Pembelajaran mesin digunakan di seluruh siklus pemesanan mobil Yandex.Taxi, dan jumlah komponen layanan yang bekerja berkat ML terus berkembang. Untuk membangunnya secara seragam, kami membutuhkan proses terpisah. Roman Khalkachev, Kepala Pembelajaran Mesin dan Layanan Analisis Data, berbicara tentang preprocessing data, penggunaan model dalam produksi, layanan prototyping dan alat terkait.
- Menurut pendapat saya, beberapa hal baru jauh lebih mudah dipahami ketika mereka diberitahu tentang beberapa contoh sederhana. Karena itu, agar laporannya tidak kering, saya memutuskan untuk membicarakan salah satu tugas yang sedang kami selesaikan. Menggunakan teladannya, saya akan menunjukkan mengapa kita bertindak dengan cara ini.
Mari kita rumuskan masalahnya. Ada pengguna taksi yang perlu naik dari titik A ke titik B, dan ada pengemudi yang siap untuk jumlah tertentu untuk mengantarkan pengguna ini dari titik A ke titik B. Pengguna memiliki beberapa kondisi di mana dia berada. Dia memanggil taksi, memilih titik A, titik B, ongkos, dan sebagainya, melakukan pendaratan taksi, menumpang, dan akhirnya melakukan pendaratan. Hari ini saya ingin berbicara tentang masuk ke mobil dan masalah yang mungkin timbul.

Biasanya, masalah-masalah ini berkaitan dengan fakta bahwa seseorang perlu memilih tempat di mana taksi harus datang. Dan di sini ada sejumlah kesulitan. Kesulitan-kesulitan ini terkait dengan empat hal yang telah saya daftarkan pada slide.
Pertama-tama, lokasi mungkin tidak familier bagi pengguna. Sebagai contoh, Anda bisa membayangkan diri Anda yang datang ke beberapa pusat perbelanjaan besar, di mana Anda tidak sering berkunjung. Anda ingin pergi, dan Anda tidak benar-benar tahu di mana Anda dapat memanggil taksi di sini, di mana mobil dapat menelepon, tetapi di mana tidak bisa, misalnya, karena penghalang. Ada masalah dengan kenyataan bahwa di beberapa tempat ada banyak orang, banyak mobil dan sulit bagi Anda untuk menemukan mobil Anda. Ada tempat-tempat di mana orang biasanya masuk ke dalam mobil, lebih mudah untuk sampai ke sana. Dan Anda mungkin tidak tahu, berada di tempat baru, belum tentu di pusat perbelanjaan, di mana tepatnya mendarat. Kesulitan dapat dihubungkan dengan fakta bahwa pengemudi tidak dapat mengemudi ke tempat Anda memanggil taksi: ia dilarang bepergian, ada beberapa pintu keluar besar dari pusat perbelanjaan, di seberangnya Anda tidak dapat berhenti, dll.
Di sisi lain, Anda mungkin memiliki masalah sebagai pengguna. Sopir tiba, semuanya baik-baik saja, tetapi Anda tidak nyaman untuk duduk, karena semua orang menggali. Anda meminta pengemudi untuk mengemudi di tempat lain. Ada alasan lain.
Contoh paling ilustratif, intisari dari semua hal di atas, adalah bandara, di mana hampir semuanya dilakukan. Bahkan jika Anda sering terbang dari Sheremetyevo, itu masih merupakan lokasi yang asing bagi Anda, karena banyak hal sering berubah di sana. Ada banyak orang, banyak mobil, ada tempat yang nyaman untuk pendaratan, ada yang tidak nyaman, tetapi sebagai aturan, tidak ada dari kita yang ingat tentang ini.
Solusinya dibaca dari judul slide. Izinkan kami merekomendasikan kepada pengguna beberapa tempat di mana, menurut pendapat kami, nyaman untuk mendarat. Pikiran itu tampak jelas, tetapi ada banyak nuansa di sini.
