Dalam posting ini kami ingin berbagi cara menarik untuk berurusan dengan konfigurasi sistem terdistribusi.
Konfigurasi diwakili secara langsung dalam bahasa Scala dalam jenis yang aman. Contoh implementasi dijelaskan secara rinci. Berbagai aspek proposal dibahas, termasuk pengaruhnya terhadap keseluruhan proses pembangunan.
( dalam bahasa Rusia )
Pendahuluan
Membangun sistem terdistribusi yang kuat membutuhkan penggunaan konfigurasi yang benar dan koheren pada semua node. Solusi khas adalah dengan menggunakan deskripsi penyebaran teks (terraform, mungkin atau sesuatu yang serupa) dan file konfigurasi yang dihasilkan secara otomatis (sering - didedikasikan untuk setiap node / peran). Kami juga ingin menggunakan protokol yang sama dari versi yang sama pada setiap node yang berkomunikasi (jika tidak kita akan mengalami masalah ketidakcocokan). Dalam dunia JVM ini berarti bahwa setidaknya perpustakaan perpesanan harus dari versi yang sama pada semua node yang berkomunikasi.
Bagaimana dengan pengujian sistem? Tentu saja, kita harus melakukan tes unit untuk semua komponen sebelum datang ke tes integrasi. Untuk dapat mengekstrapolasi hasil pengujian pada saat runtime, kita harus memastikan bahwa versi semua pustaka dijaga tetap identik di kedua runtime dan lingkungan pengujian.
Saat menjalankan tes integrasi, seringkali lebih mudah untuk memiliki classpath yang sama di semua node. Kita hanya perlu memastikan bahwa classpath yang sama digunakan pada penyebaran. (Dimungkinkan untuk menggunakan classpath yang berbeda pada node yang berbeda, tetapi lebih sulit untuk merepresentasikan konfigurasi ini dan menyebarkannya dengan benar.) Jadi, untuk mempermudah, kita hanya akan mempertimbangkan classpath identik pada semua node.
Konfigurasi cenderung berkembang bersama dengan perangkat lunak. Kami biasanya menggunakan versi untuk mengidentifikasi berbagai
tahapan evolusi perangkat lunak. Tampaknya masuk akal untuk membahas konfigurasi di bawah manajemen versi dan mengidentifikasi berbagai konfigurasi dengan beberapa label. Jika hanya ada satu konfigurasi dalam produksi, kami dapat menggunakan versi tunggal sebagai pengenal. Kadang-kadang kita mungkin memiliki beberapa lingkungan produksi. Dan untuk setiap lingkungan kita mungkin memerlukan cabang konfigurasi yang terpisah. Jadi konfigurasi mungkin diberi label dengan cabang dan versi untuk secara unik mengidentifikasi konfigurasi yang berbeda. Setiap label dan versi cabang berhubungan dengan kombinasi tunggal dari node terdistribusi, port, sumber daya eksternal, versi pustaka classpath pada setiap node. Di sini kita hanya akan membahas cabang tunggal dan mengidentifikasi konfigurasi dengan versi tiga desimal (1.2.3), dengan cara yang sama seperti artefak lainnya.
Dalam lingkungan modern file konfigurasi tidak dimodifikasi secara manual lagi. Biasanya kami menghasilkan
konfigurasikan file pada waktu penyebaran dan jangan pernah menyentuhnya sesudahnya. Jadi orang bisa bertanya mengapa kita masih menggunakan format teks untuk file konfigurasi? Opsi yang layak adalah menempatkan konfigurasi di dalam unit kompilasi dan mendapat manfaat dari validasi konfigurasi waktu kompilasi.
Dalam posting ini kita akan memeriksa ide menjaga konfigurasi dalam artefak yang dikompilasi.
Konfigurasi yang dapat dikompilasi
Pada bagian ini kita akan membahas contoh konfigurasi statis. Dua layanan sederhana - layanan gema dan klien dari layanan gema sedang dikonfigurasi dan diimplementasikan. Kemudian dua sistem terdistribusi yang berbeda dengan kedua layanan instantiated. Satu untuk konfigurasi node tunggal dan satu lagi untuk konfigurasi dua node.
Sistem terdistribusi tipikal terdiri dari beberapa node. Node dapat diidentifikasi menggunakan beberapa jenis:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
atau adil
case class NodeId(hostName: String)
atau bahkan
object Singleton type NodeId = Singleton.type
Node-node ini menjalankan berbagai peran, menjalankan beberapa layanan dan harus dapat berkomunikasi dengan node lain melalui koneksi TCP / HTTP.
