Pada bulan Februari-Maret 2019, diadakan kompetisi untuk memberi peringkat umpan jejaring sosial SNA Hackathon 2019 , di mana tim kami mengambil tempat pertama. Pada artikel ini saya akan berbicara tentang organisasi kontes, metode yang kami coba, dan pengaturan catboost untuk pelatihan tentang data besar.

SNA Hackathon
Hackathon dengan nama ini diadakan untuk ketiga kalinya. Ini diatur oleh jejaring sosial ok.ru, masing-masing, tugas dan data terkait langsung dengan jejaring sosial ini.
SNA (analisis jejaring sosial) dalam hal ini lebih baik dipahami bukan sebagai analisis grafik sosial, melainkan sebagai analisis jejaring sosial.
- Pada tahun 2014, tugasnya adalah memprediksi jumlah suka yang akan diperoleh pos.
- Pada tahun 2016, tujuan VVZ (mungkin Anda sudah familiar), lebih dekat dengan analisis grafik sosial.
- Pada tahun 2019 - peringkat umpan pengguna berdasarkan kemungkinan bahwa pengguna akan menyukai posting tersebut.
Saya tidak bisa mengatakan tentang 2014, tetapi pada 2016 dan 2019, selain kemampuan untuk menganalisis data, keterampilan dalam bekerja dengan data besar juga diperlukan. Saya pikir itu adalah kombinasi dari pembelajaran mesin dan tugas pemrosesan data besar yang menarik saya ke kontes ini, dan pengalaman di bidang ini membantu untuk menang.
mlbootcamp
Pada 2019, kompetisi diselenggarakan di platform https://mlbootcamp.ru .
Kompetisi mulai online 7 Februari dan terdiri dari 3 tugas. Setiap orang dapat mendaftar di situs, mengunduh baseline, dan mengunggah mobil mereka selama beberapa jam. Pada akhir tahap online pada 15 Maret, 15 besar dari setiap pertunjukan diundang ke kantor Mail.ru untuk tahap offline, yang berlangsung dari 30 Maret hingga 1 April.
Tantangan
Sumber data menyediakan pengidentifikasi pengguna (userId) dan pengidentifikasi pos (objectId). Jika pengguna ditampilkan sebuah posting, maka data tersebut berisi garis yang berisi userId, objectId, reaksi pengguna terhadap posting ini (umpan balik) dan satu set berbagai tanda atau tautan ke gambar dan teks.
| userId | objectId | ownerId | umpan balik | gambar |
|---|
| 3555 | 22 | 5677 | [disukai, diklik] | [hash1] |
| 12842 | 55 | 32144 | [tidak disukai] | [hash2, hash3] |
| 13145 | 35 | 5677 | [diklik, dibagikan ulang] | [hash2] |
Set data uji berisi struktur yang serupa, tetapi bidang umpan balik tidak ada. Tujuannya adalah untuk memprediksi kehadiran reaksi 'disukai' di bidang umpan balik.
File kirim memiliki struktur berikut:
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35.61.55 |
| 131 | 35,68.129,11 |
Metrik - rata - rata ROC AUC oleh pengguna.
Deskripsi data yang lebih terperinci dapat ditemukan di situs kesempurnaan . Anda juga dapat mengunduh data di sana, termasuk tes dan gambar.
Panggung online
Pada tahap online, tugas dibagi menjadi 3 bagian
- Sistem kolaboratif - mencakup semua tanda, kecuali untuk gambar dan teks;
- Gambar - hanya menyertakan informasi tentang gambar;
- Teks - hanya menyertakan informasi tentang teks.
Tahap offline
Pada tahap offline, data menyertakan semua atribut, sedangkan teks dan gambar jarang. Ada 1,5 kali lebih banyak baris dalam dataset, yang sudah banyak.
Pemecahan masalah
Karena saya melakukan cv di tempat kerja, saya memulai perjalanan saya dalam kompetisi ini dengan tugas "Gambar". Data yang disediakan adalah userId, objectId, ownerId (grup tempat posting diterbitkan), cap waktu membuat dan menampilkan posting, dan, tentu saja, gambar untuk posting ini.
Setelah membuat beberapa fitur berdasarkan stempel waktu, ide berikutnya adalah mengambil lapisan kedua dari belakang neuron yang sudah dilatih imagenet dan mengirimkan embed ini untuk ditingkatkan.
