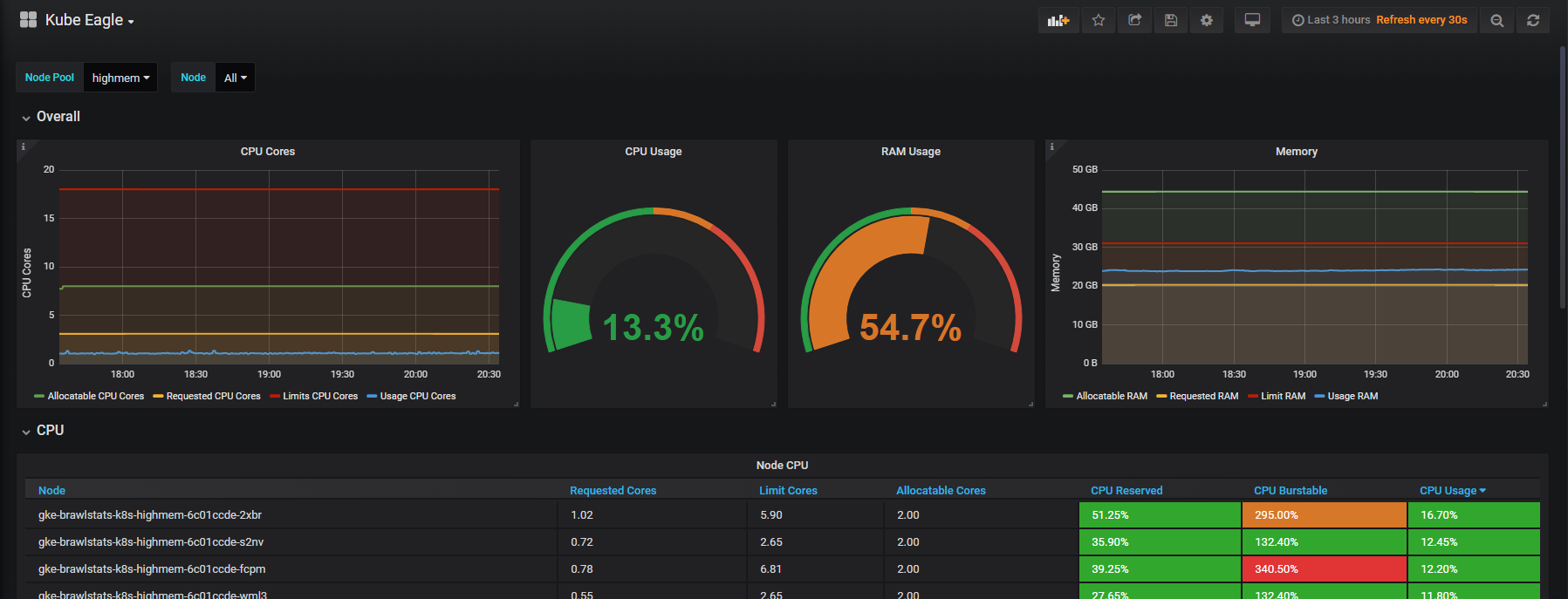
Saya membuat Kube Eagle - pengekspor Prometheus. Ternyata menjadi hal yang keren yang membantu untuk lebih memahami sumber daya cluster kecil dan menengah. Akibatnya, saya menghemat lebih dari seratus dolar, karena saya memilih jenis mesin yang tepat dan mengkonfigurasi batas sumber daya aplikasi untuk beban kerja.
Saya akan berbicara tentang kelebihan Kube Eagle , tetapi pertama-tama saya akan menjelaskan mengapa keributan muncul dan mengapa pemantauan berkualitas tinggi diperlukan.
Saya berhasil beberapa cluster 4-50 node. Di setiap cluster - hingga 200 layanan dan aplikasi mikro. Untuk memanfaatkan perangkat keras yang tersedia dengan lebih baik, sebagian besar penyebaran dikonfigurasikan dengan RAM dan CPU yang dapat meledak. Jadi polong dapat mengambil sumber daya yang tersedia, jika perlu, dan pada saat yang sama tidak mengganggu aplikasi lain pada simpul ini. Yah, bagus kan?