Untuk koneksi TCP setidaknya diperlukan nomor port. Kami juga ingin memastikan bahwa klien dan server berbicara protokol yang sama. Untuk memodelkan koneksi antara node, mari kita mendeklarasikan kelas berikut:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
di mana Port hanya sebuah Int dalam rentang yang diizinkan:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Jenis halusLihat perpustakaan yang disempurnakan . Singkatnya, ini memungkinkan untuk menambahkan batasan waktu kompilasi ke tipe lain. Dalam hal ini, Int hanya diperbolehkan memiliki nilai 16-bit yang dapat mewakili nomor port. Tidak ada persyaratan untuk menggunakan perpustakaan ini untuk pendekatan konfigurasi ini. Sepertinya pas sekali.
Untuk HTTP (REST) kami mungkin juga memerlukan jalur layanan:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Tipe hantuUntuk mengidentifikasi protokol selama kompilasi, kami menggunakan fitur Scala untuk mendeklarasikan tipe argumen Protocol yang tidak digunakan di kelas. Ini disebut tipe hantu . Saat runtime kita jarang membutuhkan instance pengenal protokol, itu sebabnya kami tidak menyimpannya. Selama kompilasi, tipe hantu ini memberikan keamanan tipe tambahan. Kami tidak dapat melewati port dengan protokol yang salah.
Salah satu protokol yang paling banyak digunakan adalah REST API dengan serialisasi Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
di mana RequestMessage adalah jenis pesan dasar yang dapat dikirim klien ke server dan ResponseMessage adalah pesan respons dari server. Tentu saja, kami dapat membuat deskripsi protokol lain yang menentukan protokol komunikasi dengan presisi yang diinginkan.
Untuk keperluan posting ini kami akan menggunakan versi protokol yang lebih sederhana:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Dalam protokol ini pesan permintaan ditambahkan ke url dan pesan respons dikembalikan sebagai string biasa.
Konfigurasi layanan dapat dijelaskan oleh nama layanan, kumpulan port dan beberapa dependensi. Ada beberapa cara yang mungkin bagaimana cara mewakili semua elemen ini di Scala (misalnya, HList , tipe data aljabar). Untuk keperluan posting ini kami akan menggunakan Pola Kue dan mewakili potongan-potongan (modul) yang dapat dikombinasikan sebagai ciri. (Pola Kue bukan persyaratan untuk pendekatan konfigurasi yang dapat dikompilasi ini. Ini hanya salah satu kemungkinan penerapan ide.)
Ketergantungan dapat direpresentasikan menggunakan Pola Kue sebagai titik akhir dari simpul lain:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Layanan gema hanya membutuhkan port yang dikonfigurasi. Dan kami menyatakan bahwa port ini mendukung protokol gema. Perhatikan bahwa kita tidak perlu menentukan port tertentu saat ini, karena sifat memungkinkan deklarasi metode abstrak. Jika kita menggunakan metode abstrak, kompiler akan membutuhkan implementasi dalam contoh konfigurasi. Di sini kami telah menyediakan implementasi ( 8081 ) dan itu akan digunakan sebagai nilai default jika kita melewatkannya dalam konfigurasi konkret.
Kami dapat mendeklarasikan ketergantungan dalam konfigurasi klien layanan gema:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
Ketergantungan memiliki tipe yang sama dengan echoService . Secara khusus, ini menuntut protokol yang sama. Oleh karena itu, kita dapat yakin bahwa jika kita menghubungkan kedua dependensi ini, keduanya akan berfungsi dengan benar.
Implementasi layananSuatu layanan membutuhkan fungsi untuk memulai dan mematikan dengan anggun. (Kemampuan untuk mematikan layanan sangat penting untuk pengujian.) Sekali lagi ada beberapa opsi untuk menentukan fungsi seperti itu untuk konfigurasi yang diberikan (misalnya, kita bisa menggunakan kelas tipe). Untuk posting ini kita akan kembali menggunakan Pola Kue. Kami dapat mewakili layanan menggunakan cats.Resource yang sudah menyediakan bracketing dan rilis sumber daya. Untuk memperoleh sumber daya, kita harus menyediakan konfigurasi dan beberapa konteks runtime. Jadi fungsi awal layanan mungkin terlihat seperti:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
dimana
Config - jenis konfigurasi yang diperlukan oleh starter layanan iniAddressResolver - objek runtime yang memiliki kemampuan untuk mendapatkan alamat nyata dari node lain (terus membaca untuk detail).