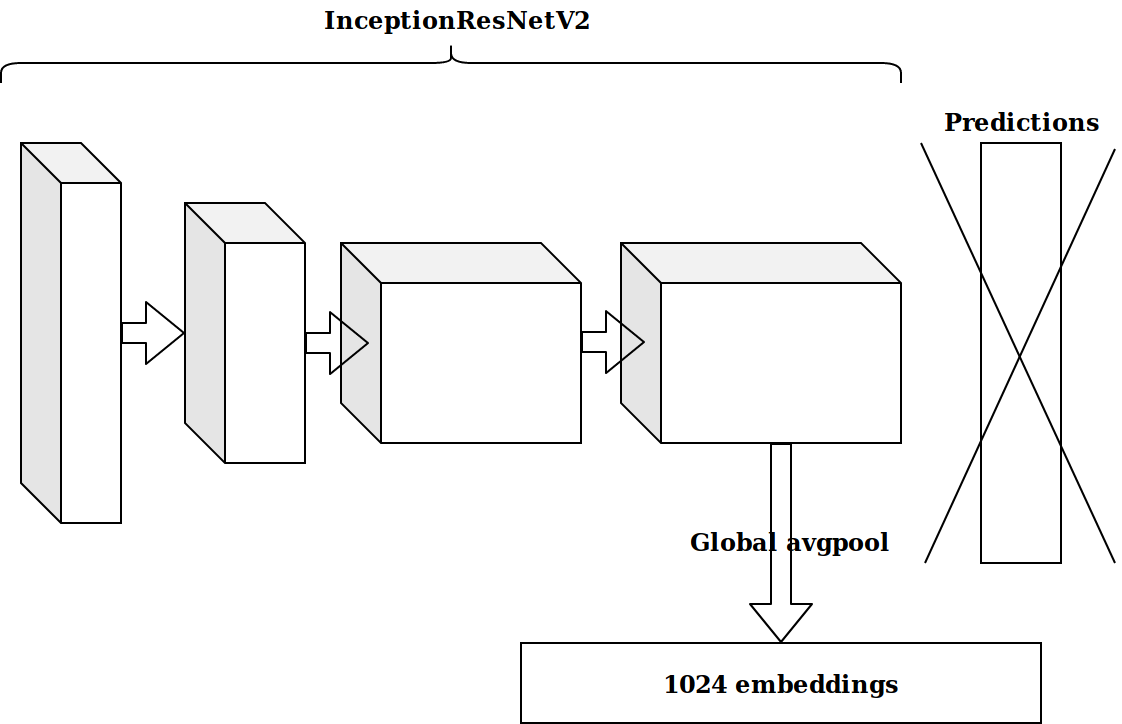
Hasilnya tidak mengesankan. Embeddings dari neuron imagenet tidak relevan, saya pikir, saya perlu mengajukan encoder otomatis saya.
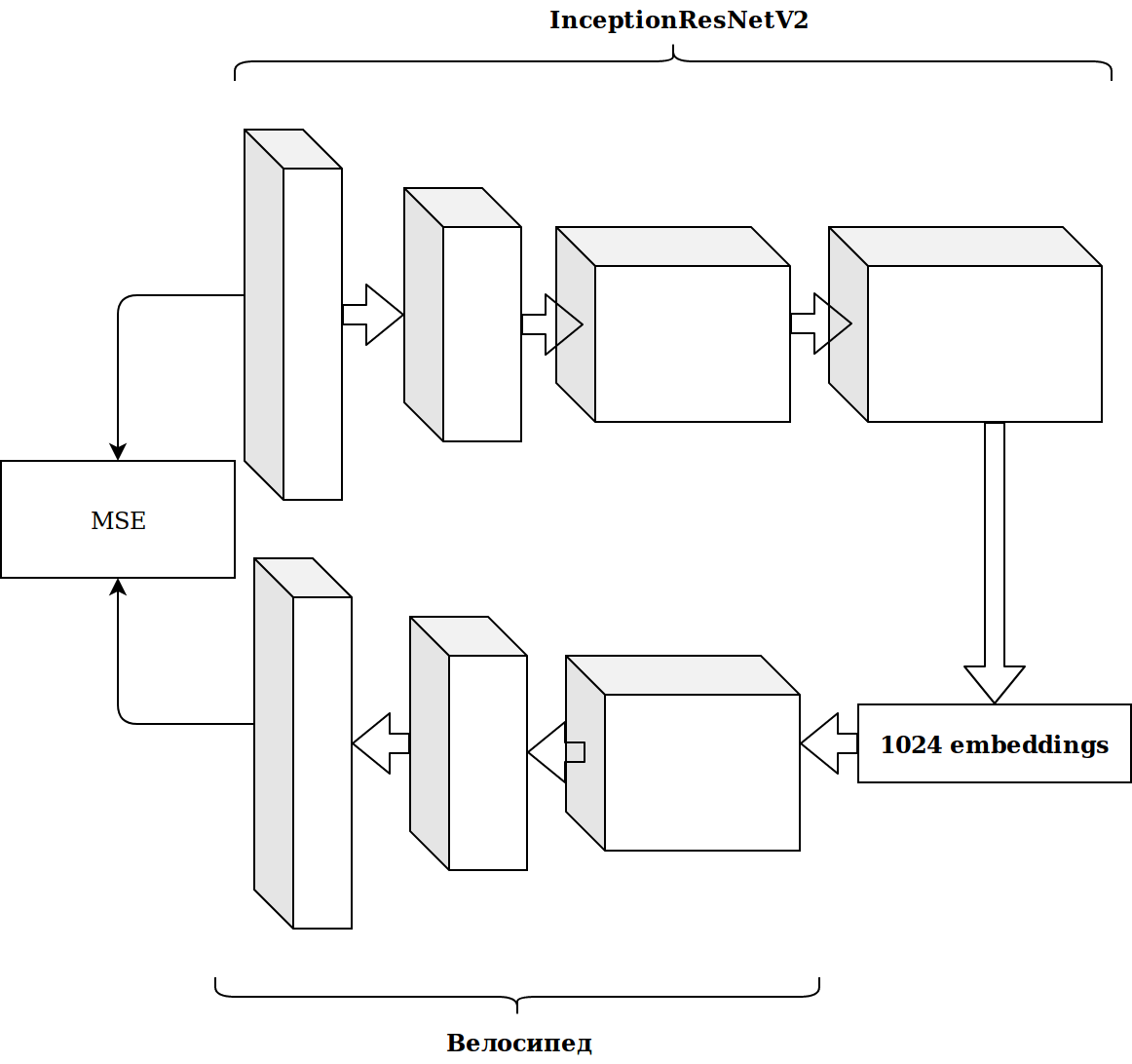
Butuh banyak waktu dan hasilnya tidak membaik.
Pembuatan Fitur
Bekerja dengan gambar membutuhkan banyak waktu, dan saya memutuskan untuk melakukan sesuatu yang lebih sederhana.
Seperti yang dapat Anda lihat segera, ada beberapa tanda kategoris dalam dataset, dan agar tidak terlalu merepotkan, saya hanya mengambil catboost. Solusinya luar biasa, tanpa pengaturan apa pun, saya langsung sampai ke baris pertama papan peringkat.
Ada banyak data dan mereka diletakkan dalam format parket, jadi tanpa berpikir dua kali, saya mengambil scala dan mulai menulis semuanya dalam percikan.
Fitur paling sederhana, yang memberikan pertumbuhan lebih dari embeddings gambar:
- berapa kali objectId, userId, dan ownerId bertemu dalam data (harus berkorelasi dengan popularitas);
- berapa banyak posting userId yang dilihat ownerId (harus berkorelasi dengan minat pengguna dalam grup);
- berapa banyak pos unik userId yang ditonton oleh ownerId (mencerminkan ukuran audiens grup).
Dari cap waktu dimungkinkan untuk mendapatkan waktu di mana pengguna menonton rekaman itu (pagi / siang / malam / malam). Dengan menggabungkan kategori-kategori ini, Anda dapat terus menghasilkan fitur:
- berapa kali userId login di malam hari;
- jam berapa posting ini sering ditampilkan (objectId) dan sebagainya.
Semua ini secara bertahap meningkatkan metrik. Tetapi ukuran dataset pelatihan sekitar 20 juta catatan, jadi menambahkan fitur sangat memperlambat pembelajaran.