Sebagai permulaan, "nyaman" adalah konsep subjektif. Tampaknya sebelum menyelesaikan masalah, perlu dirumuskan beberapa kriteria untuk fakta bahwa masalah akan diselesaikan dengan benar. Kami telah merumuskan tiga yang utama untuk diri kami sendiri. Kriteria pertama adalah seperti dalam tugas rekomendasi: mungkin, rekomendasi bagus jika digunakan. Jika kami menunjukkan poin dari mana pengguna akan benar-benar pergi - ini mungkin poin yang baik. Tapi ini, tentu saja, tidak semuanya, karena Anda dapat belajar untuk merekomendasikan sesuatu, menunjukkannya, mendorong pengguna untuk menggunakannya, tetapi Anda tidak bisa mendapatkan keuntungan nyata (kami tidak akan mendapatkan sebagai sistem, atau pengguna, atau pengemudi). Karena itu, sangat penting untuk melihat metrik lain. Kami telah memilih dua.
Jika kami memberi tahu Anda tentang tempat pendaratan yang dapat dengan mudah dikendarai oleh pengemudi, maka waktu pengiriman kendaraan harus dikurangi. Di sisi lain, jika lebih mudah bagi pengguna untuk menemukan mobil di tempat ini, lebih mudah untuk mendarat, maka waktu tunggu pengemudi oleh pengemudi harus dikurangi. Ini adalah beberapa hipotesis kami, yang kami terima begitu saja, dan ini adalah beberapa metrik yang kami lihat ketika kami membuat rekomendasi ini. Tapi tentu saja, ini bukan satu-satunya metrik untuk dilihat. Anda bisa menghasilkan selusin lagi. Saya pikir Anda masing-masing dapat membuat seratus metrik ini.
Berikut ini beberapa contoh lainnya. Ini mungkin proporsi pembatalan sebelum perjalanan. Secara teori, itu harus berkurang jika lebih mudah bagi pengguna untuk mendarat. Secara konvensional, ini adalah panggilan saat pengguna memanggil pengemudi yang berusaha menemukannya, atau, sebaliknya, pengemudi memanggil pengguna sebelum perjalanan dimulai. Seruan ini mendukung, dan bersama selusin lainnya.
Kami telah merumuskan masalahnya. Kami secara kasar memahami kriteria bahwa kami dapat menyelesaikan masalah ini. Sekarang mari kita pikirkan tentang bagaimana menyelesaikan masalah ini. Hal pertama yang terlintas dalam pikiran: mari kita merekomendasikan titik pendaratan yang terbukti dan dapat dimengerti tersebut. Di sini, di slide adalah contoh dari Pusat Perbelanjaan Eropa. Dan kami tahu pasti bahwa Anda dapat berkendara hingga keluar dari pusat perbelanjaan ini, dan ini adalah semacam tengara berkat pengguna yang dapat menemukan pengemudi. Mungkin organisasi apa pun. Ada contoh dengan ABC of Taste di beberapa pusat perbelanjaan. Menurut pendapat saya, ini adalah Yerevan Plaza. Ini juga semacam pedoman bagi pengguna dan pengemudi, yang kami ketahui dapat Anda kendarai di sana.
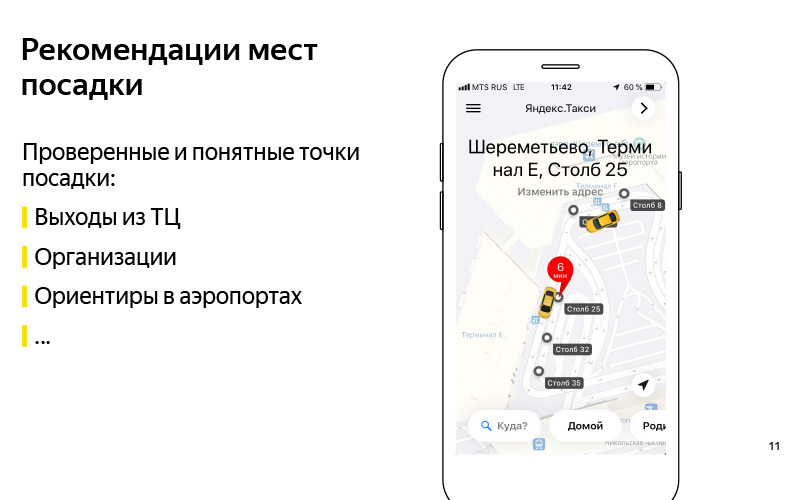
Ini mungkin landmark di bandara yang saya bicarakan. Secara konvensional, ada semacam tiang di Sheremetyevo dengan angka. Lebih mudah untuk memanggil taksi dan masuk ke mobil. Solusi yang bagus, tetapi memiliki minus sehingga tidak terlalu skalabel. Kami memiliki banyak negara, ratusan kota, sejumlah besar pusat perbelanjaan yang berbeda, bandara, persimpangan yang sulit, tempat-tempat asing yang membuat poin-poin ini sulit untuk dibuat secara manual, dan mempertahankannya tetap terkini bahkan lebih sulit. Di sinilah datang ke bantuan kami apa yang keras disebut "kecerdasan buatan." Saya lebih suka menyebutnya data mining atau pembelajaran mesin.
