
Pada 28 Februari, saya membuat presentasi di SphinxSearch-meetup , yang diadakan di kantor kami. Dia berbicara tentang bagaimana kita berasal dari pembangunan kembali indeks secara teratur untuk pencarian teks lengkap dan mengirimkan pembaruan dalam kode "di tempat" ke indeks waktu rel dan sinkronisasi otomatis keadaan indeks dan basis data MariaDB. Rekaman video dari laporan saya tersedia melalui tautan , dan bagi mereka yang lebih suka membaca daripada menonton video, saya menulis artikel ini.
Saya akan mulai dengan bagaimana pencarian kami diatur, dan mengapa kami memulai semua ini.
Pencarian kami diatur menurut skema yang sepenuhnya standar.
Dari ujung depan, permintaan pengguna datang ke server aplikasi yang ditulis dalam PHP, dan dia, pada gilirannya, berkomunikasi dengan database (kami memiliki MariaDB). Jika kita perlu melakukan pencarian, server aplikasi beralih ke balancer (kami memiliki haproxy), yang menghubungkannya ke salah satu server di mana searchd sedang berjalan, dan server itu sudah melakukan pencarian dan mengembalikan hasilnya.
Data dari database masuk ke dalam indeks dengan cara yang cukup tradisional: sesuai dengan jadwal, kami membangun kembali indeks setiap beberapa menit dengan dokumen-dokumen yang diperbarui relatif baru-baru ini, dan membangun kembali indeks dengan apa yang disebut dokumen "diarsipkan" (yaitu dokumen yang diarsipkan). Untuk waktu yang lama tidak ada yang terjadi). Ada beberapa mesin yang dialokasikan untuk pengindeksan, skrip dijalankan di sana pada jadwal, yang pertama membangun indeks, kemudian mengganti nama file indeks dengan cara khusus, dan kemudian meletakkannya di folder yang terpisah. Dan pada masing-masing server dengan searchd, rsync dimulai sekali dalam satu menit, yang dari folder ini menyalin file ke folder indeks searchd, dan kemudian, jika sesuatu telah disalin, ia menjalankan permintaan RELOAD INDEX.
Namun, untuk beberapa perubahan dalam resume dan lowongan, mereka diharuskan untuk “mencapai” indeks sesegera mungkin. Misalnya, jika lowongan yang diposting di domain publik dihapus dari publikasi, maka masuk akal untuk mengharapkan dari sudut pandang pengguna bahwa itu akan hilang dari masalah dalam beberapa detik, tidak lebih. Karenanya, perubahan semacam ini dikirim langsung melalui searchd menggunakan kueri UPDATE. Dan agar perubahan ini diterapkan ke semua salinan indeks di semua server kami, indeks terdistribusi disiapkan di setiap searchd, yang mengirimkan pembaruan atribut ke semua instance searchd. Server aplikasi masih terhubung ke penyeimbang dan mengirimkan satu permintaan untuk memperbarui indeks yang didistribusikan; dengan demikian, dia tidak perlu tahu sebelumnya baik daftar server dengan searchd, juga tidak akan sampai ke server dengan searchd secara tepat.
Semua ini bekerja dengan cukup baik, tetapi ada masalah.
- Penundaan rata-rata antara pembuatan dokumen (kami memiliki resume atau lowongan ini) dan entri ke dalam indeks berbanding lurus dengan jumlah mereka dalam database kami.
- Karena kami menggunakan indeks terdistribusi untuk mendistribusikan pembaruan atribut, kami tidak memiliki jaminan bahwa pembaruan ini diterapkan ke semua salinan indeks.
