleh spasi. Dan di sini perpustakaan membantu kami lagi.
Contoh:Mari kita ambil kalimat dari contoh sebelumnya dan terapkan metode
nltk.word_tokenize padanya
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
Kesimpulan:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. Lemmatization dan stamping teks
Biasanya teks berisi bentuk tata bahasa yang berbeda dari kata yang sama, dan kata satu-akar juga dapat terjadi. Lemmatization dan stemming bertujuan untuk membawa semua bentuk kata yang ada ke bentuk kosakata tunggal yang normal.
Contoh:Membawa berbagai bentuk kata ke satu:
dog, dogs, dog's, dogs' => dog
Hal yang sama, tetapi dengan merujuk pada keseluruhan kalimat:
the boy's dogs are different sizes => the boy dog be differ size
Lemmatization dan stemming adalah kasus khusus normalisasi dan mereka berbeda.
Stemming adalah proses heuristik kasar yang memotong "kelebihan" dari akar kata-kata, sering kali ini menyebabkan hilangnya sufiks pembangun kata.
Lemmatization adalah proses yang lebih halus yang menggunakan kosakata dan analisis morfologis untuk akhirnya membawa kata ke bentuk kanonik - lemma.
Perbedaannya adalah bahwa stemmer (implementasi spesifik dari algoritma stemming - komentar penerjemah) beroperasi tanpa mengetahui konteksnya dan, karenanya, tidak memahami perbedaan antara kata-kata yang memiliki arti yang berbeda tergantung pada bagian pembicaraan. Namun, Stemmers memiliki kelebihannya sendiri: mereka lebih mudah diimplementasikan dan mereka bekerja lebih cepat. Plus, "akurasi" yang lebih rendah mungkin tidak masalah dalam beberapa kasus.
Contoh:- Kata baik adalah lemma untuk kata yang lebih baik. Stemmer tidak akan melihat koneksi ini, karena di sini Anda perlu berkonsultasi dengan kamus.
- Kata bermain adalah bentuk dasar dari kata bermain. Di sini stemming dan lemmatization akan mengatasinya.
- Kata meeting dapat berupa bentuk normal dari kata benda atau bentuk kata kerja untuk bertemu, tergantung pada konteksnya. Tidak seperti stemming, lemmatization akan mencoba untuk memilih lemma yang tepat berdasarkan konteks.
Sekarang kita tahu apa perbedaannya, mari kita lihat sebuah contoh:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
Kesimpulan:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. Hentikan kata-kata
Stop kata adalah kata-kata yang dibuang dari teks sebelum / sesudah pemrosesan teks. Saat kami menerapkan pembelajaran mesin pada teks, kata-kata seperti itu dapat menambah banyak gangguan, jadi Anda harus menyingkirkan kata-kata yang tidak relevan.
Stop kata biasanya dipahami oleh artikel, kata seru, serikat pekerja, dll, yang tidak membawa beban semantik. Harus dipahami bahwa tidak ada daftar universal kata-kata berhenti, semuanya tergantung pada kasus tertentu.
NLTK memiliki daftar kata berhenti yang telah ditentukan. Sebelum digunakan pertama kali, Anda harus mengunduhnya:
nltk.download(“stopwords”) . Setelah mengunduh, Anda dapat mengimpor paket
stopwords dan melihat kata-katanya sendiri:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
Kesimpulan:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Pertimbangkan bagaimana Anda dapat menghapus kata berhenti dari sebuah kalimat:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
Kesimpulan:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Jika Anda tidak terbiasa dengan pemahaman daftar, Anda dapat mencari tahu lebih lanjut di
sini . Berikut ini cara lain untuk mencapai hasil yang sama:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
Namun, ingatlah bahwa pemahaman daftar lebih cepat karena mereka dioptimalkan - penerjemah mengungkapkan pola prediksi selama loop.
Anda mungkin bertanya mengapa kami mengubah daftar menjadi
banyak . Set adalah tipe data abstrak yang dapat menyimpan nilai unik dalam urutan yang tidak ditentukan. Pencarian dengan set jauh lebih cepat daripada mencari melalui daftar. Untuk sejumlah kecil kata, ini tidak masalah, tetapi jika kita berbicara tentang sejumlah besar kata, maka sangat disarankan untuk menggunakan set. Jika Anda ingin tahu lebih banyak tentang waktu yang diperlukan untuk melakukan berbagai operasi, lihat
lembar contekan yang indah ini .