Pembelajaran mesin membutuhkan beberapa jenis data, dan kami benar-benar memiliki data itu. Cara lain untuk memecahkan masalah secara otomatis adalah dengan menggunakan data ini. Gagasan tingkat tinggi adalah bahwa kita memiliki data tentang GPS, log aplikasi, dan ada grafik jalan. Dan kita dapat memahami di mana pengguna benar-benar masuk ke mobil. Bukan titik di mana mereka memanggil mobil, tetapi di mana mereka mendarat. Dan berdasarkan ini, lakukan sesuatu seperti itu.

Ini sudah menerima poin secara otomatis untuk pusat bisnis Aurora, tempat tim Yandex.Taxi kami saat ini duduk.
Saya berbicara tingkat tinggi tentang tugas kami. Sekarang mari kita bicara lebih rinci tentang tahap apa dari solusi untuk masalah ini terdiri. Jelas bahwa ada tahap persiapan data.

Data apa yang kita miliki? Pertama, kami memiliki data GPS dari pengguna kami dan data GPS dari driver kami. Ketika mereka menggunakan aplikasi kami, kami tahu perkiraan lokasi pengguna. Jelas bahwa GPS memiliki kesalahan besar, di wilayah 13-15 meter, namun demikian, ada sesuatu. Kedua, kami memiliki informasi yang terkandung dalam log aplikasi tentang kapan pengemudi beralih dari status "Saya menunggu pengguna" ke status "Saya mengambil pengguna". Dapat diasumsikan bahwa sekitar saat ini pengemudi menunggu pengguna, pengguna masuk ke mobil, dan mereka pergi. Di sekitar tempat ini, pendaratan dilakukan. Dan kami memiliki grafik jalan. Grafik jalan tidak hanya seperangkat tepi, jalan, tetapi juga meta-informasi tambahan: hambatan, informasi tentang parkir, dll. Berdasarkan data ini, Anda sudah bisa mendapatkan semacam titik otomatis.
Ini adalah sumber data. Dan di pintu keluar, kami menginginkan dua hal. Ini adalah beberapa yang disebut kandidat titik pendaratan. Bagaimana mereka terjadi? Sangat disayangkan bahwa tidak mungkin untuk menampilkan video. Berikut ini terjadi kira-kira. Kami memiliki banyak titik GPS di mana kami tahu bahwa pengemudi telah beralih dari status "Menunggu penumpang" ke status "Ayo pergi." Secara kondisional, kita dapat menarik mereka ke grafik, yaitu, memproyeksikannya ke grafik jalan, karena, sebagai suatu peraturan, mobil mulai bergerak dari suatu jalan. Pada grafik ini, lakukan semacam pengelompokan titik-titik ini. Dan untuk mendapatkan sejumlah besar kandidat - ini adalah tempat di mana beberapa pengguna masuk ke mobil, dan itu normal, nyaman bagi mereka. Bukan di mana mereka memanggil, tetapi di mana mereka akhirnya duduk.