- Perubahan "mendesak" yang terjadi selama pembangunan kembali indeks hilang ketika perintah
RELOAD INDEX dijalankan (hanya karena mereka belum dalam indeks yang baru dibangun), dan hanya masuk ke indeks setelah pengindeksan ulang berikutnya. 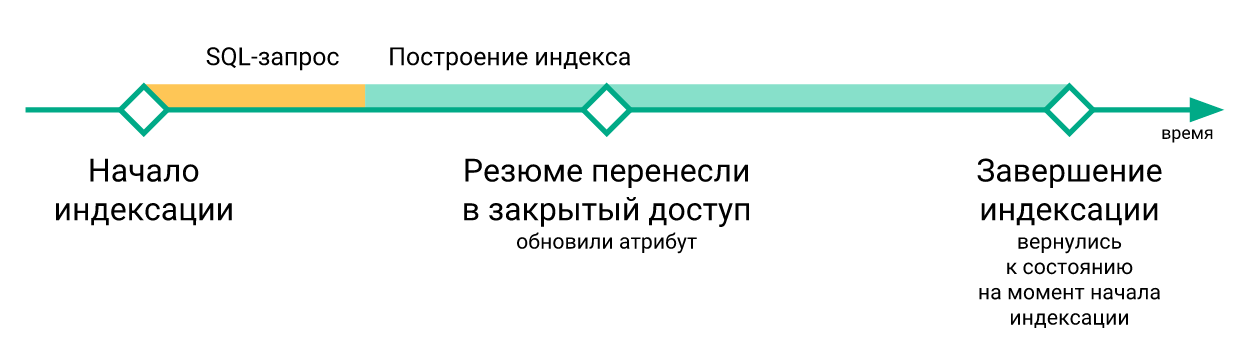
- Skrip untuk memperbarui indeks pada server dengan searchd dieksekusi secara independen satu sama lain, tidak ada sinkronisasi di antara mereka. Karena itu, penundaan antara memperbarui indeks pada server yang berbeda dapat mencapai beberapa menit.
- Jika perlu untuk menguji sesuatu yang berkaitan dengan pencarian, itu diperlukan untuk membangun kembali indeks setelah setiap perubahan.
Masing-masing masalah ini secara terpisah tidak layak dikerjakan ulang infrastruktur pencarian, tetapi secara bersama-sama mereka benar-benar merusak kehidupan.
Kami memutuskan untuk menangani masalah di atas menggunakan indeks realtime Sphinx. Selain itu, transisi ke indeks RT tidak cukup bagi kami. Untuk akhirnya menyingkirkan semua perlombaan data, perlu untuk memastikan bahwa semua pembaruan dari aplikasi ke indeks melewati saluran yang sama. Selain itu, perlu untuk menyimpan di suatu tempat perubahan yang dibuat ke database saat indeks sedang dibangun kembali (karena bagaimanapun, kadang-kadang perlu untuk membangunnya kembali, tetapi prosedurnya tidak instan).
Kami memutuskan untuk membuat koneksi menggunakan protokol replikasi MySQL seperti saluran transfer data, dan binlog MySQL adalah tempat untuk menyimpan perubahan saat membangun kembali indeks. Solusi ini memungkinkan kami untuk menghapus penulisan ke Sphinx dari kode aplikasi. Dan karena kami sudah menggunakan replikasi berbasis baris dengan id transaksi global saat itu, beralih antar replika basis data bisa dilakukan dengan cukup sederhana.
Gagasan menghubungkan langsung ke database untuk mendapatkan perubahan dari sana untuk mengirim ke indeks, tentu saja, bukan hal baru: pada 2016, rekan-rekan dari Avito membuat presentasi di mana mereka menggambarkan secara rinci bagaimana mereka memecahkan masalah sinkronisasi data di Sphinx dengan database utama. Kami memutuskan untuk menggunakan pengalaman mereka dan membuat sistem yang sama untuk diri kami sendiri, dengan perbedaan bahwa kami belum memiliki PostgreSQL, tetapi MariaDB, dan cabang Sphinx lama (yaitu, versi 2.3.2).
Kami membuat layanan yang berlangganan perubahan di MariaDB dan memperbarui indeks di Sphinx. Tanggung jawabnya adalah sebagai berikut:
- koneksi ke server MariaDB melalui protokol replikasi dan menerima acara dari binlog;
- melacak posisi binlog saat ini dan jumlah transaksi terakhir yang diselesaikan;
- memfilter acara binlog;
- mencari tahu dokumen mana yang perlu ditambahkan, dihapus atau diperbarui dalam indeks, dan untuk dokumen yang diperbarui - bidang mana yang perlu diperbarui;
- meminta data yang hilang dari MariaDB;
- pembuatan dan pelaksanaan permintaan pembaruan indeks;
- membangun kembali indeks jika perlu.