5. Ekspresi reguler.
Ekspresi reguler (regex, regexp, regex) adalah urutan karakter yang menentukan pola pencarian. Sebagai contoh:
- . - karakter apa pun kecuali umpan baris;
- satu kata;
- \ d - satu digit;
- \ s - satu ruang;
- \ W adalah satu NON-Word;
- \ D - satu non-digit;
- \ S - satu non-ruang;
- [abc] - menemukan salah satu karakter yang ditentukan cocok dengan a, b, atau c;
- [^ abc] - menemukan karakter apa pun kecuali yang ditentukan;
- [ag] - Menemukan karakter dalam kisaran dari a hingga g.
Kutipan dari
dokumentasi Python :
Ekspresi reguler menggunakan garis miring terbalik (\) untuk menunjukkan bentuk khusus atau untuk memungkinkan penggunaan karakter khusus. Ini bertentangan dengan penggunaan backslash dengan Python: misalnya, untuk benar-benar menunjukkan backslash, Anda harus menulis '\\\\' sebagai pola pencarian, karena ekspresi reguler akan terlihat seperti \\ , di mana setiap backslash harus melarikan diri.
Solusinya adalah menggunakan notasi string mentah untuk pola pencarian; garis miring terbalik tidak akan diproses secara khusus jika digunakan dengan awalan 'r' . Dengan demikian, r”\n” adalah string dengan dua karakter ('\' 'n') , dan “\n” adalah string dengan satu karakter (umpan baris).
Kita dapat menggunakan pelanggan tetap untuk memfilter teks kita lebih lanjut. Misalnya, Anda dapat menghapus semua karakter yang bukan kata-kata. Dalam banyak kasus, tanda baca tidak diperlukan dan mudah dihapus dengan bantuan pelanggan tetap.
Modul
re dengan Python mewakili operasi ekspresi reguler. Kita dapat menggunakan fungsi
re.sub untuk mengganti semua yang sesuai dengan pola pencarian dengan string yang ditentukan. Jadi, Anda dapat mengganti semua non-kata dengan spasi:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
Kesimpulan:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Reguler adalah alat yang ampuh yang dapat digunakan untuk membuat pola yang jauh lebih kompleks. Jika Anda ingin tahu lebih banyak tentang ekspresi reguler, maka saya dapat merekomendasikan 2 aplikasi web ini:
regex ,
regex101 .
6. Tas kata-kata
Algoritma pembelajaran mesin tidak dapat secara langsung bekerja dengan teks mentah, jadi Anda perlu mengonversi teks menjadi sekumpulan angka (vektor). Ini disebut
ekstraksi fitur .
Kantong kata adalah teknik ekstraksi fitur populer dan sederhana yang digunakan saat bekerja dengan teks. Ini menggambarkan kemunculan setiap kata dalam teks.
Untuk menggunakan model, kita perlu:
- Tetapkan kamus kata yang dikenal (token).
- Pilih tingkat kehadiran kata-kata terkenal.
Setiap informasi tentang susunan atau struktur kata-kata diabaikan. Itu sebabnya disebut TAS kata-kata. Model ini mencoba memahami apakah kata yang dikenal muncul di dokumen, tetapi tidak tahu di mana tepatnya kata itu muncul.
Intuition menyarankan bahwa
dokumen serupa memiliki
konten yang serupa . Juga, berkat kontennya, kita dapat mempelajari sesuatu tentang arti dokumen tersebut.
Contoh:Pertimbangkan langkah-langkah untuk membuat model ini. Kami hanya menggunakan 4 kalimat untuk memahami cara kerja model. Dalam kehidupan nyata, Anda akan menemukan lebih banyak data.
1. Unduh data
Bayangkan ini adalah data kami dan kami ingin memuatnya sebagai sebuah array:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Untuk melakukan ini, cukup baca file dan bagi dengan baris:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
Kesimpulan:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. Tetapkan kamus
Kami akan mengumpulkan semua kata-kata unik dari 4 kalimat yang dimuat, mengabaikan huruf besar, tanda baca dan token satu karakter. Ini akan menjadi kamus kami (kata-kata terkenal).
Untuk membuat kamus, Anda bisa menggunakan kelas
CountVectorizer dari perpustakaan sklearn. Lanjutkan ke langkah berikutnya.