Saya mendefinisikan ulang pendekatan penggunaan data. Meskipun data tergantung pada waktu, saya belum melihat ada informasi eksplisit yang bocor di masa depan, namun, untuk berjaga-jaga, saya mematahkannya seperti ini:
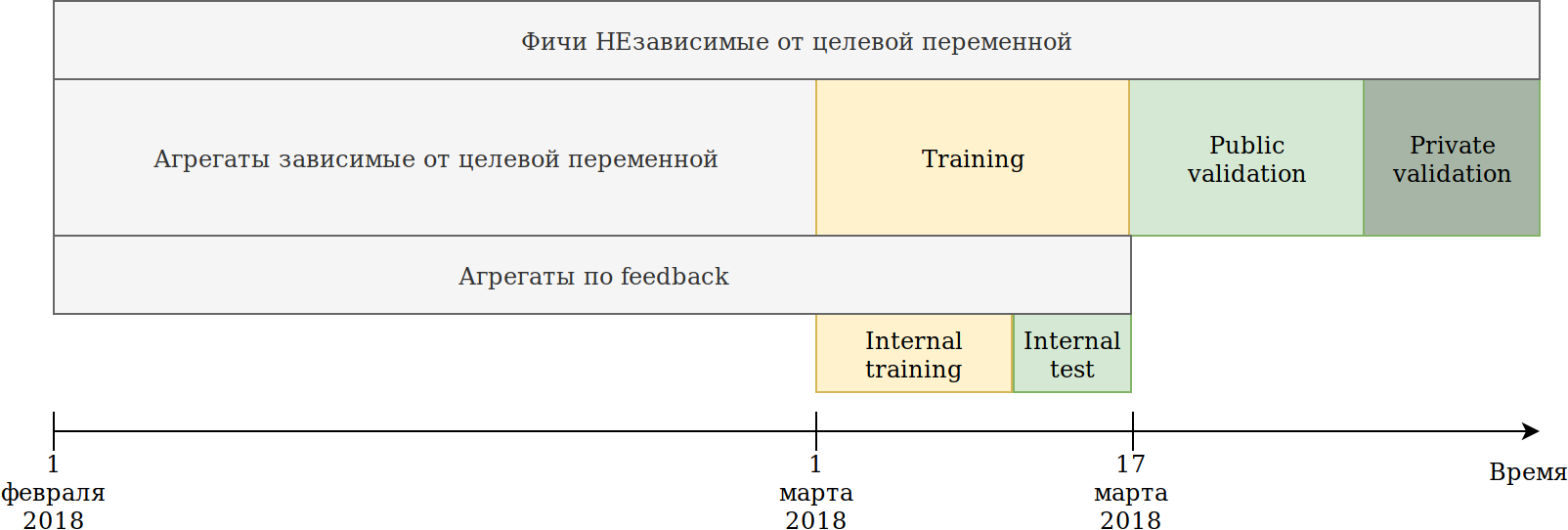
Set pelatihan yang diberikan kepada kami (Februari dan 2 minggu Maret) dibagi menjadi 2 bagian.
Pada data N hari terakhir ia melatih model. Agregasi yang dijelaskan di atas dibangun di atas semua data, termasuk tes. Pada saat yang sama, data muncul di mana berbagai encoders dari variabel target dapat dibangun. Pendekatan paling sederhana adalah dengan menggunakan kembali kode yang sudah membuat fitur baru, dan cukup berikan dengan data yang tidak akan dilatih dan target = 1.
Dengan demikian, kami mendapat fitur serupa:
- Berapa kali userId telah melihat pos di grup ownerId;
- Berapa kali userId menyukai pos ke ownerId;
- Persentase pos yang disukai penggunaId pemilikId.
Artinya, ternyata target maksud pengkodean pada bagian dataset sesuai dengan berbagai kombinasi fitur kategorikal. Pada prinsipnya, catboost juga membangun pengkodean target, dan dari sudut pandang ini tidak ada manfaatnya, tetapi, misalnya, menjadi mungkin untuk menghitung jumlah pengguna unik yang menyukai posting di grup ini. Pada saat yang sama, tujuan utama tercapai - dataset saya menurun beberapa kali, dan dimungkinkan untuk terus menghasilkan fitur.