Kami membuat koneksi menggunakan protokol replikasi menggunakan perpustakaan go-mysql . Dia bertanggung jawab untuk membangun koneksi dengan MariaDB, membaca acara replikasi, dan meneruskannya ke seorang pawang. Pawang ini dimulai dengan goroutine, yang dikendalikan oleh perpustakaan, tetapi kami menulis sendiri kode pawang. Dalam kode penangan, acara diverifikasi dengan daftar tabel yang menarik bagi kami, dan perubahan pada tabel ini dikirim untuk diproses. Pawang kami juga menyimpan status transaksi. Ini karena peristiwa dalam protokol replikasi berurutan: GTID (mulai transaksi) -> ROW (perubahan data) -> XID (akhir transaksi), dan hanya yang pertama yang berisi informasi tentang nomor transaksi. Lebih mudah bagi kami untuk mentransfer nomor transaksi bersama dengan penyelesaiannya untuk menyimpan informasi tentang ke posisi mana dalam binlog perubahan telah diterapkan, dan untuk ini kita perlu mengingat jumlah transaksi saat ini antara awal dan selesai.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
Kami menyimpan jumlah transaksi terakhir yang diselesaikan dalam indeks khusus dari satu dokumen pada setiap server dengan searchd. Pada awal layanan, kami memverifikasi bahwa indeks diinisialisasi dan memiliki struktur yang diharapkan, serta posisi yang disimpan di semua server ada dan sama di semua server. Kemudian, jika pemeriksaan ini berhasil dan kami dapat mulai membaca binlog dari posisi yang disimpan, kami memulai prosedur sinkronisasi. Jika pemeriksaan gagal, atau tidak mungkin untuk mulai membaca binlog dari posisi yang disimpan, maka kami mengatur ulang posisi yang disimpan ke posisi saat ini dari server MariaDB dan membangun kembali indeks.
Memproses peristiwa replikasi dimulai dengan menentukan dokumen mana yang dipengaruhi oleh perubahan tertentu dalam database. Untuk melakukan ini, dalam konfigurasi layanan kami, kami melakukan sesuatu seperti perutean untuk acara perubahan baris dalam tabel yang menarik bagi kami, yaitu seperangkat aturan untuk menentukan bagaimana perubahan dalam database harus diindeks.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
Misalnya, dengan seperangkat aturan ini, perubahan pada vacancy_metro_station vacancy , vacancy vacancy_language dan vacancy_metro_station harus ada dalam indeks vacancy . Nomor dokumen dapat diambil di bidang id untuk tabel vacancy , dan di bidang vacancy_id untuk dua tabel lainnya. Kolom column_map adalah tabel ketergantungan bidang indeks pada bidang tabel database yang berbeda.
Lebih lanjut, ketika kami menerima daftar dokumen yang dipengaruhi oleh perubahan, kami perlu memperbaruinya dalam indeks, tetapi kami tidak segera melakukannya. Pertama, kami mengakumulasikan perubahan untuk setiap dokumen, dan mengirimkan perubahan ke indeks segera setelah waktu singkat (kami memiliki 100 milidetik) dari perubahan terakhir dokumen ini.
Kami memutuskan untuk melakukan ini untuk menghindari banyak pembaruan indeks yang tidak perlu, karena dalam banyak kasus satu perubahan logis ke dokumen terjadi dengan bantuan beberapa pertanyaan SQL yang mempengaruhi tabel yang berbeda, dan kadang-kadang dieksekusi dalam transaksi yang sama sekali berbeda.
Saya akan memberikan contoh sederhana. Misalkan seorang pengguna telah mengedit lowongan. Kode yang bertanggung jawab untuk menyimpan perubahan sering ditulis untuk kesederhanaan kira-kira dengan cara ini:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
Dengan kata lain, pertama semua catatan lama dihapus dari tabel tertaut, dan kemudian yang baru dimasukkan. Pada saat yang sama, masih akan ada entri dalam binlog tentang penghapusan dan penyisipan ini, bahkan jika tidak ada yang berubah dalam dokumen.
Untuk memperbarui hanya apa yang diperlukan, kami melakukan hal berikut: mengurutkan baris yang diubah sehingga untuk setiap pasangan indeks-dokumen semua perubahan dapat diambil dalam urutan kronologis. Kemudian kita akan dapat menerapkannya pada gilirannya untuk menentukan bidang mana di mana tabel akhirnya berubah dan mana yang tidak, dan kemudian menggunakan tabel column_map mendapatkan daftar bidang dan atribut indeks yang perlu diperbarui untuk setiap dokumen yang terpengaruh. Selain itu, peristiwa yang terkait dengan satu dokumen mungkin tidak tiba satu per satu, tetapi seolah-olah "berbeda" jika mereka dieksekusi dalam transaksi yang berbeda. Tetapi, pada kemampuan kita untuk menentukan dokumen apa yang telah berubah, ini tidak akan mempengaruhi.
