Pada 26 Februari, kami mengadakan pertemuan Apache Ignite GreenSource, tempat kontributor open source proyek
Apache Ignite melakukan. Peristiwa penting dalam kehidupan komunitas ini adalah restrukturisasi komponen
Grid Layanan Ignite , yang memungkinkan Anda untuk menyebarkan layanan microsoft kustom langsung di cluster Ignite.
Vyacheslav Daradur , pengembang senior Yandex dan kontributor Apache Ignite selama lebih dari dua tahun, berbicara tentang proses yang sulit ini pada pertemuan tersebut.
Untuk mulai dengan, apa itu Apache Ignite secara umum. Ini adalah database yang merupakan repositori Key / Value terdistribusi dengan dukungan untuk SQL, transaksional, dan caching. Selain itu, Ignite memungkinkan Anda untuk menggunakan layanan pengguna secara langsung di cluster Ignite. Pengembang menjadi tersedia semua alat yang Ignite menyediakan - struktur data terdistribusi, Messaging, Streaming, Compute dan Data Grid. Misalnya, ketika menggunakan Kotak Data, masalah administrasi infrastruktur terpisah untuk gudang data dan, sebagai akibatnya, overhead yang dihasilkan dari ini menghilang.

Menggunakan API Kotak Layanan, Anda dapat menggunakan layanan dengan hanya menentukan skema penyebaran dalam konfigurasi dan, karenanya, layanan itu sendiri.
Biasanya, pola penyebaran adalah indikasi jumlah instance yang harus digunakan untuk node cluster. Ada dua pola penyebaran yang khas. Yang pertama adalah Cluster Singleton: kapan saja di cluster, satu contoh layanan pengguna akan dijamin akan tersedia. Yang kedua adalah Node Singleton: satu instance dari layanan ini digunakan pada setiap node cluster.
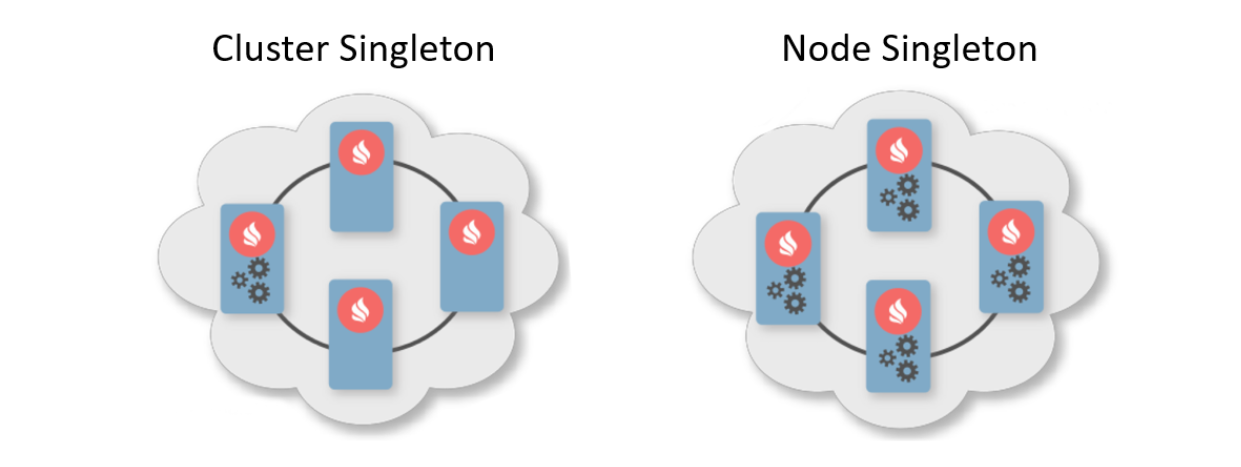
Pengguna juga dapat menentukan jumlah instance layanan di seluruh kluster dan menentukan predikat untuk memfilter node yang sesuai. Dalam skenario ini, Kotak Layanan itu sendiri akan menghitung distribusi optimal untuk penyebaran layanan.
Selain itu, ada fitur seperti Layanan Affinity. Afinitas adalah fungsi yang mendefinisikan hubungan kunci dengan partisi dan hubungan pihak dengan simpul dalam topologi. Dengan menggunakan kunci, Anda dapat menentukan simpul utama tempat data disimpan. Dengan demikian, Anda dapat mengaitkan layanan Anda sendiri dengan kunci dan cache dari fungsi afinitas. Jika fungsi afinitas berubah, operasi ulang otomatis akan terjadi. Jadi layanan akan selalu ditempatkan di sebelah data yang harus dimanipulasi, dan, dengan demikian, mengurangi overhead akses ke informasi. Skema semacam itu dapat disebut semacam komputasi yang ditempatkan.
Sekarang kami telah mengetahui apa keindahan dari Service Grid, kami akan memberi tahu Anda tentang sejarah perkembangannya.