Sementara catboost hanya dapat membangun encoders sesuai dengan reaksi suka, umpan balik memiliki reaksi lain: dibagikan ulang, tidak disukai, tidak disukai, diklik, diabaikan, yang dapat dilakukan secara manual. Saya menceritakan semua jenis agregat dan menyaring fitur dengan kepentingan rendah, agar tidak mengembang dataset.
Pada saat itu saya berada di tempat pertama dengan selisih yang lebar. Satu-satunya hal yang memalukan adalah bahwa pemasangan gambar hampir tidak memberikan keuntungan. Idenya datang untuk memberikan segalanya kepada catboost. Cluster Kmeans gambar dan dapatkan imageCat fitur kategori baru.
Berikut adalah beberapa kelas setelah secara manual memfilter dan menggabungkan kluster yang diperoleh dari KMeans.

Berdasarkan imageCat kami menghasilkan:
- Fitur kategorikal baru:
- ImageCat apa yang paling sering terlihat userId;
- ImageCat mana yang paling sering ditampilkan oleh ownerId;
- ImageCat mana yang paling sering disukai userId;
- Berbagai penghitung:
- Berapa banyak imageCat unik yang tampak userId;
- Sekitar 15 fitur serupa ditambah pengodean target seperti dijelaskan di atas.
Teks
Hasil dalam kontes gambar cocok untuk saya dan saya memutuskan untuk mencoba sendiri dalam teks. Sebelumnya, saya tidak banyak bekerja dengan teks dan, karena kebodohan, saya membunuh sehari di tf-idf dan svd. Lalu saya melihat garis dasar dengan doc2vec, yang tidak hanya apa yang saya butuhkan. Setelah sedikit menyesuaikan parameter doc2vec, saya menerima embeddings teks.
Dan kemudian dia hanya menggunakan kembali kode untuk gambar, di mana dia mengganti gambar embeddings dengan embeddings teks. Alhasil, saya mendapat posisi ke-2 dalam kontes teks.
Sistem kolaboratif
Hanya ada satu kompetisi di mana saya belum "menyodok", tetapi menilai oleh AUC di leaderboard, hasil kompetisi khusus ini seharusnya memiliki dampak terbesar pada tahap offline.
Saya mengambil semua tanda yang ada di sumber data, memilih yang kategorikal dan menghitung agregat yang sama seperti untuk gambar, kecuali untuk fitur dari gambar itu sendiri. Hanya menempatkannya di catboost, saya sampai di posisi ke-2.
Langkah pertama untuk mengoptimalkan catboost
Satu tempat pertama dan kedua menyenangkan saya, tetapi ada pemahaman bahwa saya tidak melakukan sesuatu yang istimewa, yang berarti bahwa kita dapat mengharapkan kehilangan posisi.
Tugas kompetisi adalah untuk menentukan peringkat tulisan dalam kerangka kerja pengguna, dan selama ini saya telah memecahkan masalah klasifikasi, yaitu, saya telah mengoptimalkan metrik yang salah.
Saya akan memberikan contoh sederhana:
| userId | objectId | prediksi | kebenaran dasar |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 1 |
| 1 | 14 | 0,5 | 0 |
| 2 | 15 | 0,4 | 0 |
| 2 | 16 | 0,3 | 1 |
Kami melakukan permutasi kecil
| userId | objectId | prediksi | kebenaran dasar |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 0 |
| 2 | 16 | 0,5 | 1 |
| 2 | 15 | 0,4 | 0 |
| 1 | 14 | 0,3 | 1 |
Kami mendapatkan hasil sebagai berikut:
| Model | Auc | User1 AUC | User2 AUC | berarti AUC |
|---|
| Opsi 1 | 0.8 | 1,0 | 0,0 | 0,5 |
| Opsi 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Seperti yang Anda lihat, meningkatkan keseluruhan metrik AUC tidak berarti meningkatkan rata-rata metrik AUC dalam pengguna.
Catboost dapat mengoptimalkan metrik peringkat di luar kotak. Saya membaca tentang metrik peringkat, kisah sukses ketika menggunakan catboost dan mengatur YetiRankPairwise untuk belajar malam itu. Hasilnya tidak mengesankan. Setelah memutuskan bahwa saya belum belajar dengan baik, saya mengubah fungsi kesalahan menjadi QueryRMSE, yang, dilihat dari dokumentasi catboost, lebih cepat menyatu. Hasilnya, saya mendapat hasil yang sama seperti saat pelatihan untuk klasifikasi, tetapi ansambel kedua model ini memberikan peningkatan yang baik, yang membawa saya ke tempat pertama di ketiga kompetisi.