jenis lainnya berasal dari cats :
F[_] - jenis efek (Dalam kasus paling sederhana F[A] bisa saja () => A Dalam posting ini kita akan menggunakan cats.IO )Reader[A,B] - kurang lebih adalah sinonim untuk fungsi A => Bcats.Resource - memiliki cara untuk memperoleh dan melepaskanTimer - memungkinkan untuk tidur / mengukur waktuContextShift - analog dari ExecutionContextApplicative - pembungkus fungsi yang berlaku (hampir monad) (akhirnya kami mungkin akan menggantinya dengan yang lain)
Dengan menggunakan antarmuka ini, kami dapat mengimplementasikan beberapa layanan. Misalnya, layanan yang tidak melakukan apa pun:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Lihat Kode sumber untuk implementasi layanan lain - layanan gema ,
klien echo dan pengontrol seumur hidup .)
Node adalah objek tunggal yang menjalankan beberapa layanan (memulai rangkaian sumber daya diaktifkan oleh Pola Kue):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Perhatikan bahwa dalam node kami menentukan jenis konfigurasi yang tepat yang diperlukan oleh node ini. Compiler tidak akan membiarkan kita membangun objek (Kue) dengan tipe yang tidak cukup, karena setiap sifat layanan menyatakan kendala pada tipe Config . Kami juga tidak akan dapat memulai simpul tanpa menyediakan konfigurasi lengkap.
Resolusi alamat simpulUntuk membuat koneksi, kita memerlukan alamat host nyata untuk setiap node. Ini mungkin diketahui kemudian daripada bagian lain dari konfigurasi. Oleh karena itu, kita memerlukan cara untuk menyediakan pemetaan antara id node dan alamat aktualnya. Pemetaan ini adalah fungsi:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Ada beberapa cara yang mungkin untuk mengimplementasikan fungsi tersebut.
- Jika kita mengetahui alamat aktual sebelum penyebaran, selama instance node host, maka kita dapat menghasilkan kode Scala dengan alamat aktual dan menjalankan build sesudahnya (yang melakukan pemeriksaan waktu kompilasi dan kemudian menjalankan suite uji integrasi). Dalam hal ini fungsi pemetaan kami dikenal secara statis dan dapat disederhanakan menjadi sesuatu seperti
Map[NodeId, NodeAddress] . - Kadang-kadang kami mendapatkan alamat aktual hanya pada titik kemudian ketika node benar-benar dimulai, atau kami tidak memiliki alamat node yang belum dimulai. Dalam hal ini kami mungkin memiliki layanan pencarian yang dimulai sebelum semua node lain dan setiap node dapat mengiklankan alamat itu di layanan itu dan berlangganan dependensi.
- Jika kita dapat memodifikasi
/etc/hosts , kita dapat menggunakan nama host yang telah ditentukan (seperti my-project-main-node dan echo-backend ) dan hanya mengasosiasikan nama ini dengan alamat ip pada waktu penyebaran.
Dalam posting ini kami tidak membahas kasus-kasus ini secara lebih rinci. Bahkan dalam contoh mainan kami semua node akan memiliki alamat IP yang sama - 127.0.0.1 .
Dalam posting ini kita akan mempertimbangkan dua tata letak sistem terdistribusi:
- Tata letak simpul tunggal, tempat semua layanan ditempatkan pada simpul tunggal.
- Tata letak dua simpul, di mana layanan dan klien berada di simpul yang berbeda.
Konfigurasi untuk tata letak simpul tunggal adalah sebagai berikut:
Konfigurasi simpul tunggal object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Di sini kita membuat satu konfigurasi yang memperluas konfigurasi server dan klien. Kami juga mengkonfigurasi pengontrol siklus hidup yang biasanya akan mengakhiri klien dan server setelah melewati interval lifetime .
Rangkaian implementasi dan konfigurasi layanan yang sama dapat digunakan untuk membuat tata letak sistem dengan dua node terpisah. Kami hanya perlu membuat dua konfigurasi simpul terpisah dengan layanan yang sesuai:
Konfigurasi dua node object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Lihat bagaimana kami menentukan ketergantungan. Kami menyebutkan layanan yang disediakan node lain sebagai ketergantungan dari node saat ini. Jenis ketergantungan diperiksa karena mengandung jenis hantu yang menggambarkan protokol. Dan pada saat runtime kita akan memiliki id simpul yang benar. Ini adalah salah satu aspek penting dari pendekatan konfigurasi yang diusulkan. Ini memberi kami kemampuan untuk mengatur port hanya sekali dan memastikan bahwa kami mereferensikan port yang benar.
