Hai Pada akhir tahun lalu, kami mulai secara otomatis menyembunyikan nomor plat pada foto di kartu pengumuman Avito. Tentang mengapa kami melakukan ini, dan apa cara untuk menyelesaikan masalah seperti itu, baca artikelnya.

Tantangan
Di Avito pada 2018, 2,5 juta mobil terjual. Ini hampir 7000 sehari. Semua iklan yang dijual membutuhkan ilustrasi - foto mobil. Tetapi dengan nomor negara di atasnya Anda dapat menemukan banyak informasi tambahan tentang mobil. Dan beberapa pengguna kami mencoba untuk menutup plat nomor sendiri.
Alasan mengapa pengguna ingin menyembunyikan nomor plat mungkin berbeda. Untuk bagian kami, kami ingin membantu mereka melindungi data mereka. Dan kami mencoba meningkatkan proses penjualan dan pembelian untuk pengguna. Misalnya, layanan nomor anonim telah lama bekerja dengan kami: ketika Anda menjual mobil, nomor seluler sementara dibuat untuk Anda. Nah, untuk melindungi data di plat nomor, kami menganonimkan foto.

Ikhtisar Solusi
Untuk mengotomatiskan proses melindungi foto pengguna, Anda dapat menggunakan jaringan saraf convolutional untuk mendeteksi poligon dengan plat nomor.
Sekarang, untuk mendeteksi objek, arsitektur dua kelompok digunakan: jaringan dua tahap, misalnya, RCNN Lebih Cepat dan Mask RCNN; satu tahap (singleshot) - SSD, YOLO, RetinaNet. Mendeteksi objek adalah output dari empat koordinat persegi panjang di mana objek yang diinginkan dituliskan.
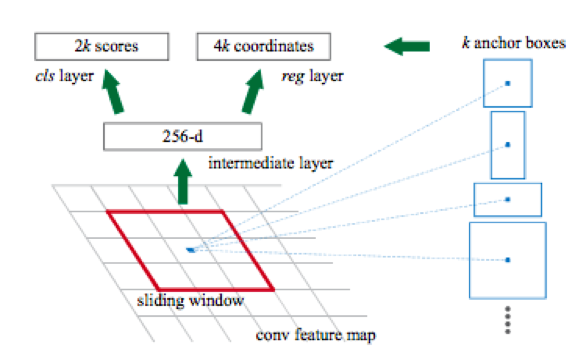
Jaringan yang disebutkan di atas dapat menemukan banyak objek dari kelas yang berbeda dalam gambar, yang sudah berlebihan untuk menyelesaikan masalah pencarian plat nomor, karena kami biasanya hanya memiliki satu mobil dalam gambar (ada pengecualian ketika orang mengambil gambar mobil yang dijual dan tetangga acaknya) , tapi ini jarang terjadi, jadi ini bisa diabaikan).
Fitur lain dari jaringan ini adalah bahwa secara default mereka menghasilkan kotak pembatas dengan sisi yang sejajar dengan sumbu koordinat. Ini terjadi karena satu set jenis bingkai persegi panjang yang telah ditentukan yang disebut kotak jangkar digunakan untuk deteksi. Lebih tepatnya, pertama menggunakan jaringan konvolusional (misalnya, resnet34), matriks atribut diperoleh dari gambar. Kemudian, untuk setiap subset atribut yang diperoleh menggunakan jendela geser, klasifikasi terjadi: apakah ada objek untuk kotak jangkar k atau tidak, dan regresi dilakukan ke dalam empat koordinat bingkai, yang menyesuaikan posisinya.
Baca lebih lanjut tentang ini di
sini .
Setelah itu, ada dua kepala lagi:
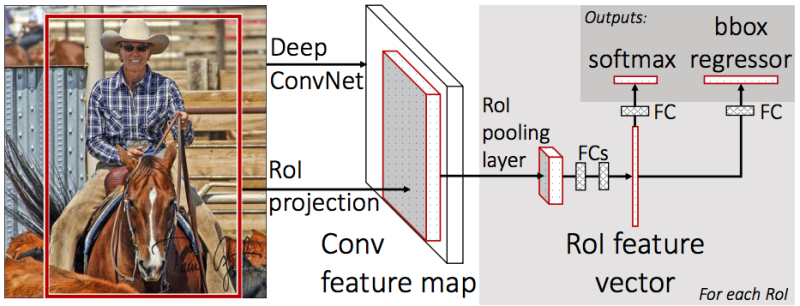
satu untuk mengklasifikasikan objek (anjing / kucing / tanaman, dll),
yang kedua (bbox regressor) - untuk regresi koordinat frame yang diperoleh pada langkah sebelumnya untuk meningkatkan rasio area objek ke area frame.
Untuk memprediksi bingkai tinju yang diputar, Anda perlu mengubah regresi bbox sehingga Anda juga mendapatkan sudut rotasi bingkai. Jika ini tidak dilakukan, maka entah bagaimana akan berubah.