5 menit sebelum penutupan panggung online dalam kompetisi Sistem Kolaboratif, Sergey Shalnov memindahkan saya ke tempat kedua. Cara selanjutnya kami pergi bersama.
Mempersiapkan fase offline
Kemenangan di panggung online dijamin bagi kami di kartu video RTX 2080 TI, tetapi hadiah utama 300.000 rubel dan, bahkan, tempat pertama terakhir memaksa kami untuk bekerja selama 2 minggu ini.
Ternyata, Sergey juga menggunakan catboost. Kami bertukar ide dan fitur, dan saya mengetahui tentang laporan Anna Veronika Dorogush di mana ada jawaban untuk banyak pertanyaan saya, dan bahkan untuk yang belum saya temui .
Melihat laporan itu membawa saya pada gagasan bahwa perlu untuk mengembalikan semua parameter ke nilai default, dan untuk menyetel pengaturan dengan sangat hati-hati dan hanya setelah memperbaiki satu set tanda. Sekarang, satu pelatihan memakan waktu sekitar 15 jam, tetapi satu model berhasil mendapatkan kecepatan yang lebih baik daripada di ansambel dengan peringkat.
Pembuatan Fitur
Dalam kompetisi "Sistem kolaboratif" sejumlah besar fitur dievaluasi sebagai penting untuk model. Misalnya, auditweights_spark_svd adalah atribut yang paling penting, dan tidak ada informasi tentang artinya. Saya pikir layak menghitung berbagai unit berdasarkan tanda-tanda penting. Misalnya, rata-rata auditweights_spark_svd per pengguna, per grup, per objek. Hal yang sama dapat dihitung dari data di mana pelatihan tidak dilakukan dan target = 1, yaitu, rata-rata auditweights_spark_svd per pengguna untuk objek yang ia sukai. Ada beberapa tanda penting, selain auditweights_spark_svd . Inilah beberapa di antaranya:
- auditweightsCtrGender
- auditweightsCtrTinggi
- userOwnerCounterCreateLikes
Sebagai contoh, nilai rata-rata auditweightsCtrGender oleh userId ternyata menjadi fitur penting, serta nilai rata-rata userOwnerCounterCreateLikes oleh userId + ownerId. Ini seharusnya membuat kami berpikir tentang bagaimana memahami arti dari ladang.
Fitur penting lainnya adalah auditweightsLikesCount dan auditweightsShowsCount . Membagi satu menjadi yang lain, fitur yang lebih penting diperoleh.
Kebocoran data
Model persaingan dan produksi adalah tugas yang sangat berbeda. Saat menyiapkan data, sangat sulit untuk memperhitungkan semua detail dan tidak mentransfer beberapa informasi non-sepele tentang variabel target pada tes. Jika kami membuat solusi produksi, kami akan mencoba menghindari penggunaan kebocoran data saat melatih model. Tetapi jika kita ingin memenangkan kontes, maka kebocoran data adalah fitur terbaik.
Setelah memeriksa data, Anda dapat melihat bahwa menurut objectId, nilai auditweightsLikesCount dan auditweightsShowsCount berubah, yang berarti bahwa rasio nilai maksimum tanda-tanda ini akan mencerminkan konversi pos jauh lebih baik daripada rasio pada saat pengiriman.
Kebocoran pertama yang kami temukan adalah auditweightsLikesCountMax / auditweightsShowsCountMax .
Tetapi bagaimana jika Anda melihat data lebih dekat? Urutkan berdasarkan tanggal pengiriman dan dapatkan:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | target (disukai) |
|---|
| 1 | 1 | 12 | 3 | mungkin juga tidak |
| 1 | 2 | 15 | 3 | mungkin ya |
| 1 | 3 | 16 | 4 | |
Mengejutkan ketika saya menemukan contoh pertama dan ternyata prediksi saya tidak menjadi kenyataan. Namun, mengingat fakta bahwa nilai maksimum dari tanda-tanda ini dalam kerangka objek memberikan peningkatan, kami tidak terlalu malas dan memutuskan untuk menemukan auditweightsShowsCountNext dan auditweightsLikesCountNext , yaitu, nilai pada saat berikutnya dalam waktu. Menambahkan fitur
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) kami melakukan lompatan tajam sepanjang waktu.
