
Dalam proyek kami, kami menggunakan arsitektur microservice. Jika bottleneck kinerja muncul, banyak waktu dihabiskan untuk memantau dan menganalisis log. Ketika mencatat waktu operasi individu ke dalam file log, biasanya sulit untuk memahami apa yang menyebabkan panggilan operasi ini, untuk melacak urutan tindakan atau offset waktu dari satu operasi relatif ke yang lain dalam layanan yang berbeda.
Untuk meminimalkan tenaga kerja manual, kami memutuskan untuk menggunakan salah satu alat pelacak. Tentang bagaimana dan mengapa Anda dapat menggunakan pelacakan dan bagaimana kami melakukannya, dan artikel ini akan dibahas.
Masalah apa yang bisa diselesaikan dengan penelusuran
- Temukan hambatan kinerja dalam satu layanan dan di seluruh pohon eksekusi antara semua layanan yang berpartisipasi. Sebagai contoh:
- Banyak panggilan singkat berurutan antar layanan, misalnya, ke geocoding atau ke basis data.
- Lama menunggu input input, misalnya, mentransfer data melalui jaringan atau membaca dari disk.
- Penguraian data lama.
- Operasi panjang yang membutuhkan CPU.
- Potongan kode yang tidak diperlukan untuk mendapatkan hasil akhir dan dapat dihapus atau dijalankan ditunda.
- Pahami dengan jelas dalam urutan apa yang disebut dan apa yang terjadi ketika operasi dilakukan.
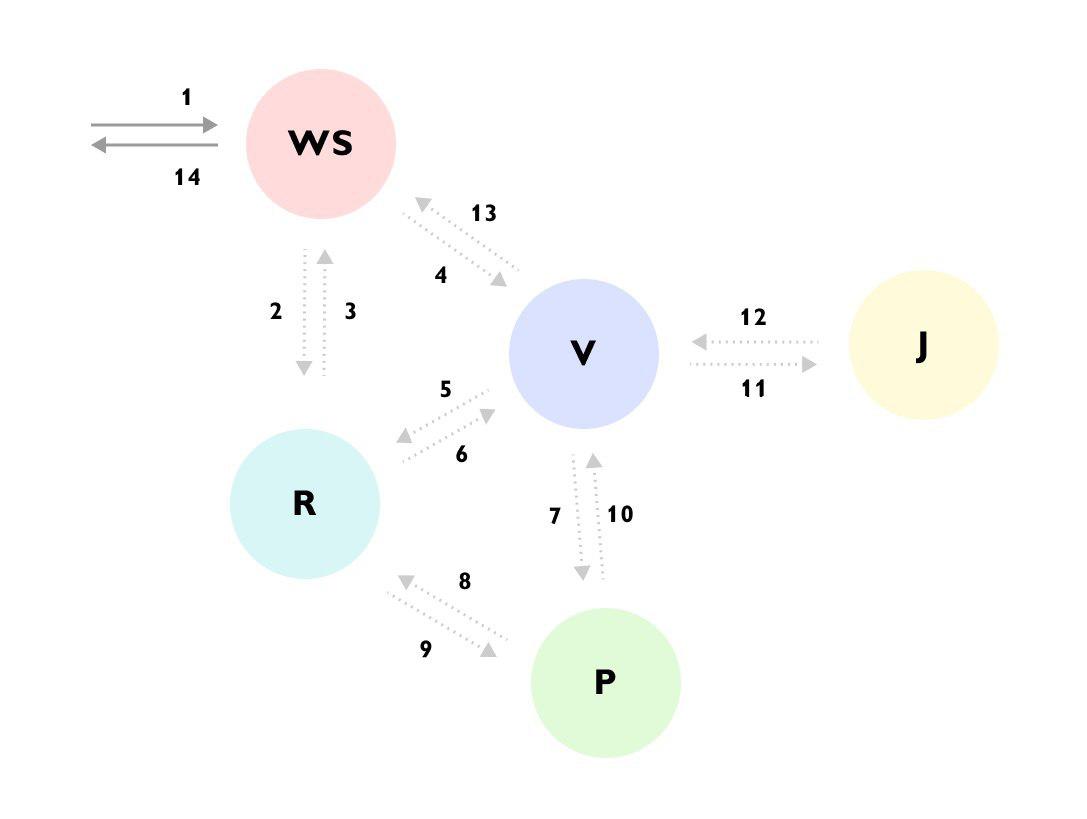
Dapat dilihat bahwa, misalnya, Permintaan datang ke layanan WS -> layanan WS melengkapi data melalui layanan R -> kemudian mengirim permintaan ke layanan V -> layanan V memuat banyak data dari layanan R -> pergi ke layanan P -> layanan P mati lagi ke layanan R -> layanan V mengabaikan hasilnya dan pergi ke layanan J -> dan baru kemudian mengembalikan jawaban ke layanan WS, sambil terus menghitung sesuatu yang lain di latar belakang.
Tanpa jejak atau dokumentasi terperinci untuk keseluruhan proses, sangat sulit untuk memahami apa yang terjadi saat pertama kali Anda melihat kode, dan kode tersebut tersebar di berbagai layanan dan disembunyikan di balik banyak tempat sampah dan antarmuka.
- Pengumpulan informasi tentang pohon eksekusi untuk analisis tertunda berikutnya. Pada setiap tahap eksekusi, Anda dapat menambahkan informasi ke jejak yang tersedia pada tahap ini dan kemudian mencari tahu masukan apa yang menyebabkan skenario yang sama. Sebagai contoh:
- ID pengguna
- Hak
- Jenis metode yang dipilih
- Kesalahan log atau eksekusi
- Ubah jejak menjadi subset metrik dan analisis lebih lanjut sebagai metrik.
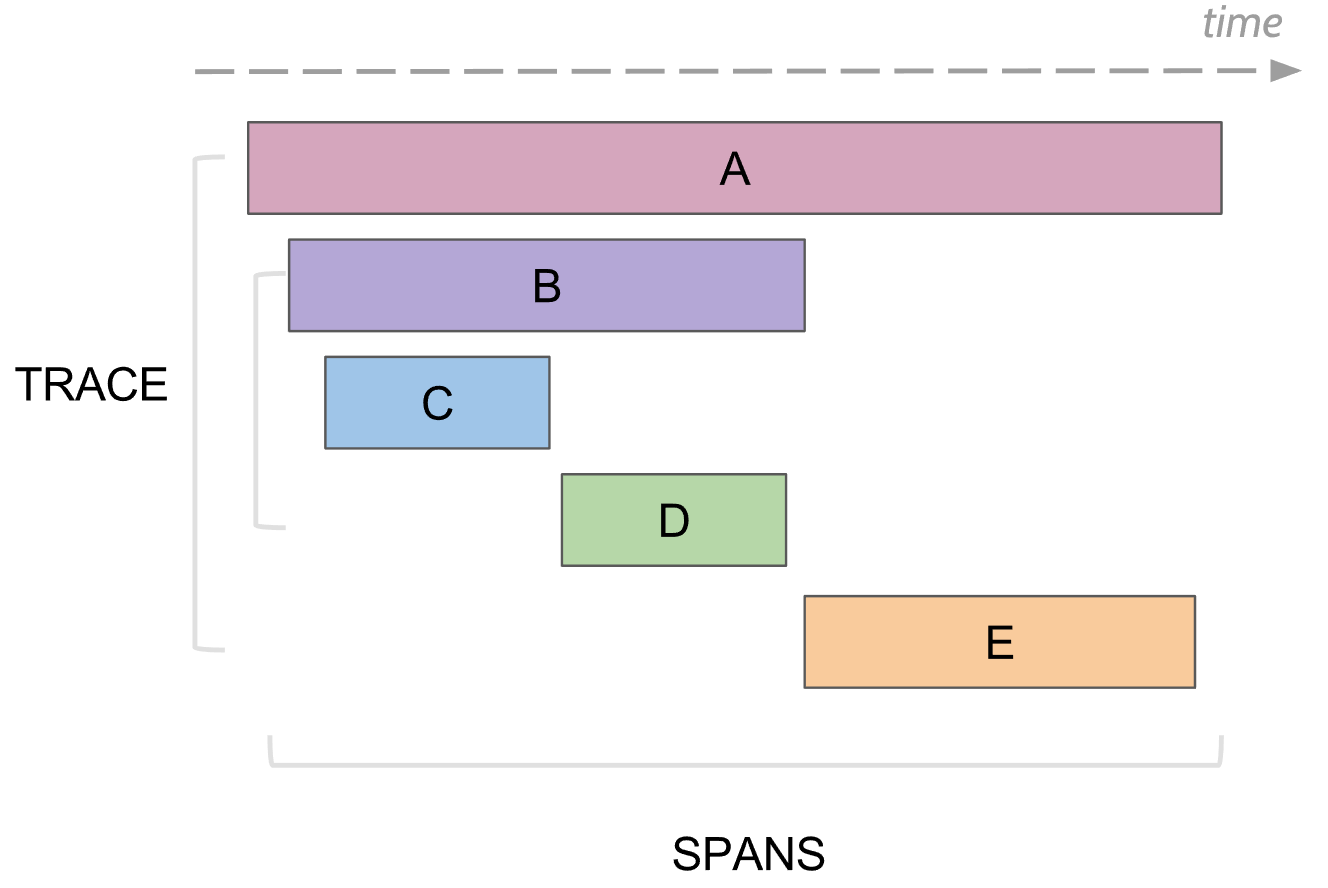
Apa yang bisa melacak logging. Rentang
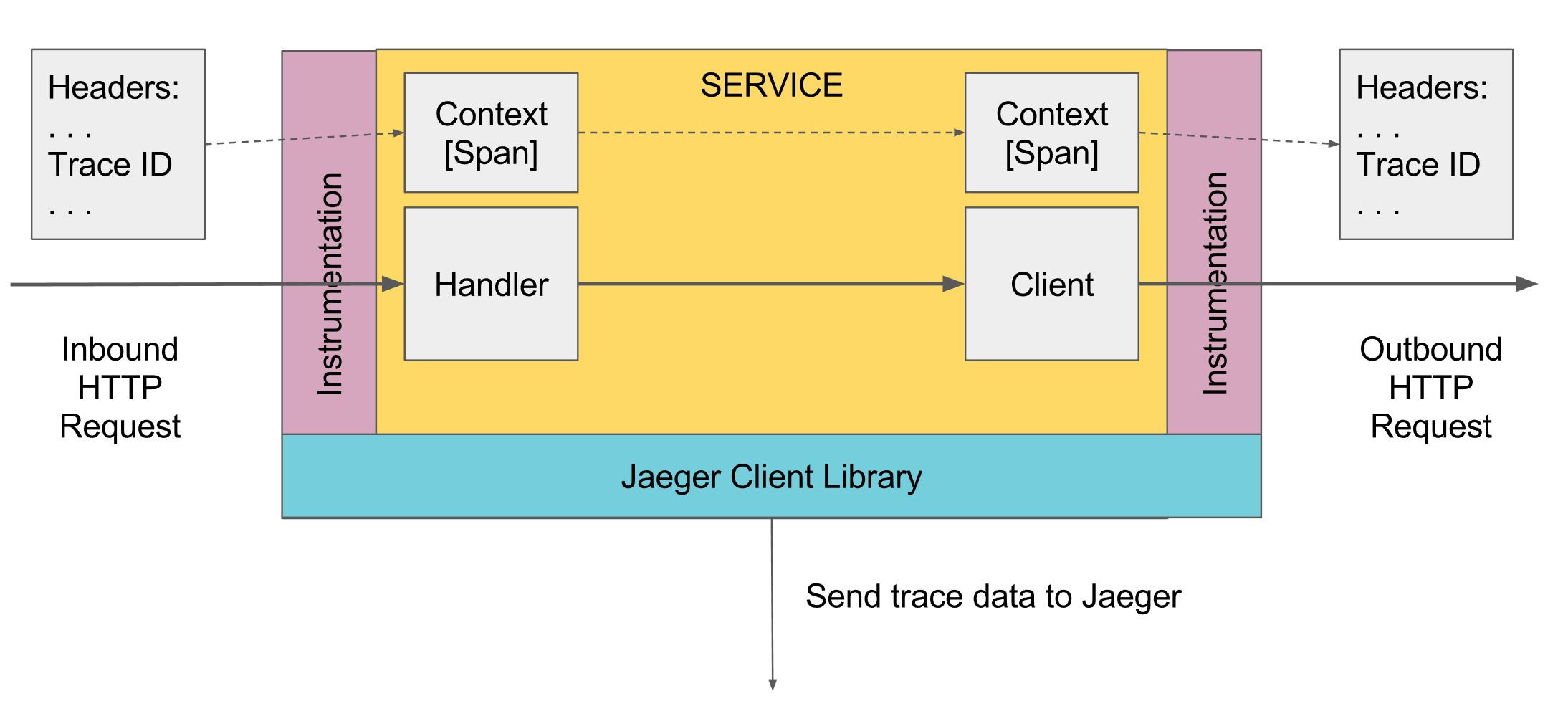
Dalam penelusuran, ada konsep span, ini merupakan analog dari satu log ke konsol. Rentang memiliki:
- Nama, biasanya nama metode yang dieksekusi
- Nama layanan tempat rentang dihasilkan
- ID unik sendiri
- Beberapa informasi meta dalam bentuk kunci / nilai, yang dijanjikan padanya. Misalnya, parameter metode atau metode berakhir dengan kesalahan atau tidak
- Waktu mulai dan akhir rentang ini
- Id rentang induk
Setiap rentang dikirim ke pengumpul rentang untuk disimpan ke database untuk dilihat nanti segera setelah menyelesaikan eksekusi. Di masa mendatang, Anda dapat membangun pohon dari semua bentang dengan menghubungkan dengan id induk. Dalam analisis, Anda dapat menemukan, misalnya, semua rentang dalam beberapa layanan yang membutuhkan waktu lebih dari beberapa waktu. Selanjutnya, pergi ke rentang tertentu, lihat seluruh pohon di atas dan di bawah rentang ini.
Opentracing, Jagger dan bagaimana kami menerapkannya untuk proyek kami
Ada standar
Opentracing umum yang menjelaskan bagaimana dan apa yang harus dirakit tanpa terikat dengan implementasi spesifik dalam bahasa apa pun. Misalnya, di Jawa, semua pekerjaan dengan jejak dilakukan melalui API Opentracing umum, dan di bawahnya, misalnya, Jaeger atau implementasi default kosong yang tidak melakukan apa pun dapat disembunyikan.
Kami menggunakan
Jaeger sebagai implementasi dari Opentracing. Ini terdiri dari beberapa komponen:
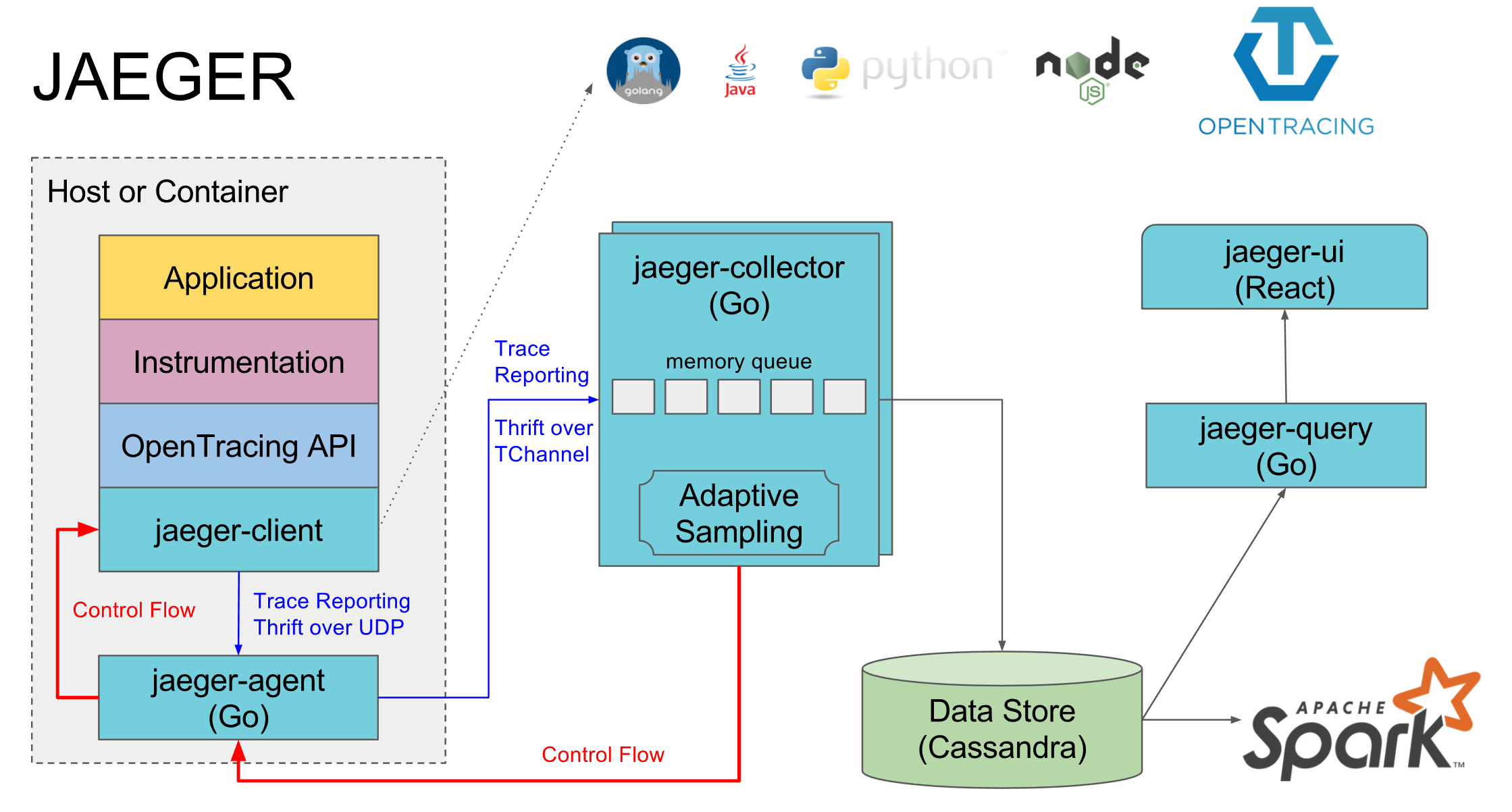
- Jaeger-agent adalah agen lokal yang biasanya berdiri di setiap mesin dan layanan masuk ke dalamnya pada port default lokal. Jika tidak ada agen, maka jejak semua layanan pada mesin ini biasanya dimatikan
- Jaeger-collector - semua agen mengirim jejak yang dikumpulkan untuk itu, dan dia menempatkan mereka di database yang dipilih
- Basis data adalah cassandra pilihan mereka, tetapi kami menggunakan elasticsearch, ada implementasi untuk beberapa database lain dan dalam memori implementasi yang tidak menyimpan apa pun ke disk
- Jaeger-query adalah layanan yang masuk ke database dan memberikan jejak yang sudah dikumpulkan untuk analisis
- Jaeger-ui adalah antarmuka web untuk mencari dan melihat jejak, ia pergi ke jaeger-query
Komponen terpisah adalah implementasi opa pelacak jaeger untuk bahasa tertentu, melalui mana bentang dikirim ke agen jaeger.
Menghubungkan Jagger di Jawa turun untuk mensimulasikan antarmuka io.opentracing.Tracer, setelah itu semua jejak melalui itu akan terbang ke agen nyata.
Anda juga dapat menghubungkan
opentracing-spring-cloud-starter dan implementasi dari Jaeger
opentracing-spring-jaeger-cloud-starter yang secara otomatis akan mengkonfigurasi pelacakan untuk segala sesuatu yang melewati komponen-komponen ini, misalnya, permintaan http ke pengontrol, permintaan basis data melalui jdbc dll.
Tracing Logging in Java
Di suatu tempat di tingkat paling atas, Rentang pertama harus dibuat, ini dapat dilakukan secara otomatis, misalnya, oleh pengontrol pegas ketika permintaan diterima, atau secara manual jika tidak ada. Selanjutnya ditransmisikan melalui Lingkup di bawah ini. Jika beberapa metode di bawah ini ingin menambahkan Span, dibutuhkan activeSpan saat ini dari Scope, membuat Span baru dan mengatakan bahwa induknya menerima activeSpan, dan membuat Span baru aktif. Ketika layanan eksternal dipanggil, rentang aktif saat ini ditransfer ke mereka, dan layanan tersebut membuat rentang baru dengan mengacu pada rentang ini.
Semua pekerjaan melewati instance Tracer, Anda bisa mendapatkannya melalui mekanisme DI, atau GlobalTracer.get () sebagai variabel global jika mekanisme DI tidak berfungsi. Secara default, jika pelacak tidak diinisialisasi, NoopTracer akan kembali yang tidak melakukan apa-apa.
Selanjutnya, lingkup saat ini diperoleh dari pelacak melalui ScopeManager, lingkup baru dibuat dari yang saat ini dengan pengikatan rentang baru, dan kemudian Lingkup yang dibuat ditutup, yang menutup rentang yang dibuat dan mengembalikan Lingkup sebelumnya ke keadaan aktif. Lingkup terikat ke aliran, jadi ketika pemrograman multi-utas, Anda jangan lupa untuk mentransfer rentang aktif ke aliran lain, untuk aktivasi lebih lanjut Lingkup aliran lain dengan mengacu pada rentang ini.
io.opentracing.Tracer tracer = ...;
Untuk pemrograman multi-utas, ada juga TracedExecutorService dan pembungkus serupa yang secara otomatis meneruskan rentang saat ini ke aliran saat meluncurkan tugas yang tidak sinkron:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
Untuk permintaan http eksternal, ada
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
Masalah yang kita hadapi
- Kacang dan DI tidak selalu berfungsi jika pelacak tidak digunakan dalam layanan atau komponen, maka Pelacak Autowired mungkin tidak berfungsi dan Anda harus menggunakan GlobalTracer.get ().
- Anotasi tidak berfungsi jika itu bukan komponen atau layanan, atau jika pemanggilan metode berasal dari metode tetangga dari kelas yang sama. Anda harus berhati-hati, memeriksa apa yang berhasil, dan menggunakan pembuatan jejak secara manual jika @Traced tidak berfungsi. Anda juga dapat mengacaukan kompiler tambahan untuk penjelasan java, lalu mereka harus bekerja di mana saja.
- Di pegas dan pegas boot lama, konfigurasi otomatis dari cloud pelumasan pembuka tidak berfungsi karena bug di DI, maka jika Anda ingin jejak dalam komponen pegas bekerja secara otomatis, Anda dapat melakukannya dengan analogi dengan github.com/opentracing-contrib/java-spring-jaeger/blob/ master / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- Coba dengan sumber daya tidak berfungsi di asyik, Anda harus menggunakan coba akhirnya.
- Setiap layanan harus memiliki spring.application.name di mana jejak akan dicatat. Apa nama yang terpisah untuk dijual dan diuji, agar tidak mengganggu mereka bersama.
- Jika Anda menggunakan GlobalTracer dan kucing jantan, maka semua layanan yang berjalan di kucing jantan ini memiliki satu GlobalTracer, sehingga mereka semua akan memiliki nama layanan yang sama.
- Saat menambahkan jejak ke suatu metode, Anda harus memastikan bahwa itu tidak dipanggil berulang kali. Penting untuk menambahkan satu jejak umum untuk semua panggilan, yang menjamin total waktu kerja. Kalau tidak, kelebihan beban akan dibuat.
- Sekali di jaeger-ui mereka membuat permintaan terlalu besar untuk sejumlah besar jejak dan karena mereka tidak menunggu jawaban, mereka melakukannya lagi. Akibatnya, permintaan-jaeger mulai memakan banyak memori dan memperlambat elastisitasnya. Membantu me-restart jaeger-query
Sampling, penyimpanan dan melihat jejak
Ada tiga jenis
jejak sampel :
- Const yang mengirim dan menyimpan semua jejak.
- Probabilistik yang menyaring jejak dengan beberapa probabilitas yang diberikan.
- Ratelimiting yang membatasi jumlah jejak per detik. Anda dapat mengkonfigurasi opsi ini pada klien, baik pada agen jaeger atau di kolektor. Sekarang kita memiliki const 1 di tumpukan penilai, karena tidak ada banyak permintaan, tetapi mereka membutuhkan waktu lama. Di masa depan, jika ini akan memberikan beban berlebihan pada sistem, Anda dapat membatasi itu.
Jika Anda menggunakan cassandra maka secara default menyimpan jejak hanya dalam dua hari. Kami menggunakan
elasticsearch dan jejak disimpan sepanjang waktu dan tidak dihapus. Indeks terpisah dibuat untuk setiap hari, misalnya, jaeger-service-2019-03-04. Di masa mendatang, Anda harus mengonfigurasi pembersihan otomatis jejak lama.
Untuk menonton kursus yang Anda butuhkan:
- Pilih layanan tempat Anda ingin memfilter jejak, misalnya tomcat7-default untuk layanan yang menggunakan tomat dan tidak dapat memiliki nama.