Selain Faster R-CNN dua tahap, ada detektor satu tahap, seperti RetinaNet. Ini berbeda dari arsitektur sebelumnya karena langsung memprediksi kelas dan bingkai, tanpa tahap awal mengusulkan bagian gambar yang mungkin berisi objek. Untuk memprediksi topeng yang diputar, Anda juga harus mengubah kepala subnet kotak.
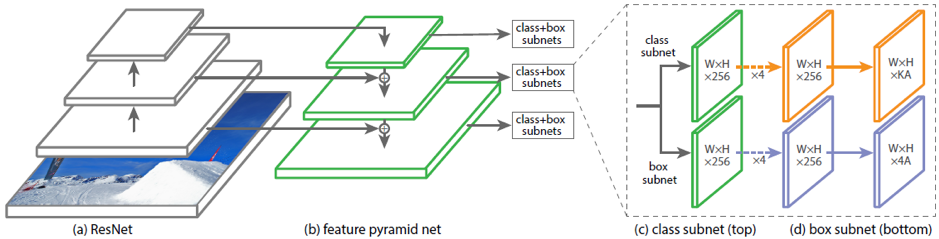
Salah satu contoh arsitektur yang ada untuk memprediksi rotating bounding box adalah DRBOX. Jaringan ini tidak menggunakan tahap awal proposal kawasan, seperti pada RCNN Lebih Cepat, oleh karena itu, ini merupakan modifikasi dari metode satu tahap. Untuk melatih jaringan ini, K diputar pada kotak sudut pembatas tertentu (rbox) digunakan. Jaringan memprediksi probabilitas untuk setiap rbox K untuk memuat objek target, koordinat, ukuran bbox, dan sudut rotasi.

Memodifikasi arsitektur dan melatih kembali salah satu jaringan yang dipertimbangkan pada data dengan kotak pembatas yang diputar adalah tugas yang dapat direalisasikan. Tetapi tujuan kami dapat dicapai dengan lebih mudah, karena ruang lingkup jaringan yang kami miliki jauh lebih sempit - hanya untuk menyembunyikan plat nomor.
Oleh karena itu, kami memutuskan untuk memulai dengan jaringan sederhana untuk memprediksi empat poin dari angka tersebut, dan selanjutnya dimungkinkan untuk mempersulit arsitekturnya.
Data
Perakitan dataset dibagi menjadi dua langkah: untuk mengumpulkan gambar mobil dan menandai area dengan plat nomor pada mereka. Tugas pertama telah diselesaikan dalam infrastruktur kami: kami dengan hati-hati menyimpan semua iklan yang pernah ditempatkan di Avito. Untuk mengatasi masalah kedua, kami menggunakan Toloka. Di
toloka.yandex.ru/requester kami membuat tugas:
Tugas diberikan foto mobil. Penting untuk menyoroti plat nomor mobil menggunakan quadrangle. Dalam hal ini, nomor negara harus dialokasikan seakurat mungkin.