Implementasi dua nodeUntuk konfigurasi ini kami menggunakan implementasi layanan yang persis sama. Tidak ada perubahan sama sekali. Namun, kami membuat dua implementasi simpul berbeda yang berisi rangkaian layanan berbeda:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Node pertama mengimplementasikan server dan hanya perlu konfigurasi sisi server. Node kedua mengimplementasikan klien dan membutuhkan bagian lain dari konfigurasi. Kedua node memerlukan spesifikasi seumur hidup. Untuk keperluan simpul layanan pos ini akan memiliki masa hidup tak terbatas yang dapat diakhiri menggunakan SIGTERM , sementara klien gema akan berakhir setelah durasi terbatas yang dikonfigurasi. Lihat aplikasi starter untuk detailnya.
Keseluruhan proses pengembangan
Mari kita lihat bagaimana pendekatan ini mengubah cara kita bekerja dengan konfigurasi.
Konfigurasi sebagai kode akan dikompilasi dan menghasilkan artefak. Tampaknya masuk akal untuk memisahkan artefak konfigurasi dari artefak kode lainnya. Seringkali kita dapat memiliki banyak konfigurasi pada basis kode yang sama. Dan tentu saja, kita dapat memiliki beberapa versi dari berbagai cabang konfigurasi. Dalam konfigurasi, kami dapat memilih versi perpustakaan tertentu dan ini akan tetap konstan setiap kali kami menggunakan konfigurasi ini.
Perubahan konfigurasi menjadi perubahan kode. Jadi harus dicakup oleh proses penjaminan kualitas yang sama:
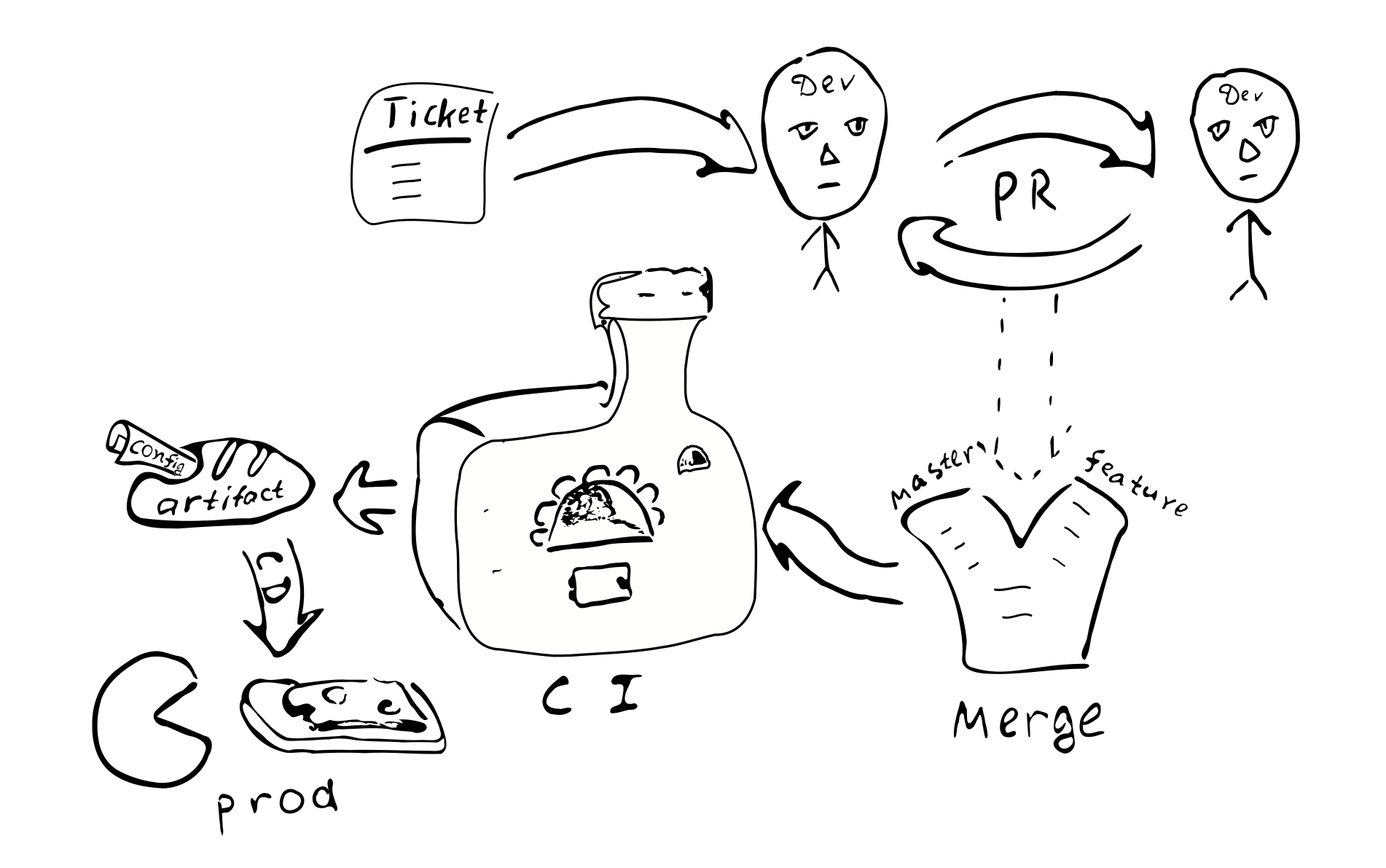
Tiket -> PR -> ulasan -> penggabungan -> integrasi berkelanjutan -> penyebaran berkelanjutan
Ada konsekuensi berikut dari pendekatan ini:
Konfigurasi ini koheren untuk instance sistem tertentu. Tampaknya tidak ada cara untuk memiliki koneksi yang salah antara node.
Tidak mudah mengubah konfigurasi hanya dalam satu node. Tampaknya tidak masuk akal untuk masuk dan mengubah beberapa file teks. Jadi konfigurasi drift menjadi kurang memungkinkan.
Perubahan konfigurasi kecil tidak mudah dilakukan.
Sebagian besar perubahan konfigurasi akan mengikuti proses pengembangan yang sama, dan akan melewati beberapa tinjauan.