Setelah itu, ketika kita memiliki banyak kandidat dan kita memiliki beberapa pengguna online, kita tahu lokasinya, jadi dia membuka aplikasi dan ingin memanggil taksi, maka kita dapat memilih lima terbaik dari sejumlah besar kandidat dan menunjukkan kepada mereka. Lima terbaik ditentukan oleh beberapa model pembelajaran mesin, yang belajar menentukan peringkat semua kandidat berdasarkan kemungkinan bahwa pengguna saat ini, dengan mempertimbangkan lokasi dan riwayat perjalanannya, paling mudah untuk pergi. Dan kira-kira dengan cara ini kita dapat secara otomatis menghasilkan poin-poin ini. Selain itu, jika pada suatu titik mereka secara kondisional menggali di suatu tempat, yaitu, menjadi tidak nyaman untuk memanggil taksi, atau di suatu tempat mereka memasang tanda yang melarang berhenti, dan pengemudi dan pengguna benar-benar berhenti mendarat di tempat ini, maka di beberapa saat algoritma akan memahami ini, dan data akan diperbarui.
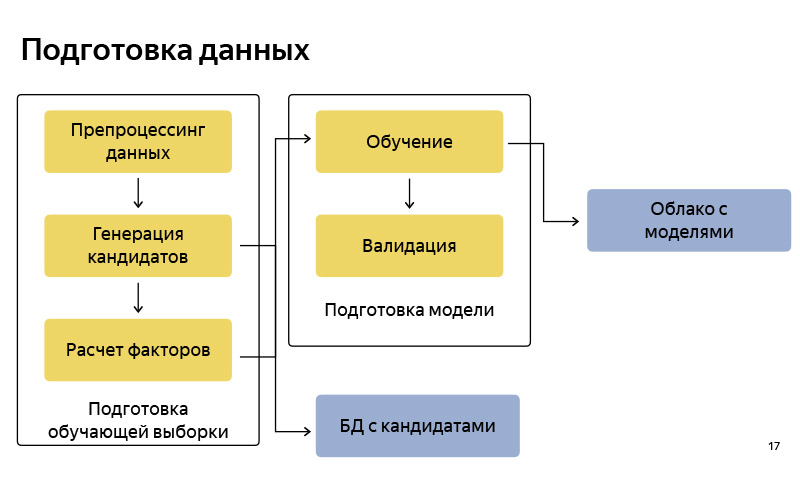
Ini kira-kira diagram blok bagaimana kita mempersiapkan data. Dengan demikian, ini cukup standar, seperti pada pipa pembelajaran mesin. Ada persiapan data, ada generasi kandidat menurut algoritma, saya mengatakan versi yang disederhanakan. Kami menyimpan kandidat ini dalam database tertentu. Setelah itu, kami menyiapkan beberapa kumpulan untuk pelatihan (sampel pelatihan), di mana ada, secara kondisional, pengguna, waktu, meta-informasi, satu set kandidat, dan diketahui dari titik mana pengguna akhirnya pergi. Pada ini kita melatih model klasifikasi. Dan kemudian, berdasarkan prediksi probabilitas, kami memberi peringkat pada kandidat. Saat model siap, kami mengunggahnya ke beberapa cloud, di mana ia tersimpan dengan baik.
Alat apa yang kami gunakan dalam menyiapkan data? Pada dasarnya, semua persiapan data yang kami tulis dalam Python, pada tumpukan Python: ini adalah standar NumPy, Panda, Scikit-learn, dll. Kami memiliki banyak data. Kami memiliki jutaan perjalanan per bulan. Banyak data tentang GPS, tentang trek driver, log aplikasi, jadi kita perlu memproses semuanya di cluster. Untuk melakukan ini, kami menggunakan MapReduce versi intra-Yandex kami, yang disebut YT, dan ada perpustakaan yang ditulis dengan Python, yang memungkinkan beberapa pemetaan dan reduksi diluncurkan, dan untuk melakukan beberapa perhitungan pada sekelompok besar.
Akhirnya, ketika pipeline sudah siap, kita perlu mengotomatiskannya agar datanya mutakhir, dan untuk ini kita menggunakan hal seperti Nirvana dan Hitman. Ini juga pengembangan intra-Yandex. Nirvana adalah kerangka kerja manajemen komputasi cluster. Bahkan, dia tahu bagaimana menjalankan hampir semua program, menjadi toleran terhadap kesalahan, menjadi lintas DC (00:14:53). Dan jika ada sesuatu yang jatuh, dia tahu bagaimana me-restart-nya, untuk membuat peluncuran atas kejadian apa pun. dll.