Kebocoran serupa dapat digunakan jika nilai-nilai berikut ditemukan untuk userOwnerCounterCreateLikes dalam userId + ownerId dan, misalnya, auditweightsCtrGender dalam objectId + userGender. Kami menemukan 6 bidang serupa dengan kebocoran dan menarik informasi dari mereka sebanyak mungkin.
Pada saat itu, kami telah memeras maksimal informasi dari atribut kolaboratif, tetapi tidak kembali ke kontes gambar dan teks. Ada ide bagus untuk memeriksa: berapa banyak fitur secara langsung memberikan gambar atau teks dalam kompetisi yang sesuai?
Tidak ada kebocoran dalam kontes untuk gambar dan teks, tetapi pada saat itu saya telah mengembalikan parameter default dari catboost, menyisir kode dan menambahkan beberapa fitur. Hasil total:
| Solusi | kecepatan |
|---|
| Maksimum dengan gambar | 0,6411 |
| Maksimal tidak ada gambar | 0,6297 |
| Hasil tempat kedua | 0,6295 |
| Solusi | kecepatan |
|---|
| Maksimum dengan teks | 0,666 |
| Maksimum tanpa teks | 0,660 |
| Hasil tempat kedua | 0,656 |
| Solusi | kecepatan |
|---|
| Maksimal kolaboratif | 0,745 |
| Hasil tempat kedua | 0,723 |
Menjadi jelas bahwa banyak teks dan gambar tidak mungkin diperas, dan setelah mencoba beberapa ide yang paling menarik, kami berhenti bekerja dengan mereka.
Generasi fitur selanjutnya dalam sistem kolaboratif tidak memberikan pertumbuhan, dan kami mulai memberi peringkat. Pada tahap online, ansambel klasifikasi dan peringkat memberi saya sedikit peningkatan, ternyata karena saya memiliki klasifikasi yang kurang terlatih. Tidak ada fungsi kesalahan, termasuk YetiRanlPairwise, bahkan memberikan hasil dekat yang diberikan LogLoss (0,745 melawan 0,725). Ada harapan untuk QueryCrossEntropy yang tidak dapat diluncurkan.
Tahap offline
Pada tahap offline, struktur data tetap sama, tetapi ada perubahan kecil:
- pengidentifikasi userId, objectId, ownerId telah diacak ulang;
- beberapa tanda telah dihapus dan beberapa diganti namanya;
- data telah menjadi sekitar 1,5 kali lebih banyak.
Selain kesulitan yang terdaftar, ada satu nilai tambah besar: server besar dengan RTX 2080TI dialokasikan untuk tim. Saya menikmati htop untuk waktu yang lama.
Idenya adalah satu - hanya untuk mereproduksi apa yang sudah ada. Setelah menghabiskan beberapa jam menyiapkan lingkungan di server, kami secara bertahap mulai memverifikasi bahwa hasilnya sedang direproduksi. Masalah utama yang kita hadapi adalah peningkatan volume data. Kami memutuskan untuk sedikit mengurangi beban dan mengatur parameter catboost ctr_complexity = 1. Ini sedikit menurunkan kecepatan, tetapi model saya mulai bekerja, hasilnya bagus - 0,733. Sergei, tidak seperti saya, tidak membagi data menjadi 2 bagian dan melatih semua data, meskipun ini memberikan hasil terbaik pada tahap online, ada banyak kesulitan pada tahap offline. Jika kita mengambil semua fitur yang telah kita hasilkan dan mencoba memasukkannya ke dalam catboost "di dahi", maka tidak ada yang akan terjadi di panggung online. Sergey melakukan optimasi tipe, misalnya, mengubah tipe float64 menjadi float32. Dalam artikel ini Anda dapat menemukan informasi tentang cara mengoptimalkan memori dalam panda. Alhasil, Sergey melatih CPU pada semua data dan ternyata sekitar 0,735.
Hasil ini cukup untuk menang, tetapi kami menyembunyikan kecepatan kami yang sebenarnya dan tidak dapat memastikan bahwa tim lain tidak melakukan hal yang sama.