Apakah kita memerlukan repositori terpisah untuk konfigurasi produksi? Konfigurasi produksi mungkin berisi informasi sensitif yang kami ingin jauhkan dari jangkauan banyak orang. Jadi mungkin perlu menyimpan repositori terpisah dengan akses terbatas yang akan berisi konfigurasi produksi. Kami dapat membagi konfigurasi menjadi dua bagian - satu yang berisi sebagian besar parameter produksi terbuka dan satu yang berisi bagian rahasia dari konfigurasi. Ini akan memungkinkan akses ke sebagian besar pengembang ke sebagian besar parameter sambil membatasi akses ke hal-hal yang sangat sensitif. Sangat mudah untuk mencapai ini menggunakan sifat perantara dengan nilai parameter default.
Variasi
Mari kita lihat pro dan kontra dari pendekatan yang diusulkan dibandingkan dengan teknik manajemen konfigurasi lainnya.
Pertama-tama, kami akan mencantumkan beberapa alternatif untuk berbagai aspek dari cara yang diusulkan untuk menangani konfigurasi:
- File teks pada mesin target.
- Penyimpanan nilai kunci terpusat (seperti
etcd / zookeeper ). - Komponen subproses yang dapat dikonfigurasi ulang / dihidupkan ulang tanpa memulai kembali proses.
- Konfigurasi di luar artefak dan kontrol versi.
File teks memberikan beberapa fleksibilitas dalam hal perbaikan ad-hoc. Administrator sistem dapat masuk ke node target, melakukan perubahan, dan cukup memulai kembali layanan. Ini mungkin tidak sebagus sistem yang lebih besar. Tidak ada jejak yang tertinggal di balik perubahan. Perubahan tidak ditinjau oleh sepasang mata lain. Mungkin sulit untuk mengetahui apa yang menyebabkan perubahan itu. Itu belum diuji. Dari perspektif sistem terdistribusi, seorang administrator bisa saja lupa untuk memperbarui konfigurasi di salah satu node lainnya.
(Btw, jika pada akhirnya akan ada kebutuhan untuk mulai menggunakan file konfigurasi teks, kita hanya perlu menambahkan parser + validator yang bisa menghasilkan tipe Config sama dan itu sudah cukup untuk mulai menggunakan konfigurasi teks. Ini juga menunjukkan bahwa kompleksitas konfigurasi waktu kompilasi sedikit lebih kecil daripada kompleksitas konfigurasi berbasis teks, karena dalam versi berbasis teks kita memerlukan beberapa kode tambahan.)