3. Buat vektor dokumen
Selanjutnya, kita perlu mengevaluasi kata-kata dalam dokumen. Pada langkah ini, tujuan kami adalah mengubah teks mentah menjadi satu set angka. Setelah itu, kami menggunakan set ini sebagai input ke model pembelajaran mesin. Metode penilaian yang paling sederhana adalah mencatat keberadaan kata, yaitu, beri 1 jika ada kata dan 0 jika tidak ada.
Sekarang kita dapat membuat sekumpulan kata-kata menggunakan kelas CountVectorizer yang disebutkan di atas.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
Kesimpulan:
Ini adalah saran kami. Sekarang kita melihat bagaimana model “bag of words” bekerja.
Beberapa kata tentang kantong kata-kata
Kompleksitas model ini adalah bagaimana menentukan kamus dan bagaimana cara menghitung kemunculan kata-kata.
Ketika ukuran kamus meningkat, vektor dokumen juga tumbuh. Pada contoh di atas, panjang vektor sama dengan jumlah kata yang dikenal.
Dalam beberapa kasus, kita dapat memiliki jumlah data yang sangat besar dan kemudian vektor dapat terdiri dari ribuan atau jutaan elemen. Selain itu, setiap dokumen hanya dapat berisi sebagian kecil dari kata-kata dari kamus.
Akibatnya, akan ada banyak nol dalam representasi vektor. Vektor dengan banyak nol disebut vektor jarang, mereka memerlukan lebih banyak memori dan sumber daya komputasi.
Namun, kita dapat mengurangi jumlah kata yang dikenal saat kita menggunakan model ini untuk mengurangi tuntutan pada sumber daya komputasi. Untuk melakukan ini, Anda dapat menggunakan teknik yang sama yang sudah kami pertimbangkan sebelum membuat sekumpulan kata:
- mengabaikan kata-kata;
- mengabaikan tanda baca;
- mengeluarkan kata-kata berhenti;
- pengurangan kata-kata ke bentuk dasarnya (lemmatization dan stemming);
- koreksi kata-kata yang salah eja.
Cara lain yang lebih rumit untuk membuat kamus adalah dengan menggunakan kata-kata yang dikelompokkan. Ini akan mengubah ukuran kamus dan memberikan kantung kata-kata lebih detail tentang dokumen. Pendekatan ini disebut "
N-gram ."
N-gram adalah urutan entitas apa pun (kata, huruf, angka, angka, dll.). Dalam konteks badan linguistik, N-gram biasanya dipahami sebagai urutan kata-kata. Unigram adalah satu kata, bigram adalah urutan dua kata, trigram adalah tiga kata, dan seterusnya. Angka N menunjukkan berapa banyak kata yang dikelompokkan dimasukkan dalam N-gram. Tidak semua N-gram yang mungkin termasuk dalam model, tetapi hanya yang muncul dalam case.
Contoh:Pertimbangkan kalimat berikut:
The office building is open today
Inilah bigrams-nya:
- kantor
- gedung kantor
- bangunan itu
- terbuka
- buka hari ini
Seperti yang Anda lihat, sekantong bigrams adalah pendekatan yang lebih efektif daripada sekumpulan kata-kata.
Penilaian (penilaian) kata-kataKetika kamus dibuat, keberadaan kata-kata harus dievaluasi. Kami telah mempertimbangkan pendekatan biner yang sederhana (1 - ada kata, 0 - tidak ada kata).
Ada metode lain:
- Jumlah Dihitung berapa kali setiap kata muncul dalam dokumen.
- Frekuensi Dihitung seberapa sering setiap kata muncul dalam teks (dalam kaitannya dengan jumlah total kata).
7. TF-IDF
Skor frekuensi memiliki masalah: kata-kata dengan frekuensi tertinggi memiliki, masing-masing, peringkat tertinggi. Dengan kata-kata ini mungkin tidak ada banyak
informasi untuk model seperti dalam kata-kata yang kurang sering. Salah satu cara untuk memperbaiki situasi adalah dengan menurunkan skor kata, yang sering ditemukan
di semua dokumen serupa . Ini disebut
TF-IDF .
TF-IDF (kependekan dari term term - frekuensi dokumen terbalik) adalah ukuran statistik untuk menilai pentingnya sebuah kata dalam dokumen yang merupakan bagian dari kumpulan atau kumpulan.