Pada saat yang sama, pendekatan ini memungkinkan kami untuk memperbarui hanya atribut indeks, jika tidak ada perubahan di bidang teks, serta menggabungkan pengiriman perubahan ke Sphinx.
Jadi, sekarang kita bisa mengetahui dokumen mana yang perlu diperbarui dalam indeks.
Dalam banyak kasus, data dari binlog tidak cukup untuk membangun permintaan untuk memperbarui indeks, jadi kami mendapatkan data yang hilang dari server yang sama dari tempat kami membaca binlog. Untuk ini, ada templat permintaan untuk menerima data dalam konfigurasi layanan kami.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
Dalam templat ini, semua bidang ditandai dengan alias khusus: [___]:___ .
Ini digunakan baik dalam pembentukan permintaan untuk menerima data yang hilang dan dalam pembangunan indeks (lebih lanjut tentang ini nanti).
Kami membentuk permintaan jenis ini:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
Kemudian untuk setiap dokumen kami memeriksa apakah itu sebagai hasil dari permintaan ini. Jika tidak, itu berarti telah dihapus dari tabel utama, dan itu juga dapat dihapus dari indeks (kami menjalankan kueri DELETE untuk dokumen ini). Jika ya, maka lihat apakah kami perlu memperbarui bidang teks untuk dokumen ini. Jika bidang teks tidak perlu diperbarui, maka kami membuat kueri UPDATE untuk dokumen ini, jika tidak REPLACE .
Perlu dicatat bahwa logika mempertahankan posisi dari mana Anda dapat mulai membaca binlog jika terjadi kegagalan harus rumit, karena sekarang situasi mungkin di mana kami tidak menerapkan semua perubahan yang dibaca dari binlog.
Agar pembacaan kembali binlog berfungsi dengan benar, kami melakukan hal berikut: untuk setiap acara perubahan baris dalam database, ingat id dari transaksi yang diselesaikan terakhir pada saat peristiwa ini terjadi. Setelah mengirim perubahan ke Sphinx, kami memperbarui nomor transaksi dari mana Anda dapat mulai membaca dengan aman, sebagai berikut. Jika kami tidak memproses semua akumulasi perubahan (karena beberapa dokumen tidak "dilacak" dalam antrian), maka kami mengambil jumlah transaksi paling awal dari yang terkait dengan perubahan yang belum berhasil kami terapkan. Dan jika itu terjadi, kami menerapkan semua perubahan yang terakumulasi, maka kami hanya mengambil jumlah transaksi yang terakhir diselesaikan.
Apa yang terjadi sebagai hasilnya baik-baik saja dengan kami, tetapi ada satu poin yang lebih penting: agar kinerja indeks waktu nyata tetap pada tingkat yang dapat diterima dari waktu ke waktu, perlu bahwa ukuran dan jumlah "potongan" dari indeks ini tetap kecil. Untuk melakukan ini, Sphinx memiliki permintaan FLUSH RAMCHUNK , yang membuat potongan disk baru, dan permintaan OPTIMIZE INDEX , yang menggabungkan semua potongan disk menjadi satu. Awalnya, kami berpikir bahwa kami hanya akan melakukannya secara berkala dan itu saja. Tetapi, sayangnya, ternyata dalam versi 2.3.2 OPTIMIZE INDEX tidak berfungsi (yaitu, dengan probabilitas yang cukup tinggi mengarah pada penurunan dalam pencariand). Karena itu, kami memutuskan hanya sekali sehari untuk membangun kembali indeks sepenuhnya, terutama karena dari waktu ke waktu kami masih harus melakukannya (misalnya, jika skema indeks atau pengaturan tokenizer berubah).
Prosedur untuk membangun kembali indeks berlangsung dalam beberapa tahap.
Kami membuat konfigurasi untuk pengindeks
Seperti disebutkan di atas, ada templat kueri SQL dalam konfigurasi layanan. Ini juga digunakan untuk membentuk konfigurasi pengindeks.
Juga di konfigurasi ada pengaturan lain yang diperlukan untuk membangun indeks (pengaturan tokenizer, kamus, berbagai pembatasan konsumsi sumber daya).
Simpan posisi MariaDB saat ini
Dari posisi ini, kita akan mulai membaca binlog, setelah indeks baru tersedia di semua server dengan searchd.
Kami memulai pengindeks
indexer --config tmp.vacancy.indexer.0.conf --all perintah form indexer --config tmp.vacancy.indexer.0.conf --all dan tunggu penyelesaiannya. Apalagi jika indeks dibagi menjadi beberapa bagian, maka kita mulai membangun semua bagian secara paralel.