Penyimpanan nilai kunci terpusat adalah mekanisme yang baik untuk mendistribusikan parameter meta aplikasi. Di sini kita perlu berpikir tentang apa yang kita anggap sebagai nilai konfigurasi dan apa yang hanya data. Diberikan fungsi C => A => B kita biasanya memanggil nilai C "konfigurasi" yang jarang berubah, sementara data A sering berubah - hanya input data. Konfigurasi harus disediakan untuk fungsi lebih awal dari data A Dengan gagasan ini, kita dapat mengatakan bahwa frekuensi perubahan yang diharapkan dapat digunakan untuk membedakan data konfigurasi dari hanya data. Juga data biasanya berasal dari satu sumber (pengguna) dan konfigurasi berasal dari sumber yang berbeda (admin). Berurusan dengan parameter yang dapat diubah setelah inisialisasi proses mengarah pada peningkatan kompleksitas aplikasi. Untuk parameter seperti itu kita harus menangani mekanisme pengiriman, penguraian dan validasi, menangani nilai yang salah. Oleh karena itu, untuk mengurangi kompleksitas program, lebih baik kita mengurangi jumlah parameter yang dapat berubah saat runtime (atau bahkan menghilangkan semuanya).
Dari perspektif posting ini kita harus membuat perbedaan antara parameter statis dan dinamis. Jika logika layanan memerlukan perubahan langka pada beberapa parameter saat runtime, maka kami dapat menyebutnya parameter dinamis. Kalau tidak, mereka statis dan dapat dikonfigurasi menggunakan pendekatan yang diusulkan. Untuk konfigurasi ulang dinamis, pendekatan lain mungkin diperlukan. Sebagai contoh, bagian dari sistem mungkin di-restart dengan parameter konfigurasi baru dengan cara yang sama untuk memulai kembali proses terpisah dari sistem terdistribusi.
(Pendapat saya yang sederhana adalah untuk menghindari konfigurasi ulang runtime karena menambah kompleksitas sistem.
Mungkin lebih mudah untuk hanya mengandalkan dukungan OS untuk memulai kembali proses. Padahal, itu mungkin tidak selalu mungkin.)
Salah satu aspek penting dari menggunakan konfigurasi statis yang terkadang membuat orang menganggap konfigurasi dinamis (tanpa alasan lain) adalah gangguan layanan selama pembaruan konfigurasi. Memang, jika kita harus membuat perubahan pada konfigurasi statis, kita harus me-restart sistem sehingga nilai-nilai baru menjadi efektif. Persyaratan untuk waktu henti bervariasi untuk sistem yang berbeda, sehingga mungkin tidak terlalu penting. Jika sangat penting, maka kita harus merencanakan ke depan untuk memulai ulang sistem apa pun. Misalnya, kita bisa menerapkan pengeringan koneksi AWS ELB . Dalam skenario ini setiap kali kita perlu me-restart sistem, kita memulai instance baru dari sistem secara paralel, kemudian beralih ELB ke situ, sambil membiarkan sistem lama menyelesaikan layanan koneksi yang ada.
Bagaimana dengan menjaga konfigurasi di dalam artefak berversi atau di luar? Menyimpan konfigurasi di dalam artefak berarti dalam sebagian besar kasus konfigurasi ini telah melewati proses penjaminan kualitas yang sama dengan artefak lainnya. Jadi orang mungkin yakin bahwa konfigurasinya berkualitas baik dan dapat dipercaya. Sebaliknya konfigurasi dalam file yang terpisah berarti bahwa tidak ada jejak siapa dan mengapa membuat perubahan pada file itu. Apakah ini penting? Kami percaya bahwa untuk sebagian besar sistem produksi lebih baik memiliki konfigurasi yang stabil dan berkualitas tinggi.
Versi artefak memungkinkan untuk mencari tahu kapan itu dibuat, nilai-nilai apa yang dikandungnya, fitur apa yang diaktifkan / dinonaktifkan, siapa yang bertanggung jawab untuk membuat setiap perubahan dalam konfigurasi. Mungkin memerlukan beberapa upaya untuk menjaga konfigurasi di dalam artefak dan itu adalah pilihan desain untuk dibuat.