Pertempuran hingga yang terakhir
Tuning kapal cat
Solusi kami sepenuhnya direproduksi, kami menambahkan fitur data teks dan gambar, sehingga yang tersisa hanyalah menyesuaikan parameter catboost. Sergey belajar pada CPU dengan sejumlah kecil iterasi, dan saya belajar dengan ctr_complexity = 1. Hanya ada satu hari tersisa, dan jika Anda hanya menambahkan iterasi atau meningkatkan ctr_complexity, maka di pagi hari Anda bisa mendapatkan kecepatan yang lebih baik, dan berjalan sepanjang hari.
Pada tahap offline, skor bisa sangat mudah disembunyikan, hanya dengan memilih bukan solusi terbaik di situs. Kami mengharapkan perubahan tajam pada leaderboard di menit terakhir sebelum penutupan pengiriman dan memutuskan untuk tidak berhenti.
Dari video Anna, saya belajar bahwa untuk meningkatkan kualitas model, yang terbaik adalah memilih parameter berikut:
- learning_rate - Nilai default dihitung berdasarkan ukuran dataset. Dengan penurunan learning_rate, perlu untuk meningkatkan jumlah iterasi untuk mempertahankan kualitas.
- l2_leaf_reg - Koefisien regularisasi , nilai default 3, lebih disukai dari 2 hingga 30. Penurunan nilai mengarah ke peningkatan overfit.
- bagging_temperature - Menambahkan pengacakan ke bobot objek dalam seleksi. Nilai default adalah 1, di mana bobot dipilih dari distribusi eksponensial. Penurunan nilai menyebabkan peningkatan pakaian dalam.
- random_strength - Mempengaruhi pilihan split untuk iterasi tertentu. Semakin tinggi random_strength, semakin tinggi peluang pemisahan kepentingan rendah yang dipilih. Pada setiap iterasi berikutnya, keacakan menurun. Penurunan nilai menyebabkan peningkatan pakaian dalam.
Parameter lain secara signifikan kurang mempengaruhi hasil akhir, jadi saya tidak mencoba untuk memilihnya. Satu iterasi pelatihan pada dataset GPU saya dengan ctr_complexity = 1 membutuhkan waktu 20 menit, dan parameter yang dipilih pada dataset berkurang sedikit berbeda dari yang optimal pada dataset lengkap. Akibatnya, saya melakukan sekitar 30 iterasi pada 10% data, dan kemudian sekitar 10 iterasi lagi pada semua data. Ternyata kira-kira sebagai berikut:
- Saya meningkatkan learning_rate sebesar 40% dari standar;
- l2_leaf_reg meninggalkan yang sama;
- bagging_temperature dan random_strength dikurangi menjadi 0,8.
Kita dapat menyimpulkan bahwa dengan parameter default, modelnya kurang terlatih.
Saya sangat terkejut ketika saya melihat hasilnya di papan peringkat:
| Model | model 1 | model 2 | model 3 | ansambel |
|---|
| Tanpa penyetelan | 0,7403 | 0,7404 | 0,7404 | 0,7407 |
| Dengan penyetelan | 0,7406 | 0,7405 | 0,7406 | 0,7408 |
Saya menyimpulkan sendiri bahwa jika Anda tidak memerlukan aplikasi cepat dari model, maka lebih baik untuk mengganti pemilihan parameter dengan ansambel beberapa model pada parameter yang tidak dioptimalkan.
Sergey terlibat dalam mengoptimalkan ukuran dataset untuk menjalankannya pada GPU. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
.
. , , , 2 .
Kesimpulan
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- Tidak seperti tim lain, ansambel model kami memberi peningkatan besar. Kami bertukar ide dan menulis dalam berbagai bahasa. Kami memiliki pendekatan berbeda untuk memisahkan data, dan saya pikir semua orang memiliki bug sendiri.
- Tidak jelas mengapa optimasi peringkat menghasilkan hasil yang lebih buruk daripada optimasi klasifikasi.
- Saya mendapat sedikit pengalaman dengan teks dan pemahaman tentang bagaimana sistem rekomendasi dibuat.

Terima kasih kepada panitia atas emosi, pengetahuan, dan hadiah yang diterima.