Apa yang sebelumnya
Implementasi sebelumnya dari Service Grid didasarkan pada cache sistem replikasi transite Ignite. Kata "cache" di Ignite berarti penyimpanan. Artinya, ini bukan sesuatu yang sementara, seperti yang mungkin Anda pikirkan. Terlepas dari kenyataan bahwa cache dapat direplikasi dan setiap node berisi seluruh kumpulan data, di dalam cache ia memiliki tampilan yang dipartisi. Ini karena optimasi penyimpanan.

Apa yang terjadi ketika pengguna ingin menggunakan layanan?
- Semua node dalam cluster berlangganan untuk memperbarui data dalam repositori menggunakan mekanisme Continuous Query bawaan.
- Node yang memulai berdasarkan transaksi yang sudah dilakukan membuat catatan dalam database yang berisi konfigurasi layanan, termasuk instance serial.
- Setelah menerima pemberitahuan catatan baru, koordinator menghitung distribusi berdasarkan konfigurasi. Objek yang dihasilkan ditulis kembali ke database.
- Node membaca informasi tentang distribusi baru dan menyebarkan layanan ke
jika perlu.
Apa yang tidak cocok untuk kita
Pada titik tertentu, kami sampai pada kesimpulan: tidak mungkin untuk bekerja dengan layanan. Ada beberapa alasan.
Jika beberapa jenis kesalahan terjadi selama penyebaran, maka Anda bisa mengetahuinya hanya dari log node di mana semuanya terjadi. Hanya ada penyebaran yang tidak sinkron, jadi setelah mengembalikan kontrol dari metode penyebaran ke pengguna, butuh waktu ekstra untuk memulai layanan - dan pada saat itu pengguna tidak dapat mengendalikan apa pun. Untuk mengembangkan Grid Layanan lebih lanjut, untuk melihat fitur-fitur baru, untuk menarik pengguna baru dan membuat hidup lebih mudah bagi semua orang, Anda perlu mengubah sesuatu.
Saat merancang Grid Layanan baru, kami pertama-tama ingin memberikan jaminan penerapan yang sinkron: segera setelah pengguna mengembalikan kontrol dari API, ia dapat segera menggunakan layanan. Saya juga ingin memberi inisiator kesempatan untuk menangani kesalahan penyebaran.
Selain itu, saya ingin memfasilitasi implementasi, yaitu untuk menjauh dari transaksi dan penyeimbangan kembali. Terlepas dari kenyataan bahwa cache dapat direplikasi dan tidak ada penyeimbangan, ada masalah selama penyebaran besar dengan banyak node. Saat mengubah topologi, node perlu bertukar informasi, dan dengan penyebaran yang besar, data ini dapat banyak menimbang.
Ketika topologi tidak stabil, koordinator perlu menghitung ulang distribusi layanan. Dan secara umum, ketika Anda harus bekerja dengan transaksi pada topologi yang tidak stabil, ini dapat menyebabkan kesalahan yang sulit diprediksi.
Masalahnya
Apa perubahan global tanpa disertai masalah? Yang pertama adalah perubahan topologi. Anda perlu memahami bahwa kapan saja, bahkan pada saat penyebaran layanan, sebuah node dapat masuk atau keluar dari sebuah cluster. Selain itu, jika pada saat penyebaran node memasuki cluster, akan diperlukan untuk secara konsisten mentransfer semua informasi tentang layanan ke node baru. Dan kita berbicara tidak hanya tentang apa yang sudah dikerahkan, tetapi juga tentang penyebaran saat ini dan masa depan.
Ini hanyalah salah satu masalah yang dapat disatukan dalam daftar terpisah:
- Bagaimana cara menggunakan layanan yang dikonfigurasi secara statis saat memulai sebuah simpul?
- Node keluar dari cluster - bagaimana jika layanan host host?
- Apa yang harus dilakukan jika koordinator telah berubah?
- Apa yang harus dilakukan jika klien terhubung kembali ke kluster?
- Apakah saya perlu memproses permintaan aktivasi / deaktivasi dan bagaimana caranya?
- Tetapi bagaimana jika mereka disebut Hancurkan cache, dan kami memiliki layanan afinitas yang terikat padanya?
Dan itu belum semuanya.
Solusi
Sebagai target, kami memilih pendekatan Event Driven dengan implementasi proses komunikasi menggunakan pesan. Ignite telah mengimplementasikan dua komponen yang memungkinkan node meneruskan pesan di antara mereka - komunikasi-spi dan penemuan-spi.