Pro & kontra
Di sini kami ingin menyoroti beberapa kelebihan dan mendiskusikan beberapa kelemahan dari pendekatan yang diusulkan.
Keuntungan
Fitur konfigurasi yang dapat dikompilasi dari sistem terdistribusi lengkap:
- Pemeriksaan konfigurasi statis. Ini memberikan tingkat kepercayaan yang tinggi, bahwa konfigurasi sudah benar diberikan batasan tipe.
- Bahasa konfigurasi yang kaya. Biasanya pendekatan konfigurasi lain terbatas pada paling banyak penggantian variabel.
Menggunakan Scala satu dapat menggunakan berbagai fitur bahasa untuk membuat konfigurasi lebih baik. Sebagai contoh, kita dapat menggunakan ciri-ciri untuk memberikan nilai default, objek untuk mengatur ruang lingkup yang berbeda, kita dapat merujuk pada nilai yang didefinisikan hanya sekali dalam lingkup luar (KERING). Dimungkinkan untuk menggunakan urutan literal, atau instance dari kelas tertentu ( Seq , Map , dll.). - DSL Scala memiliki dukungan yang layak untuk penulis DSL. Seseorang dapat menggunakan fitur ini untuk membuat bahasa konfigurasi yang lebih nyaman dan ramah pengguna akhir, sehingga konfigurasi akhir setidaknya dapat dibaca oleh pengguna domain.
- Integritas dan koherensi antar node. Salah satu manfaat memiliki konfigurasi untuk keseluruhan sistem terdistribusi di satu tempat adalah bahwa semua nilai didefinisikan secara ketat sekali dan kemudian digunakan kembali di semua tempat di mana kita membutuhkannya. Juga ketikkan deklarasi port aman memastikan bahwa dalam semua kemungkinan konfigurasi yang benar node sistem akan berbicara bahasa yang sama. Ada ketergantungan eksplisit antara node yang membuatnya sulit untuk lupa menyediakan beberapa layanan.
- Kualitas perubahan yang tinggi. Pendekatan keseluruhan melewati perubahan konfigurasi melalui proses PR normal menetapkan standar kualitas yang tinggi juga dalam konfigurasi.
- Perubahan konfigurasi simultan. Setiap kali kami melakukan perubahan dalam konfigurasi penerapan otomatis memastikan bahwa semua node diperbarui.
- Penyederhanaan aplikasi. Aplikasi tidak perlu menguraikan dan memvalidasi konfigurasi dan menangani nilai konfigurasi yang salah. Ini menyederhanakan aplikasi keseluruhan. (Beberapa peningkatan kompleksitas ada dalam konfigurasi itu sendiri, tetapi ini merupakan trade-off sadar terhadap keselamatan.) Cukup mudah untuk kembali ke konfigurasi biasa - cukup tambahkan bagian yang hilang. Lebih mudah untuk memulai dengan konfigurasi yang dikompilasi dan menunda implementasi potongan-potongan tambahan untuk beberapa waktu kemudian.
- Konfigurasi berversi. Karena kenyataan bahwa perubahan konfigurasi mengikuti proses pengembangan yang sama, akibatnya kami mendapatkan artefak dengan versi unik. Ini memungkinkan kita untuk beralih konfigurasi kembali jika diperlukan. Kami bahkan dapat menggunakan konfigurasi yang digunakan setahun yang lalu dan itu akan bekerja dengan cara yang persis sama. Konfigurasi yang stabil meningkatkan kemampuan prediksi dan keandalan sistem terdistribusi. Konfigurasi ini diperbaiki pada waktu kompilasi dan tidak dapat dengan mudah diubah pada sistem produksi.
- Modularitas Kerangka yang diusulkan adalah modular dan modul dapat dikombinasikan dengan berbagai cara
mendukung berbagai konfigurasi (pengaturan / tata letak). Secara khusus, dimungkinkan untuk memiliki tata letak simpul tunggal skala kecil dan pengaturan multi simpul skala besar. Masuk akal untuk memiliki beberapa tata letak produksi. - Pengujian Untuk tujuan pengujian seseorang dapat mengimplementasikan layanan tiruan dan menggunakannya sebagai ketergantungan dengan cara yang aman. Beberapa tata letak pengujian yang berbeda dengan berbagai bagian yang diganti dengan tiruan dapat dipertahankan secara bersamaan.