Menggunakan Toloka, Anda dapat membuat tugas untuk menandai data. Misalnya, mengevaluasi kualitas hasil pencarian, menandai berbagai kelas objek (teks dan gambar), menandai video, dll. Mereka akan dilakukan oleh pengguna Toloka, untuk biaya yang Anda kenakan. Misalnya, dalam kasus kami, toloker harus menyorot TPA dengan nomor plat mobil di foto. Secara umum, sangat nyaman untuk menandai dataset yang besar, tetapi mendapatkan kualitas tinggi cukup sulit. Ada banyak bot di kerumunan, tugasnya adalah mendapatkan uang dari Anda dengan memberikan jawaban secara acak atau menggunakan semacam strategi. Untuk mengatasi bot ini ada sistem aturan dan pemeriksaan. Pemeriksaan utama adalah pencampuran pertanyaan kontrol: Anda secara manual menandai bagian dari tugas menggunakan antarmuka Toloki, dan kemudian mencampurnya ke dalam tugas utama. Jika markup sering keliru pada pertanyaan kontrol, Anda memblokirnya dan tidak memperhitungkan markup.
Untuk tugas klasifikasi, sangat mudah untuk menentukan apakah penandaan itu salah atau tidak, dan untuk masalah menyoroti suatu wilayah, itu tidak begitu sederhana. Cara klasik adalah menghitung IoU.
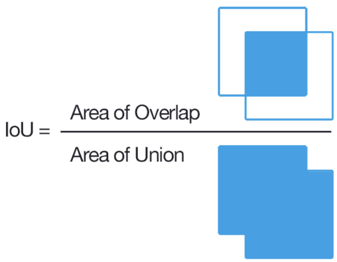
Jika rasio ini kurang dari ambang tertentu untuk beberapa tugas, maka pengguna tersebut diblokir. Namun, untuk dua quadrangles sewenang-wenang, menghitung IoU tidak begitu sederhana, terutama karena di Tolok perlu menerapkan ini dalam JavaScript. Kami membuat retasan kecil, dan kami percaya bahwa pengguna tidak salah jika untuk setiap titik poligon sumber di lingkungan kecil ada titik yang ditandai dengan juru tulis. Ada juga aturan respons cepat untuk memblokir respons pengguna terlalu cepat, captcha, perbedaan dengan pendapat mayoritas, dll. Setelah menyiapkan aturan ini, Anda dapat mengharapkan markup yang cukup bagus, tetapi jika Anda benar-benar membutuhkan markup yang berkualitas tinggi dan kompleks, Anda perlu menyewa scribers freelancer secara khusus. Akibatnya, set data kami berjumlah 4k gambar yang ditandai, dan semuanya berharga $ 28 di Tolok.
Model
Sekarang mari kita membuat jaringan untuk memprediksi empat titik area. Kami akan mendapatkan tanda-tanda menggunakan resnet18 (parameter 11,7M versus parameter 21,8M untuk resnet34), kemudian kami membuat kepala untuk regresi ke empat poin (delapan koordinat) dan kepala untuk klasifikasi apakah ada plat nomor dalam gambar atau tidak. Kepala kedua diperlukan, karena dalam iklan untuk penjualan mobil, tidak semua foto dengan mobil. Foto mungkin detail mobil.

Mirip dengan kita, tentu saja, tidak perlu dideteksi.
Kami melatih dua tujuan secara bersamaan dengan menambahkan ke dataset sebuah foto tanpa plat dengan kotak pembatas (0,0,0,0,0,0,0,0,0,0) dan nilai untuk "gambar dengan / tanpa plat nomor" - (0, 1).
Kemudian Anda dapat membuat fungsi kerugian tunggal untuk kedua sasaran sebagai jumlah dari kerugian berikut. Untuk regresi ke koordinat poligon plat kami menggunakan kerugian L1 halus.
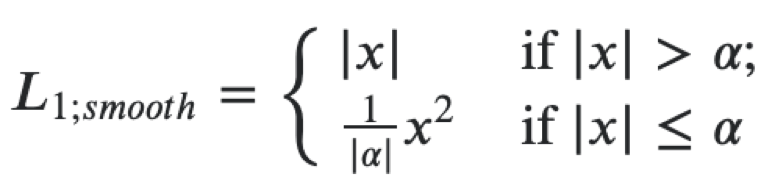
Ini dapat diartikan sebagai kombinasi L1 dan L2, yang berperilaku seperti L1 ketika nilai absolut dari argumen besar dan sebagai L2 ketika nilai argumen mendekati nol. Untuk klasifikasi, kami menggunakan kerugian softmax dan crossentropy. Extractor fitur resnet18, kami menggunakan bobot yang sudah dilatih sebelumnya di ImageNet, lalu kami akan melatih ekstraktor dan kepala lebih lanjut pada dataset kami. Dalam masalah ini, kami menggunakan kerangka mxnet, karena itu adalah yang utama untuk visi komputer di Avito. Secara umum, arsitektur microservice memungkinkan Anda untuk tidak terikat pada kerangka kerja tertentu, tetapi ketika Anda memiliki basis kode yang besar, lebih baik untuk menggunakannya dan tidak menulis kode yang sama lagi.
Setelah menerima kualitas yang dapat diterima pada dataset kami, kami berpaling kepada para perancang untuk memberi kami plat nomor dengan logo Avito. Awalnya kami mencoba melakukannya sendiri, tentu saja, tetapi itu tidak terlihat sangat indah. Selanjutnya, Anda perlu mengubah kecerahan plat nomor Avito ke kecerahan area asli dengan plat nomor dan Anda dapat menumpangkan logo pada gambar.