Kami memuat file indeks di server
Mengunduh ke setiap server juga terjadi secara paralel, tetapi kami secara alami menunggu hingga semua file diunggah ke semua server. Untuk mengunduh file dalam konfigurasi layanan, ada bagian dengan templat perintah untuk mengunduh file.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Untuk setiap server, kami cukup mengganti namanya dalam variabel Host dan menjalankan perintah yang dihasilkan. Kami menggunakan rsync untuk diunduh, tetapi pada prinsipnya program atau skrip apa pun yang menerima daftar file di stdin dan mengunduh file-file ini ke folder tempat searchd mengharapkan untuk melihat file indeks akan dilakukan.
Kami menghentikan sinkronisasi
Kami berhenti membaca binlog, menghentikan goroutine yang bertanggung jawab atas akumulasi perubahan.
Ganti indeks lama dengan yang baru
Untuk setiap server dengan searchd, kami membuat kueri berurutan RELOAD INDEX vacancy_plain , RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy . Jika indeks dibagi menjadi beberapa bagian, maka kami menjalankan kueri ini untuk setiap bagian secara berurutan. Pada saat yang sama, jika kita berada dalam lingkungan produksi, maka sebelum mengeksekusi kueri ini pada server apa pun, kami menghapus beban dari itu melalui penyeimbang (sehingga tidak ada yang membuat SELECT kueri ke indeks antara TRUNCATE dan ATTACH ), dan segera setelah permintaan ATTACH terakhir selesai, kami mengembalikan beban ke server ini.
Melanjutkan sinkronisasi dari posisi yang disimpan
Segera setelah kami mengganti semua indeks waktu nyata dengan yang baru dibangun, kami melanjutkan membaca dari binlog dan menyinkronkan peristiwa dari binlog, mulai dari posisi yang kami simpan sebelum pengindeksan dimulai.
Berikut ini adalah contoh grafik lag indeks dari server MariaDB.

Di sini Anda dapat melihat bahwa meskipun keadaan indeks setelah pembangunan kembali kembali pada waktunya, ini terjadi sangat singkat.
Sekarang semuanya sudah lebih atau kurang siap, saatnya untuk rilis. Kami melakukannya secara bertahap. Pertama, kami menuangkan indeks waktu nyata pada beberapa server, dan sisanya pada saat itu bekerja dengan cara yang sama. Pada saat yang sama, struktur indeks pada server "baru" tidak berbeda dari yang lama, sehingga aplikasi PHP kami masih dapat terhubung ke penyeimbang tanpa khawatir tentang apakah permintaan akan diproses pada indeks realtime atau pada indeks biasa.
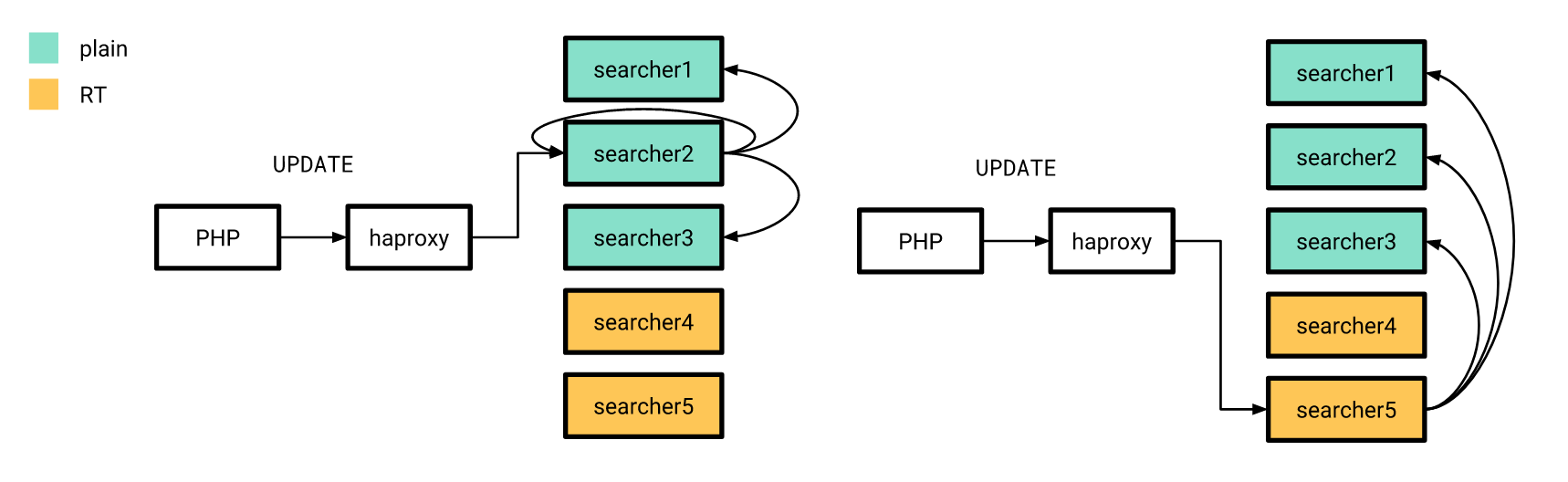
Pembaruan atribut, yang saya bicarakan sebelumnya, juga dikirim sesuai dengan skema lama, dengan perbedaan bahwa indeks terdistribusi pada semua server dikonfigurasi untuk mengirim permintaan UPDATE hanya ke server dengan indeks biasa. Selain itu, jika permintaan-UPDATE dari aplikasi mencapai server dengan indeks realtime, maka itu tidak menjalankan permintaan ini di rumah, tetapi mengirimkannya ke server yang dikonfigurasi dengan cara lama.