Pemberian skor oleh TF-IDF tumbuh sebanding dengan frekuensi kemunculan kata dalam dokumen, tetapi ini dikompensasi dengan jumlah dokumen yang mengandung kata ini.
Rumus pemberian skor untuk kata X dalam dokumen Y:
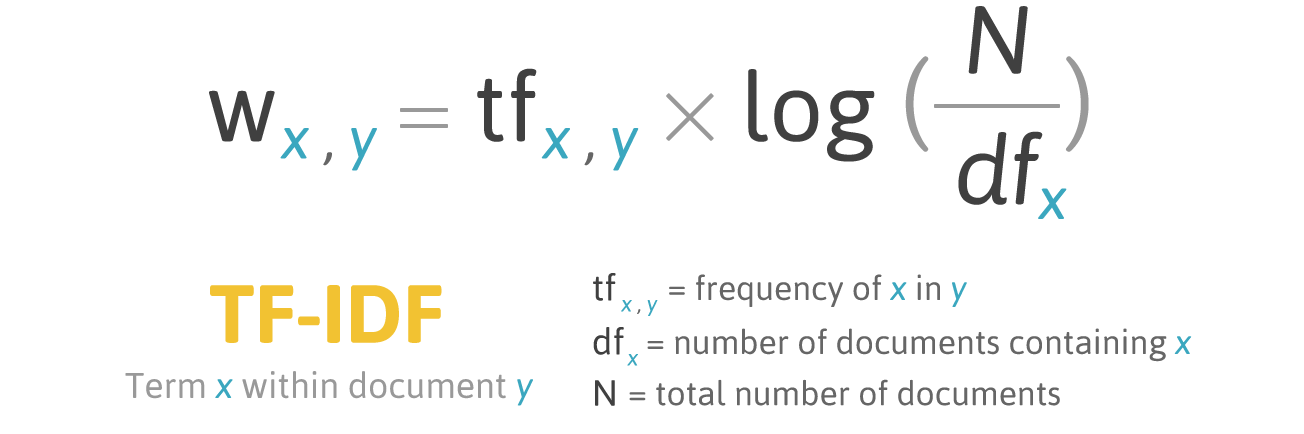 Formula TF-IDF. Sumber: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
Formula TF-IDF. Sumber: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (istilah frekuensi) adalah rasio dari jumlah kemunculan kata ke total jumlah kata dalam dokumen.
IDF (frekuensi dokumen terbalik) adalah kebalikan dari frekuensi kata yang muncul dalam kumpulan dokumen.
Akibatnya, TF-IDF untuk
istilah kata dapat dihitung sebagai berikut:
Contoh:Anda dapat menggunakan kelas
TfidfVectorizer dari pustaka sklearn untuk menghitung TF-IDF. Mari kita lakukan ini dengan pesan yang sama yang kita gunakan dalam kantong kata-kata contoh.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Kode:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
Kesimpulan:
Kesimpulan
Artikel ini telah membahas dasar-dasar NLP untuk teks, yaitu:
- NLP memungkinkan penggunaan algoritma pembelajaran mesin untuk teks dan ucapan;
- NLTK (Natural Language Toolkit) - platform terkemuka untuk membuat program-NLP dengan Python;
- tokenization proposal adalah proses membagi bahasa tertulis menjadi komponen kalimat;
- kata tokenization adalah proses membagi kalimat menjadi kata-kata komponen;
- Lemmatization dan stemming bertujuan untuk membawa semua bentuk kata yang ditemui menjadi satu bentuk kosa kata normal;
- kata berhenti adalah kata-kata yang dibuang dari teks sebelum / sesudah pemrosesan teks;
- regex (regex, regexp, regex) adalah urutan karakter yang menentukan pola pencarian;
- tas kata adalah teknik ekstraksi fitur populer dan sederhana yang digunakan saat bekerja dengan teks. Ini menggambarkan kemunculan setiap kata dalam teks.
Hebat! Sekarang setelah Anda mengetahui dasar-dasar ekstraksi fitur, Anda dapat menggunakan fitur sebagai input untuk algoritma pembelajaran mesin.
Jika Anda ingin melihat semua konsep yang dijelaskan dalam satu contoh besar, maka
inilah Anda .