Ini kira-kira seperti apa antarmuka web cluster MapReduce kami. Dapat dilihat di sini bahwa kita memiliki banyak mesin, seperti node di mana perhitungan dilakukan.
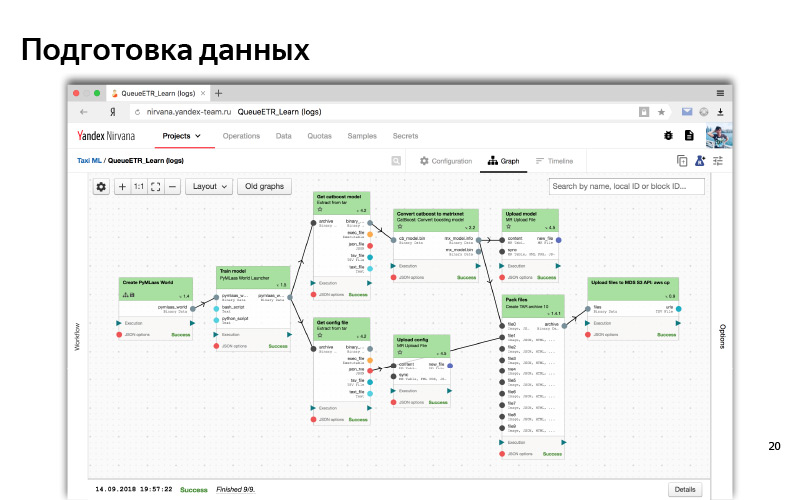
Jadi dalam antarmuka web proses khas dari beberapa jenis preprocessing data dan pelatihan model terlihat. Ini adalah grafik ketergantungan. Ketergantungan seperti data, ketika satu bagian (satu kubus) sedang menunggu data dari kubus lain; dan ketergantungan logis (pertama kami menyiapkan semua data, kemudian memulai pelatihan). Ini adalah semacam sistem otomatis. Untuk semua ini, kami biasanya menggunakan Python.
Kami merumuskan masalah, merumuskan kriteria keberhasilan, belajar bagaimana menyelesaikannya secara offline, bahkan membuat semacam model, dan tampaknya berfungsi sesuai dengan beberapa metrik offline - itu benar-benar memprediksi titik di mana pengguna meninggalkan dan menemukan titik-titik tersebut yang, tampaknya, akan mengurangi waktu tunggu dan pengiriman mobil.

Mari kita coba model ini, gunakan data ini. Untuk melakukan ini, bayangkan apa layanan Yandex.Taxi.
Diagram yang sangat dangkal terlihat seperti ini. Ada pengguna, mereka memiliki aplikasi, dan ada driver, mereka juga memiliki aplikasi yang disebut "Taximeter". Aplikasi ini entah bagaimana berkomunikasi dengan backend, dan backend adalah seperangkat layanan microsoft yang berkomunikasi satu sama lain - Ilya
membicarakan hal ini. Salah satu layanan microser adalah layanan kami, tim kami melakukannya, disebut ML sebagai Layanan, MLaaS.

Yang perlu Anda ketahui tentang dia adalah MLaaS yang ditulis dalam C ++, berdasarkan apa yang disebut Fastcgi Daemon. Ini adalah pustaka sumber terbuka, yang, secara kasar, adalah kerangka kerja untuk menulis server web yang bisa mendapatkan dan mengirim permintaan, semuanya standar. Itu pernah ditulis dalam Yandex, ditata dalam sumber terbuka. Kami menggunakan versi yang dicelupkan. Apa yang bisa dilakukan layanan ini? Dia tahu cara bekerja dengan model: menerapkannya, menyimpannya di rumah dan kadang-kadang memperbarui, pergi ke cloud yang luar biasa ini, di mana model diperbarui secara berkala, disimpan, dan unduh.