Setelah rilis, seperti yang kami harapkan, ternyata secara signifikan mengurangi penundaan antara bagaimana resume atau lowongan berubah dalam database dan bagaimana perubahan yang sesuai masuk ke dalam indeks.
Setelah beralih ke indeks waktu nyata, tidak perlu membangun kembali indeks setelah setiap perubahan pada server pengujian. Sehingga menjadi mungkin untuk menulis autotest ujung ke ujung dengan partisipasi pencarian yang relatif tidak mahal. Namun, karena kami memproses perubahan dari binlog secara tidak sinkron (dari sudut pandang klien yang menulis ke basis data), kami harus memungkinkan untuk menunggu hingga perubahan terkait dokumen yang berpartisipasi dalam autotest diproses oleh layanan kami dan dikirim ke searchd .
Untuk melakukan ini, kami membuat titik akhir dalam layanan kami, yang melakukan hal itu, yaitu menunggu hingga semua perubahan diterapkan ke nomor transaksi yang ditentukan. Untuk melakukan ini, segera setelah kami melakukan perubahan yang diperlukan pada database, kami meminta dari MariaDB @@gtid_current_pos dan mentransfernya ke titik akhir layanan kami. Jika kami sudah menerapkan semua transaksi pada posisi ini saat ini, layanan segera menjawab bahwa kami dapat melanjutkan. Jika tidak, maka di goroutine yang bertanggung jawab untuk menerapkan perubahan, kami membuat langganan ke GTID ini, dan segera setelah itu (atau yang mengikutinya) diterapkan, kami juga memungkinkan klien untuk melanjutkan autotest.
Dalam kode PHP, tampilannya seperti ini:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
Hasil
Sebagai hasilnya, kami dapat secara signifikan mengurangi penundaan antara memperbarui MariaDB dan Sphinx.


Kami juga menjadi jauh lebih percaya diri bahwa semua pembaruan menjangkau semua server Sphinx kami tepat waktu.
Selain itu, pengujian pencarian (baik manual dan otomatis) menjadi jauh lebih menyenangkan.
Sayangnya, ini tidak diberikan kepada kami secara gratis: kinerja indeks waktu nyata dibandingkan dengan indeks biasa ternyata sedikit lebih buruk.
Distribusi waktu pemrosesan permintaan pencarian tergantung pada waktu untuk indeks biasa ditunjukkan di bawah ini.

Dan di sini adalah grafik yang sama untuk indeks realtime.

Anda dapat melihat bahwa pangsa permintaan "cepat" sedikit menurun, sedangkan pangsa permintaan "lambat" telah meningkat.
Alih-alih sebuah kesimpulan
Tetap mengatakan bahwa kode layanan yang dijelaskan dalam artikel ini, kami diposting di domain publik . Sayangnya, belum ada dokumentasi terperinci, tetapi jika Anda mau, Anda dapat menjalankan contoh menggunakan layanan ini melalui docker-compose .
Referensi
- Video dan slide laporan
- Laporan video oleh Andrey Smirnov dan Vyacheslav Kryukov di Highload ++
- Go-mysql library
- Kode layanan dengan contoh penggunaan