Luncurkan dalam prod
Masalah reproduktifitas hasil, dukungan dan pengembangan proyek, diselesaikan dengan beberapa kesalahan dalam dunia pengembangan backend dan frontend, masih berdiri terbuka di mana diperlukan untuk menggunakan model pembelajaran mesin. Anda mungkin harus memahami model kode lama. Baik jika readme memiliki tautan ke artikel atau repositori open source yang menjadi dasar solusinya. Skrip untuk memulai pelatihan ulang mungkin gagal dengan kesalahan, misalnya, versi cudnn telah berubah, dan versi tensorflow tidak lagi berfungsi dengan versi cudnn ini, dan cudnn tidak berfungsi dengan versi driver nvidia ini. Mungkin untuk pelatihan kami menggunakan satu iterator sesuai dengan data, dan untuk pengujian dalam produksi yang lain. Ini dapat berlanjut untuk beberapa waktu. Secara umum, masalah reproduktifitas ada.
Kami mencoba menghapusnya menggunakan lingkungan nvidia-docker untuk model pelatihan, ia memiliki semua dependensi yang diperlukan untuk suda, dan kami juga menginstal dependensi untuk python di sana. Versi perpustakaan dengan iterator sesuai dengan data, augmentasi, dan model inferensi adalah umum untuk tahap pelatihan / percobaan dan untuk produksi. Jadi, untuk melatih model pada data baru, Anda perlu memompa repositori ke server, menjalankan skrip shell yang akan mengumpulkan lingkungan buruh pelabuhan, di mana notebook jupyter akan naik. Di dalam, Anda akan memiliki semua buku catatan untuk pelatihan dan pengujian, yang tentunya tidak akan gagal dengan kesalahan karena lingkungan. Tentu saja, lebih baik memiliki satu file train.py, tetapi latihan menunjukkan bahwa Anda selalu perlu melihat dengan mata Anda apa yang diberikan oleh model dan mengubah sesuatu dalam proses pembelajaran, jadi pada akhirnya Anda akan tetap menjalankan jupyter.
Bobot model disimpan dalam git lfs - ini adalah teknologi khusus untuk menyimpan file besar dalam git. Sebelum itu, kami menggunakan artifaktor, tetapi menggunakan git lfs lebih nyaman, karena mengunduh repositori dengan layanan, Anda segera mendapatkan versi skala timbangan saat ini, seperti dalam produksi. Autotests ditulis untuk inferensi model, sehingga Anda tidak akan dapat meluncurkan layanan dengan bobot yang tidak lulus. Layanan itu sendiri diluncurkan di buruh pelabuhan di dalam infrastruktur microservice di cluster kubernetes. Untuk memantau kinerja, kami menggunakan grafana. Setelah bergulir, kami secara bertahap meningkatkan beban pada instance layanan dengan model baru. Saat meluncurkan fitur baru, kami membuat tes a / b dan mengeluarkan putusan tentang nasib fitur tersebut di masa mendatang, berdasarkan pada uji statistik.
Sebagai hasilnya: kami meluncurkan pemangkasan angka pada iklan dalam kategori otomatis untuk pedagang swasta, persentil ke-95 dari waktu pemrosesan satu gambar untuk menyembunyikan angkanya adalah 250 ms.