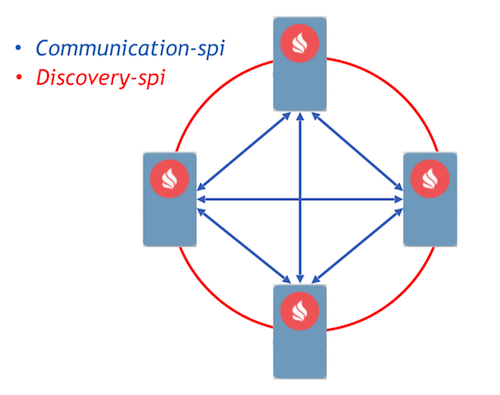
Communication-spi memungkinkan node untuk berkomunikasi dan meneruskan pesan secara langsung. Sangat cocok untuk mengirim data dalam jumlah besar. Discovery-spi memungkinkan Anda untuk mengirim pesan ke semua node di cluster. Dalam implementasi standar, ini dilakukan sesuai dengan topologi ring. Ada juga integrasi dengan Zookeeper, dalam hal ini topologi bintang digunakan. Poin penting lainnya yang perlu diperhatikan: discovery-spi menjamin bahwa pesan akan dikirim dalam urutan yang benar ke semua node.
Pertimbangkan protokol penyebaran. Semua permintaan pengguna untuk penyebaran dan distribusi dikirim melalui discovery-spi. Ini memberikan
jaminan berikut:
- Permintaan akan diterima oleh semua node di cluster. Ini akan memungkinkan Anda untuk terus memproses permintaan saat mengganti koordinator. Ini juga berarti bahwa dalam satu pesan setiap node akan memiliki semua metadata yang diperlukan, seperti konfigurasi layanan dan contoh serialnya.
- Pesanan pengiriman pesan yang ketat memungkinkan Anda untuk menyelesaikan konflik konfigurasi dan permintaan yang bersaing.
- Karena input node ke topologi juga diproses oleh discovery-spi, semua data yang diperlukan untuk bekerja dengan layanan akan sampai ke node baru.
Setelah menerima permintaan, node dalam cluster memvalidasi dan membentuk tugas untuk diproses. Tugas-tugas ini diantrekan dan kemudian diproses di utas lain oleh pekerja terpisah. Ini diimplementasikan dengan cara ini, karena penyebaran bisa memakan waktu yang cukup lama dan menunda aliran penemuan yang mahal tidak dapat diterima.
Semua permintaan dari antrian diproses oleh manajer penempatan. Dia memiliki pekerja khusus yang menarik tugas dari antrian ini dan menginisialisasi untuk memulai penempatan. Setelah ini, tindakan berikut terjadi:
- Setiap node menghitung distribusi secara independen berkat fungsi penetapan deterministik baru.
- Node membentuk pesan dengan hasil penyebaran dan mengirimkannya ke koordinator.
- Koordinator mengumpulkan semua pesan dan menghasilkan hasil dari seluruh proses penyebaran, yang dikirim melalui discovery-spi ke semua node di cluster.
- Setelah menerima hasil, proses penyebaran selesai, setelah itu tugas dihapus dari antrian.
 Desain berbasis event baru: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Desain berbasis event baru: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.javaJika kesalahan terjadi pada saat penyebaran, node segera menyertakan kesalahan ini dalam pesan, yang mengirimkannya ke koordinator. Setelah pengumpulan pesan, koordinator akan memiliki informasi tentang semua kesalahan selama penyebaran dan akan mengirim pesan ini melalui discovery-spi. Informasi kesalahan akan tersedia pada setiap simpul di gugus.
Menurut algoritma ini, semua peristiwa penting di dalam Grid Layanan diproses. Misalnya, perubahan topologi juga merupakan pesan penemuan-spi. Dan secara umum, jika dibandingkan dengan apa itu, protokolnya ternyata cukup ringan dan dapat diandalkan. Begitu banyak untuk menangani situasi apa pun selama penyebaran.
Apa yang akan terjadi selanjutnya?
Sekarang tentang rencananya. Setiap pengembangan besar dalam proyek Ignite dilakukan sebagai inisiatif untuk meningkatkan Ignite, yang disebut IEP. Perancangan ulang Grid Layanan juga memiliki IEP -
IEP No. 17 dengan nama olok-olok "Oil Change in Service Grid". Tapi nyatanya, kami tidak mengganti oli di mesin, tapi seluruh mesin.
Kami membagi tugas dalam IEP menjadi 2 fase. Yang pertama adalah fase utama, yang terdiri dari mengubah protokol penempatan. Sudah dituangkan ke panduan, Anda dapat mencoba Kotak Layanan baru, yang akan muncul di versi 2.8. Fase kedua mencakup banyak tugas lain:
- Penukaran panas
- Versi Layanan
- Peningkatan Resiliensi
- Klien yang kurus
- Alat untuk memantau dan menghitung berbagai metrik
Terakhir, kami dapat menyarankan Anda Service Grid untuk membangun sistem ketersediaan tinggi yang toleran terhadap kesalahan. Kami juga mengundang Anda ke
dev-list dan
daftar pengguna untuk berbagi pengalaman Anda. Pengalaman Anda sangat penting bagi komunitas, itu akan membantu Anda memahami ke mana harus pergi selanjutnya, bagaimana mengembangkan komponen di masa depan.