- Pengujian integrasi. Terkadang dalam sistem terdistribusi, sulit untuk menjalankan tes integrasi. Menggunakan pendekatan yang dijelaskan untuk mengetik konfigurasi aman dari sistem terdistribusi lengkap, kita dapat menjalankan semua bagian yang didistribusikan pada server tunggal dengan cara yang terkendali. Sangat mudah untuk meniru situasi
ketika salah satu layanan menjadi tidak tersedia.
Kekurangan
Pendekatan konfigurasi yang dikompilasi berbeda dari konfigurasi "normal" dan mungkin tidak sesuai dengan semua kebutuhan. Berikut adalah beberapa kelemahan dari konfigurasi yang dikompilasi:
- Konfigurasi statis. Mungkin tidak cocok untuk semua aplikasi. Dalam beberapa kasus ada kebutuhan untuk segera memperbaiki konfigurasi dalam produksi dengan melewati semua langkah-langkah keamanan. Pendekatan ini membuatnya lebih sulit. Kompilasi dan pemindahan diperlukan setelah membuat perubahan dalam konfigurasi. Ini adalah fitur dan bebannya.
- Generasi konfigurasi. Ketika konfigurasi dihasilkan oleh beberapa alat otomasi, pendekatan ini membutuhkan kompilasi berikutnya (yang mungkin gagal). Mungkin diperlukan upaya tambahan untuk mengintegrasikan langkah tambahan ini ke sistem build.
- Instrumen. Ada banyak alat yang digunakan saat ini yang bergantung pada konfigurasi berbasis teks. Beberapa dari mereka
tidak akan berlaku ketika konfigurasi dikompilasi. - Diperlukan pergeseran pola pikir. Pengembang dan DevOps terbiasa dengan file konfigurasi teks. Gagasan mengkompilasi konfigurasi mungkin tampak aneh bagi mereka.
- Sebelum memperkenalkan konfigurasi yang dapat dikompilasi, diperlukan proses pengembangan perangkat lunak berkualitas tinggi.
Ada beberapa batasan contoh yang diterapkan:
- Jika kami memberikan konfigurasi tambahan yang tidak diminta oleh implementasi node, compiler tidak akan membantu kami untuk mendeteksi implementasi yang tidak ada. Ini dapat diatasi dengan menggunakan
HList atau ADT (kelas kasus) untuk konfigurasi simpul, bukan sifat dan Pola Kue. - Kami harus menyediakan beberapa boilerplate dalam file konfigurasi: (
package , import , deklarasi object ;
override def untuk parameter yang memiliki nilai default). Ini mungkin sebagian ditangani menggunakan DSL. - Dalam posting ini kami tidak membahas konfigurasi ulang dinamis dari cluster node yang sama.
Kesimpulan
Dalam posting ini kita telah membahas ide untuk mewakili konfigurasi secara langsung dalam kode sumber dengan cara yang aman. Pendekatan ini dapat digunakan dalam banyak aplikasi sebagai pengganti xml- dan konfigurasi berbasis teks lainnya. Meskipun contoh kita telah diimplementasikan dalam Scala, itu juga dapat diterjemahkan ke bahasa kompilasi lainnya (seperti Kotlin, C #, Swift, dll.). Orang bisa mencoba pendekatan ini dalam proyek baru dan, jika itu tidak cocok, beralih ke cara lama.
Tentu saja, konfigurasi yang dapat dikompilasi membutuhkan proses pengembangan yang berkualitas tinggi. Sebagai imbalannya ia berjanji untuk memberikan konfigurasi yang kuat dan berkualitas tinggi.
Pendekatan ini dapat diperluas dengan berbagai cara:
- Seseorang dapat menggunakan makro untuk melakukan validasi konfigurasi dan gagal pada waktu kompilasi jika terjadi kegagalan kendala logika bisnis.
- DSL dapat diimplementasikan untuk mewakili konfigurasi dengan cara yang ramah pengguna-domain.
- Manajemen sumber daya yang dinamis dengan penyesuaian konfigurasi otomatis. Sebagai contoh, ketika kita menyesuaikan jumlah node cluster kita mungkin ingin (1) node untuk mendapatkan konfigurasi yang sedikit dimodifikasi; (2) manajer cluster untuk menerima info node baru.
Terima kasih
Saya ingin mengucapkan terima kasih kepada Andrey Saksonov, Pavel Popov, Anton Nehaev karena memberikan umpan balik inspirasional pada draft posting ini yang membantu saya membuatnya lebih jelas.