Dan meskipun cluster mengkonsumsi CPU yang relatif sedikit (8%) dan RAM (40%), kami terus-menerus mengalami masalah dengan crowding out hearths ketika mereka mencoba mengalokasikan lebih banyak memori daripada yang tersedia pada node. Kemudian kami hanya memiliki satu dasbor untuk memantau sumber daya Kubernetes. Ini satu:
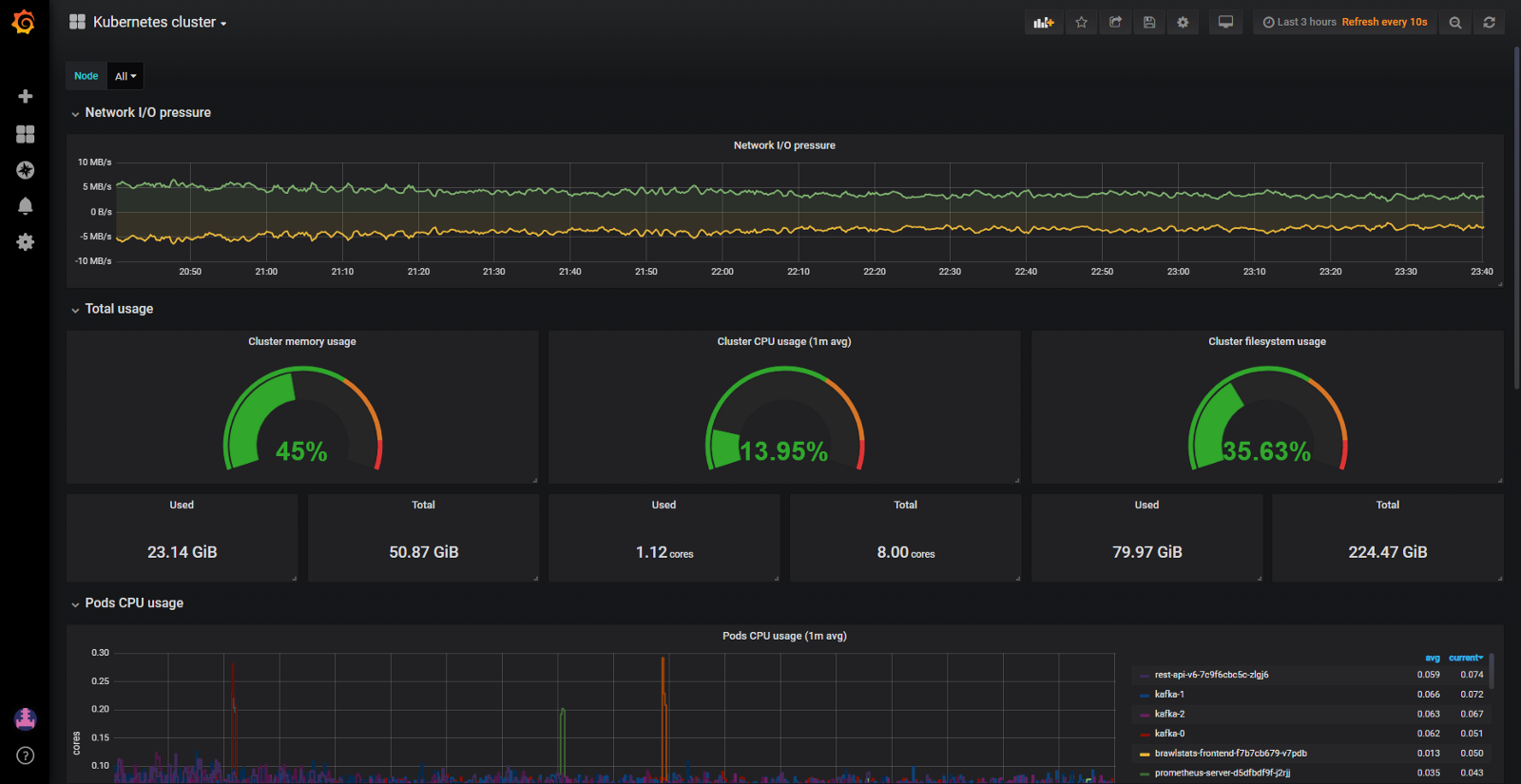
Dasbor Grafana dengan metrik cAdvisor saja
Dengan panel seperti itu, node yang memakan banyak memori dan CPU tidak menjadi masalah. Masalahnya adalah untuk mencari tahu alasannya. Untuk mempertahankan pod, Anda tentu saja dapat mengkonfigurasi sumber daya yang dijamin pada semua pod (sumber yang diminta sama dengan batas). Tapi ini bukan penggunaan besi yang paling cerdas. Ada beberapa ratus gigabytes memori di cluster, sementara beberapa node kelaparan, sementara yang lain memiliki cadangan 4-10 GB.