Setiap fungsionalitas, misalnya, titik pendaratan ini - di dalamnya kami menyebutnya titik penjemputan - atau, misalnya, tips poin B yang dibicarakan Ilya dan terus-menerus rusak dalam laporan sebelumnya, masing-masing fungsi tersebut, di mana ada semacam pembelajaran mesin, sesuai dengan handler, yang menyimpan logika penerimaan permintaan, menghasilkan faktor pembelajaran mesin, dan menerapkan model, dan menghasilkan respons. Tentu saja, layanan ini tidak terisolasi, dapat pergi ke beberapa sumber data tambahan, basis data, dan beberapa layanan Microsoft lainnya.
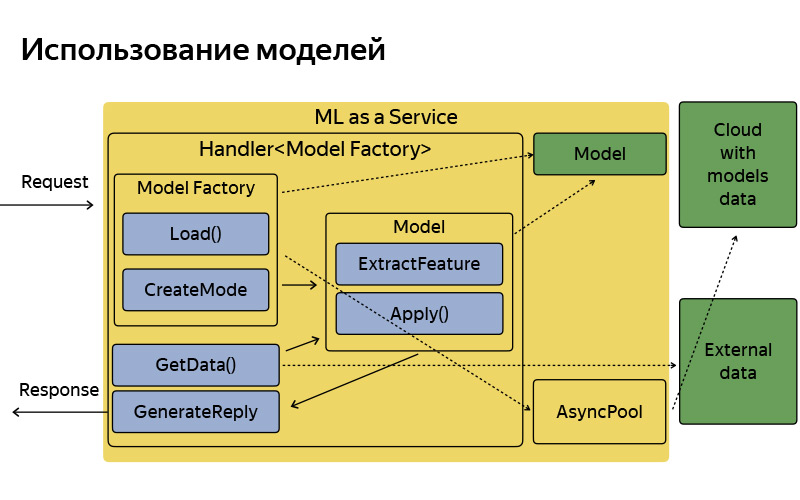
Beginilah cara mengaturnya, ia memiliki arsitektur yang agak sederhana. Saya tidak ingin membahas slide ini secara terperinci, saya hanya ingin mengatakan bahwa, secara konvensional, arsitekturnya sangat sederhana. Permintaan tiba, ada beberapa pabrik model, yang terkadang mengunduh model-model ini dari cloud. Dalam memori mereka disimpan dalam satu salinan. Untuk setiap permintaan, objek model yang agak ringan dibuat, yang mengekstrak fitur, berlaku, dan menghasilkan respons.

Tapi apa yang kita miliki untuk saat ini? Saya sudah memberi tahu Anda bahwa kami memiliki persiapan data, pelatihan, berbagai studi, eksperimen, dan semua ini ditulis dalam Python Stack, dan ada beberapa produksi yang ditulis dalam C ++, hanya karena kami memiliki tuntutan besar pada efisiensi dan produktivitas. Ketika Anda hidup dalam ekosistem seperti itu, dua masalah muncul.
Pertama-tama, ini adalah masalah eksperimen. Sebagai contoh, seorang ilmuwan data yang bekerja di tim kami mendapat ide. Jika Anda menjalankan semacam algoritma pengelompokan atau klasifikasi dengan parameter yang sedikit berbeda, Anda dapat mencapai kualitas yang lebih baik. Dia mencoba menguji hipotesisnya secara offline, membangun ke dalam proses Python kami, menghitungnya, dan ternyata benar-benar terjadi. Dan sekarang dia ingin percobaan AB, yaitu, bagian dari pengguna untuk menunjukkan algoritma baru dan mengukur beberapa metrik yang sudah online: apakah waktu benar-benar turun, tunggu, penggunaan meningkat. Untuk melakukan ini, ia secara kondisional memiliki lima versi algoritmanya, di mana ia percaya, yang offline memberikan kualitas yang baik: diimplementasikan dalam C ++ dan melakukan percobaan AB. Dan setelah percobaan AB ini, mungkin kelima-duanya akan menuju ke memo, yaitu, kualitas mereka secara daring akan menjadi lebih buruk daripada offline, yaitu, lebih buruk daripada dalam produksi. Artinya, proses eksperimen memakan waktu lama karena fakta bahwa, secara kondisional, dua bahasa berbeda, dua teknologi berbeda.