- Selanjutnya, pilih operasi, interval waktu dan waktu operasi minimum, misalnya dari 10 detik, untuk hanya berjalan lama.
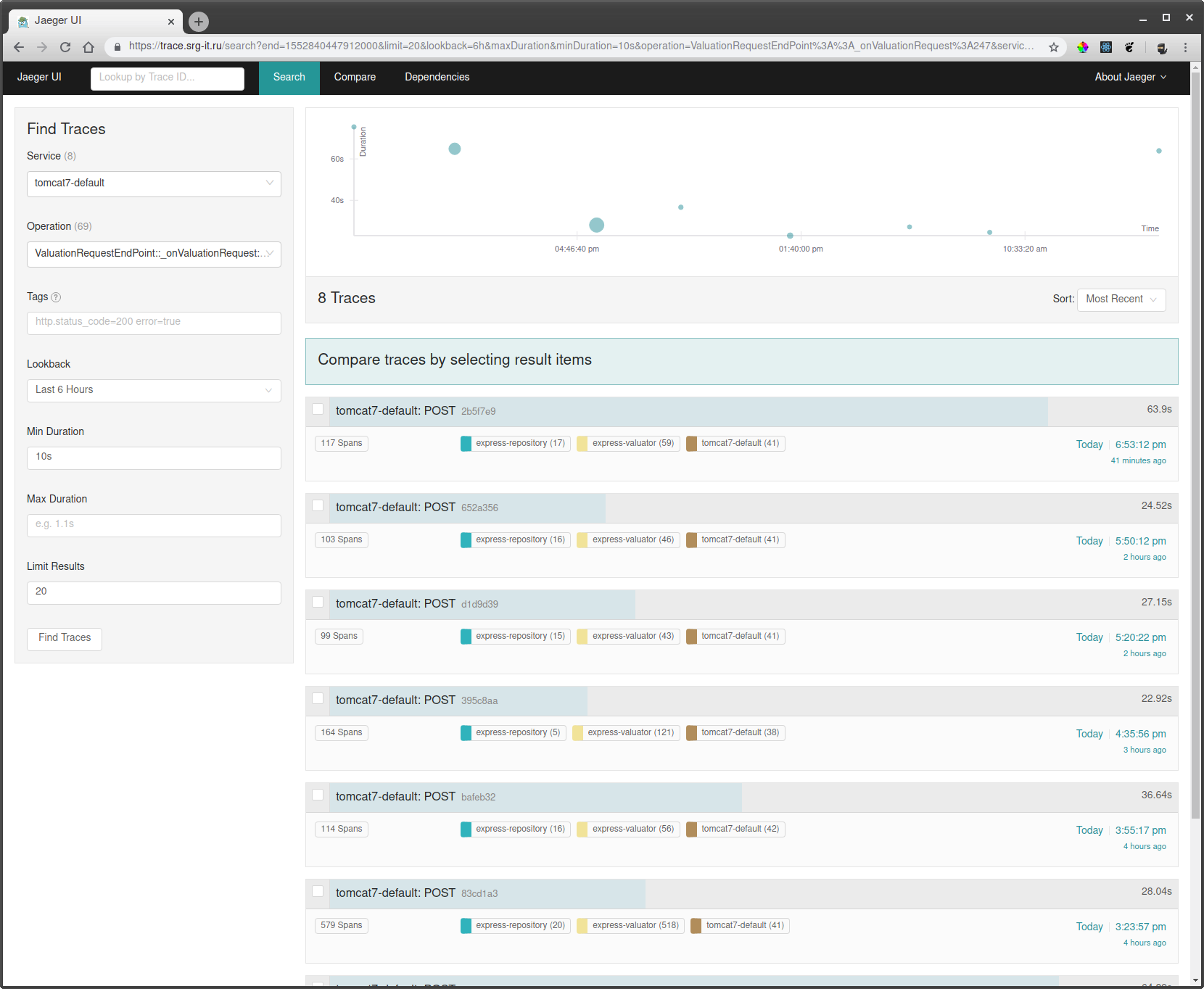
- Pergi ke salah satu trek dan lihat apa yang melambat di sana.

Juga, jika id permintaan diketahui, maka Anda dapat menemukan jejak oleh id ini melalui pencarian tag, jika id ini dicatat dalam rentang trek.
Dokumentasi
Artikel
Video