Ternyata penjadwal Kubernetes mendistribusikan beban kerja di sumber daya yang tersedia secara tidak merata. Penjadwal Kubernetes mempertimbangkan konfigurasi yang berbeda: aturan afinitas, noda dan toleransi, penyeleksi simpul yang dapat membatasi simpul yang tersedia. Tetapi dalam kasus saya tidak ada yang seperti itu, dan polong direncanakan tergantung pada sumber daya yang diminta pada setiap node.
Untuk perapian, sebuah node dipilih yang memiliki sumber daya paling bebas dan yang memenuhi kondisi permintaan. Ternyata sumber daya yang diminta pada node tidak sesuai dengan penggunaan yang sebenarnya, dan di sini Kube Eagle dan kemampuannya untuk memantau sumber daya datang untuk menyelamatkan.
Saya memiliki hampir semua cluster Kubernetes dilacak hanya dengan eksportir Node dan Metrik Kube State . Eksportir Node menyediakan statistik tentang I / O dan penggunaan disk, CPU dan RAM, dan Metrik Kube State menampilkan metrik objek Kubernetes, seperti permintaan dan batasan pada CPU dan sumber daya memori.
Kita perlu menggabungkan metrik penggunaan dengan metrik kueri dan batas di Grafana, dan kemudian kita mendapatkan semua informasi tentang masalah tersebut. Kedengarannya sederhana, tetapi pada kenyataannya, kedua alat ini memiliki nama yang berbeda untuk label, dan beberapa metrik tidak memiliki label metadata sama sekali. Kube Eagle melakukan semuanya sendiri dan panelnya terlihat seperti ini:
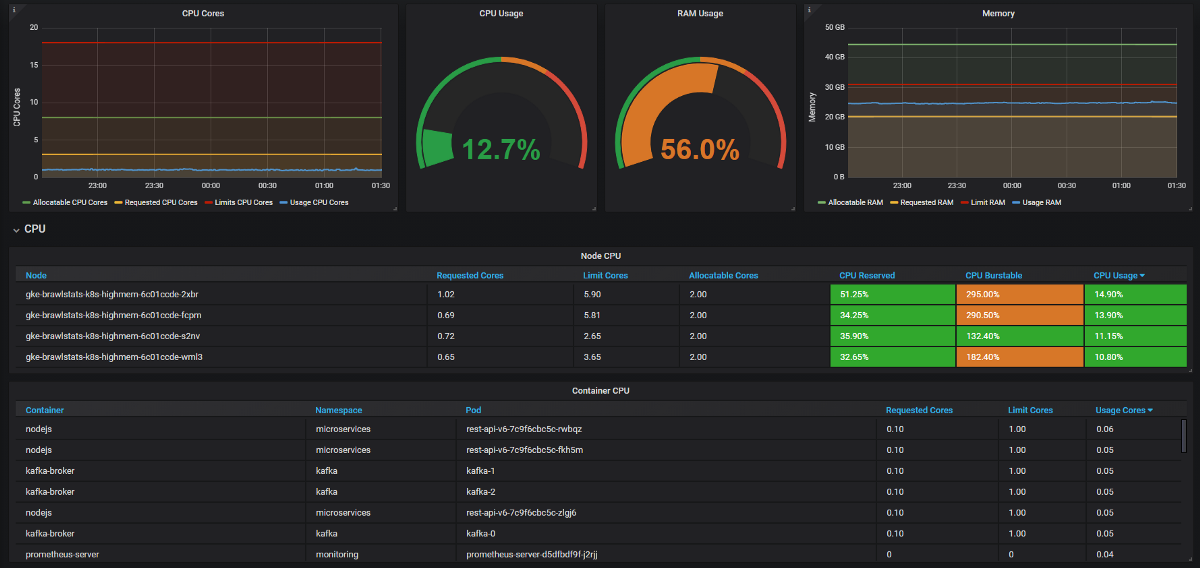
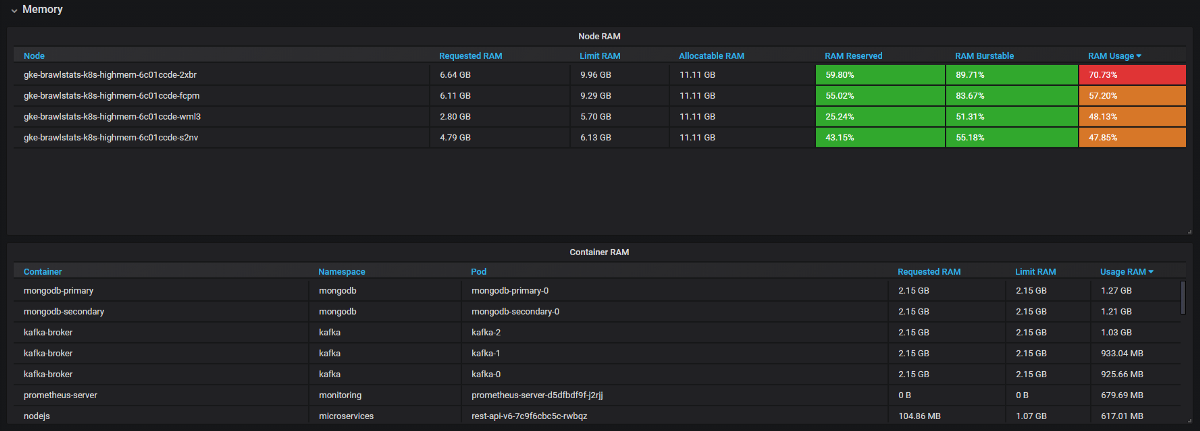
Dashboard Kube Eagle
Kami berhasil memecahkan banyak masalah dengan sumber daya dan menghemat peralatan:
- Beberapa pengembang tidak tahu berapa banyak sumber daya yang diperlukan layanan microser (atau hanya tidak peduli). Kami tidak menemukan apa pun yang salah dengan permintaan sumber daya - untuk ini kami perlu mengetahui konsumsi ditambah permintaan dan batasan. Sekarang mereka melihat metrik Prometheus, memantau penggunaan aktual, dan menyempurnakan kueri serta batasan.
- Aplikasi JVM mengambil RAM sebanyak yang mereka ambil. Pengumpul sampah membebaskan memori hanya jika lebih dari 75% terlibat. Dan karena sebagian besar layanan memiliki memori yang dapat meledak, JVM selalu menempatinya. Oleh karena itu, semua layanan Java ini mengkonsumsi lebih banyak RAM daripada yang diperkirakan.
- Beberapa aplikasi meminta terlalu banyak memori, dan scheduler Kubernetes tidak memberikan node ini ke aplikasi lain, meskipun pada kenyataannya mereka lebih bebas daripada node lain. Satu pengembang tanpa sengaja menambahkan satu digit tambahan dalam permintaan dan meraih sebagian besar RAM: 20 GB, bukannya 2. Tidak ada yang memperhatikan. Aplikasi memiliki 3 replika, sehingga 3 node terpengaruh.
- Kami memperkenalkan batas sumber daya, merencanakan ulang pod dengan permintaan yang benar, dan mendapatkan keseimbangan sempurna menggunakan besi di semua node. Beberapa node umumnya dapat ditutup. Dan kemudian kami melihat bahwa kami memiliki mesin yang salah (berorientasi pada CPU, bukan berorientasi pada memori). Kami mengubah jenis dan menghapus beberapa node lagi.
Ringkasan
Dengan sumber daya yang dapat meledak di sebuah cluster, Anda menggunakan perangkat keras yang ada secara lebih efisien, tetapi penjadwal Kubernet menjadwalkan pod pada permintaan sumber daya, yang penuh. Untuk membunuh dua burung dengan satu batu: untuk menghindari masalah, dan untuk menggunakan sumber daya sepenuhnya, diperlukan pemantauan yang baik. Kube Eagle (pengekspor Prometheus dan dasbor Grafana) berguna untuk ini.