Ini untuk fitur yang ada. Dan ada yang baru. Dulu titik pengambilan ini juga merupakan ide yang ingin saya periksa dengan cepat. Jangan menghabiskan dua bulan pembangunan - disarankan untuk mendapatkan sesuatu dalam tiga minggu. Untuk membuat prototipe semacam itu cukup melelahkan. Pertama, tulis dengan Python ekstraksi fitur, hanya karena nyaman - bergerak cepat, seperti kata mereka. Anda dapat membangun prototipe apa pun dengan Python, ada banyak pustaka untuk analisis data. Anda bereksperimen di laptop Anda, dan sekarang Anda ingin memeriksa pengguna. Dan untuk membuat prototipe ternyata cukup sulit. Kami sampai pada kesimpulan bahwa kami memerlukan beberapa layanan tambahan untuk merakit prototipe semacam itu dengan agak cepat - kondisional, dalam seminggu atau bahkan dalam sehari - dan juga untuk melakukan percobaan AB.
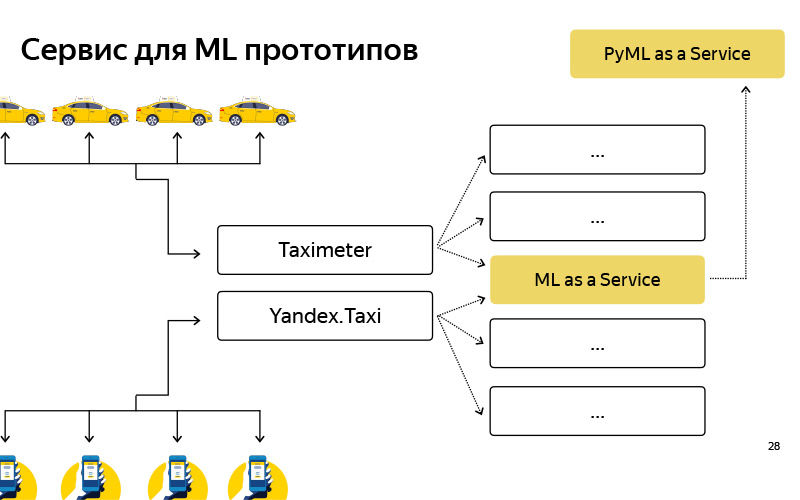
Kami membuat layanan seperti itu, menyebutnya PyMLaaS. Seperti apa dia? Sebenarnya, ini adalah analog lengkap MLaaS, tentang yang saya bicarakan sebelumnya, tetapi ditulis dalam Python berdasarkan Flask, nginx dan Gunicorn. Arsitekturnya cukup sederhana, sama seperti MLaaS, tetapi ada peluang untuk dengan cepat menggali beberapa prototipe dari eksperimen offline Anda. Selain itu, kami mengatur proxy seperti itu pada tingkat nginx, sehingga, secara kondisional, kami memiliki kesempatan untuk meneruskan sebagian beban dari MLaaS ke PyMLaaS dan dengan demikian bereksperimen.

Artinya, kami memindahkan beberapa parameter dan ingin memeriksa bagaimana ini memengaruhi pengguna. Kami memulai 5% dari beban pada PyMLaaS, dan kami akan melihat apa yang terjadi dalam percobaan. Akhirnya, nyaman untuk membuat prototipe. Saya membuat prototipe dari beberapa fitur baru, melihatnya di PyMLaaS dan Anda dapat segera mengujinya dalam produksi.
Kami sangat menyukainya sehingga gagasan itu muncul - mengapa tidak menggunakannya sepanjang waktu? Karena, secara kondisional, ada fitur yang membutuhkan beban besar, 1000 RPS, kebutuhan memori besar. Saya ingin memiliki paralelisme yang cukup fleksibel. Tetapi untuk beberapa fitur, untuk beberapa produk atau layanan yang tidak memiliki tuntutan besar pada beban, kinerja, RPS, dan sebagainya, kami cukup berhasil menggunakan layanan ini.

Untuk meringkas. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .